Kettle概述
1. ETL简介
ETL(Extract-Transform-Load的缩写,即数据抽取、转换、装载的过程),对于企业或行业应用来说,我们经常会遇到各种数据的处理,转换,迁移,所以了解并掌握一种ETL工具的使用,必不可少。市面上常用的ETL工具有很多,比如Sqoop,DataX,Kettle,Talend等
2. Kettle是什么
Kettle是一款国外开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行。Kettle中文名称叫水壶,该项目的主程序员MATT希望把各种数据放到一个壶里,然后以一种指定的格式流出。Kettle这个ETL工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做。
Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。Kettle(现在已经更名为PDI,Pentaho Data Integration-Pentaho数据集成)。 Kettle官方doc文档地址: Kettle9.3.x文档
警告
Pentaho目前的长期支持版本(LTS)是10.2版,从这个版本开始Pentaho CE社区版已停止发布及更新,随着时间推移,继续使用CE老版本无疑存在严重安全隐患。代替CE版的DE开发版,基于最新BSL 1.1软件许可协议,仅限用于非生产环境的开发测试,企业生产环境要合规使用Pentaho,需选用EE商用版。
3. Pentaho的进化历程
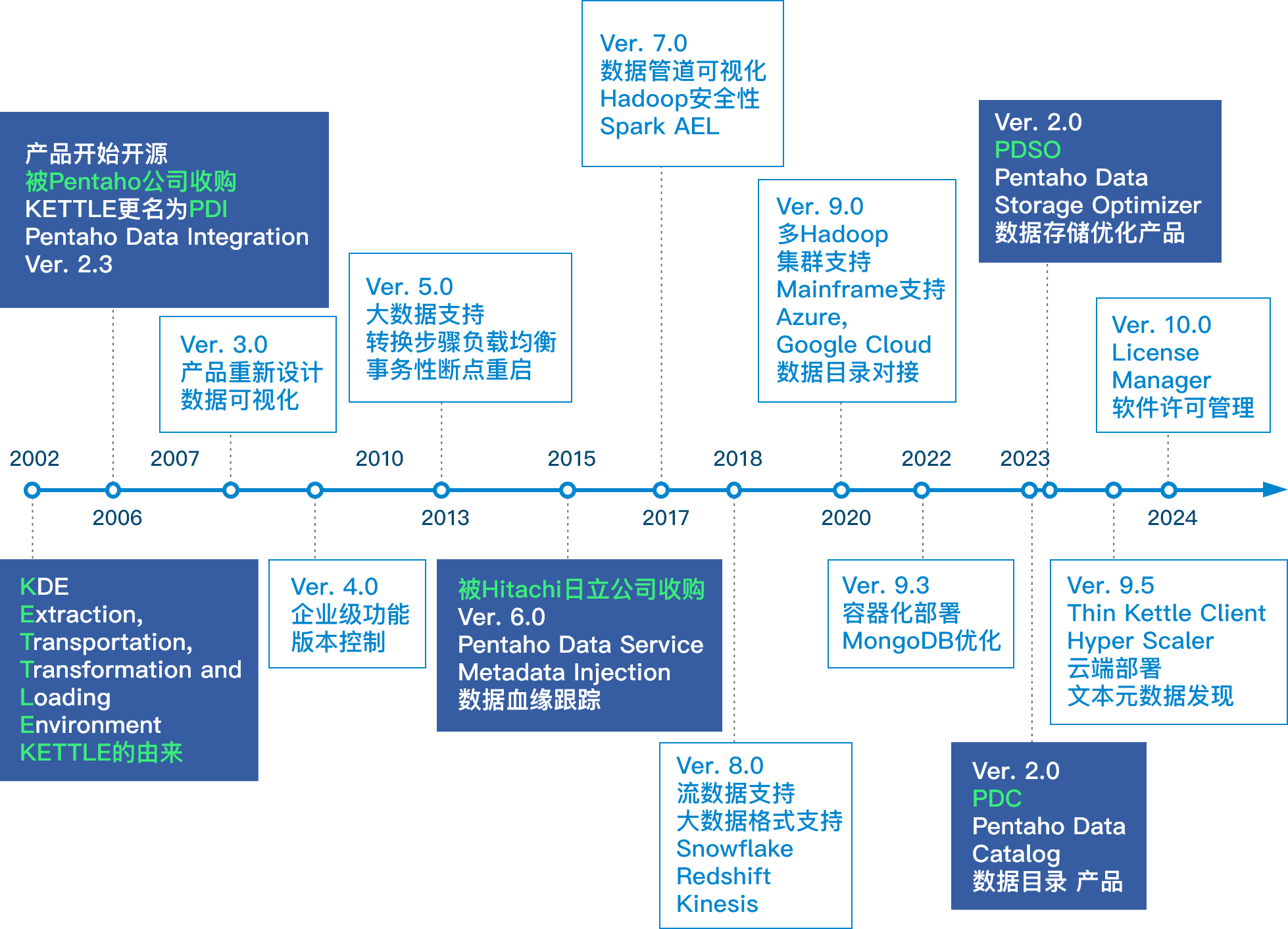 Kettle目前是Pentaho Data Integration(PDI)项目的一部分。
Kettle目前是Pentaho Data Integration(PDI)项目的一部分。
4. Kettle要点
4.1 Kettle工程存储方式
- 以XML形式存储
- 以资源库方式存储(数据库资源库和文件资源库)
4.2 transformation和job区别
Transformation(转换):完成针对数据的基础转换。
Job(作业):完成整个工作流的控制。
区别:
- 作业是步骤流,转换是数据流。这是作业和转换最大的区别。
- 作业的每一个步骤,必须等到前面的步骤都跑完了,后面的步骤才会执行;而转换会一次性把所有控件全部先启动(一个控件对应启动一个线程),然后数据流会从第一个控件开始,一条记录、一条记录地流向最后的控件;
4.4 Kettle的组成
spoon.sh/Spoon.bat(勺子):一个图形化作业和转换创建UI工具
pan.sh/Pan.bat(煎锅): 在命令行中调用Trans
kitchen.sh/Kitchen.bat(厨房):在命令行中调用job
carte.sh/Carte.bat(菜单):一个轻量级Web服务器,用于执行转换和作业。Carte启动后的默认用户名和密码:cluster 使用最多的是勺子(Spoon)
使用最多的是勺子(Spoon)
5. kettle特点
- 免费开源:基于java的免费开源软件,对商业用户没有限制。
- 易配置:可以跨平台运行,绿色无需安装。
- 支持多种数据库:可以管理多种不同数据源数据。
- 两种脚本文件:trans和job,trans完成对数据的基础转换,job完成整个工作流的控制。
- 图像界面设计:通过图形界面设计实现业务配置,无需写代码实现。
- 定时功能:在job的start模块可以实现每日,每周等方式定时周期运行。
6. Kettle核心概念
6.1 转换
转换负责数据的输入、转换、校验和输出等工作。Kettle中使用转换完成ETL全部工作。转换由多个步骤组成,如文本的输入,过滤输入行,执行SQL脚本等。各个步骤使用跳(Hop)链接。跳定义了一个输入流通道,即数据由一个步骤流(跳)向下一个步骤。在Kettle中数据最小的单位是数据行(Row),数据流中流动其实是缓存的行集(RowSet)。 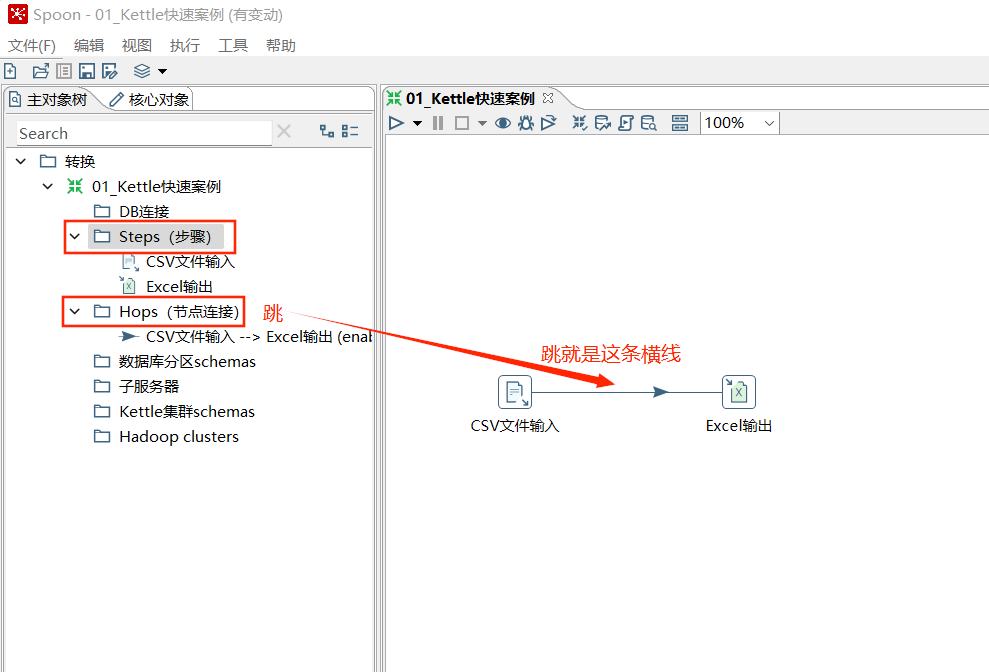
6.2 步骤(step)
步骤(控件)是转换里的基本组成部分,一个步骤有如下几个关键特性:
- 步骤需要一个名字,这个名字在同一个转换范围内唯一。
- 每个步骤都会读、写数据行(唯一例外是"生成记录"步骤,该步骤只写数据)
- 步骤将数据写到与之相连的一个或多个跳(hop),再传送到跳的另一端的步骤。
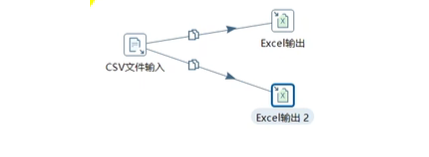
- 大多数的步骤都可以有多个输出跳。一个步骤的数据发送可以被设置为分发和复制,比如一共5条数据行:
- 分发:分发到两个excel表中,一个表两条,一个表三条。
- 复制:每个输出表都将有5条数据输出。
6.3 跳(hop)
跳就是带箭头的连线,跳定义了步骤之间的数据通路。 ![Alt text]images/Snipaste_20250210_222039.png) 跳实际上是两个步骤之间被称之为行集的数据行缓存,行集的大小可以在转换的设置里定义。当行集满了,向行集写数据的步骤将停止写入,直到行集里又有了空间。当行集空了,从行集读取数据的步骤停止读取,直到行集里又有可读的数据行。
【双击空白区域-杂项】 可查看最大行集(一次最多传递多少数据) 
6.4 元数据
每个步骤在输出数据行时都有对字段的描述,这种描述就是数据行的元数据。通常包含下面一些信息:
- 名称:数据行里的字段名是唯一的。
- 数据类型:字段的数据类型
- 格式:数据显示的方式,如Integer的#、0.00。
- 长度:字符串的长度或BigNumber数据类型的长度
- 精度:BigNumber数据类型的十进制精度
- 货币符号:¥
- 小数点符号:十进制小数点格式。不同文化背景下的小数点符号是不同的,有(.)有(,)。
分组符号:数值类型数据的分组符号,不同的文化背景下数字里的分组符号也是不同的,一般是(.)或(,)或(‘)。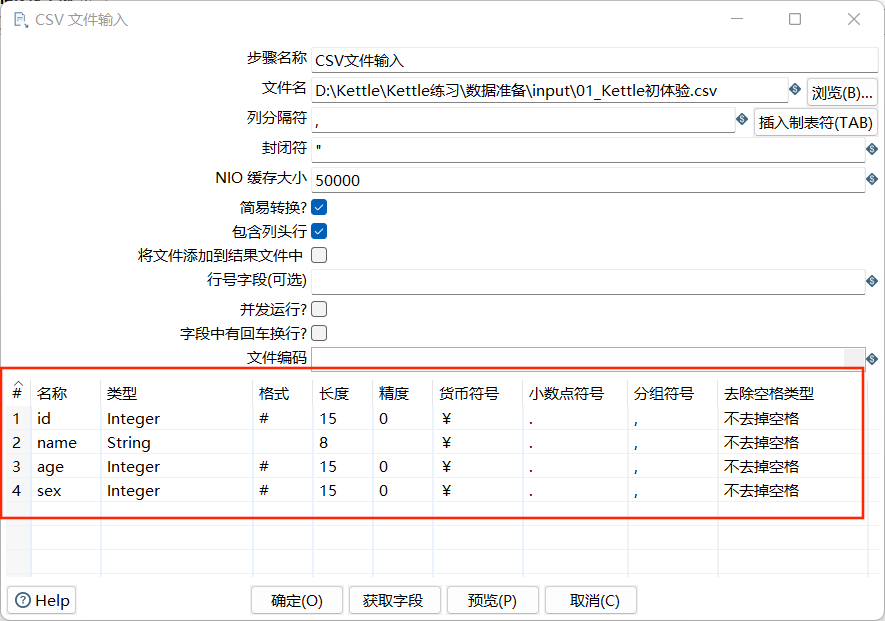
6.5 数据类型
- String:字符串
- Number:双精度浮点型
- Integer:带符号长整型(64位)
- BigNumber:任意精度数据
- Date:带毫秒精度的日期时间值
- Boolean:取值为true和false的布尔值
- Binary:二进制字段,可以包含图像、声音、视频以及其他类型的二进制数据。
6.6 并行
跳的这种基于行集缓存的规则允许每个步骤都是由一个独立的线程运行,这样并发程度最高。这一规则也允许数据以最小消耗内存的数据流的方式来处理。对于Kettle的转换,不能定义一个执行顺序,因为所有步骤都以并发方式执行:当转换启动后,所有步骤都同时启动,从它们的输入跳中读取数据,并把处理过的数据写到输出跳,直到输出跳里不再有数据,就终止步骤的运行。当所有的步骤都中止了,整个转换就终止了。如果你想一个任务沿着指定的顺序执行,那么就要使用下面所讲的"作业"了。
6.7 作业
作业(Job),负责定义一个完成整个工作流的控制,比如将转换的结果发送邮件给相关人员。因为转换以并行方式执行,所以必须存在一个串行的调度工具来执行转换,这就是Kettle中的作业。