IDEA开发SparkSQL
实际开发中,都是使用IDEA进行开发的。
1. 环境准备
1. 添加依赖
xml
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.4.2</version>
</dependency>1.2 添加数据
在datas目录下新建user.json文件
json
{"name": "jack", "age": 12}
{"name": "tom", "age": 22}
{"name": "zhangsan", "age": 16}2. 读取文件并作查询
编写SparkSQLBasic类
sh
package com.rocket.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, SparkSession}
object SparkSQLBasic {
def main(args: Array[String]): Unit = {
//创建上下文环境配置对象
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQLBasic")
val spark = SparkSession.builder().config(conf).getOrCreate()
val df: DataFrame = spark.read.json("datas/user.json")
//SQL 风格语法
df.createTempView("user")
session.sql("select name, age from user limit 1").show
session.sql("select avg(age) from user").show
// 使用DSL
df.select("name").show
// 如果涉及到转换操作,需要引入隐式转换规则, 这里并不是导包
import session.implicits._
df.select($"age"+1).show
session.stop()
spark.stop()
}
}执行结果, 和命令行执行差不多: 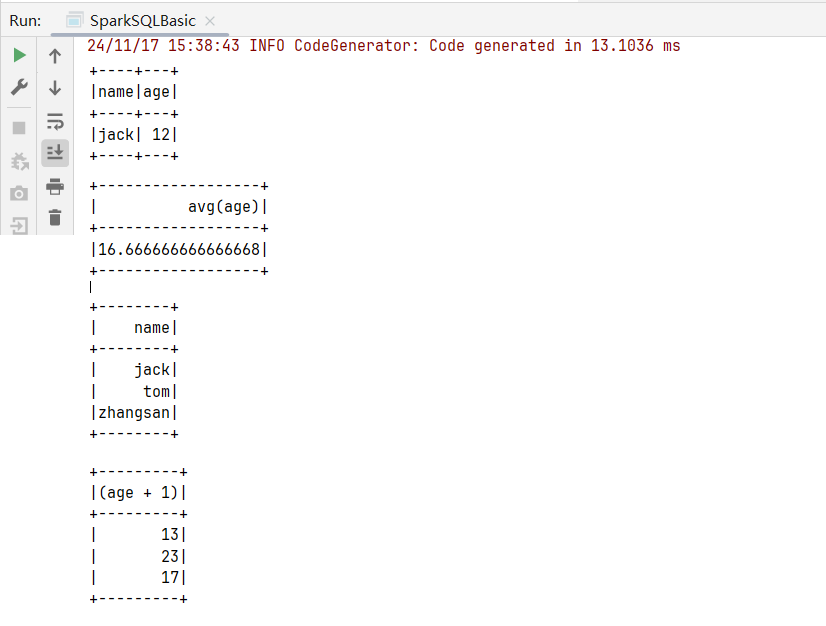
3. RDD、DataFrame、DataSet转换
新建SparkSQLTransform
scala
object SparkSQLTransform {
case class Person(id: Int, name: String, age:Int)
def main(args: Array[String]): Unit = {
//创建上下文环境配置对象
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQLBasic")
val session = SparkSession.builder().config(conf).getOrCreate()
import session.implicits._
val rdd1: RDD[(Int, String, Int)] = session.sparkContext.makeRDD(List((1, "zhangsan", 30), (2, "lisi", 25)))
// RDD <=> DataFrame
val df1: DataFrame = rdd1.toDF("id", "name", "age")
// 得到rdd, 但是类型变成了ROW, 从rdd中解析数据不太方便
val rdd2: RDD[Row] = df1.rdd
// DataFrame <=> Dataset
val ds: Dataset[Person] = df1.as[Person]
val df2: DataFrame = ds.toDF()
// RDD <=> Dataset
val ds2: Dataset[Person] = rdd1.map {
case (id, name, age) => Person(id, name, age)
}.toDS()
val rdd3: RDD[Person] = ds2.rdd
session.stop()
}
}