实时数仓预研
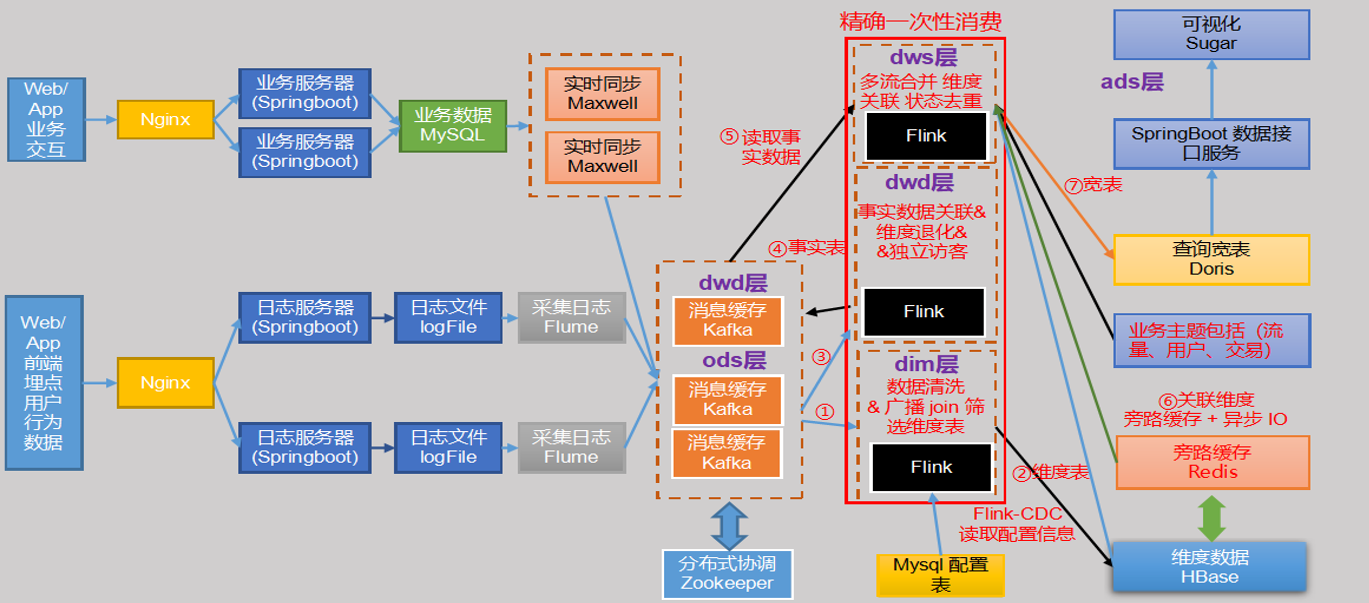
1. 数据仓库核心架构
2. 普通实时计算与实时数仓比较
普通的实时计算优先考虑时效性,所以从数据源采集经过实时计算直接得到结果。如此做时效性更好,但是弊端是由于计算过程中的中间结果没有沉淀下来,所以当面对大量实时需求的时候,计算的复用性较差,开发成本随着需求增加直线上升。  实时数仓基于一定的数据仓库理念,对数据处理流程进行规划、分层,目的是提高数据的复用性。
实时数仓基于一定的数据仓库理念,对数据处理流程进行规划、分层,目的是提高数据的复用性。 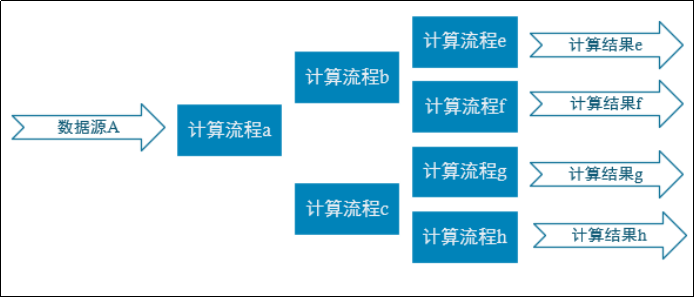
3. 离线计算与实时计算的比较
- 离线计算:就是在计算开始前已知所有输入数据,输入数据不会产生变化,一般计算量级较大,计算时间也较长。例如今天早上一点,把昨天累积的日志,计算出所需结果。最经典的就是Hadoop的MapReduce方式;
一般是根据前一日的数据生成报表,虽然统计指标、报表繁多,但是对时效性不敏感。从技术操作的角度,这部分属于批处理的操作。即根据确定范围的数据一次性计算。 - 实时计算:输入数据是可以以序列化的方式一个个输入并进行处理的,也就是说在开始的时候并不需要知道所有的输入数据。与离线计算相比,运行时间短,计算量级相对较小。强调计算过程的时间要短,即所查当下给出结果。
主要侧重于对当日数据的实时监控,通常业务逻辑相对离线需求简单一些,统计指标也少一些,但是更注重数据的时效性,以及用户的交互性。从技术操作的角度,这部分属于流处理的操作。根据数据源源不断地到达进行实时的运算。