RDD综合代码实操
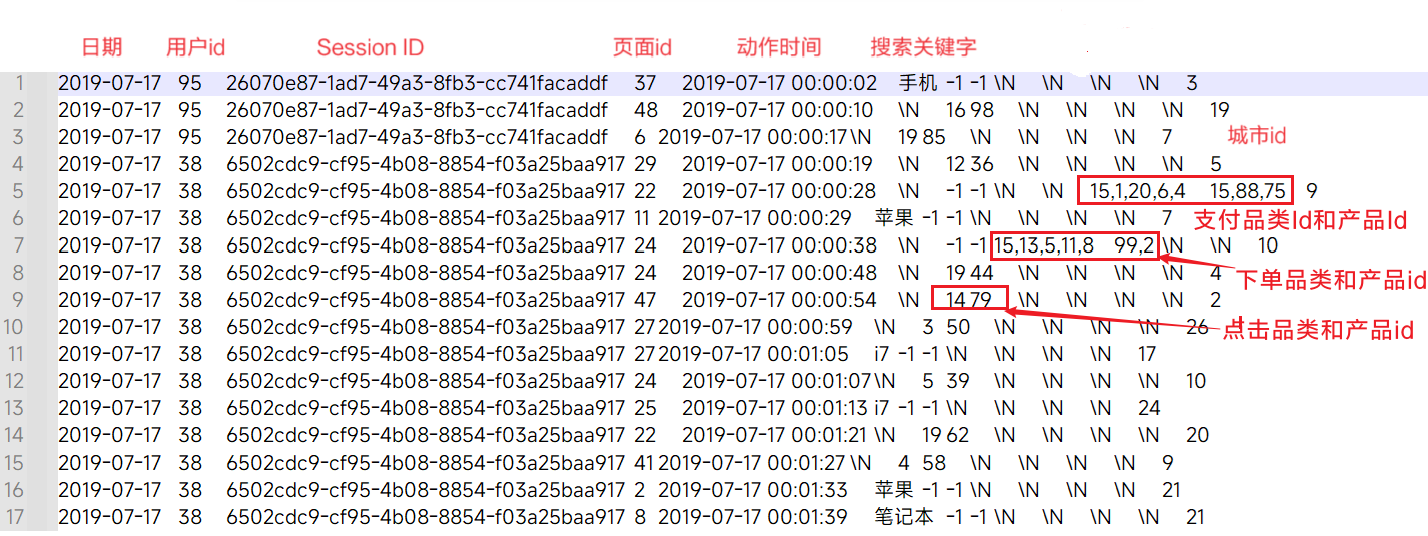 上面的数据图是从数据文件中截取的一部分内容,表示为电商网站的用户行为数据,主要包含用户的4种行为:搜索,点击,下单,支付。数据规则如下:
上面的数据图是从数据文件中截取的一部分内容,表示为电商网站的用户行为数据,主要包含用户的4种行为:搜索,点击,下单,支付。数据规则如下:
数据文件中每行数据采用下划线分隔数据
➢ 每一行数据表示用户的一次行为,这个行为只能是4种行为的一种
➢ 如果搜索关键字为null(\N),表示数据不是搜索数据
➢ 如果点击的品类ID和产品ID为-1,表示数据不是点击数据
➢ 针对于下单行为,一次可以下单多个商品,所以品类ID和产品ID可以是多个id之间采用逗号分隔,如果本次不是下单行为,则数据采用null(\N)表示
➢ 支付行为和下单行为类似
1. Top10热门品类
1.1 需求详情
按照每个品类的点击、下单、支付的量来统计热门品类。
1.2 代码实现
- 处理方法一:一次性统计每个品类点击的次数,下单的次数和支付的次数
(品类,(点击总数,下单总数,支付总数))
scala
object HotCategoryAnalyse {
def main(args: Array[String]): Unit = {
val hotCategoryAnalyse: SparkConf = new SparkConf().setMaster("local[*]").setAppName("HotCategoryAnalyse")
val sparkContext = new SparkContext(hotCategoryAnalyse)
val fileRDD: RDD[String] = sparkContext.textFile("datas/user_visit_action.txt")
// 统计品类点击数量 List[(String, Int)]
val userVisitActionRdd: RDD[(String, (Int, Int, Int))] = fileRDD.flatMap(line => {
val datas: Array[String] = line.split("\t")
val listBuffer: ListBuffer[(String, (Int, Int, Int))] = ListBuffer()
if (datas(6) != "-1") {
val tuple: (String, (Int, Int, Int)) = (datas(6), (1, 0, 0))
listBuffer.append(tuple)
}
if (datas(8) != "\\N") {
listBuffer.appendAll(datas(8).split(",").map(item => (item, (0, 1, 0))))
}
if (datas(10) != "\\N") {
listBuffer.appendAll(datas(10).split(",").map(item => (item, (0, 0, 1))))
}
listBuffer
})
val value: RDD[(String, (Int, Int, Int))] =
userVisitActionRdd
.reduceByKey {
// 模式匹配
case ((v1a, v2a, v3a), (v1b, v2b, v3b)) => (v1a + v1b, v2a + v2b, v3a + v3b)
}
value.sortBy(_._2, false).take(10)
.foreach(println)
sparkContext.stop()
}
}- 方式二:reduceByKey聚合算子有存在shuffle操作(spark会提供优化,使用缓存减少IO读取), 改为使用累加器的方式聚合数据。
scala
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object HotCategoryAnalyseV2 {
def main(args: Array[String]): Unit = {
val hotCategoryAnalyse: SparkConf = new SparkConf().setMaster("local[*]").setAppName("HotCategoryAnalyse")
val sparkContext = new SparkContext(hotCategoryAnalyse)
val fileRDD: RDD[String] = sparkContext.textFile("datas/user_visit_action.txt")
// 申明累加器
val hotCategoryAccumulator = new HotCategoryAccumulator
// 注册累加器
sparkContext.register(hotCategoryAccumulator, "hotCategoryAccumulator")
// 不再需要flatMap算子,直接遍历
fileRDD.foreach(line => {
val datas: Array[String] = line.split("\t")
if (datas(6) != "-1") {
hotCategoryAccumulator.add(("click", datas(6)))
}
if (datas(8) != "\\N") {
datas(8).split(",").foreach(item => hotCategoryAccumulator.add(("order", item)))
}
if (datas(10) != "\\N") {
datas(10).split(",").foreach(item => hotCategoryAccumulator.add(("pay", item)))
}
})
val list: List[HotCategory] = hotCategoryAccumulator.value.values.toList
val top10Category: List[HotCategory] = list.sortWith((hc1, hc2) => {
if (hc1.clickCount > hc2.clickCount) {
true
} else if (hc1.clickCount == hc2.clickCount) {
if (hc1.orderCount > hc2.orderCount) {
true
} else if (hc1.orderCount == hc2.orderCount) {
hc1.payCount > hc2.payCount
} else {
false
}
} else {
false
}
}).take(10)
top10Category.foreach(println)
sparkContext.stop()
}
}scala
class HotCategoryAccumulator extends AccumulatorV2[(String, String), mutable.Map[String, HotCategory]] {
val map = mutable.Map[String, HotCategory]()
override def isZero: Boolean = map.isEmpty
override def reset(): Unit = map.clear()
override def copy(): AccumulatorV2[(String, String), mutable.Map[String, HotCategory]] = new HotCategoryAccumulator
override def add(data: (String, String)): Unit = {
val newValue: HotCategory = map.getOrElse(data._2, HotCategory(data._2, 0, 0, 0))
if (data._1 == "click") {
newValue.clickCount += 1
} else if (data._1 == "order") {
newValue.orderCount += 1
} else if (data._1 == "pay") {
newValue.payCount += 1
}
map.update(data._2, newValue)
}
override def merge(other: AccumulatorV2[(String, String), mutable.Map[String, HotCategory]]): Unit = {
val otherMap = other.value
otherMap.foreach{
case (cid, hc)=>{
val category = map.getOrElse(cid, HotCategory(cid, 0, 0, 0))
category.clickCount += hc.clickCount
category.orderCount += hc.orderCount
category.payCount += hc.payCount
map.update(cid, category)
}
}
}
override def value: mutable.Map[String, HotCategory] = map
}scala
case class HotCategory(var categoryId: String,
var clickCount: Int,
var orderCount: Int,
var payCount: Int)2. Top10热门品类中每个品类的Top10活跃Session统计
2.1 需求详情
在需求一的基础上,增加每个品类用户session的点击统计
2.2 代码实现
scala
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object HotCategoryTop10SessionAnalysis {
def main(args: Array[String]): Unit = {
val hotCategoryAnalyse: SparkConf = new SparkConf().setMaster("local[*]").setAppName("HotCategoryAnalyse")
val sparkContext = new SparkContext(hotCategoryAnalyse)
val fileRDD: RDD[String] = sparkContext.textFile("datas/user_visit_action.txt")
fileRDD.cache()
val categoryTop10Str: List[String] = getTop10Category(sparkContext, fileRDD)
// 1. 过滤原始数据,保留点击和前10品类ID
val filterRdd: RDD[String] = fileRDD.filter(line => {
val categoryId: String = line.split("\\t")(6)
categoryTop10Str.contains(categoryId)
})
// 2. 根据品类ID和sessionid进行点击量的统计
val reduceRdd: RDD[((String, String), Int)] = filterRdd.map(line => {
val datas = line.split("\\t")
((datas(6), datas(2)), 1)
}).reduceByKey(_ + _)
// 3. 将统计的结果进行结构的转换, 相同的品类进行分组
val groupRdd: RDD[(String, Iterable[(String, Int)])] = reduceRdd.map {
case (k, v) => {
(k._1, (k._2, v))
}
}.groupByKey()
// 4. 将分组后的数据进行点击量的排序,取前10名
val sessionTop10Rdd: RDD[(String, List[(String, Int)])] = groupRdd.mapValues(itemList => {
itemList.toList.sortBy(item => item._2)(Ordering.Int.reverse).take(10)
})
sessionTop10Rdd.foreach(println)
sparkContext.stop()
}
def getTop10Category(sparkContext: SparkContext, fileRDD: RDD[String]): List[String] = {
// 申明累加器
val hotCategoryAccumulator = new HotCategoryAccumulator
// 注册累加器
sparkContext.register(hotCategoryAccumulator, "hotCategoryAccumulator")
// 不再需要flatMap算子,直接遍历
fileRDD.foreach(line => {
val datas: Array[String] = line.split("\t")
if (datas(6) != "-1") {
hotCategoryAccumulator.add(("click", datas(6)))
}
if (datas(8) != "\\N") {
datas(8).split(",").foreach(item => hotCategoryAccumulator.add(("order", item)))
}
if (datas(10) != "\\N") {
datas(10).split(",").foreach(item => hotCategoryAccumulator.add(("pay", item)))
}
})
val list: List[HotCategory] = hotCategoryAccumulator.value.values.toList
val top10Category: List[HotCategory] = list.sortWith((hc1, hc2) => {
if (hc1.clickCount > hc2.clickCount) {
true
} else if (hc1.clickCount == hc2.clickCount) {
if (hc1.orderCount > hc2.orderCount) {
true
} else if (hc1.orderCount == hc2.orderCount) {
hc1.payCount > hc2.payCount
} else {
false
}
} else {
false
}
}).take(10)
top10Category.map(_.categoryId)
}
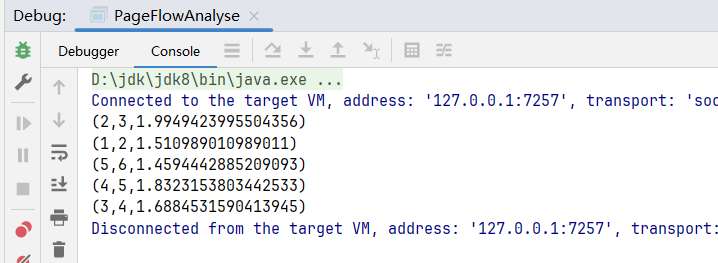
}3. 页面单跳转换率统计
3.1 需求详情
计算页面单跳转化率,什么是页面单跳转换率,比如一个用户在一次Session 过程中访问的页面路径 3,5,7,9,10,21,那么页面3跳到页面5叫一次单跳,7-9也叫一次单跳,那么单跳转化率就是要统计页面点击的概率。 
3.2 代码实现
scala
object PageFlowAnalyse {
def main(args: Array[String]): Unit = {
val hotCategoryAnalyse: SparkConf = new SparkConf().setMaster("local[*]").setAppName("PageFlowAnalyse")
val sparkContext = new SparkContext(hotCategoryAnalyse)
val fileRDD: RDD[String] = sparkContext.textFile("datas/user_visit_action.txt")
// 初始化需要关注统计的页面: 比如首页->下单->支付
val requirePageList: List[Long] = List(1, 2, 3, 4, 5, 6)
/**
* 1,2,3,4,5,6
* 得到 1-2,2-3,3-4,4-5,5-6
* 方式1 利用sliding 滑窗函数
* 方式2 利用zip 拉链
*/
val requirePageFlow: List[(Long, Long)] = requirePageList.sliding(2).map(item => (item(0), item(1))).toList
// 总的页面访问量
// 过滤数据,得到要统计的数据
val userVisitActionRdd: RDD[UserVisitAction] = fileRDD
.map(line => {
val datas: Array[String] = line.split("\\t")
UserVisitAction(datas(0), datas(1).toLong, datas(2), datas(3).toLong, datas(4))
})
// 计算分母
val totalPageVisitMap: Map[Long, Int] = userVisitActionRdd
.filter(visitAction => {
// init得到1,2,3,4,5 第6页可以不作为统计
requirePageList.init.contains(visitAction.page_id)
})
.groupBy(_.page_id)
.mapValues(item => {
item.size
}).collect().toMap
// 根据session进行分组
// 分组后,根据访问时间进行排序(升序)
val pageFlowRdd: RDD[(String, List[(Long, Long)])] = userVisitActionRdd
.groupBy(_.session_id)
.mapValues(it => {
val pageIds: List[Long] = it.toList
.sortBy(_.action_time)
.map(item => item.page_id)
// zip : 拉链
pageIds.zip(pageIds.tail)
})
val pageFlowCountRdd: RDD[((Long, Long), Int)] = pageFlowRdd
.flatMap(_._2)
.filter(requirePageFlow.contains(_))
.map((_, 1))
.reduceByKey(_ + _)
val resultRdd: RDD[(Long, Long, Double)] = pageFlowCountRdd.map {
case ((sourcePageId, targetPageId), pageCount) => {
val totalPageCount: Int = totalPageVisitMap.getOrElse(sourcePageId, 0)
var changeRate = 0.0
if (totalPageCount != 0) {
// 计算单跳转换率, 需要注意需要提前转Double
changeRate = pageCount.toDouble / totalPageCount * 100
}
(sourcePageId, targetPageId, changeRate)
}
}
resultRdd.collect().foreach(println)
sparkContext.stop()
}
}计算结果: