数据读取和保存
Spark SQL提供了通用的API进行保存💾数据和数据加载, 默认读取和保存的文件格式为parquet。
1. 加载数据介绍
spark.read.load是加载数据的通用方法
scala> spark.read.
csv format jdbc json load option options orc parquet schema table text textFile如果读取不同格式的数据,可以对不同的数据格式进行设定
格式为: spark.read.format("…")[.option("…")].load("…")
format("…"): 指定加载的数据类型,包括"csv"、"jdbc"、"json"、"orc"、"parquet"和"textFile"。load("…"): 在"csv"、"jdbc"、"json"、"orc"、"parquet"和"textFile"格式下需要传入加载。option("…"): 在"jdbc"格式下需要传入JDBC相应参数,url、user、password和dbtable 我们前面都是使用read API先把文件加载到DataFrame然后再查询,其实我们也可以直接在文件上进行查询数据的路径:文件格式.文件路径`
提示
Spark SQL的默认数据源为Parquet格式。Parquet是一种能够有效存储嵌套数据的列式存储格式。修改配置项spark.sql.sources.default, 可修改默认数据源格式。
2. 保存数据介绍
df.write.save是保存数据的通用方法
scala> df.write.
bucketBy format jdbc mode options parquet save sortBy
csv insertInto json option orc partitionBy saveAsTable text如果保存不同格式的数据,可以对不同的数据格式进行设定
格式:df.write.format("…")[.option("…")].save("…")
format("…"):指定保存的数据类型,包括"csv"、"jdbc"、"json"、"orc"、"parquet"和"textFile"。save ("…"):在"csv"、"orc"、"parquet"和"textFile"格式下需要传入保存数据的路径。option("…"):在"jdbc"格式下需要传入 JDBC 相应参数,url、user、password和dbtable 保存操作可以使用SaveMode, 用来指明如何处理数据,使用mode()方法来设置。有一点很重要: 这些SaveMode都是没有加锁的, 也不是原子操作。SaveMode是一个枚举类,其中的常量包括:
| Scala/Java | Any Language | Meaning |
|---|---|---|
| SaveMode.ErrorIfExists(default) | "error"(default) | 如果文件已经存在则抛出异常 |
| SaveMode.Append | "append" | 如果文件已经存在则追加 |
| SaveMode.Overwrite | "overwrite" | 如果文件已经存在则覆盖 |
| SaveMode.Ignore | "ignore" | 如果文件已经存在则忽略 |
将读取的文件写到output目录:
# 保存为parquet格式, 追加模式将在目录下额外生成parquet文件
scala> df.write.mode("append").json("/opt/module/data/output")3. 读取文件实操
3.1 读取parquet文件
scala> val df = spark.read.load("../examples/src/main/resources/users.parquet")
df: org.apache.spark.sql.DataFrame = [name: string, favorite_color: string ... 1 more field]
scala> df.show
+------+--------------+----------------+
| name|favorite_color|favorite_numbers|
+------+--------------+----------------+
|Alyssa| null| [3, 9, 15, 20]|
| Ben| red| []|
+------+--------------+----------------+3.2 读取非parquet文件
## 使用format可以指定读取文件类型
scala> val df = spark.read.format("json").load("../examples/src/main/resources/people.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
scala> df.show
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
## 还可以使用对应类型的函数读取指定文件
scala> spark.read.orc("../examples/src/main/resources/users.orc").show
+------+--------------+----------------+
| name|favorite_color|favorite_numbers|
+------+--------------+----------------+
|Alyssa| null| [3, 9, 15, 20]|
| Ben| red| []|
+------+--------------+----------------+
## 可以sql直接读取json文件,内部会按照指定格式去解析
scala> spark.sql("select * from json.`examples/src/main/resources/employees.json`").show
+-------+------+
| name|salary|
+-------+------+
|Michael| 3000|
| Andy| 4500|
| Justin| 3500|
| Berta| 4000|
+-------+------+
## 读取csv文件,需要配置读取规则
scala> spark.read.format("csv").option("sep", ";").option("inferSchema", "true").option("header","true").load("../examples/src/main/resources/people.csv").show
+-----+---+---------+
| name|age| job|
+-----+---+---------+
|Jorge| 30|Developer|
| Bob| 32|Developer|
+-----+---+---------+4. 读写MySQL数据
4.1 在Shell中读取数据库
Spark SQL可以通过JDBC从关系型数据库中读取数据的方式创建DataFrame,如果使用spark-shell操作,可在启动shell时指定相关的数据库驱动路径或者将相关的数据库驱动放到spark的类路径下。
./bin/spark-shell --jars /opt/software/mysql-connector-java-5.1.47.jar
val jdbcUrl = "jdbc:mysql://hadoop102:3306/gmall?useSSL=false"
val connectionProperties = new java.util.Properties()
connectionProperties.put("user", "root")
connectionProperties.put("password", "123456")
connectionProperties.put("driver", "com.mysql.jdbc.Driver")
scala> val df = spark.read.jdbc(jdbcUrl, "activity_info", connectionProperties).show
+---+----------------+-------------+-------------+-------------------+-------------------+-------------------+
| id| activity_name|activity_type|activity_desc| start_time| end_time| create_time|
+---+----------------+-------------+-------------+-------------------+-------------------+-------------------+
| 1|联想品牌优惠活动| 2201| 满减活动 |2020-02-27 17:11:09|2020-02-29 17:11:12|2020-02-27 17:11:16|
+---+----------------+-------------+-------------+-------------------+-------------------+-------------------+4.2 在代码中读写数据库
- 添加依赖
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.33</version>
</dependency>- 读写数据
package com.rocket.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
import java.util.Properties
object SparkSQLMySQL {
case class Province(id:Long, name:String, region_id: String, area_code:String, iso_code:String)
def main(args: Array[String]): Unit = {
//创建上下文环境配置对象
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQLBasic")
val session = SparkSession.builder().config(conf).getOrCreate()
import session.implicits._
//方式 1:通用的 load 方法读取
session.read.format("jdbc")
.option("url", "jdbc:mysql://hadoop102:3306/gmall?userSSL=false")
.option("driver", "com.mysql.cj.jdbc.Driver")
.option("user", "root")
.option("password", "123456")
.option("prepareQuery", "WITH t AS (select * from activity_info)")
.option("query", "select * from t")
.load().show
//方式 2:通用的 load 方法读取 参数另一种形式
session.read.format("jdbc")
.options(Map("url"->"jdbc:mysql://hadoop102:3306/gmall?userSSL=false&user=root&password=123456",
"dbtable"->"activity_info","driver"->"com.mysql.cj.jdbc.Driver"))
.load().show(1) // 查询第1条
//方式 3:使用 jdbc 方法读取
val props: Properties = new Properties()
props.setProperty("user", "root")
props.setProperty("password", "123456")
props.setProperty("driver", "com.mysql.cj.jdbc.Driver")
val df1: DataFrame = session.read.jdbc("jdbc:mysql://hadoop102:3306/gmall?userSSL=false", "base_province", props)
val list: List[Province] = df1.as[Province].collect().toList
list.take(10).foreach(println)
// 写数据
df1.write.mode(SaveMode.Append).jdbc("jdbc:mysql://hadoop102:3306/gmall?userSSL=false", "base_province2", props)
val configMap: Map[String, String] = Map("url" -> "jdbc:mysql://hadoop102:3306/gmall?userSSL=false&user=root&password=123456",
"user" -> "root", "driver" -> "com.mysql.cj.jdbc.Driver")
// 执行更新操作会报错,视图是不能更新的
df1.createTempView("base_province2")
session.sql("update base_province2 set name='北京2' where id=1", configMap).write
session.sql("select * from base_province2 where name='北京2' ", configMap).show()
session.stop()
}
}执行结果: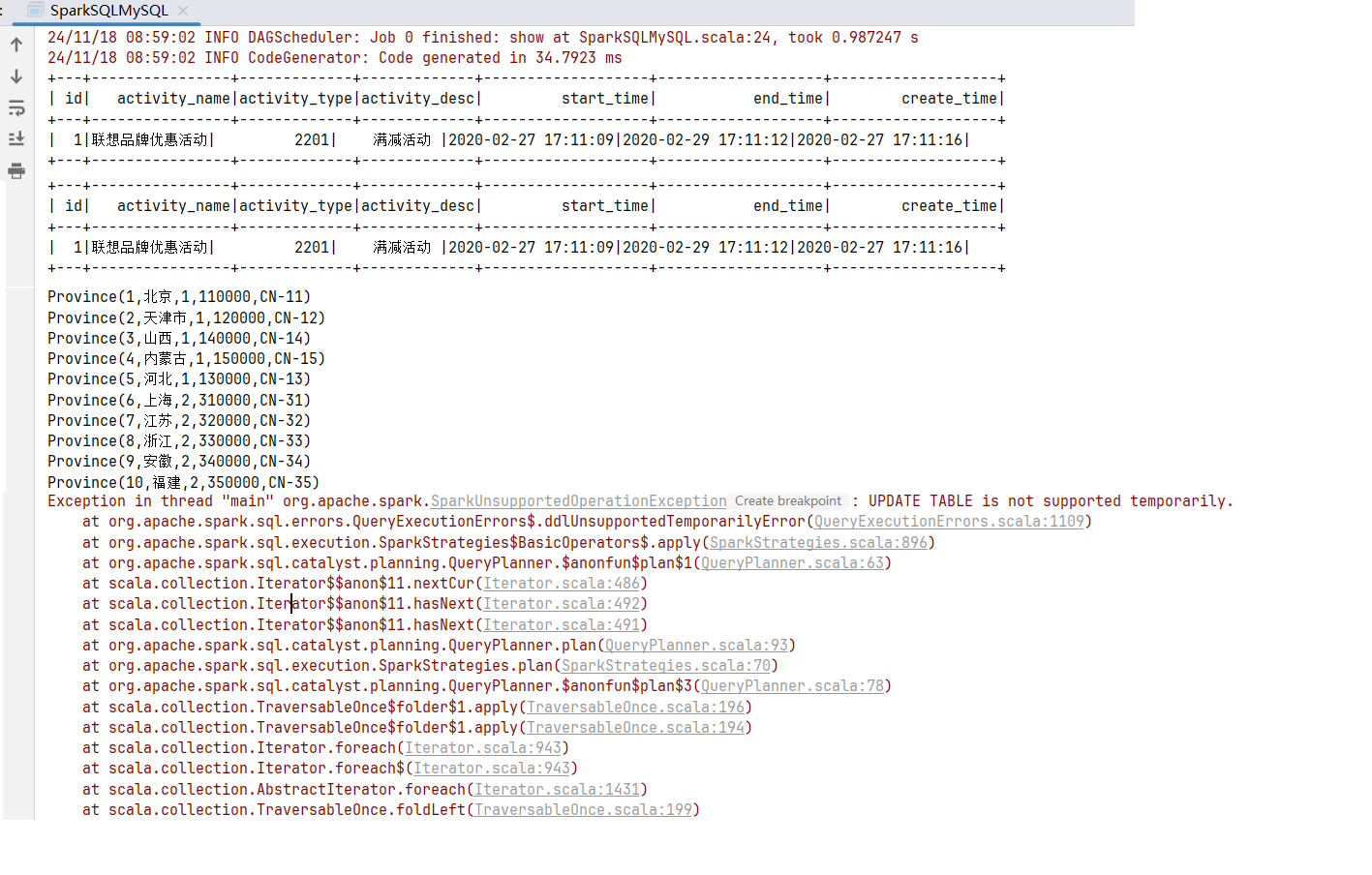 查看数据表,发现已经有了base_province2:
查看数据表,发现已经有了base_province2: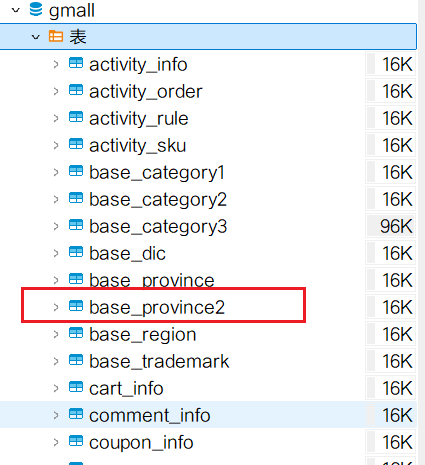
提示
Spark不支持直接更新数据,你可以先读取数据在写回
5. 读写Hive数据
Spark连接Hive有两种方式:内置Hive和外连接Hive库
5.1 内嵌的HIVE
如果使用Spark内嵌的Hive, 可以直接使用。内置Hive的元数据存储在derby中,默认仓库地址:$SPARK_HOME/spark-warehouse。
scala> spark.sql("show tables").show
+---------+---------+-----------+
|namespace|tableName|isTemporary|
+---------+---------+-----------+
+---------+---------+-----------+Spark会在conf目录查找Hive的相关配置,如果没有将会在$SPARK_HOME下面创建metastore_db文件夹存放元数据信息,并开始使用内置Hive。
scala> val df = spark.read.json("examples/src/main/resources/employees.json")
df: org.apache.spark.sql.DataFrame = [name: string, salary: bigint]
scala> df.createOrReplaceTempView("user")
## 内置Hive里面有一张临时视图
scala> spark.sql("show tables;").show
+---------+---------+-----------+
|namespace|tableName|isTemporary|
+---------+---------+-----------+
| | user| true|
+---------+---------+-----------+- 内置Hive也支持建表,和插入数据到表中
# 创建表data1
scala> spark.sql("create table data1(id int)")
24/11/18 12:12:14 WARN ResolveSessionCatalog: A Hive serde table will be created as there is no table provider specified. You can set spark.sql.legacy.createHiveTableByDefault to false so that native data source table will be created instead.
res7: org.apache.spark.sql.DataFrame = []
## 在$SPARK_HOME/data下面创建data1.txt文件
scala> spark.sql("load data local inpath 'data/data1.txt' into table data1")
res10: org.apache.spark.sql.DataFrame = []
## 可以看到data1表不是临时表
scala> spark.sql("show tables;").show
+---------+---------+-----------+
|namespace|tableName|isTemporary|
+---------+---------+-----------+
| default| data1| false|
| | user| true|
+---------+---------+-----------+数据导入后,Spark会创建文件夹$SPARK_HOME/spark-warehouse 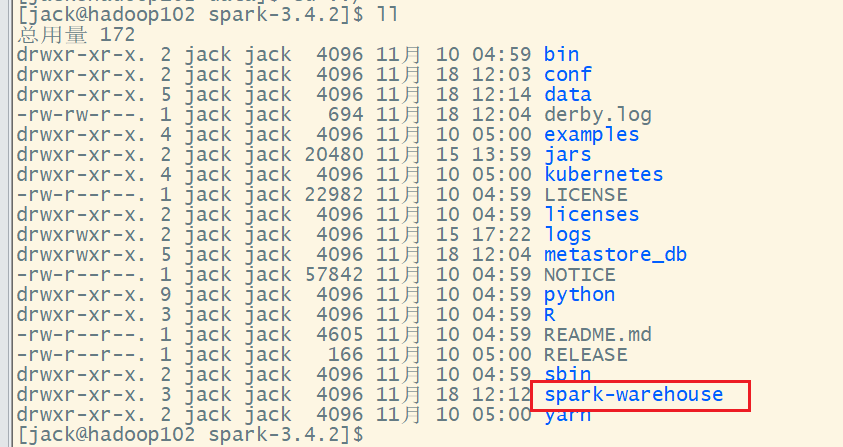 进入文件夹spark-warehouse,可以看到data1文件夹和data1.txt
进入文件夹spark-warehouse,可以看到data1文件夹和data1.txt
[jack@hadoop103 spark-3.4.2]$ cd spark-warehouse/
[jack@hadoop103 spark-warehouse]$ ll
总用量 4
drwxr-xr-x. 2 jack jack 4096 11月 18 12:16 data1
[jack@hadoop103 spark-warehouse]$ cd data1/
[jack@hadoop103 data1]$ ll
总用量 4
-rwxr-xr-x. 1 jack jack 9 11月 18 12:16 data1.txt由于不是临时表,可以直接查询表数据
scala> spark.sql("select * from data1").show
+---+
| id|
+---+
| 1|
| 2|
| 37|
| 8|
+---+5.2 命令行访问外置Hive
如果想连接外部已经部署好的Hive,需要通过以下几个步骤:
Spark要接管Hive需要把hive-site.xml拷贝到conf/目录下
- 把Mysql驱动复制到jars/目录下
- 如果访问不到hdfs,则需要把core-site.xml和hdfs-site.xml拷贝到conf/目录下
- 重启spark-shell
通过spark-shell访问Hive:
scala> spark.sql("show tables").show
+---------+---------+-----------+
|namespace|tableName|isTemporary|
+---------+---------+-----------+
| default| stu| false|
| default| student| false|
+---------+---------+-----------+
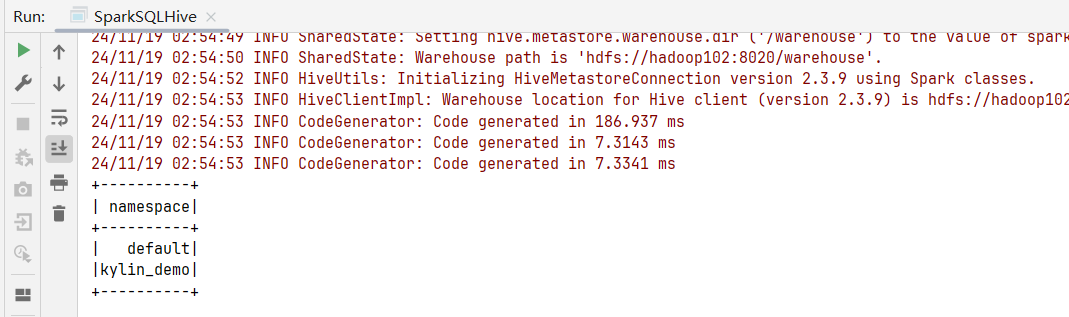
scala> spark.sql("show databases").show
+----------+
| namespace|
+----------+
| default|
|kylin_demo|
+----------+提示
默认官方下载的Spark3二进制版本支持连接的Hive版本为2.3.9,如果需要连接外置Hive3.x, 需要下载Spark源码加入Hive3.x依赖支持进行手动编辑打包。
5.2 spark-sql访问外置Hive
Spark SQL CLI可以很方便的在本地运行Hive元数据服务以及从命令行执行查询任务,可以直接执行SQL语句。
scala> [jack@hadoop103 spark-3.4.2]$ ./bin/spark-sql
spark-sql (default)> show tables;
stu
student
Time taken: 3.276 seconds, Fetched 2 row(s)
spark-sql (default)> use kylin_demo;
Time taken: 0.09 seconds
spark-sql (kylin_demo)> show tables;
emp
dept
Time taken: 0.126 seconds, Fetched 2 row(s)查询出来结果不太好看,没有窗格线。
5.3 Spark beeline访问外置Hive
Spark提供Thrift Server无缝兼容HiveServer2, 它是Spark社区基于HiveServer2实现的一个Thrift服务。Spark Thrift Server的接口和协议都和HiveServer2完全一致,它可以和Hive Metastore进行交互,获取到Hive的元数据。Spark还在在bin目录下面提供beeline客户端去访问Spark Thrift Server, 实现和HiveServer2一致的功能。
如果想连接Thrift Server,需要通过以下几个步骤:
- Spark要接管Hive需要把hive-site.xml 拷贝到conf/目录下
- 把Mysql的驱动copy到jars/目录下
- 如果访问不到hdfs,则需要把core-site.xml 和hdfs-site.xml拷贝到conf/目录下
- 启动Thrift Server
[jack@hadoop103 spark-3.4.2]$ ./sbin/start-thriftserver.sh
starting org.apache.spark.sql.hive.thriftserver.HiveThriftServer2, logging to /opt/module/spark-3.4.2/logs/spark-jack-org.apache.spark.sql.hive.thriftserver.HiveThriftServer2-1-hadoop103.out- 使用beeline连接Thrift Server
[jack@hadoop103 spark-3.4.2]$ ./bin/beeline -u jdbc:hive2://hadoop102:10000 -n jack
Connecting to jdbc:hive2://hadoop102:10000
Connected to: Apache Hive (version 4.0.1)
Driver: Hive JDBC (version 2.3.9)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 2.3.9 by Apache Hive
0: jdbc:hive2://hadoop102:10000> show tables;
INFO : Compiling command(queryId=jack_20241119025106_fc84247a-71a9-4191-808d-f772b6573c65): show tables
INFO : Semantic Analysis Completed (retrial = false)
INFO : Created Hive schema: Schema(fieldSchemas:[FieldSchema(name:tab_name, type:string, comment:from deserializer)], properties:null)
INFO : Completed compiling command(queryId=jack_20241119025106_fc84247a-71a9-4191-808d-f772b6573c65); Time taken: 0.018 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=jack_20241119025106_fc84247a-71a9-4191-808d-f772b6573c65): show tables
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=jack_20241119025106_fc84247a-71a9-4191-808d-f772b6573c65); Time taken: 0.069 seconds
+-----------+
| tab_name |
+-----------+
| stu |
| student |
+-----------+
2 rows selected (0.297 seconds)5.3 代码中访问外置Hive
- 导入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.4.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.27</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.3</version>
</dependency>- 将hive-site.xml文件拷贝到项目的resources目录中
package com.rocket.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
object SparkSQLHive {
case class Province(id:Long, name:String, region_id: String, area_code:String, iso_code:String)
def main(args: Array[String]): Unit = {
//创建上下文环境配置对象
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQLBasic")
// 创建数据库默认是在本地仓库, 需要指向HDFS
conf.set("spark.sql.warehouse.dir", "hdfs://hadoop102:8020/user/hive/warehouse")
// 添加Hive功能特性支持
val session = SparkSession.builder().enableHiveSupport().config(conf).getOrCreate()
session.sql("show databases").show()
session.stop()
}
}执行结果: