Spark内核源码之SparkSubmit
1. Spark运行流程总览
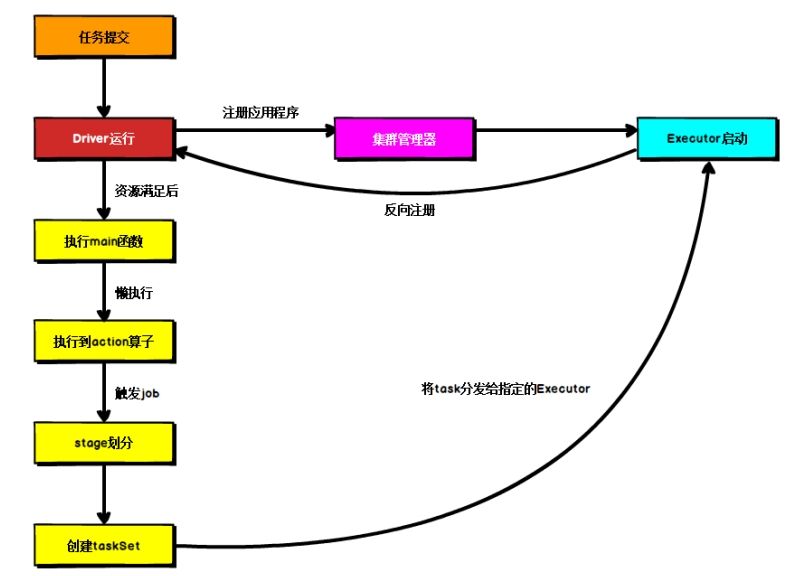 这个流程是按照如下的核心步骤进行工作的:
这个流程是按照如下的核心步骤进行工作的:
- 任务提交后,都会先启动Driver程序;
- 随后Driver向集群管理器注册应用程序;
- 之后集群管理器根据此任务的配置文件分配Executor并启动;
- Driver开始执行main函数,Spark查询为懒执行,当执行到Action算子时开始反向推算,根据宽依赖进行Stage的划分,随后每一个Stage对应一个Taskset,Taskset中有多个Task,查找可用资源Executor进行调度;
- 根据本地化原则,Task会被分发到指定的Executor去执行,在任务执行的过程中,Executor也会不断与Driver进行通信,报告任务运行情况。
2. 作业提交入口
- spark-shell脚本中:

- spark-submit脚本中:
 可以看到程序入口是org.apache.spark.deploy.SparkSubmit类中的伴生对象
可以看到程序入口是org.apache.spark.deploy.SparkSubmit类中的伴生对象  程序解析输入的命令行参数:
程序解析输入的命令行参数:submit.doSubmit(args):
scala
def doSubmit(args: Array[String]): Unit = {
// Initialize logging if it hasn't been done yet. Keep track of whether logging needs to
// be reset before the application starts.
val uninitLog = initializeLogIfNecessary(true, silent = true)
// 解析命令行参数
val appArgs = parseArguments(args)
if (appArgs.verbose) {
logInfo(appArgs.toString)
}
// 模式匹配执行Spark的行为
appArgs.action match {
case SparkSubmitAction.SUBMIT => submit(appArgs, uninitLog)
case SparkSubmitAction.KILL => kill(appArgs)
case SparkSubmitAction.REQUEST_STATUS => requestStatus(appArgs)
case SparkSubmitAction.PRINT_VERSION => printVersion()
}
}3. 命令参数解析
在SparkSubmit.scala中98行,封装SparkSubmitArguments对象,里面对参数解析
scala
protected def parseArguments(args: Array[String]): SparkSubmitArguments = {
new SparkSubmitArguments(args)
}SparkSubmitArguments.scala中第110行负责解析参数  里面使用正则表达式匹配解析得到参数
里面使用正则表达式匹配解析得到参数  参数最后交给SparkSubmitArguments.scala进行封装
参数最后交给SparkSubmitArguments.scala进行封装 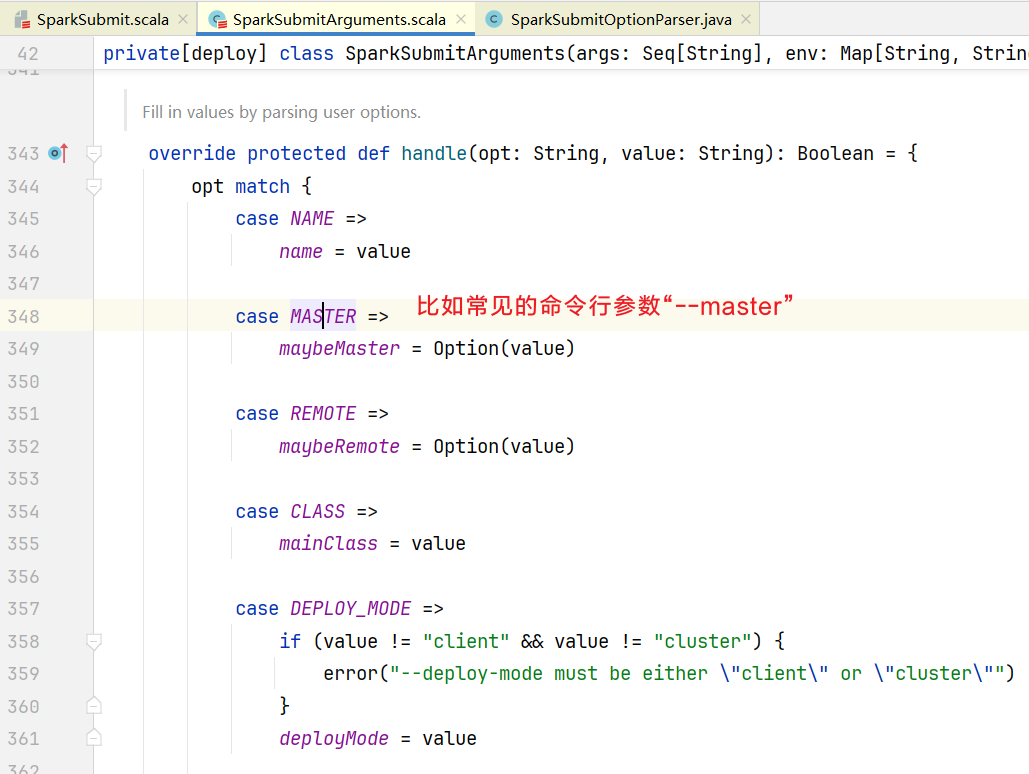 当然也要解析Action参数, 如果没有Action默认就是Submit:
当然也要解析Action参数, 如果没有Action默认就是Submit: 
3. 按照Action参数程序执行
回到SparkSubmit.scala中程序会判断submit会执行submit()方法: 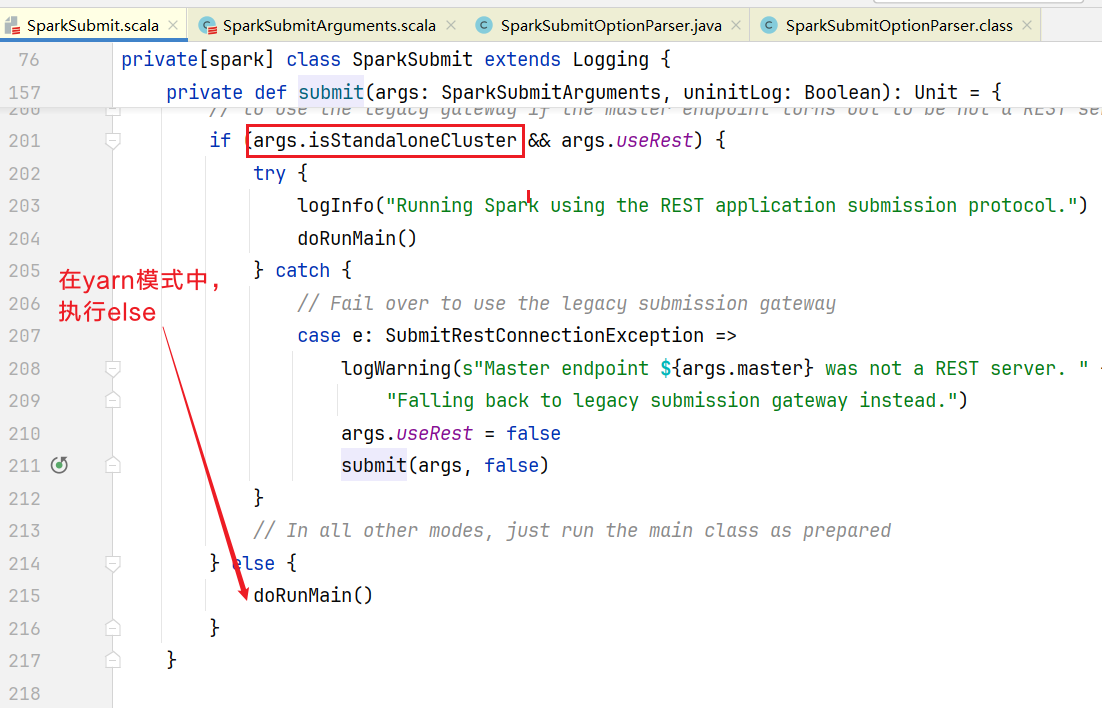 执行doRunMain()方法, 由于没有传代理用户参数,走else执行runMain():
执行doRunMain()方法, 由于没有传代理用户参数,走else执行runMain():
scala
def doRunMain(): Unit = {
if (args.proxyUser != null) {
......
} else {
// 执行主函数
runMain(args, uninitLog)
}
}在SparkSubmit.scala第954行runMain()方法中,先做提交环境准备:
scala
private def runMain(args: SparkSubmitArguments, uninitLog: Boolean): Unit = {
// 提交环境准备,其中childMainClass会在代码后面生成构造对象实例
val (childArgs, childClasspath, sparkConf, childMainClass) = prepareSubmitEnvironment(args)
......
var mainClass: Class[_] = null
try {
mainClass = Utils.classForName(childMainClass)
} catch {
......
}
// 如果是继承SparkApplication则通过反射,否则通过new方法创建对象app
val app: SparkApplication = if (classOf[SparkApplication].isAssignableFrom(mainClass)) {
mainClass.getConstructor().newInstance().asInstanceOf[SparkApplication]
} else {
new JavaMainApplication(mainClass)
}
......
try {
app.start(childArgs.toArray, sparkConf)
} catch {
case t: Throwable =>
throw findCause(t)
} finally {
if (args.master.startsWith("k8s") && !isShell(args.primaryResource) &&
!isSqlShell(args.mainClass) && !isThriftServer(args.mainClass) &&
!isConnectServer(args.mainClass)) {
try {
SparkContext.getActive.foreach(_.stop())
} catch {
case e: Throwable => logError(s"Failed to close SparkContext: $e")
}
}
}
}childMainClass在yarn环境中,默认会是org.apache.spark.deploy.yarn.YarnClusterApplication 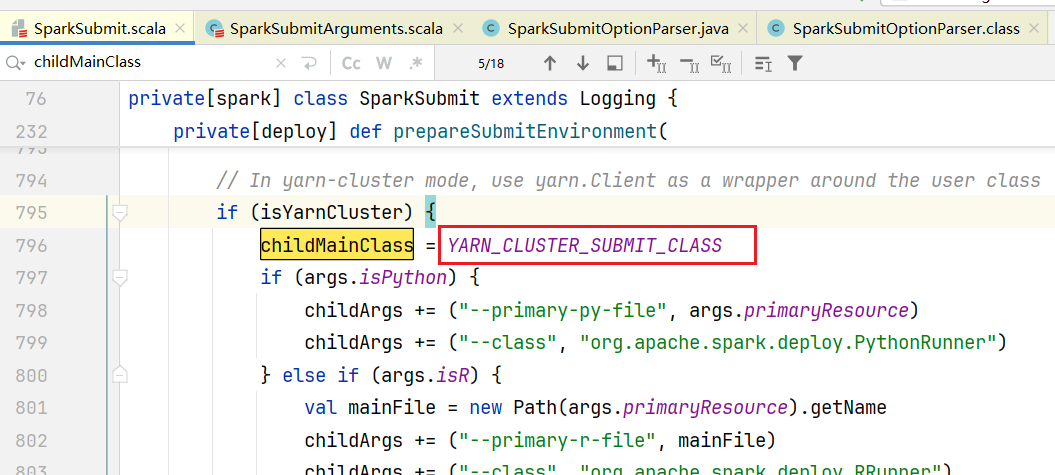 添加yarn依赖
添加yarn依赖
xml
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-yarn_2.12</artifactId>
<version>3.4.2</version>
</dependency>在Client.scala中可以看到YarnClusterApplication是继承了SparkApplication的,里面定义了start方法 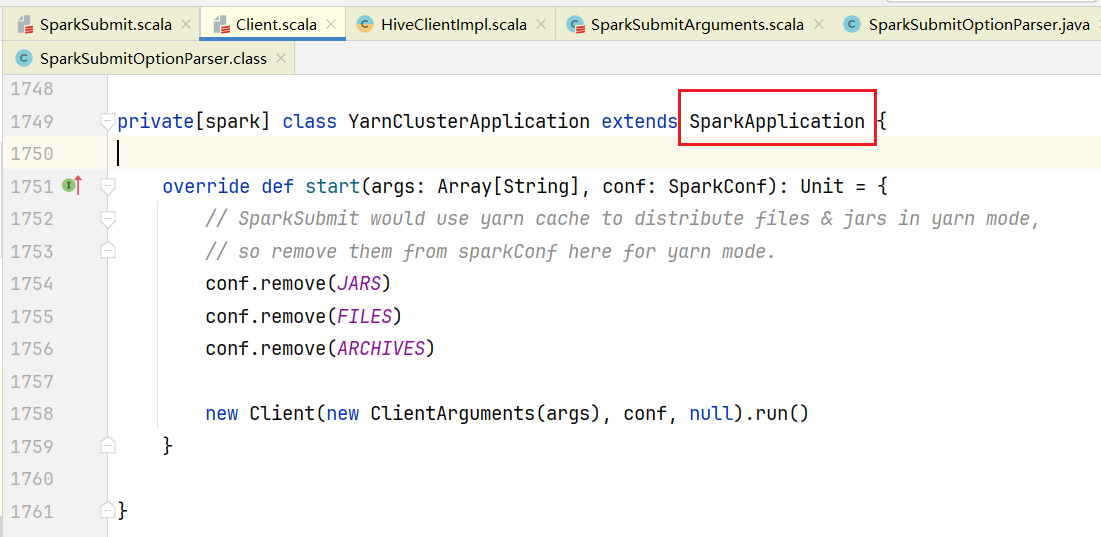
4. 执行start方法
start()方法中创建了Client对象, 进入源码Client类中发现有yarnClient属性: 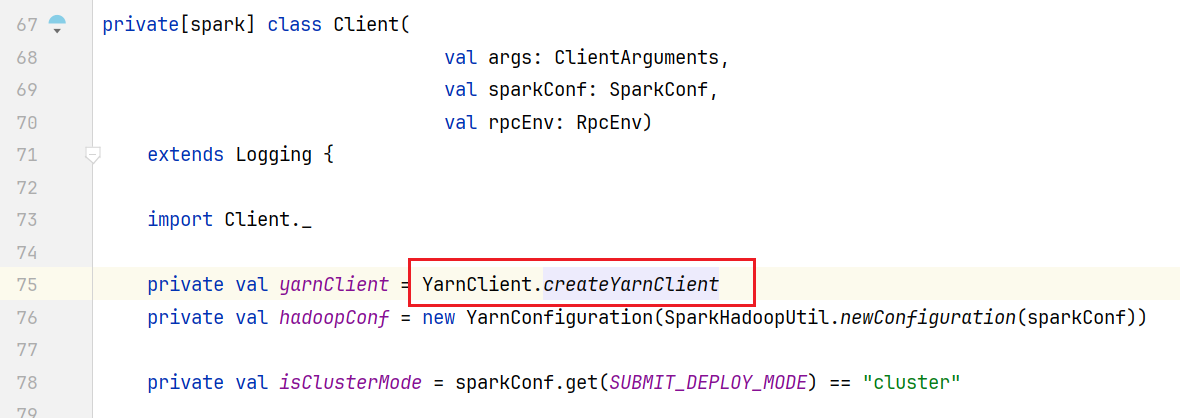
底层使用的YarnClientImpl类
java
public static YarnClient createYarnClient() {
YarnClient client = new YarnClientImpl();
return client;
}其中rmClient就是资源调度节点ResourceMananger节点的客户端对象 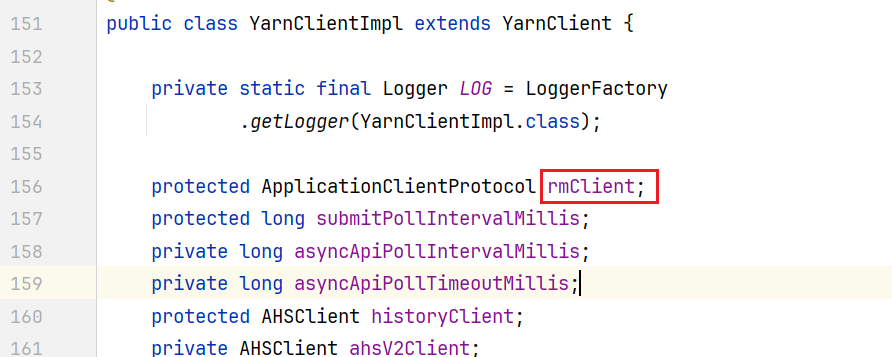 回到Client.scala中,Client类执行run()方法
回到Client.scala中,Client类执行run()方法
scala
def run(): Unit = {
// 任务提交
submitApplication()
// 省略任务监控代码
.......
}在submitApplication()方法中
scala
def submitApplication(): Unit = {
ResourceRequestHelper.validateResources(sparkConf)
try {
launcherBackend.connect()
yarnClient.init(hadoopConf)
// yarn客户端启动,和yarn集群建立连接
yarnClient.start()
// 向yarn请求创建容器
val newApp = yarnClient.createApplication()
val newAppResponse = newApp.getNewApplicationResponse()
// 创建好之后会得到全局唯一id
this.appId = newAppResponse.getApplicationId()
......
// 创建启动容器上下文,里面包含命令行参数
val containerContext = createContainerLaunchContext()
// 创建应用上下文环境,生成应用名称,优先级,内存大小等信息
val appContext = createApplicationSubmissionContext(newApp, containerContext)
// Finally, submit and monitor the application
logInfo(s"Submitting application $appId to ResourceManager")
// 提交容器上下文环境
yarnClient.submitApplication(appContext)
launcherBackend.setAppId(appId.toString)
reportLauncherState(SparkAppHandle.State.SUBMITTED)
} catch {
......
}进入createContainerLaunchContext()方法 