Dstream入门
1. WordCount案例实操
1.1 需求
使用netcat工具向9999端口不断的发送数据,通过SparkStreaming读取端口数据并统计不同单词出现的次数。
1.2 代码实现
- 添加依赖
xml
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.4.2</version>
</dependency>- 编写代码
scala
package com.rocket.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreamDemo {
def main(args: Array[String]): Unit = {
//1.初始化 Spark 配置信息
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("StreamWordCount")
//2.初始化 SparkStreamingContext
val ssc = new StreamingContext(sparkConf, Seconds(3))
//3.通过监控端口创建 DStream,读进来的数据为一行
val lineStreams = ssc.socketTextStream("hadoop102", 7777)
//将每一行数据做切分,形成一个个单词
val wordStreams = lineStreams.flatMap(_.split(" "))
//将单词映射成元组(word,1)
val wordAndOneStreams = wordStreams.map((_, 1))
//将相同的单词次数做统计
val wordAndCountStreams = wordAndOneStreams.reduceByKey(_+_)
//打印
wordAndCountStreams.print()
//启动 SparkStreamingContext
ssc.start()
ssc.awaitTermination()
}
}- 运行代码测试
启动程序并通过netcat发送数据:
sh
nc -lk 9999
hello spark hello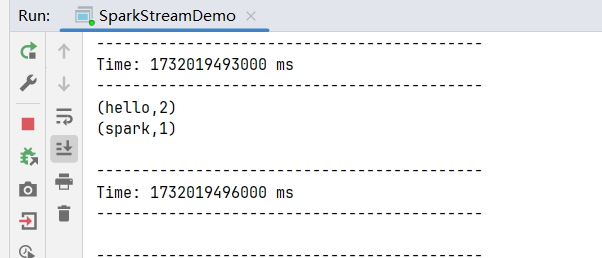
2. WordCount解析
Discretized Stream是Spark Streaming的基础抽象,代表持续性的数据流和经过各种Spark原语操作后的结果数据流。在内部实现上,DStream是一系列连续的RDD来表示。每个RDD含有一段时间间隔内的数据。 DStream就像管道,对数据的操作按照RDD为单位源源不断进行的
DStream就像管道,对数据的操作按照RDD为单位源源不断进行的 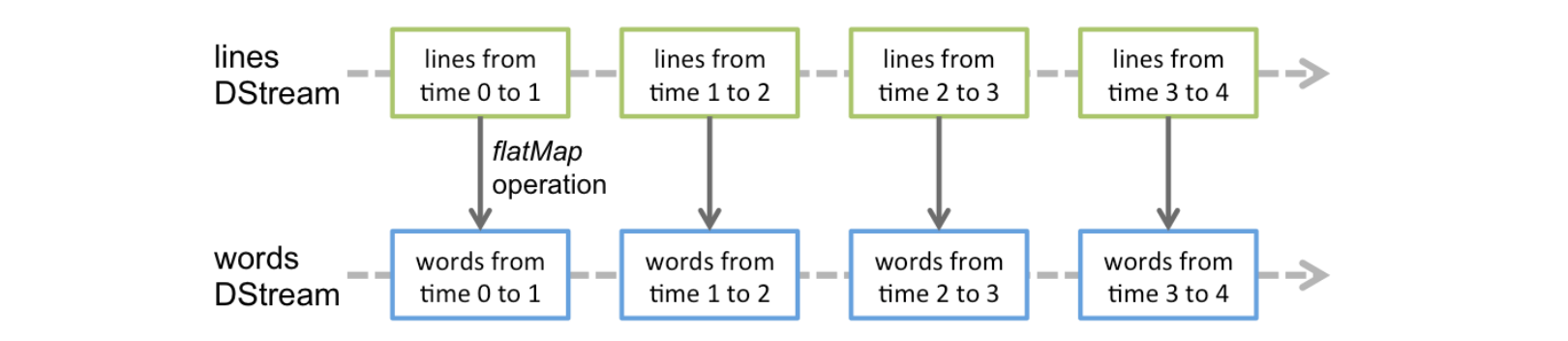 计算过程由Spark Engine来完成
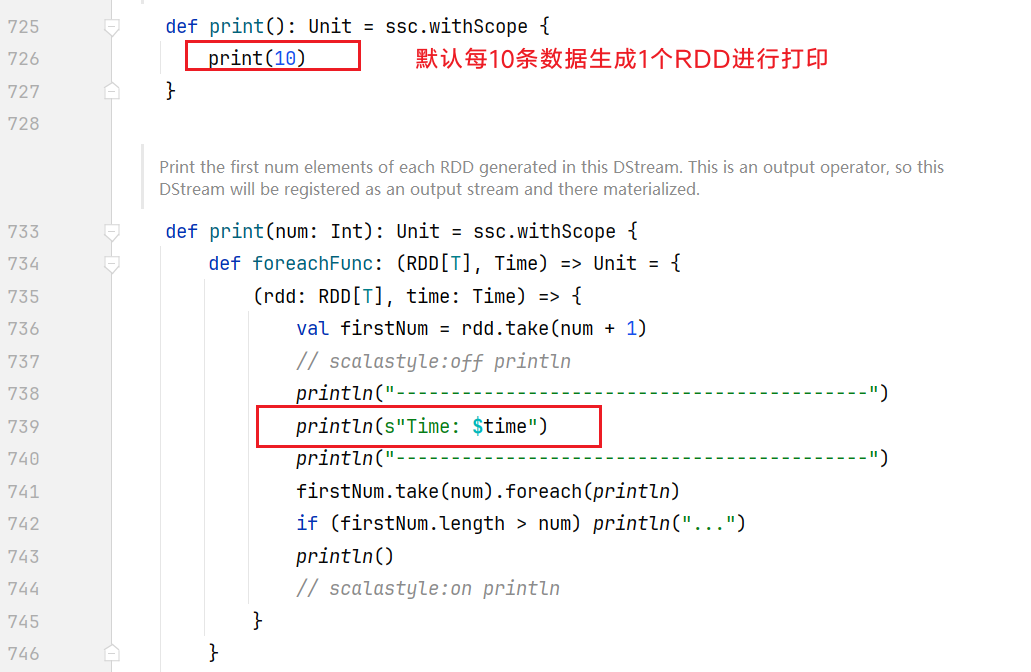
计算过程由Spark Engine来完成  控制台不断打印----和毫秒值,是因为源码中print函数执行的效果:
控制台不断打印----和毫秒值,是因为源码中print函数执行的效果: