DStream创建
创建DStream有很多方式,常见的有RDD队列,自定义数据源方式和Kafka。
1. RDD队列
1.1 用法和说明
主要用来测试,可以通过使用ssc.queueStream(queueOfRDDs)来创建DStream,每一个推送到这个队列中的RDD,都会作为一个DStream处理。
1.2 代码举例
循环创建几个RDD,将RDD放入队列。通过SparkStream创建Dstream:
scala
package com.rocket.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable
object DStreamByRddQueue {
def main(args: Array[String]): Unit = {
//1.初始化 Spark 配置信息
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("DStreamByRddQueue")
//2.初始化 SparkStreamingContext
val ssc = new StreamingContext(sparkConf, Seconds(3))
//3.创建 RDD 队列
val rddQueue = new mutable.Queue[RDD[Int]]
//4.创建 QueueInputDStream
val inputStream: InputDStream[Int] = ssc.queueStream(rddQueue, oneAtATime = false)
//5.处理队列中的 RDD 数据
val mappedStream = inputStream.map((_,1))
val reducedStream = mappedStream.reduceByKey(_ + _)
//6.打印结果
reducedStream.print()
//7.启动任务
ssc.start()
//8.循环创建并向 RDD 队列中放入 RDD
for (i <- 1 to 5) {
rddQueue += ssc.sparkContext.makeRDD(1 to 300, 10)
Thread.sleep(2000)
}
ssc.awaitTermination()
}
}运行结果: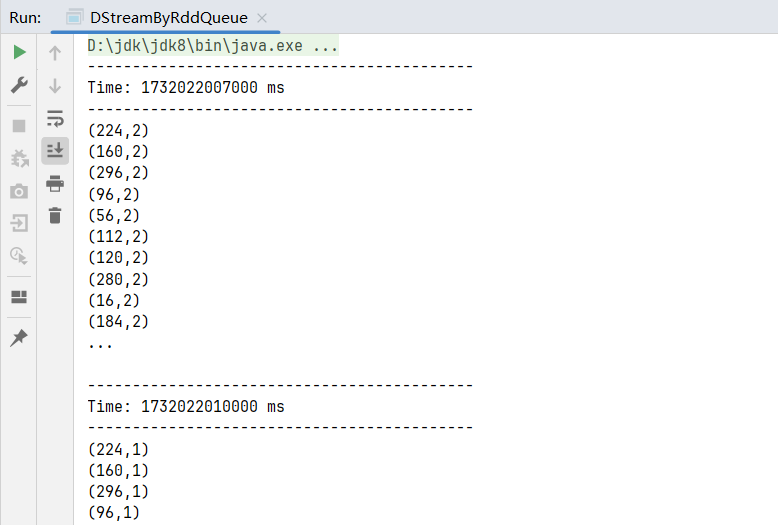
2. 自定义数据源
Spark可以采集很多流式数据,但是并没有提供现成的数据源类,我们可以通过自定义方式去读取各种类型数据。
2.1 用法及说明
继承Receiver,并实现onStart、onStop方法来自定义数据源采集。
2.2 代码实操
自定义数据源,实现监控某个端口号,获取该端口号内容。
scala
package com.rocket.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import org.apache.spark.streaming.receiver.Receiver
import org.apache.spark.streaming.{Seconds, StreamingContext}
import java.util.concurrent.TimeUnit
import scala.util.Random
object DStreamByDIY {
def main(args: Array[String]): Unit = {
//1.初始化 Spark 配置信息
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("DStreamByRddQueue")
//2.初始化 SparkStreamingContext
val ssc = new StreamingContext(sparkConf, Seconds(3))
// 使用自定义的数据源采集数据
val messageDS: ReceiverInputDStream[String] = ssc.receiverStream(new MyReceiver)
// 打印
messageDS.print()
// 启动任务
ssc.start()
ssc.awaitTermination()
}
class MyReceiver extends Receiver[String](StorageLevel.MEMORY_AND_DISK){
private var flag = true
override def onStart(): Unit = {
new Thread(()=>{
while(flag){
val message: String = s"采集的数据为:${new Random().nextInt(10).toString}"
store(message)
TimeUnit.SECONDS.sleep(2)
}
}).start()
}
override def onStop(): Unit = {
flag = false
}
}
}运行结果: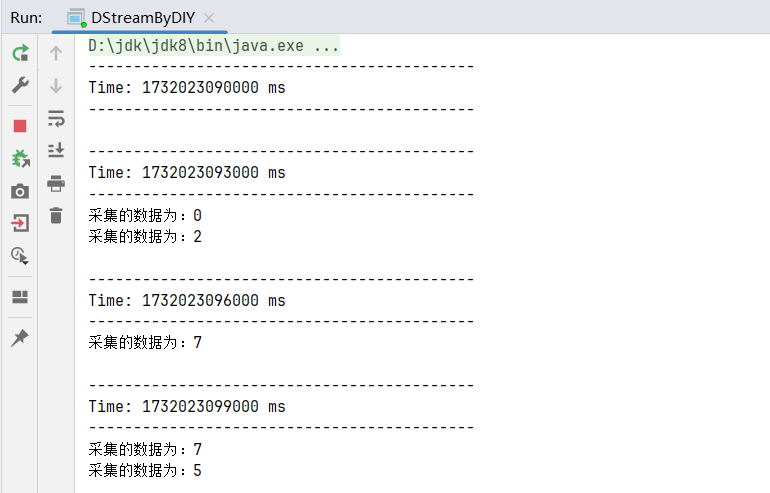
3. Kafka数据源
通过SparkStreaming从Kafka读取数据,并将读取过来的数据做简单计算,最终打印到控制台。
3.1 Kafka0-10 Direct模式
DirectAPI:是由计算的Executor来主动消费Kafka的数据,速度由自身控制。
- 导入依赖
scala
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.4.2</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
<version>3.4.2</version>
</dependency>- 代码实现
scala
package com.rocket.spark.streaming
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object DStreamByKafka {
def main(args: Array[String]): Unit = {
//1.初始化 Spark 配置信息
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("DStreamByRddQueue")
//2.初始化 SparkStreamingContext
val ssc = new StreamingContext(sparkConf, Seconds(3))
//3.定义 Kafka 参数
val kafkaParam: Map[String, Object] = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG ->
"hadoop102:9092,hadoop103:9092,hadoop104:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "jack",
ConsumerConfig.AUTO_OFFSET_RESET_CONFIG -> "earliest",
"key.deserializer" ->
"org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer" ->
"org.apache.kafka.common.serialization.StringDeserializer"
)
//4.读取 Kafka 数据创建 DStream
val kafkaDStream: InputDStream[ConsumerRecord[String, String]] =
KafkaUtils.createDirectStream[String, String](ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Set("sparkTopic"), kafkaParam))
//5.将每条消息的 KV 取出
val valueDStream: DStream[String] = kafkaDStream.map(record => record.value())
//6.计算 WordCount
valueDStream.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
.print()
// 启动任务
ssc.start()
ssc.awaitTermination()
}
}执行结果: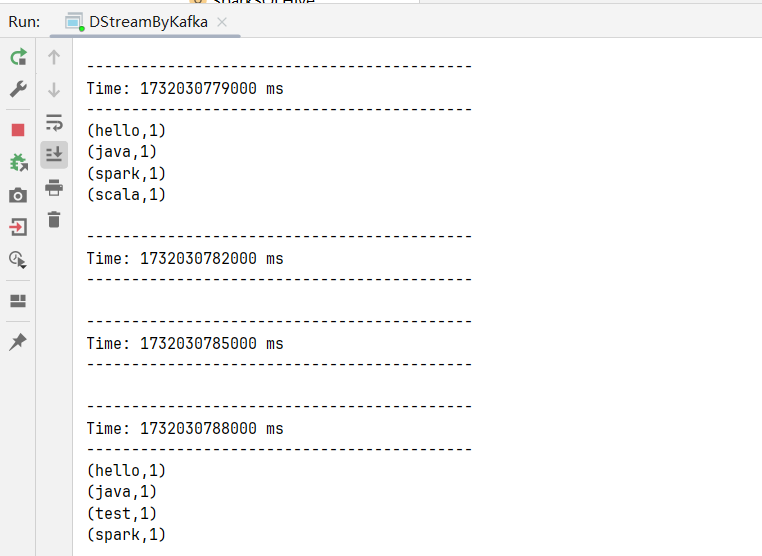
查看Kafka消费进度
sh
[jack@hadoop102 module]$ kafka-consumer-groups.sh --describe --bootstrap-server hadoop102:9092 --group jack
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
jack sparkTopic 0 8 8 0 consumer-jack-1-56ee48c1-5f93-4f98-a875-f6bf1a93e8da /192.168.101.8 consumer-jack-1