RDD编程工程化
前面三个需求开发都是在一个文件中做所有步骤的功能,不利于工作开发。
1. 三层架构
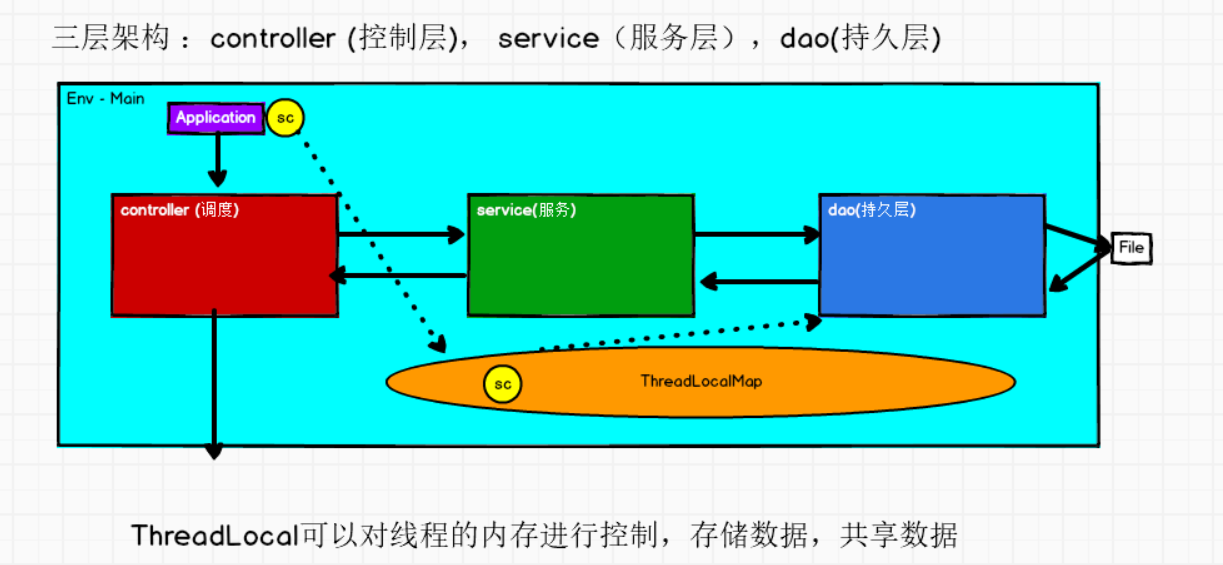
2. 三层架构实操
2.1 新建工程
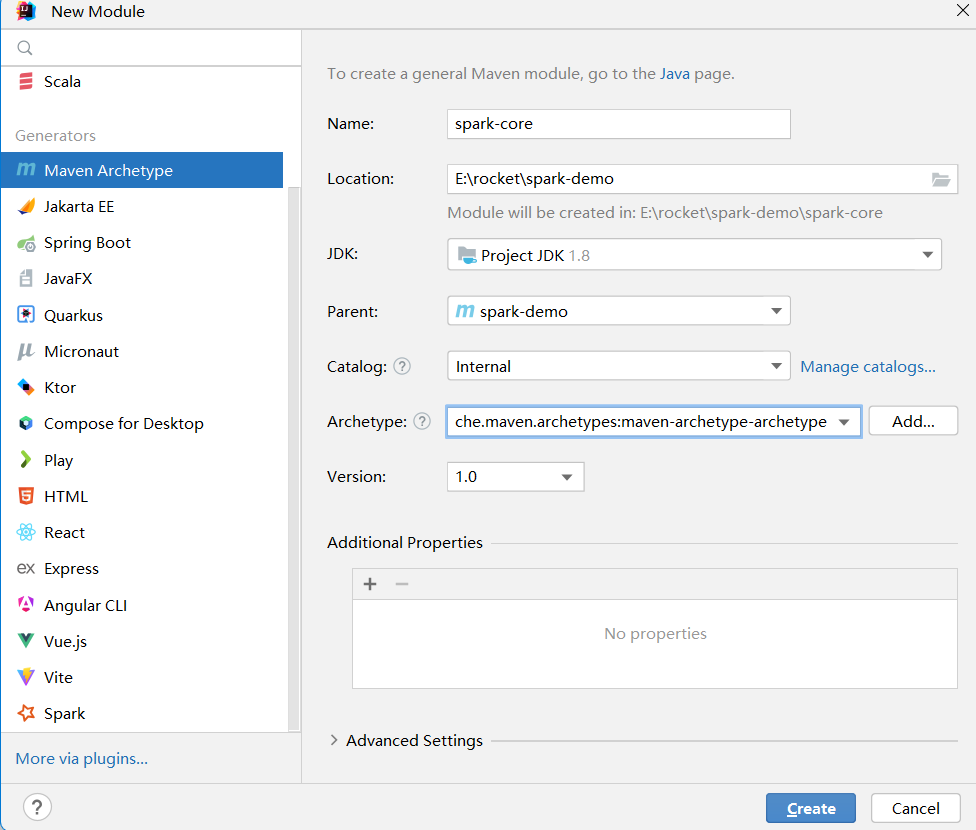
2.2 创建目录
创建包:com.rocket.spark.core.framework,在下面创建如图所示 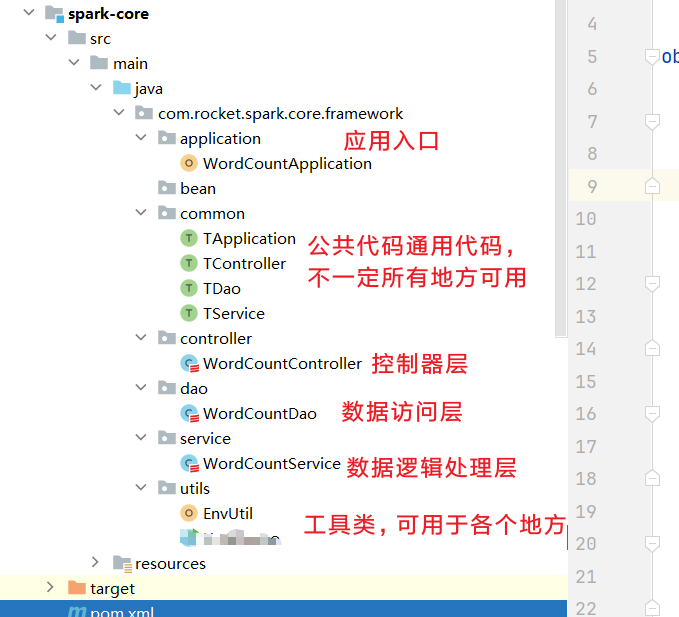
3. 具体代码
3.1 入口类
scala
package com.rocket.spark.core.framework.application
import com.rocket.spark.core.framework.common.TApplication
import com.rocket.spark.core.framework.controller.WordCountController
object WordCountApplication extends App with TApplication{
start(){
val wordCountController = new WordCountController()
wordCountController.dispatch()
}
}3.2 controller层
scala
package com.rocket.spark.core.framework.controller
import com.rocket.spark.core.framework.common.TController
import com.rocket.spark.core.framework.service.WordCountService
class WordCountController extends TController{
private val countService = new WordCountService()
override def dispatch()={
val array: Array[(String, Int)] = countService.analyzer()
array.foreach(println)
}
}3.2 dao层
scala
package com.rocket.spark.core.framework.dao
import com.rocket.spark.core.framework.common.TDao
class WordCountDao extends TDao{
}3.3 service层
scala
package com.rocket.spark.core.framework.service
import com.rocket.spark.core.framework.common.TService
import com.rocket.spark.core.framework.dao.WordCountDao
import org.apache.spark.rdd.RDD
class WordCountService extends TService{
private val wordCountDao = new WordCountDao()
override def analyzer(): Array[(String, Int)]={
val fileRdd: RDD[String] = wordCountDao.readFile("datas/1.txt")
val wordRdd: RDD[(String, Int)] = fileRdd.flatMap(line => {
line.split(" ").map((_, 1)).toList
})
val resultRdd: RDD[(String, Int)] = wordRdd.reduceByKey(_ + _)
val array: Array[(String, Int)] = resultRdd.collect()
array
}
}3.5 common层
scala
package com.rocket.spark.core.framework.common
import com.rocket.spark.core.framework.utils.EnvUtil
import org.apache.spark.{SparkConf, SparkContext}
trait TApplication {
/**
* @param config 利用函数支持配置默认值特性
* @param appName 利用函数支持配置默认值特性
* @param op 使用scala中控制抽象的语法,可以将一段代码传递到函数中,并利用函数参数柯里化,将参数分为要传和不传的分开更加灵活
*/
def start(config: String="local[*]", appName:String="Application")(op: =>Unit)={
// 1. 环境准备
val sparkConf: SparkConf = new SparkConf().setMaster(config).setAppName(appName)
val sc = new SparkContext(sparkConf)
EnvUtil.putSc(sc)
try {
op
}catch {
case ex => ex.printStackTrace()
}
sc.stop()
EnvUtil.clear()
}
}scala
package com.rocket.spark.core.framework.common
trait TController {
// Controller需要实现dispatch
def dispatch={}
}scala
package com.rocket.spark.core.framework.common
import com.rocket.spark.core.framework.utils.EnvUtil
import org.apache.spark.rdd.RDD
trait TDao {
// 将常用的函数提取出来,作为公共代码
def readFile(path: String) = {
val fileRdd: RDD[String] = EnvUtil.getSc().textFile(path)
fileRdd
}
}scala
package com.rocket.spark.core.framework.common
trait TService {
// Service需要实现analyzer
def analyzer(): Any
}3.6 utils层
scala
package com.rocket.spark.core.framework.utils
import org.apache.spark.SparkContext
object EnvUtil {
// 利用整个执行流程都是主线程中执行,从ThreadLocal中提取
// 原理就是利用Thread类有属性为threadLocals进行保存数据,threadLocals是ThreadLocal.ThreadLocalMap内部类,
// ThreadLocalMap里面就维护了一个Entry, key为ThreadLocal实例对象,value为要存的值
private val tl = new ThreadLocal[SparkContext]
def putSc(sc: SparkContext)={
tl.set(sc)
}
def getSc():SparkContext={
tl.get()
}
def clear()={
tl.remove()
}
}