自定义函数
用户可以通过 spark.udf功能添加自定义函数,实现自定义功能。
1. 自定义UDF函数
给数据中name一列增加前缀字符串:'Name:'
scala
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
object SparkSQLUDF {
case class Person(id: Int, name: String, age: Int)
def main(args: Array[String]): Unit = {
//创建上下文环境配置对象
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQLBasic")
val session = SparkSession.builder().config(conf).getOrCreate()
import session.implicits._
val df1: DataFrame = session.read.json("datas/user.json")
df1.createTempView("user")
// 注册UDF函数
session.udf.register("prefixName", (value: String) => "Name:" + value)
// 使用UDF函数
session.sql("select age, prefixName(name) from user").show
session.stop()
}
}执行结果: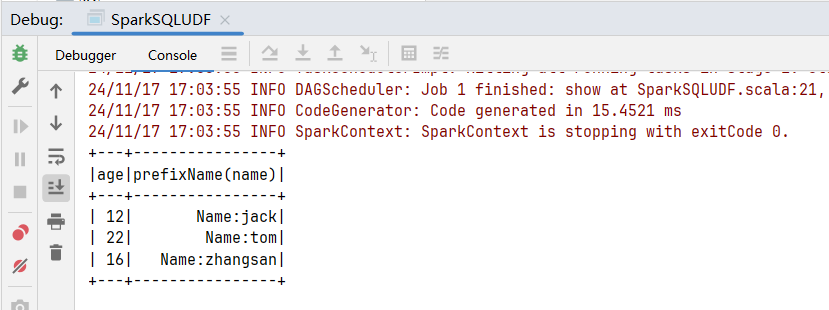
2. 自定义UDAF函数
强类型的Dataset和弱类型的DataFrame都提供了相关的聚合函数,如count(),countDistinct(),avg(),max(),min()。除此之外,用户可以设定自己的自定义聚合函数。通过继承UserDefinedAggregateFunction来实现用户自定义弱类型聚合函数。从Spark3.0版本后,UserDefinedAggregateFunction已经不推荐使用了。可以统一采用强类型聚合函数 Aggregator。
2.1 需求
计算平均工资
以前可以使用RDD,或者累加器实现。
2.2 代码实现
自定义聚合函数AvgAgeUDAF,步骤如下:
- 继承org.apache.spark.sql.expressions.Aggregator#Aggregator,定义泛型:
- IN: 输入数据类型
- BUF: 缓冲区的数据类型
- OUT: 输出的数据类型
- 重写方法
scala
package com.rocket.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.expressions.Aggregator
import org.apache.spark.sql.{Dataset, Encoder, Encoders, SparkSession, functions}
object SparkSQLAvgAge {
case class Person(id: Int, name: String, age: Int)
def main(args: Array[String]): Unit = {
//创建上下文环境配置对象
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQLBasic")
val session = SparkSession.builder().config(conf).getOrCreate()
import session.implicits._
val ds1: Dataset[Person] = session.createDataset(List(Person(1, "jack", 30), Person(2, "tom", 23)))
ds1.createOrReplaceTempView("user")
// 注册udaf函数
session.udf.register("avgAge", functions.udaf(new AvgAgeUDAF()))
session.sql("select avgAge(age) from user").show
session.stop()
}
case class AgeBuffer(var sum:Long, var count: Long)
class AvgAgeUDAF extends Aggregator[Long, AgeBuffer, Double] {
// 缓冲区初始化
override def zero: AgeBuffer = {
AgeBuffer(0L, 0L)
}
// 根据输入的数据更新缓冲区的数据
override def reduce(buff: AgeBuffer, in: Long): AgeBuffer = {
buff.sum += in
buff.count += 1
buff
}
// 合并缓冲区
override def merge(buff1: AgeBuffer, buff2: AgeBuffer): AgeBuffer = {
buff1.sum += buff2.sum
buff1.count += buff2.count
buff1
}
//计算结果
override def finish(reduction: AgeBuffer): Double = {
if(reduction.count == 0){
0
}else{
reduction.sum / reduction.count
}
}
// 缓冲区的编码操作, 固定写法
override def bufferEncoder: Encoder[AgeBuffer] = Encoders.product
// 输出的编码操作, 固定写法
override def outputEncoder: Encoder[Double] = Encoders.scalaDouble
}
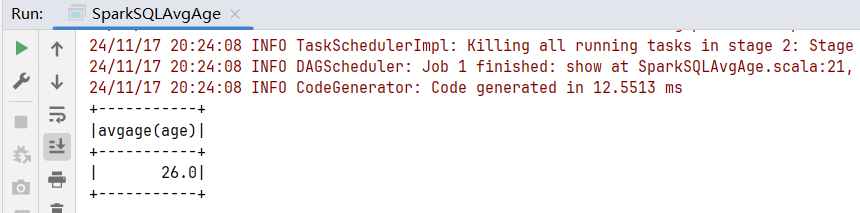
}运行结果: