初识Kafka
1. Kafka简介
Kafka是分布式的发布—订阅消息系统。它最初由LinkedIn(领英)公司开发,于2010年12月份开源,成为Apache的顶级项目。它主要用于日志收集、消息系统、用户活动跟踪、流式处理等。
2. Kafka特点
- 高吞吐率
可以满足每秒百万级别消息的生产和消费——生产消费。 - 消息持久性
有一套完善的消息存储机制,确保数据的高效安全的持久化——中间存储。 - 分布式
基于分布式的扩展和容错机制;Kafka的数据都会复制到几台服务器上。当某一台故障失效时,生产者和消费者转而使用其它的机器——整体 - 健壮性
3. 应用场景
- 缓存/削峰
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。 - 解耦
允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。 - 异步通信
允许用户把一个消息放入队列,但并不立即处理它,然后在需要的时候再去处理它们。
4. Kafka相关概念
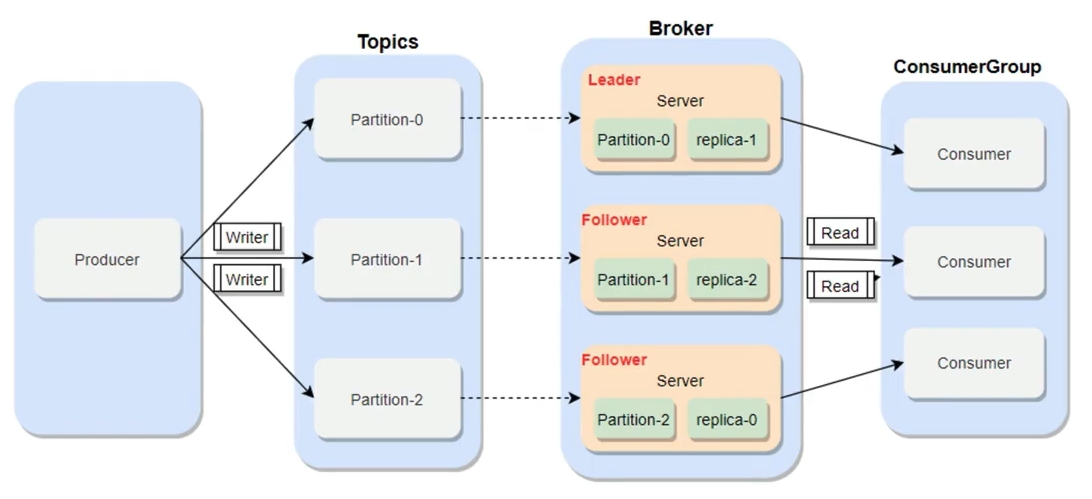
- Broker(代理):Kafka节点,一个 Kafka节点就是一个 broker,多个broker可以组成一个Kafka集群, 每个broker可以有多个topic。
- Producer(生产者):生产message(数据)发送到 topic。
- Consumer(消费者):订阅topic消费message,consumer作为一个线程来消费。
- Consumer Group(消费者组):一个Consumer Group包含多个consumer,这个是预先在配置文件中配置好的,某个分区只能由消费者组中的一个消费者消费。
- Topic(主题):可以理解为一个队列,每一条消息都必须指定它的topic, 不同的消息会进行分开存储,如果topic很大,可以分布到多个broker上,例如page view日志、click日志等都可以以topic的形式存在,Kaka集群能够同时负责多个topic的分发。
- Partition(分区):Topic物理上的分组,一个topic在broker中被分为多个partition,每个partition是一个有序的队列。
- Replicas(副本): 每一个分区,根据副本因子N,会有N个副本。比如在broker1上有一个topic,分区为topic-1,副本因子为2,那么在两个broker的数据目录里,就都有一个topic-1,其中一个是leader,一个replicas。
- Segment: partition物理上由多个segment组成,每个Segment存着message信息。
- Zookeeper:协调Kafka的正常运行。
- Leader:每个分区多个副本的主,生产者发送数据的对象,以及消费者消费数据的对象都是Leader。
- Follower:每个分区多个副本中的从,实时从Leader中同步数据,保持和Leader数据的同步。Leader发生故障时,某个 Follower会成为新的Leader。
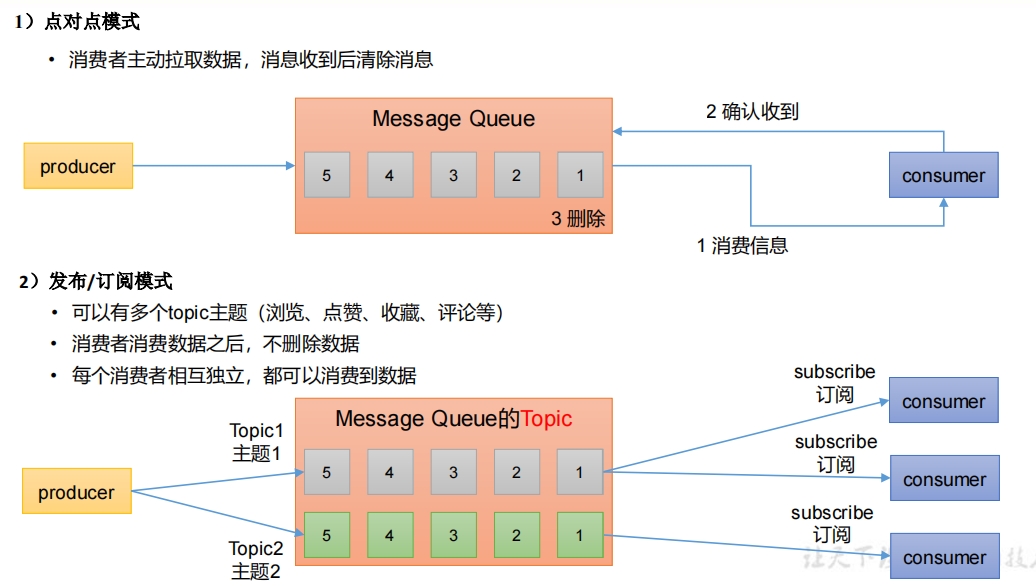
5. 消息队列的两种模式
6. 和其他消息MQ对比
| Kafka | RocketMQ | RabbitMQ | |
|---|---|---|---|
| 性能 | 高吞吐量,百万级 | 10W | |
| 厂家 | apache顶级项目 | 阿里巴巴 | |
| 场景 | 大数据场景,不丢失数据 |
RocketMQ参考了Kafka的架构,性能却还不如Kafka。此外Kafka的社区热度比RocketMQ好。