RDD序列化
1. 闭包检查
从计算的角度, 算子以外的代码都是在Driver端执行, 算子里面的代码都是在Executor端执行。那么在scala的函数式编程中,就会导致算子内经常会用到算子外的数据,这样就形成了闭包的效果,如果使用的算子外的数据无法序列化,就意味着无法传值给Executor端执行,就会发生错误,所以需要在执行任务计算前,检测闭包内的对象是否可以进行序列化,这个操作我们称之为闭包检测。
scala
object RDD_demo {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
val rdd1 = sc.makeRDD(List(("a", 1),("b", 1),("a", 3),("a", 4)), 2)
val user = new User()
rdd1.foreach(t=>{
println(s"${t._1}"+ user.name)
})
sc.stop()
}
}
class User(){
var name:String = "jiebaba"
}运行结果: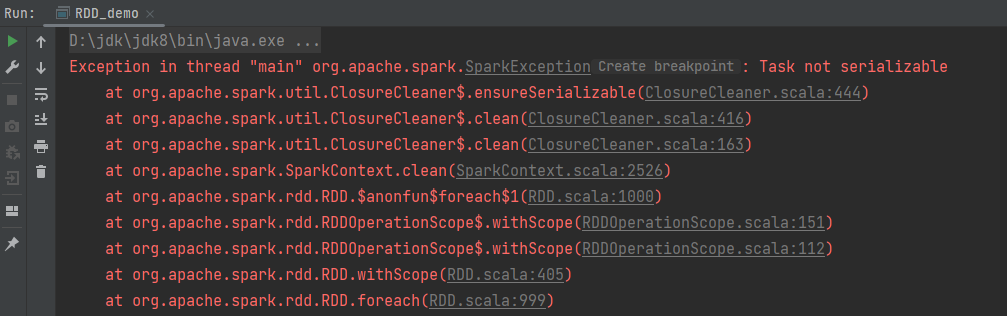 原因就在于foreach算子中使用匿名函数,它包含闭包操作,就会触发闭包监测。
原因就在于foreach算子中使用匿名函数,它包含闭包操作,就会触发闭包监测。
Spark源码:
scala
def foreach(f: T => Unit): Unit = withScope {
val cleanF = sc.clean(f)
sc.runJob(this, (iter: Iterator[T]) => iter.foreach(cleanF))
}
private[spark] def clean[F <: AnyRef](f: F, checkSerializable: Boolean = true): F = {
// 检测是否序列化
ClosureCleaner.clean(f, checkSerializable)
f
}解决办法是:
- 将User实现序列化
scala
class User() extends Serializable {
var name:String = "jiebaba"
}2, 将User类改成样例类, 因为样例类在编译时会自动混入序列化特性
scala
case class User() {
var name:String = "jiebaba"
}2. 序列化方法和属性
Java的序列化能够序列化任何的类。但是比较重(字节多),序列化后,对象的提交也比较大。Spark出于性能的考虑,Spark2.0开始支持另外一种Kryo序列化机制。Kryo速度是Serializable的10倍。当RDD在Shuffle数据的时候,简单数据类型、数组和字符串类型已经在Spark内部使用Kryo来序列化。
使用Spark中的Kryo包序列化和反序列化:
java
import com.esotericsoftware.kryo.Kryo;
import com.esotericsoftware.kryo.io.Input;
import com.esotericsoftware.kryo.io.Output;
import com.esotericsoftware.kryo.serializers.BeanSerializer;
import java.io.*;
public class KryoDemo {
public static void main(String[] args) throws IOException {
User user = new User();
user.setAge(32);
user.setName("jack");
serialByJava(user, "E:\\user.class");
kryoSerial(user, "E:\\user.clazz");
User user1 = kryoDeSerial(User.class, "E:\\user.clazz");
System.out.println("name = " + user1.getName());
System.out.println("name = " + user1.getName());
}
public static <T> T kryoDeSerial(Class<T> c, String filepath) {
try {
Kryo kryo = new Kryo();
kryo.register(c, new BeanSerializer(kryo, c));
Input input = new Input(new BufferedInputStream(new FileInputStream(filepath)));
T t = kryo.readObject(input, c);
input.close();
return t;
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
public static void kryoSerial(Serializable s, String filepath) {
try {
Kryo kryo = new Kryo();
kryo.register(s.getClass(), new BeanSerializer(kryo, s.getClass()));
Output output = new Output(new BufferedOutputStream(new FileOutputStream(filepath)));
kryo.writeObject(output, s);
output.flush();
output.close();
} catch (Exception e) {
e.printStackTrace();
}
}
public static void serialByJava(Serializable s, String path) throws IOException {
try (ObjectOutputStream outputStream = new ObjectOutputStream(new FileOutputStream(path))) {
outputStream.writeObject(s);
}
}
static class User implements Serializable {
// java中被transient修饰的属性不能被序列化
private transient String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
}运行结果: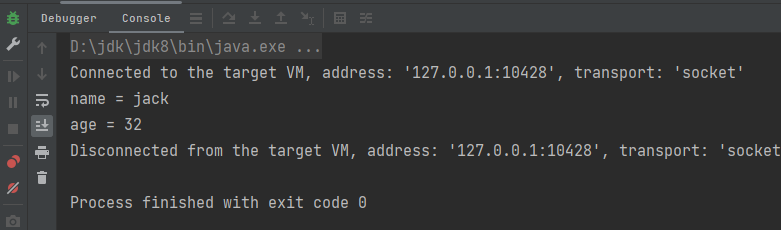 可以看到User对象的name属性通过kyro框架仍然可以读出来,kyro框架不仅性能高,生成字节码小利于传输,而且kyro框架规避了java序列化的一些安全限制,使得数据在序列化传输中得以完整。解决了比如常见的ArrayList类的数据就被标记transient导致序列化数据传输的问题,以下是ArrayList的源码:
可以看到User对象的name属性通过kyro框架仍然可以读出来,kyro框架不仅性能高,生成字节码小利于传输,而且kyro框架规避了java序列化的一些安全限制,使得数据在序列化传输中得以完整。解决了比如常见的ArrayList类的数据就被标记transient导致序列化数据传输的问题,以下是ArrayList的源码:
java
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
.......
/**
* The array buffer into which the elements of the ArrayList are stored.
* The capacity of the ArrayList is the length of this array buffer. Any
* empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
* will be expanded to DEFAULT_CAPACITY when the first element is added.
*/
transient Object[] elementData;