源码之应用程序执行
1. 初始化SparkContext
我们的代码最开始会有创建SparkContext,它创建主要会初始化一些属性: 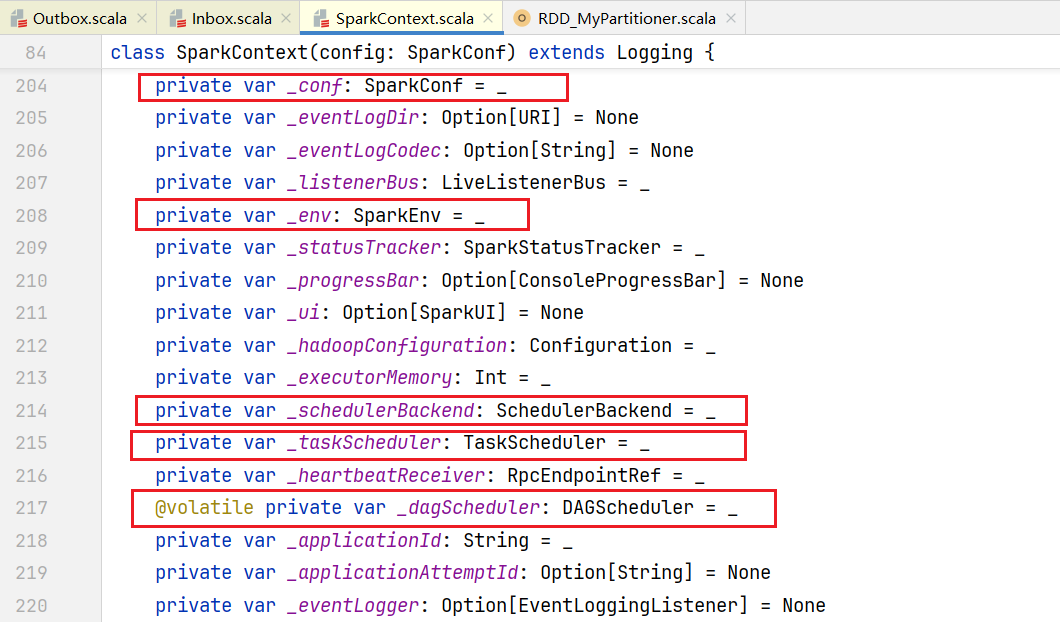 主要就是以下这些属性比较重要:
主要就是以下这些属性比较重要: 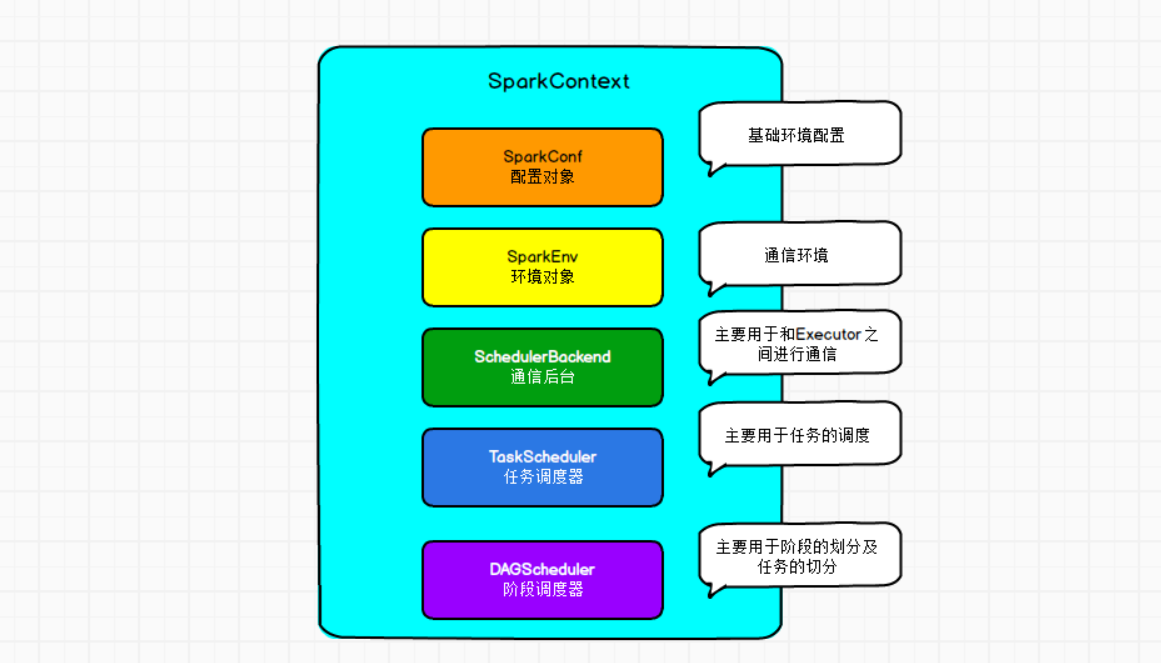
##2.Rdd依赖 我们编写的代码执行到后面会有RDD的一些处理,比如读取文件sc.textFile("datas"),点击进入源码: 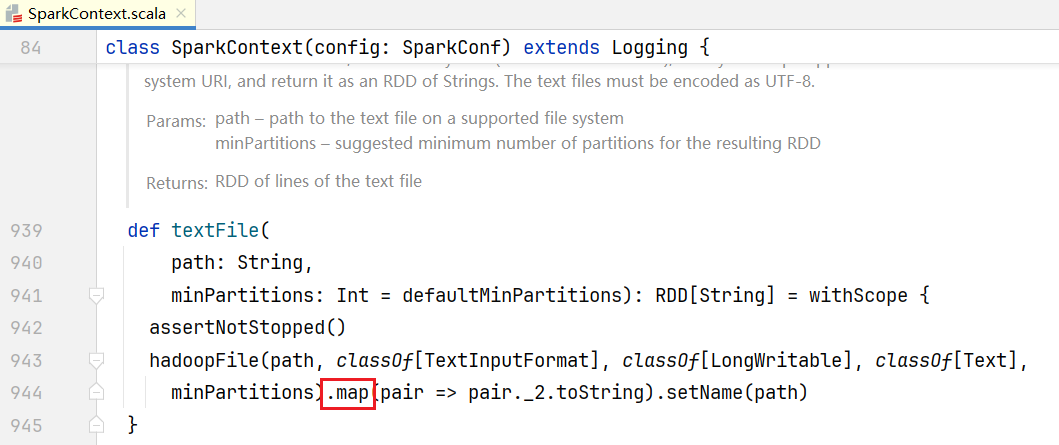 可以看到底层读取Hadoop文件会执行map()方法,点击进入map()方法:
可以看到底层读取Hadoop文件会执行map()方法,点击进入map()方法: 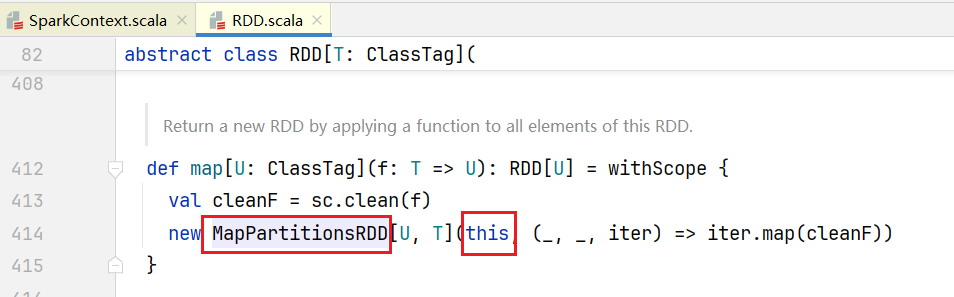 可以看到得到的对象是MapPartitionsRDD,我们编写的代码继续往下执行,比如会执行
可以看到得到的对象是MapPartitionsRDD,我们编写的代码继续往下执行,比如会执行lines.flatMap(_.split("")),进入源码查看:  返回的对象也是MapPartitionsRDD,值得注意的是代码里面的this就是之前的MapPartitionsRDD,点击查看MapPartitionsRDD:
返回的对象也是MapPartitionsRDD,值得注意的是代码里面的this就是之前的MapPartitionsRDD,点击查看MapPartitionsRDD: 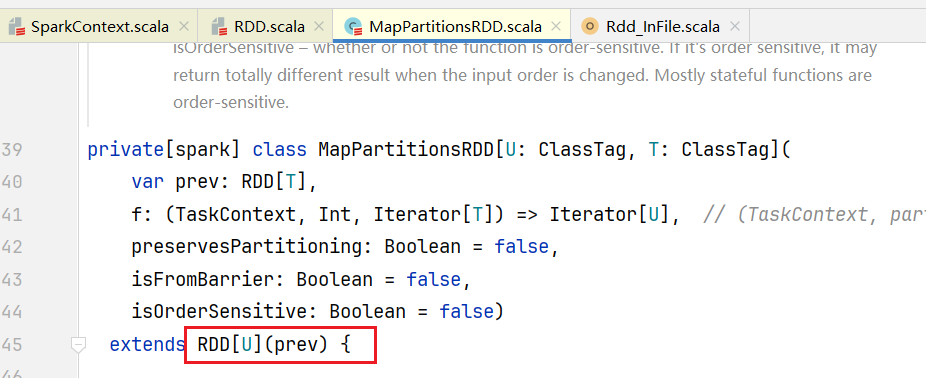 可见MapPartitionsRDD继承了RDD,进入RDD源码,如果子类MapPartitionsRDD要初始化需要调用父类的构造函数:
可见MapPartitionsRDD继承了RDD,进入RDD源码,如果子类MapPartitionsRDD要初始化需要调用父类的构造函数: 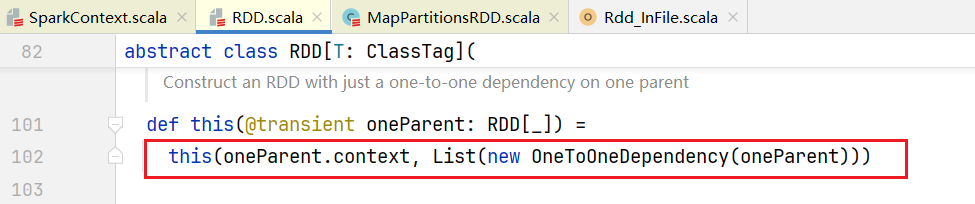 里面传入参数OneToOneDependency对象,维护RDD之间的依赖关系,OneToOneDependency对象构造函数传入的oneParent就是prev,prev就是上一个RDD,依赖关系叫做OneToOneDependency。 我们的代码继续执行,比如会执行到
里面传入参数OneToOneDependency对象,维护RDD之间的依赖关系,OneToOneDependency对象构造函数传入的oneParent就是prev,prev就是上一个RDD,依赖关系叫做OneToOneDependency。 我们的代码继续执行,比如会执行到wordMapRdd.reduceByKey(_._1),点击进入源码:  会执行combineByKeyWithClassTag()方法,点击进入:
会执行combineByKeyWithClassTag()方法,点击进入: 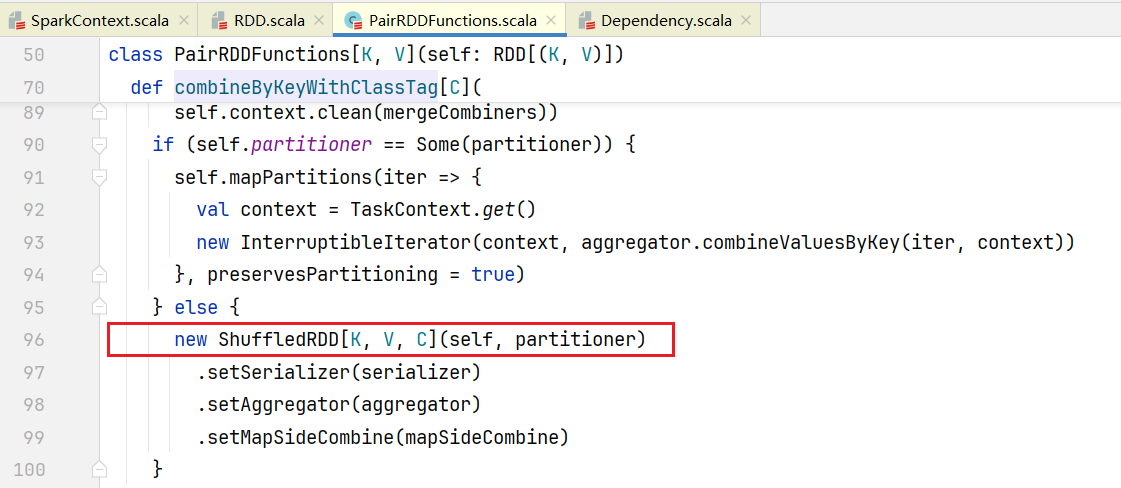 正常情况程序会正常执行会走else,可以看到里面会创建ShuffledRDD对象,点击ShuffledRDD:
正常情况程序会正常执行会走else,可以看到里面会创建ShuffledRDD对象,点击ShuffledRDD: 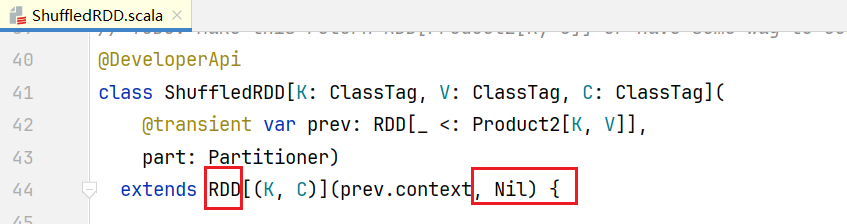 可以看到它也是继承RDD,但和之前RDD子类不同,它在父类构造函数中传入的是依赖关系是Nil,在ShuffledRDD中也有获取依赖方法getDependencies():
可以看到它也是继承RDD,但和之前RDD子类不同,它在父类构造函数中传入的是依赖关系是Nil,在ShuffledRDD中也有获取依赖方法getDependencies(): 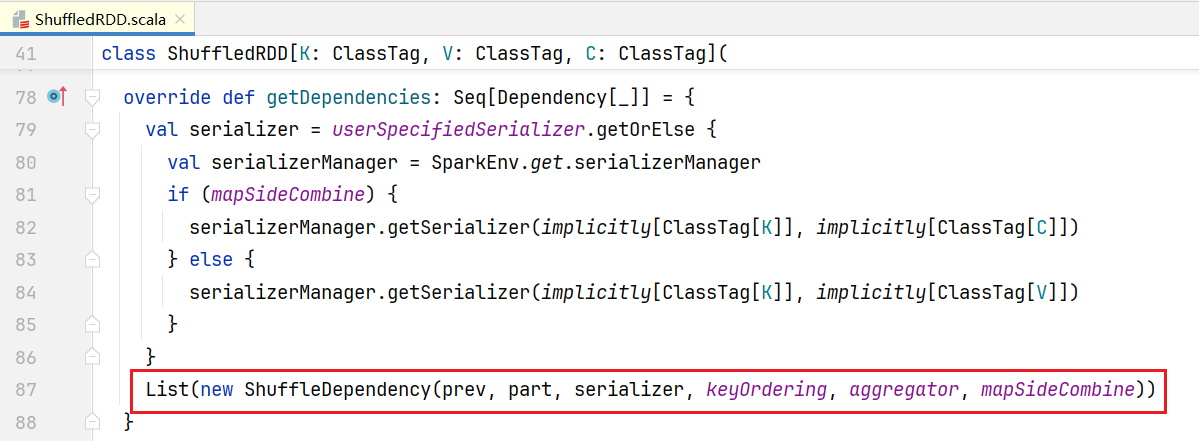 里面会传入prev,也就是说通过getDependencies()能找到上一个RDD,依赖关系叫做ShuffleDependency 整个过程如下图所示:
里面会传入prev,也就是说通过getDependencies()能找到上一个RDD,依赖关系叫做ShuffleDependency 整个过程如下图所示: 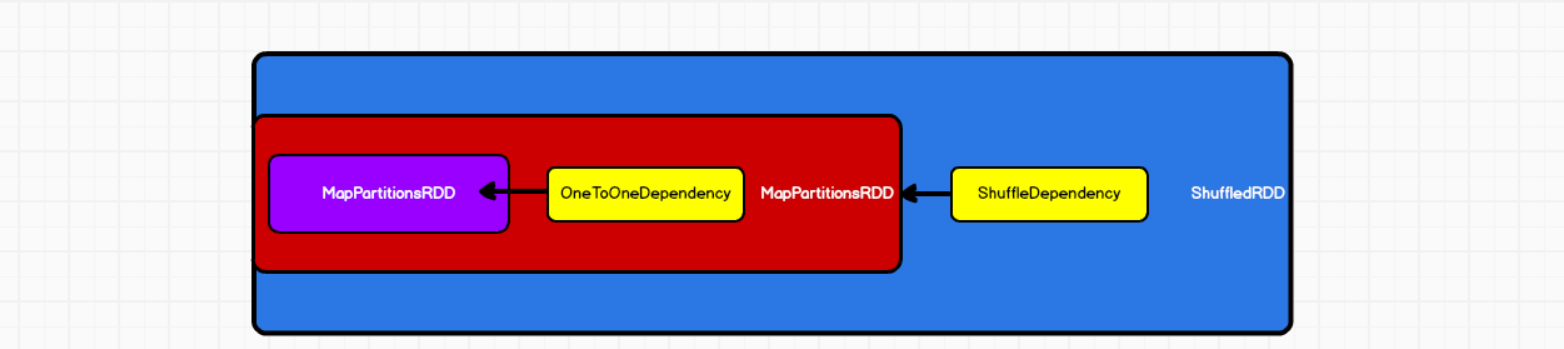
##3.阶段的划分 我们的代码中RDD转换逻辑执行完毕后,比如会执行reductRdd.collect(),点击进入行动算子collect()代码中: 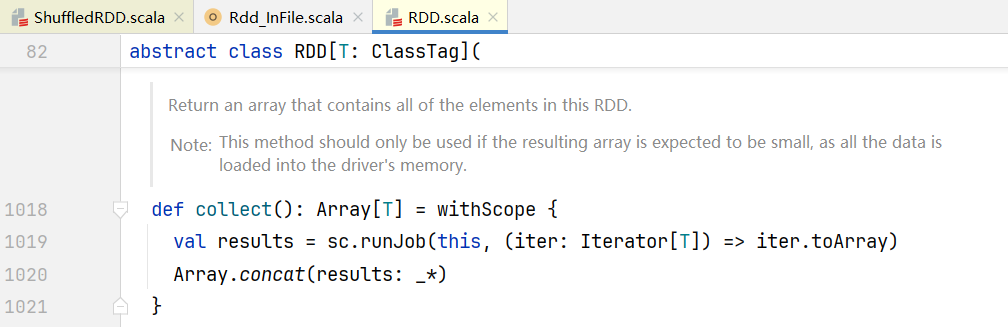 点击sc.runJob()方法,进入SparkContext.scala中:
点击sc.runJob()方法,进入SparkContext.scala中: 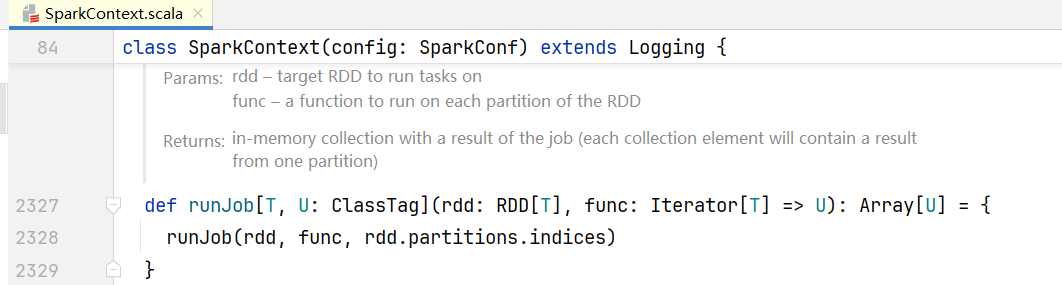 进入runJob()代码中:
进入runJob()代码中:
defrunJob[T,U:ClassTag](
rdd:RDD[T],
func:Iterator[T]=>U,
partitions:Seq[Int]):Array[U]={
valcleanedFunc=clean(func)
runJob(rdd,(ctx:TaskContext,it:Iterator[T])=>cleanedFunc(it),partitions)
}再次点击,进入runJob方法中:
defrunJob[T,U:ClassTag](
rdd:RDD[T],
func:(TaskContext,Iterator[T])=>U,
partitions:Seq[Int]):Array[U]={
valresults=newArray[U](partitions.size)
runJob[T,U](rdd,func,partitions,(index,res)=>results(index)=res)
results
}可以看到会使用dagScheduler去调度任务: 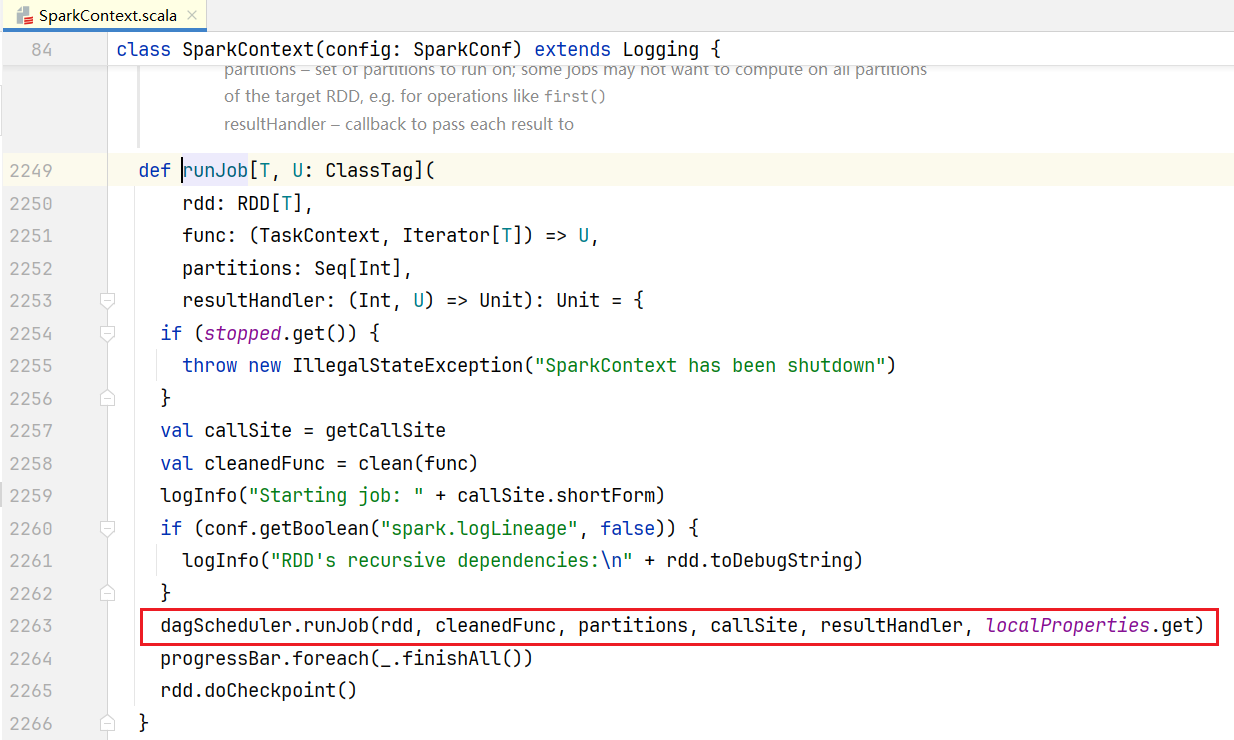 点击进入dagScheduler的runJob()方法:
点击进入dagScheduler的runJob()方法:
defrunJob[T,U](
rdd:RDD[T],
func:(TaskContext,Iterator[T])=>U,
partitions:Seq[Int],
callSite:CallSite,
resultHandler:(Int,U)=>Unit,
properties:Properties):Unit={
valstart=System.nanoTime
//提交作业
valwaiter=submitJob(rdd,func,partitions,callSite,resultHandler,properties)
ThreadUtils.awaitReady(waiter.completionFuture,Duration.Inf)
。。。。。。
}点击submitJob()方法,进入提交作业逻辑:
defsubmitJob[T,U](
rdd:RDD[T],
func:(TaskContext,Iterator[T])=>U,
partitions:Seq[Int],
callSite:CallSite,
resultHandler:(Int,U)=>Unit,
properties:Properties):JobWaiter[U]={
......//省略一些检测和事件监听注册
valwaiter=newJobWaiter[U](this,jobId,partitions.size,resultHandler)
eventProcessLoop.post(JobSubmitted(
jobId,rdd,func2,partitions.toArray,callSite,waiter,
Utils.cloneProperties(properties)))
waiter
}可以看到会向eventProcessLoop中发送JobSubmitted事件消息,点击进入post()方法 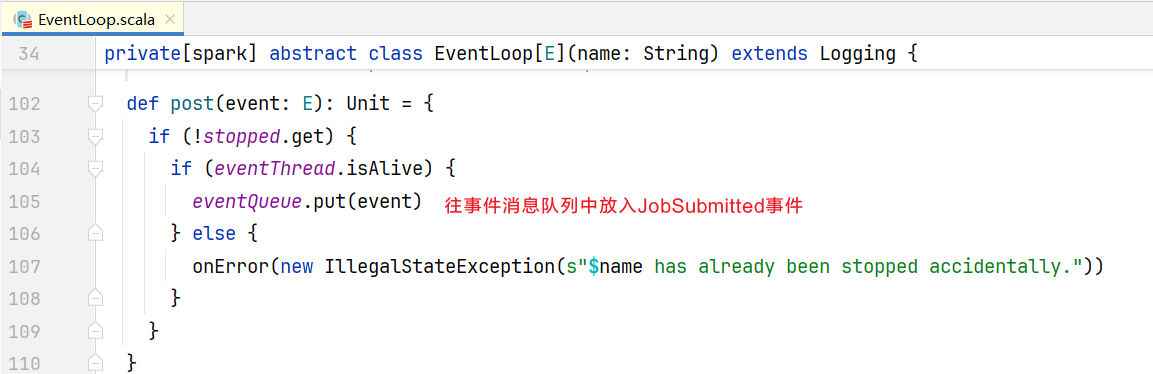 消息放入过后如何取出来呢,可以看到有一个事件线程eventThread,点击eventThread:
消息放入过后如何取出来呢,可以看到有一个事件线程eventThread,点击eventThread: 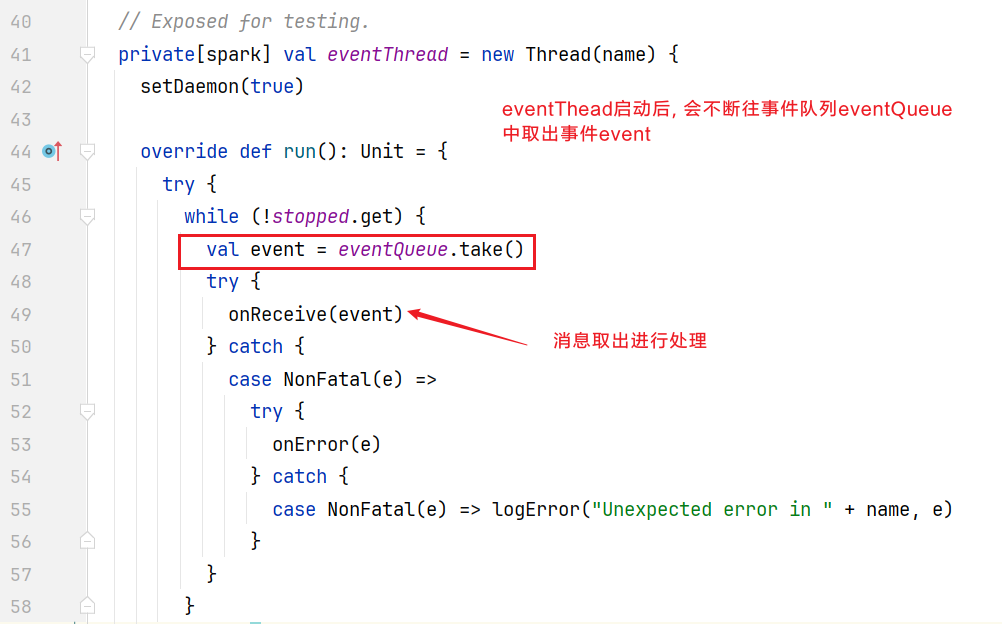 点击进入onReceive()方法:
点击进入onReceive()方法:  发现是一个抽象方法,查看子类实现:
发现是一个抽象方法,查看子类实现: 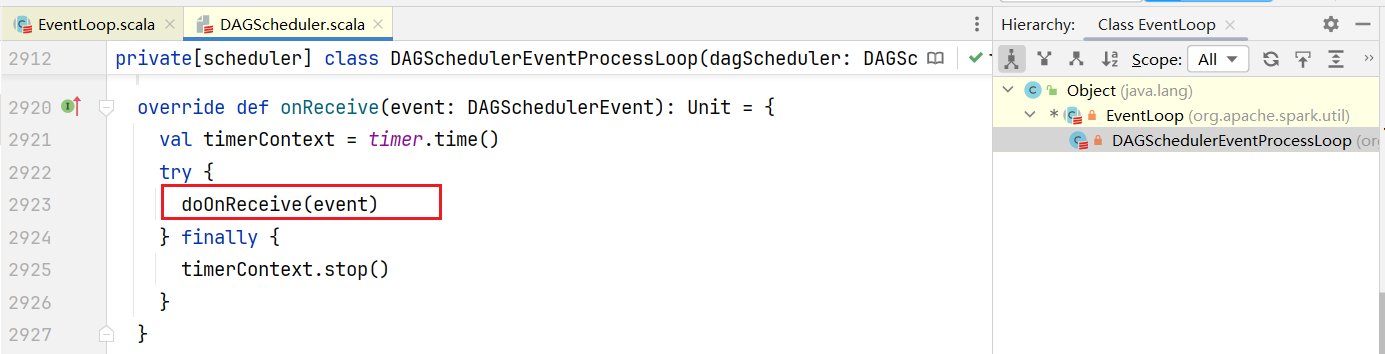 点击doOnReceive()方法,可以发现里面使用模式匹配,第一个就是JobSubmitted类型处理逻辑:
点击doOnReceive()方法,可以发现里面使用模式匹配,第一个就是JobSubmitted类型处理逻辑:
privatedefdoOnReceive(event:DAGSchedulerEvent):Unit=eventmatch{
caseJobSubmitted(jobId,rdd,func,partitions,callSite,listener,properties)=>
dagScheduler.handleJobSubmitted(jobId,rdd,func,partitions,callSite,listener,properties)
caseMapStageSubmitted(jobId,dependency,callSite,listener,properties)=>
dagScheduler.handleMapStageSubmitted(jobId,dependency,callSite,listener,properties)
......点击进入handleJobSubmitted()方法,里面就是涉及阶段的划分了: 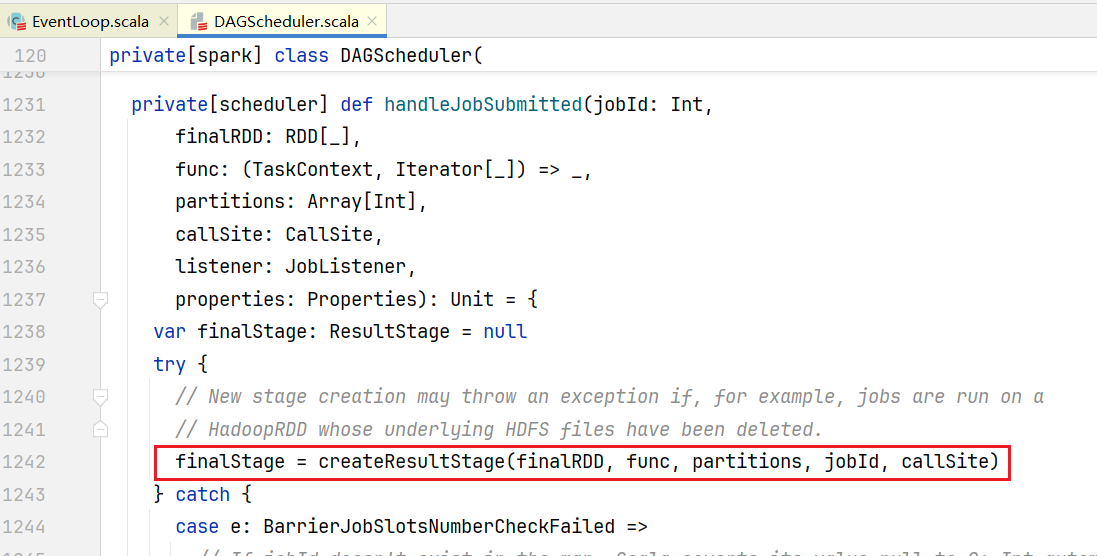 点击进入createResultStage()方法
点击进入createResultStage()方法
privatedefcreateResultStage(
rdd:RDD[_],
func:(TaskContext,Iterator[_])=>_,
partitions:Array[Int],
jobId:Int,
callSite:CallSite):ResultStage={
......
val(shuffleDeps,resourceProfiles)=getShuffleDependenciesAndResourceProfiles(rdd)
valparents=getOrCreateParentStages(shuffleDeps,jobId)
valid=nextStageId.getAndIncrement()
//划分了一个ResultStage阶段,也就是结果阶段
valstage=newResultStage(id,rdd,func,partitions,parents,jobId,
callSite,resourceProfile.id)
stageIdToStage(id)=stage
updateJobIdStageIdMaps(jobId,stage)
stage
}里面传入了很多参数,其中rdd就是最后的rdd也就是reductRdd,类型是ShuffleRDD,而parents是父阶段的意思,它是执行getOrCreateParentStages()的得到,可是怎么知道当前阶段的上一个阶段呢?进入getOrCreateParentStages()方法:
privatedefgetOrCreateParentStages(shuffleDeps:HashSet[ShuffleDependency[_,_,_]],
firstJobId:Int):List[Stage]={
shuffleDeps.map{shuffleDep=>
//创建ShuffleMap阶段
getOrCreateShuffleMapStage(shuffleDep,firstJobId)
}.toList
}它传入的shuffleDeps参数是从上一步中getShuffleDependenciesAndResourceProfiles()方法得到: 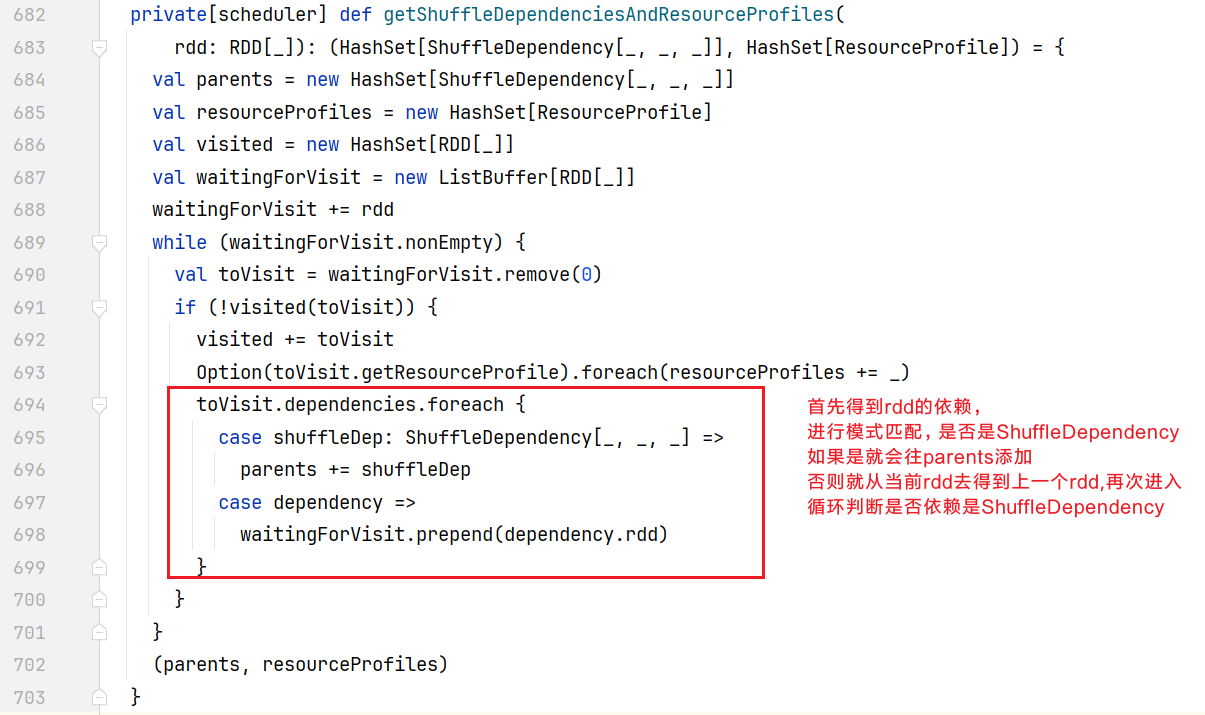 当前我们的代码就只有一个Shuffle依赖,直接执行返回parents,大小为1。在getOrCreateParentStages()方法中就是shuffleDeps,调用map时,由于只有一个,只会执行一次里面的getOrCreateShuffleMapStage()方法。得到一个ShuffleMap阶段。点击getOrCreateShuffleMapStage()方法,查看创建ShuffleMap阶段逻辑:
当前我们的代码就只有一个Shuffle依赖,直接执行返回parents,大小为1。在getOrCreateParentStages()方法中就是shuffleDeps,调用map时,由于只有一个,只会执行一次里面的getOrCreateShuffleMapStage()方法。得到一个ShuffleMap阶段。点击getOrCreateShuffleMapStage()方法,查看创建ShuffleMap阶段逻辑:
privatedefgetOrCreateShuffleMapStage(
shuffleDep:ShuffleDependency[_,_,_],
firstJobId:Int):ShuffleMapStage={
shuffleIdToMapStage.get(shuffleDep.shuffleId)match{
......
//Finally,createastageforthegivenshuffledependency.
//创建ShuffleMap阶段
createShuffleMapStage(shuffleDep,firstJobId)
}
}点击进入createShuffleMapStage()方法,可以看到它会拿上一个rdd进行相同的逻辑判断查找Shuffle依赖: 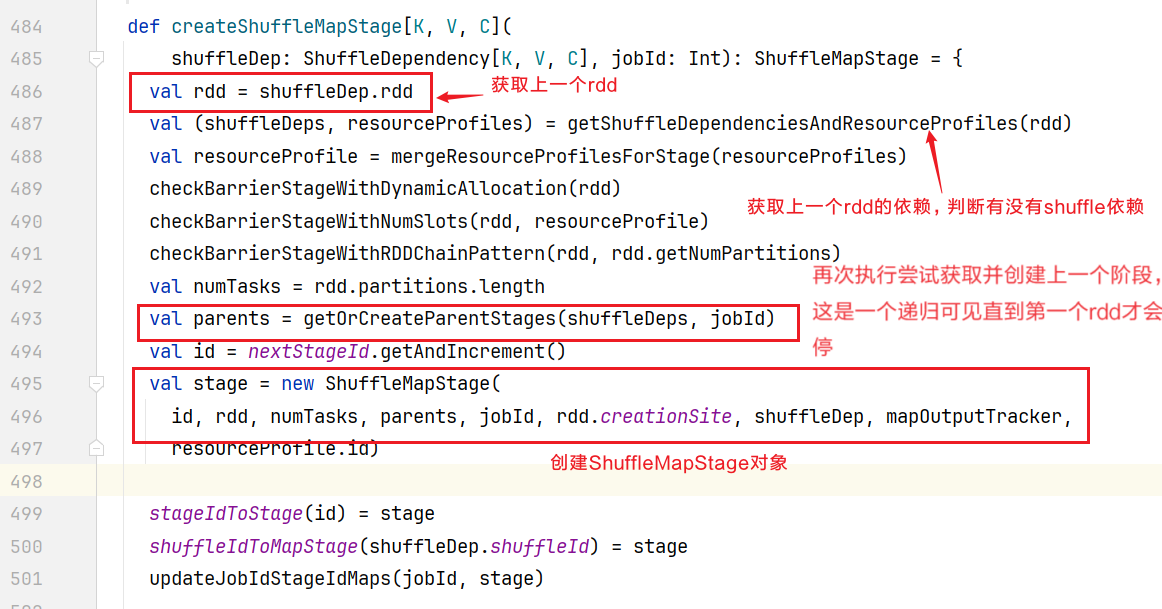 执行最终效果就是下面如图所示:
执行最终效果就是下面如图所示: 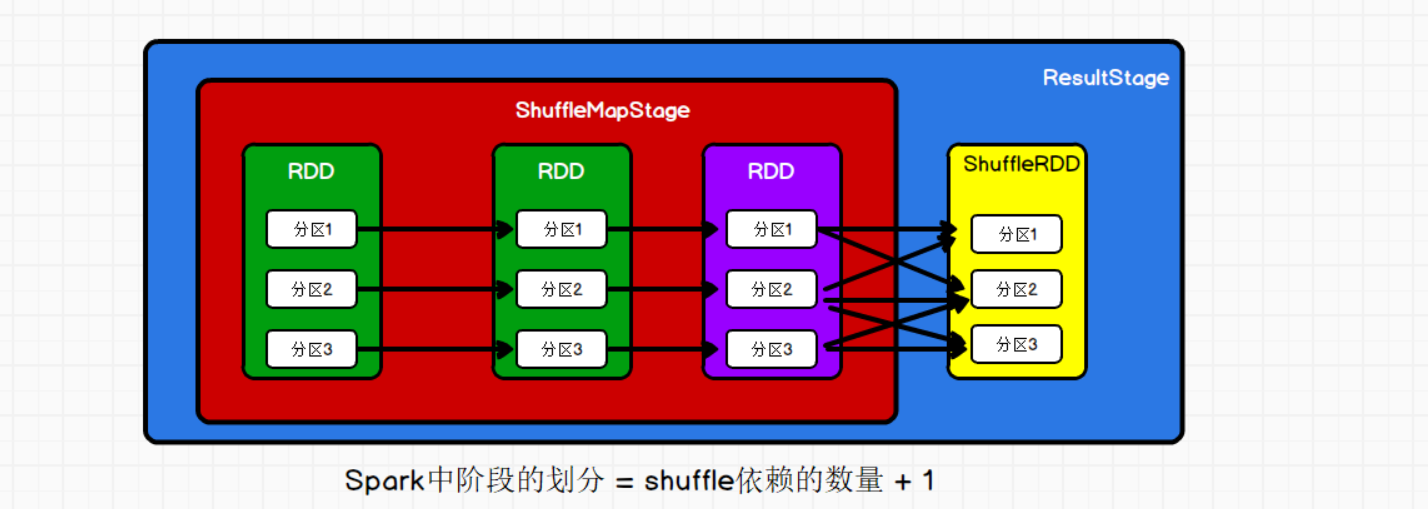 可见划分了两个阶段,有shuffle依赖就会划分阶段或者阶段划分的目的就是为了讲读写方便,比如图中ShuffleMapStage用来写数据到磁盘,ResultStage则是读文件数据。 ##4.任务的切分 我们执行的代码被划分成不同阶段,上一个阶段执行完成才能进入下一个阶段,那就是说每个阶段都是独立执行的,那么阶段里面的任务也是独立的。那么任务如何进行切分呢? 回到DAGScheduler.scala代码中的handleJobSubmitted()方法,
可见划分了两个阶段,有shuffle依赖就会划分阶段或者阶段划分的目的就是为了讲读写方便,比如图中ShuffleMapStage用来写数据到磁盘,ResultStage则是读文件数据。 ##4.任务的切分 我们执行的代码被划分成不同阶段,上一个阶段执行完成才能进入下一个阶段,那就是说每个阶段都是独立执行的,那么阶段里面的任务也是独立的。那么任务如何进行切分呢? 回到DAGScheduler.scala代码中的handleJobSubmitted()方法,  提交整体阶段后,查看submitStage()方法:
提交整体阶段后,查看submitStage()方法:  进入submitMissingTasks(),查看里面干了啥:
进入submitMissingTasks(),查看里面干了啥: 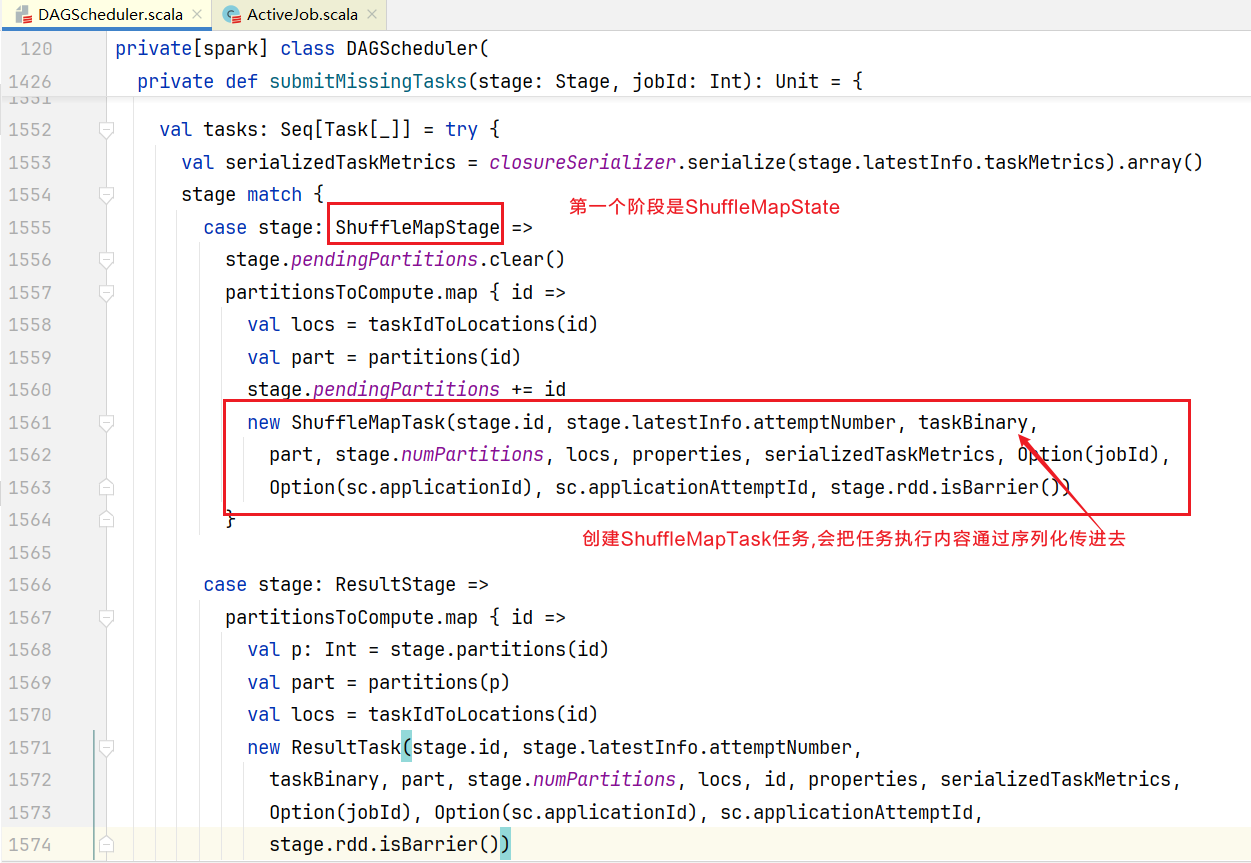 到底创建几个ShuffleMapTask呢,查看partitionsToCompute对象实例如何创建的:
到底创建几个ShuffleMapTask呢,查看partitionsToCompute对象实例如何创建的:  点击findMissingPartitions()发现是一个抽象方法,点击进入实现:
点击findMissingPartitions()发现是一个抽象方法,点击进入实现:  可以看到这个方法获得就是0到分区数(until不包含最后一个)的数组,也就是任务id是[0,n),而numPartitions是怎么来的呢?点击查看numPartitions的初始化代码:
可以看到这个方法获得就是0到分区数(until不包含最后一个)的数组,也就是任务id是[0,n),而numPartitions是怎么来的呢?点击查看numPartitions的初始化代码: 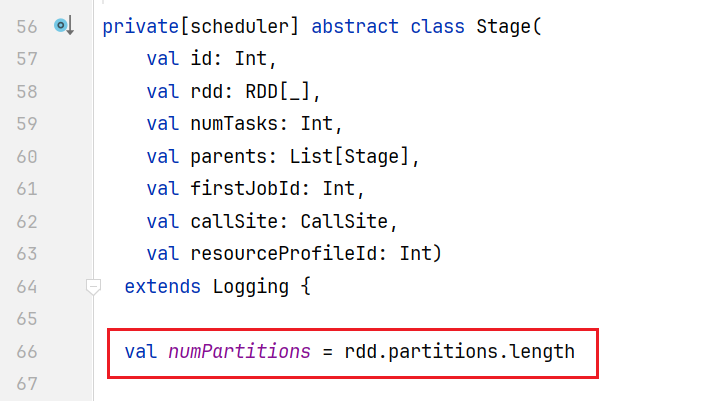 可以看到是numPartitions是从Stage对象中rdd的分区数来的,当前的Stages是ShuffleMapStage,从之前的源码分析(createShuffleMapStage()方法)里面得知这是ShuffleMapStage里面最后一个Rdd,也就是那个ReduceByKey那个RDD。从而说明在一个Stage(阶段)中,任务数量就按照分区的数量进行创建的。 ##5.任务的调度 任务被创建出指定的数量,那么如何进行调度呢?回到DAGScheduler.scala的submitMissingTasks()中,创建任务后代码后面会做任务不为空判断,进行提交任务:
可以看到是numPartitions是从Stage对象中rdd的分区数来的,当前的Stages是ShuffleMapStage,从之前的源码分析(createShuffleMapStage()方法)里面得知这是ShuffleMapStage里面最后一个Rdd,也就是那个ReduceByKey那个RDD。从而说明在一个Stage(阶段)中,任务数量就按照分区的数量进行创建的。 ##5.任务的调度 任务被创建出指定的数量,那么如何进行调度呢?回到DAGScheduler.scala的submitMissingTasks()中,创建任务后代码后面会做任务不为空判断,进行提交任务: 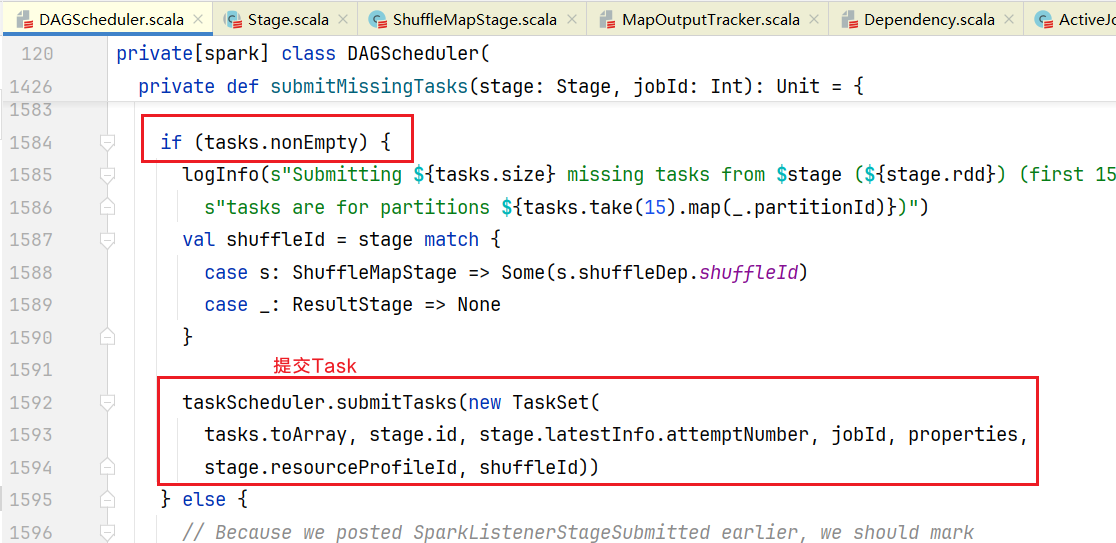 此时是任务的调度器登场,taskScheduler提交作业通过任务集TaskSet方式,点击进入实现方法TaskSchedulerImpl.scala中:
此时是任务的调度器登场,taskScheduler提交作业通过任务集TaskSet方式,点击进入实现方法TaskSchedulerImpl.scala中:
overridedefsubmitTasks(taskSet:TaskSet):Unit={
valtasks=taskSet.tasks
logInfo("Addingtaskset"+taskSet.id+"with"+tasks.length+"tasks"
+"resourceprofile"+taskSet.resourceProfileId)
this.synchronized{
//创建任务集管理器
valmanager=createTaskSetManager(taskSet,maxTaskFailures)
valstage=taskSet.stageId
valstageTaskSets=
taskSetsByStageIdAndAttempt.getOrElseUpdate(stage,newHashMap[Int,TaskSetManager])
stageTaskSets(taskSet.stageAttemptId)=manager
//调度构建器添加任务集管理器到里面
schedulableBuilder.addTaskSetManager(manager,manager.taskSet.properties)
...
}
backend.reviveOffers()
}可以看到taskSet又被包装了一层成为TaskSetManager,schedulableBuilder是拿来干嘛的呢,查看schedulableBuilder初始化:  可以看出调度任务有两种策略FIFO和FAIR,回来查看submitTasks(),在里面查看addTaskSetManager()的方法的实现,发现它添加TaskSetManager有两种实现,点击进入FIFOSchedulableBuilder类实现:
可以看出调度任务有两种策略FIFO和FAIR,回来查看submitTasks(),在里面查看addTaskSetManager()的方法的实现,发现它添加TaskSetManager有两种实现,点击进入FIFOSchedulableBuilder类实现:
overridedefaddTaskSetManager(manager:Schedulable,properties:Properties):Unit={
//向任务池中添加任务
rootPool.addSchedulable(manager)
}任务有策略的加入任务池中后,需要通知Driver取任务。回来查看submitTasks(),最后有个backend.reviveOffers(),点击进入,发现是抽象方法,选择集群类CoarseGrainedSchedulerBackend.scala中方法实现:
overridedefreviveOffers():Unit=Utils.tryLogNonFatalError{
driverEndpoint.send(ReviveOffers)
}给自己发了一个ReviveOffers消息: 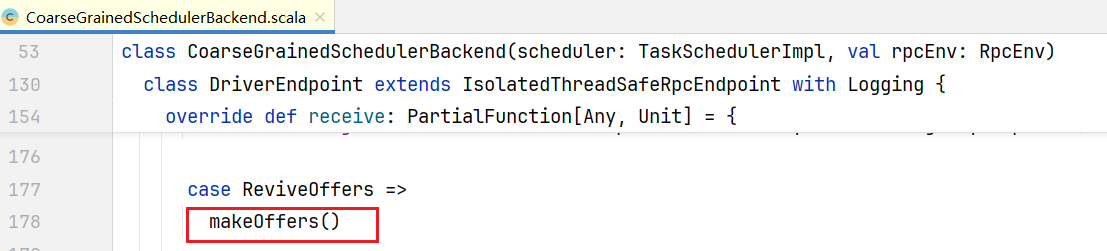 收到消息执行makeOffers()方法
收到消息执行makeOffers()方法 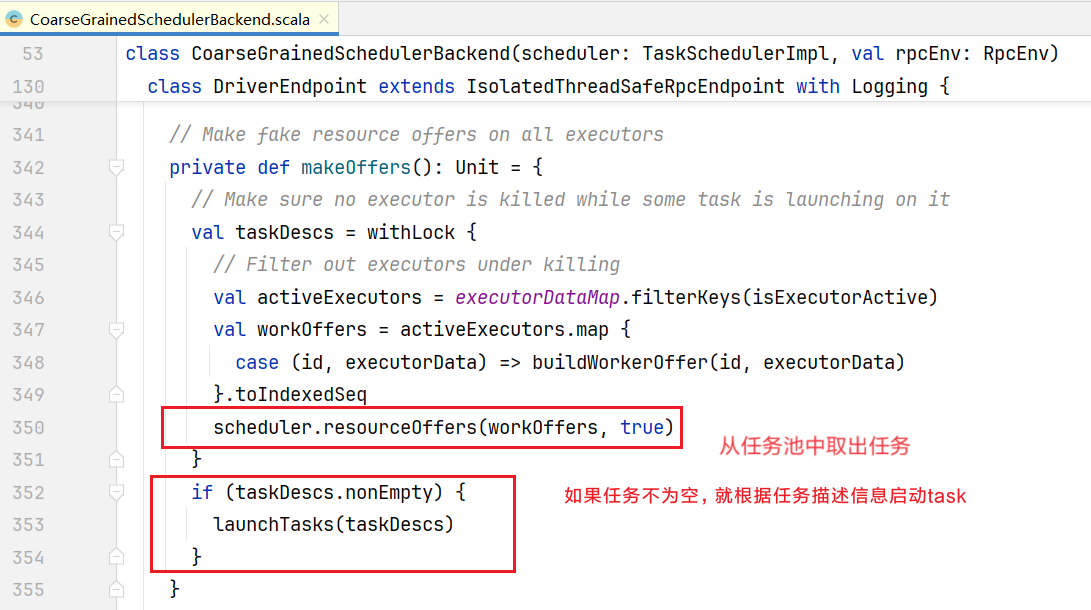 查看取任务resourceOffers()方法:
查看取任务resourceOffers()方法:  点击getSortedTaskSetQueue()方法,可以发现任务集被进行排序后才能取出,而排序逻辑点击进去查看:
点击getSortedTaskSetQueue()方法,可以发现任务集被进行排序后才能取出,而排序逻辑点击进去查看:  排序的时候使用模式匹配,按照之前的策略进行匹配,从而确定谁先执行谁后执行,回到submitTasks(),排序后面进行后面的操作:
排序的时候使用模式匹配,按照之前的策略进行匹配,从而确定谁先执行谁后执行,回到submitTasks(),排序后面进行后面的操作:  给任务集赋予本地化级别后,会进行和Executor的匹配
给任务集赋予本地化级别后,会进行和Executor的匹配  选择具体位置的Executor,会按照如图下面的算法优先匹配:
选择具体位置的Executor,会按照如图下面的算法优先匹配: 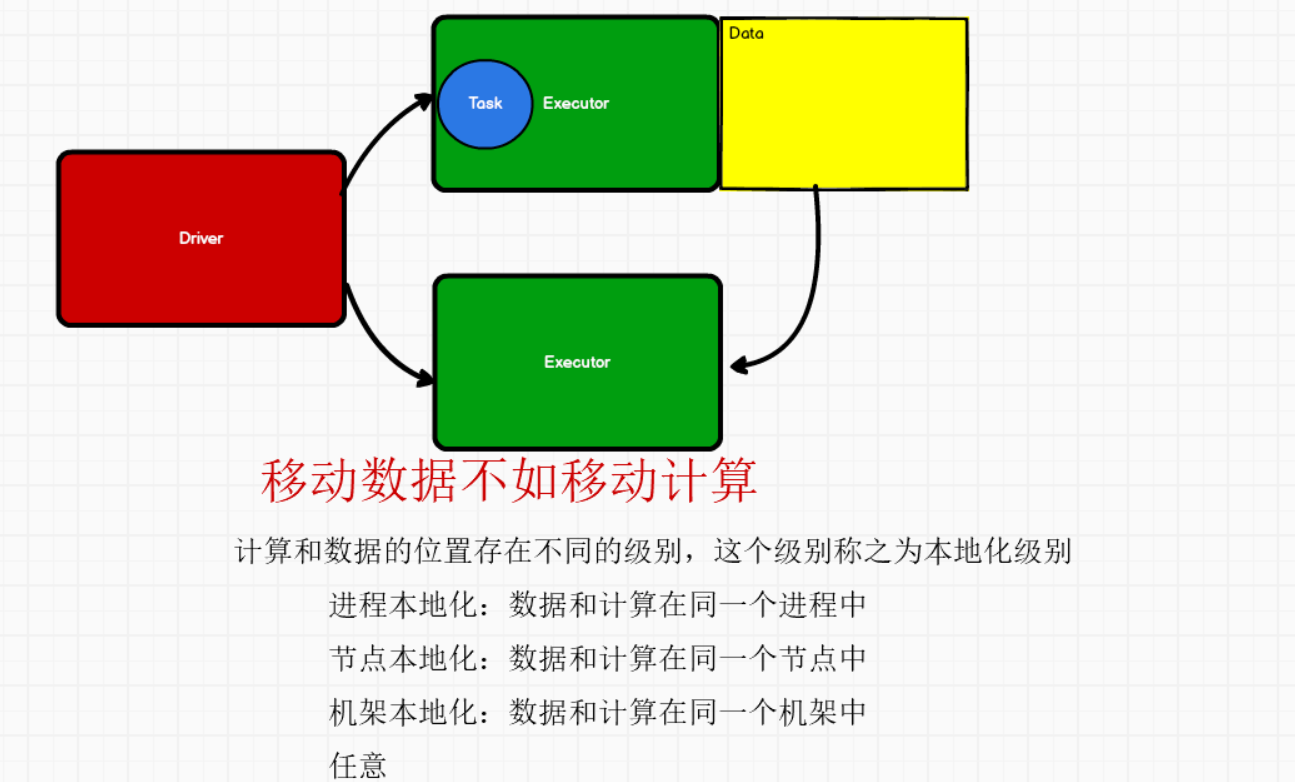 回到CoarseGrainedSchedulerBackend.scala类中makeOffers()方法,取出任务后,就可以执行了:
回到CoarseGrainedSchedulerBackend.scala类中makeOffers()方法,取出任务后,就可以执行了: 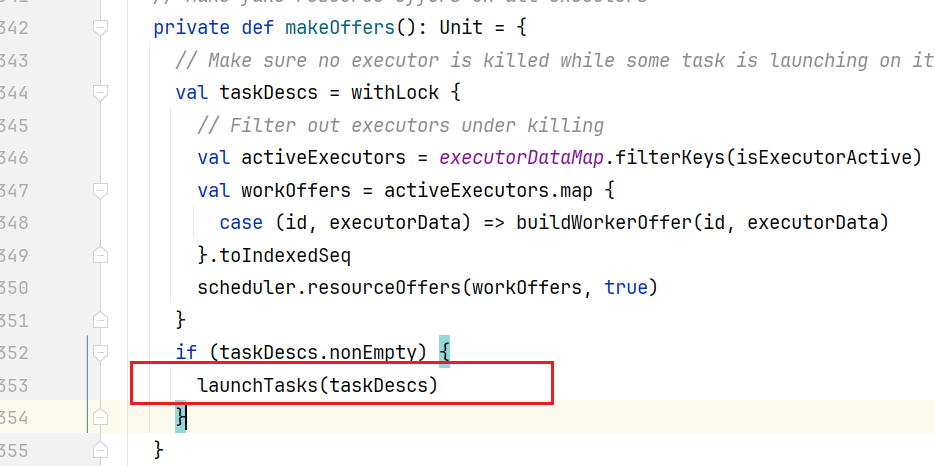 点击进入launchTasks()方法:
点击进入launchTasks()方法:
privatedeflaunchTasks(tasks:Seq[Seq[TaskDescription]]):Unit={
//遍历取出的任务
for(task<-tasks.flatten){
//序列化任务字节码
valserializedTask=TaskDescription.encode(task)
//如果任务超过最大设置数量
if(serializedTask.limit()>=maxRpcMessageSize){
......
}
else{//我们的任务没有超过最大设置数量,执行else
valexecutorData=executorDataMap(task.executorId)
//Doresourcesallocationhere.Theallocatedresourceswillgetreleasedafterthetask
//finishes.
executorData.freeCores-=task.cpus
task.resources.foreach{case(rName,rInfo)=>
assert(executorData.resourcesInfo.contains(rName))
executorData.resourcesInfo(rName).acquire(rInfo.addresses)
}
logDebug(s"Launchingtask${task.taskId}onexecutorid:${task.executorId}hostname:"+
s"${executorData.executorHost}.")
//向对应的executor发送LaunchTask消息,里面包含了序列化的任务
executorData.executorEndpoint.send(LaunchTask(newSerializableBuffer(serializedTask)))
}
}
}##6.任务的执行 executor如果收到LaunchTask消息,查看CoarseGrainedExecutorBackend.scala中receive()方法: 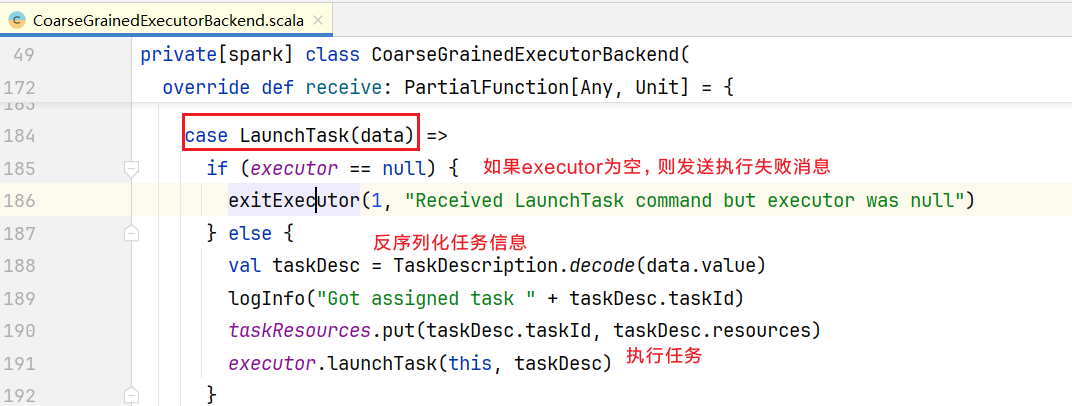 点击launchTask()方法,查询任务执行:
点击launchTask()方法,查询任务执行: 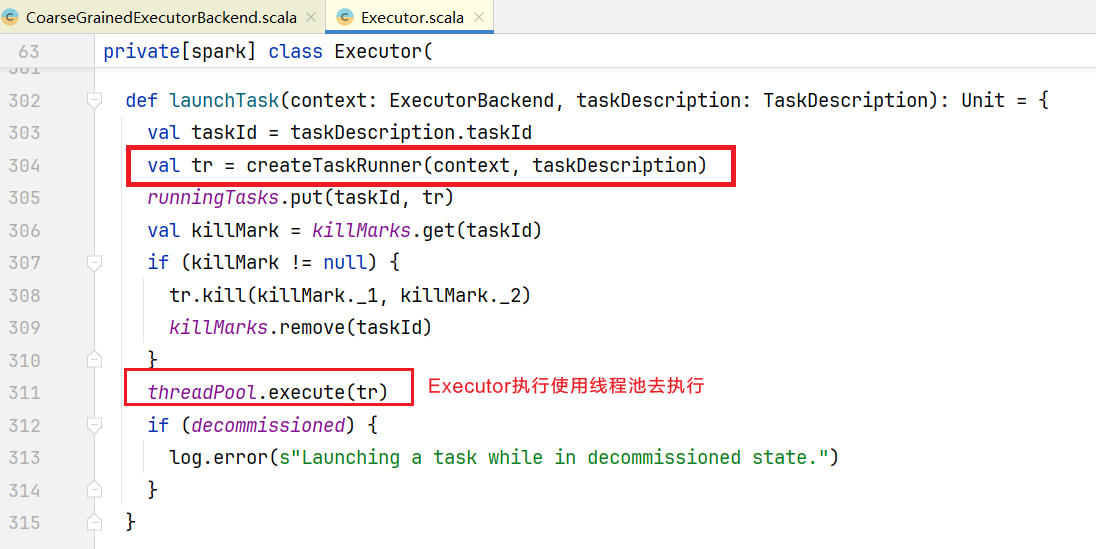 可以看到使用线程池去执行任务,但是我们写的任务代码并没有实现Runable接口或者继承Thread类,点击查看createTaskRunner()方法:
可以看到使用线程池去执行任务,但是我们写的任务代码并没有实现Runable接口或者继承Thread类,点击查看createTaskRunner()方法:
private[executor]defcreateTaskRunner(context:ExecutorBackend,
taskDescription:TaskDescription)=newTaskRunner(context,taskDescription,plugins)点击TaskRunner会发现它就是一个线程类: 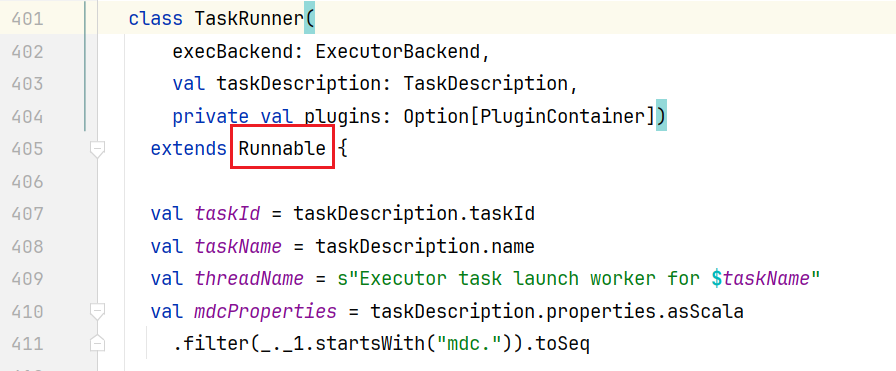 点击进入里面run()方法:
点击进入里面run()方法: 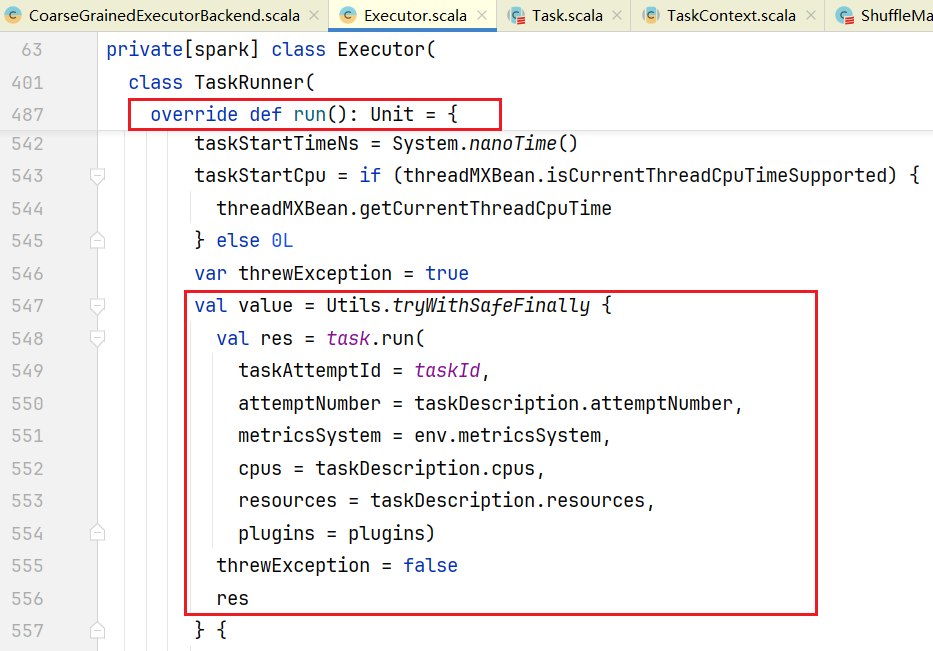 点击task.run()方法,进入Task.scala中:
点击task.run()方法,进入Task.scala中: 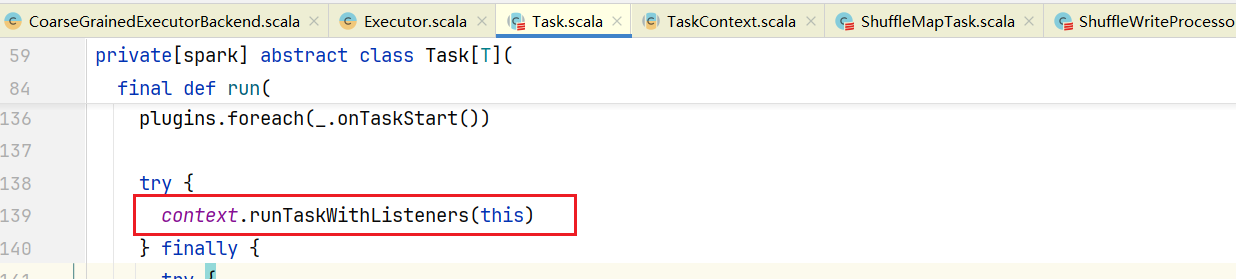 点击进入runTaskWithListeners()方法:
点击进入runTaskWithListeners()方法:  发现是一个抽象方法,选择ShuffleMapTask.scala实现方法:
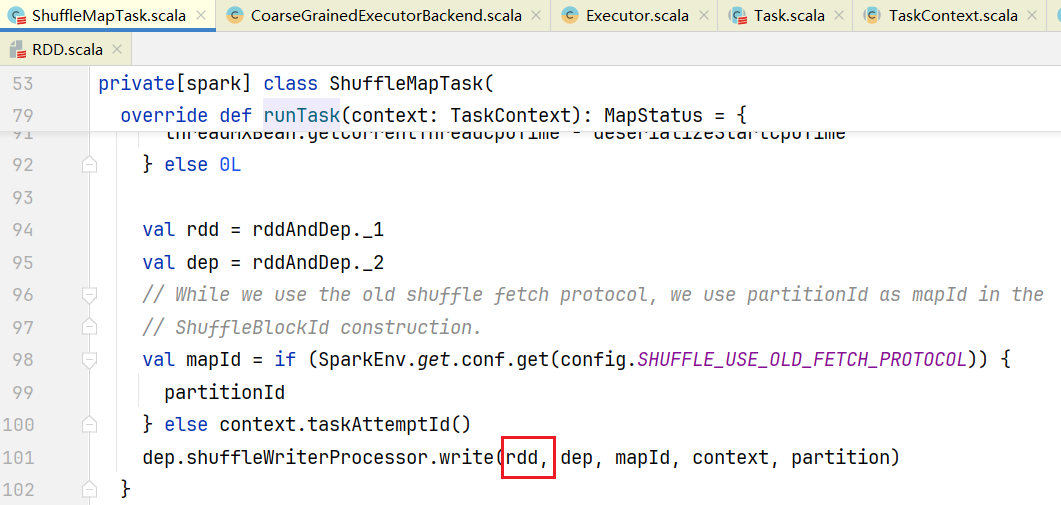
发现是一个抽象方法,选择ShuffleMapTask.scala实现方法: 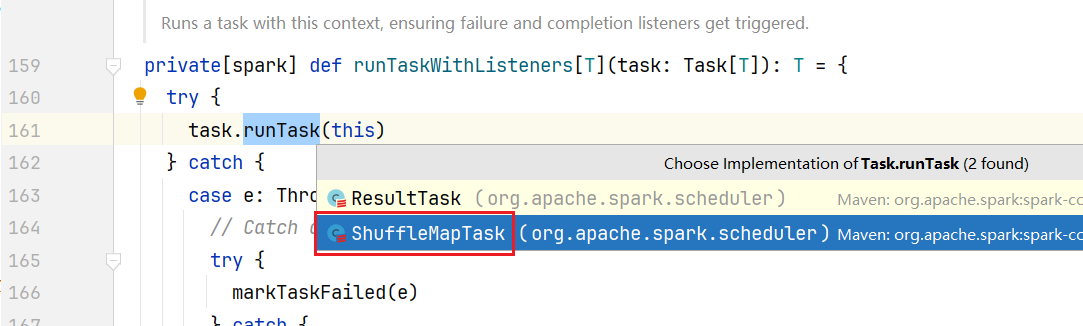 在ShuffleMapTask.scala中,可见其中的write方法使用了我们的rdd,从而完成我们具体代码的计算逻辑。
在ShuffleMapTask.scala中,可见其中的write方法使用了我们的rdd,从而完成我们具体代码的计算逻辑。