累加器和广播变量
1. 累加器
1.1 为何使用累加器
scala
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("MyPartitioner")
val sc = new SparkContext(sparkConf)
val rdd1: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
var sum = 0
rdd1.foreach(it => {
sum += it
})
println(s"计算结果为: ${sum}")
sc.stop()
}运行结果: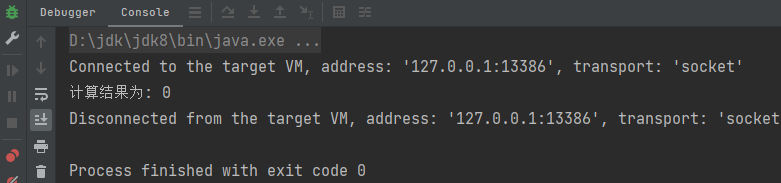 从计算结果来看sum应该为10,为何打印结果为0❌呢?原因在于这里简单的累加是在分布式计算环境中,每个Excutor正常计算出结果并且不同,他们只通过闭包特性序列化方式得到sum=0,并没有返回结果给Driver, Driver即使收到结果也没有对应的处理办法,sum依旧为0。使用累加器可以实现数据回传。
从计算结果来看sum应该为10,为何打印结果为0❌呢?原因在于这里简单的累加是在分布式计算环境中,每个Excutor正常计算出结果并且不同,他们只通过闭包特性序列化方式得到sum=0,并没有返回结果给Driver, Driver即使收到结果也没有对应的处理办法,sum依旧为0。使用累加器可以实现数据回传。
1.2 实现原理
累加器用来把Executor端变量信息聚合到Driver端。在Driver程序中定义的变量,在Executor端的每个Task都会得到这个变量的一份新的副本,每个task更新这些副本的值后,传回Driver端进行merge。
1.3 系统累加器
Spark内置的累加器有: LongAccumulator、DoubleAccumulator、CollectionAccumulator。
scala
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("MyPartitioner")
val sc = new SparkContext(sparkConf)
val rdd1: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
// 创建累加器
val sumAcc: LongAccumulator = sc.longAccumulator("sumAcc")
rdd1.foreach(it => {
// 使用累加器
sumAcc.add(it)
})
// 获取累加器的值
println(s"计算结果为: ${sumAcc.value}")
sc.stop()
}运行结果: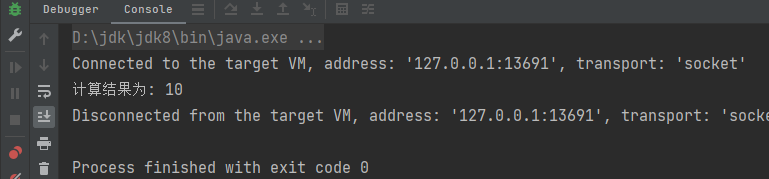
1.4 自定义累加器
内置累加器没有map类型数据的累加器:
scala
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("MyPartitioner")
val sc = new SparkContext(sparkConf)
val rdd1: RDD[String] = sc.makeRDD(List("hello", "java", "spark", "scala", "spark"), 2)
val myAcc = new MyAccumulator()
// 注册累加器
sc.register(myAcc, "myAcc")
rdd1.foreach(it => {
// 使用累加器
myAcc.add(it)
})
rdd1.collect()
rdd1.collect()
// 获取累加器的值
println(s"计算结果为: ${myAcc.value}")
sc.stop()
}
// 创建累加器
class MyAccumulator extends AccumulatorV2[String, mutable.Map[String, Int]] {
private var myMap: mutable.Map[String, Int] = mutable.Map[String, Int]()
// 是否初始状态
override def isZero: Boolean = {
myMap.size == 0
}
// 复制
override def copy(): AccumulatorV2[String, mutable.Map[String, Int]] = {
new MyAccumulator()
}
// 重置累加器
override def reset(): Unit = {
myMap.clear()
}
override def add(key: String): Unit = {
val newCount = myMap.getOrElse(key, 0)+1
myMap.update(key, newCount)
}
// Driver合并累加器结果
override def merge(other: AccumulatorV2[String, mutable.Map[String, Int]]): Unit = {
val map1 = this.myMap
val map2 = other.value
map2.foreach{
case (word: String, count:Int) =>{
val newCount = map1.getOrElse(word, 0)+count
map1.update(word, newCount)
}
}
}
// 累加器结果
override def value: mutable.Map[String, Int] = {
myMap
}
}运行结果: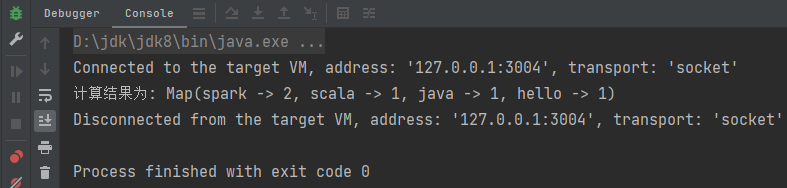
2. 广播变量
2.1 为何使用广播变量
scala
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("BroadcastDemo")
val sc = new SparkContext(sparkConf)
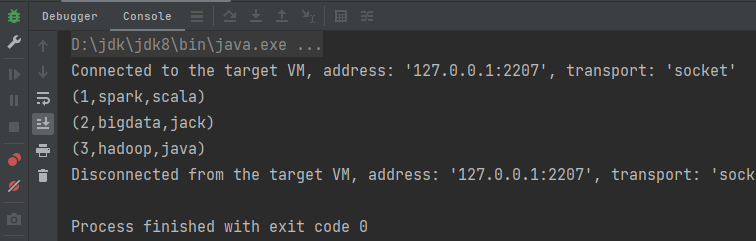
val rdd1: RDD[(Int, String)] = sc.makeRDD(List((1, "scala"), (2, "jack"), (3, "java")), 2)
// val rdd2: RDD[(Int, String)] = sc.makeRDD(List((1, "spark"), (2, "bigdata"), (3, "hadoop")), 2)
// 使用join会导致数据量几何倍的增长,并且会影响shuffle的性能,不推荐使用
// val rdd3: RDD[(Int, (String, String))] = rdd1.join(rdd2)
val map1: mutable.Map[Int, String] = mutable.Map((1, "spark"), (2, "bigdata"), (3, "hadoop"))
rdd1.map {
case (word, value) => {
val newValue = map1.getOrElse(word, 0)+","+value
(word,newValue)
}
}.collect().foreach(println)
sc.stop()
}虽然没有使用join因而不会发生笛卡尔积现象,但是map1的数据会在rdd计算中会分发给每个Task节点,导致一个Executor中含有大量重复的数据,并且占用大量的内存。Executor其实就一个JVM进程,所以在启动时会自动分配内存,可以使用全局只读变量也就是广播变量来存储map1数据。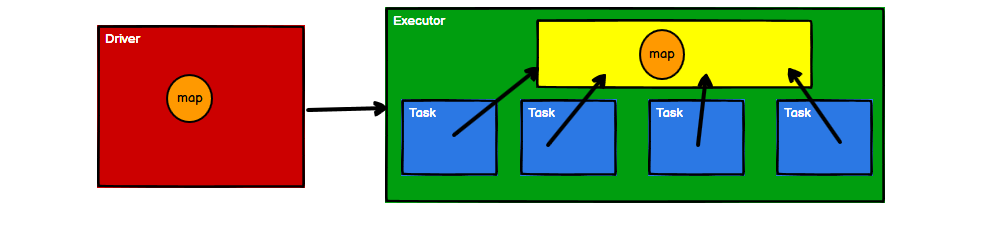
2.2 实现原理
广播变量用来高效分发较大的对象。向所有工作节点发送一个较大的只读值,以供一个或多个Spark操作使用。比如你的应用需要向所有节点发送一个较大的只读查询表,广播变量用起来就很方便。
2.3 基础编程
scala
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("BroadcastDemo")
val sc = new SparkContext(sparkConf)
val rdd1: RDD[(Int, String)] = sc.makeRDD(List((1, "scala"), (2, "jack"), (3, "java")), 2)
val map1: mutable.Map[Int, String] = mutable.Map((1, "spark"), (2, "bigdata"), (3, "hadoop"))
// 设置广播变量
val bc: Broadcast[mutable.Map[Int, String]] = sc.broadcast(map1)
rdd1.map {
case (word, value) => {
// 使用广播变量
val newValue = bc.value.getOrElse(word, 0)+","+value
(word, newValue)
}
}.collect().foreach(println)
sc.stop()
}