SparkSQL性能调优
1. Explain查看执行计划
Spark3.0大版本发布,Spark SQL的优化占比将近50%。Spark SQL取代Spark Core,成为新一代的引擎内核,所有其他子框架如Mllib、Streaming和Graph,都可以共享Spark SQL的性能优化,都能从Spark社区对于Spark SQL的投入中受益。
要优化SparkSQL应用时,一定是要了解SparkSQL执行计划的。发现SQL执行慢的根本原因,才能知道应该在哪儿进行优化,是调整SQL的编写方式、还是用Hint、还是调参,而不是把优化方案拿来试一遍。
1.1 基本使用
从3.0开始,explain方法有一个新的参数mode,该参数可以指定执行计划展示格式:
explain(mode="simple"); //只展示物理执行计划。
explain(mode="extended"); //展示物理执行计划和逻辑执行计划。
explain(mode="codegen"); //展示要Codegen生成的可执行Java代码。
explain(mode="cost");// 展示优化后的逻辑执行计划以及相关的统计。
explain(mode="formatted"); //以分隔的方式输出,它会输出更易读的物理执行计划,并展示每个节点的详细信息。1.2 准备测试用表和数据
- 上传3个log到hdfs新建的sparkdata路径
- hive中创建sparktuning数据库
- 在本地执行spark的InitUtil的main程序
执行后在HDFS上面有这几张表:
1.2 执行计划处理流程
def main( args: Array[String] ): Unit = {
val sparkConf = new SparkConf().setAppName("ExplainDemo")
.setMaster("local[*]") //TODO 要打包提交集群执行,注释掉
val sparkSession: SparkSession = InitUtil.initSparkSession(sparkConf)
val sqlstr =
"""
|select
| sc.courseid,
| sc.coursename,
| sum(sellmoney) as totalsell
|from sale_course sc join course_shopping_cart csc
| on sc.courseid=csc.courseid and sc.dt=csc.dt and sc.dn=csc.dn
|group by sc.courseid,sc.coursename
""".stripMargin
sparkSession.sql("use sparktuning;")
println("=====================================explain()-只展示物理执行计划============================================")
sparkSession.sql(sqlstr).explain()
println("===============================explain(mode = \"simple\")-只展示物理执行计划=================================")
sparkSession.sql(sqlstr).explain(mode = "simple")
println("============================explain(mode = \"extended\")-展示逻辑和物理执行计划==============================")
sparkSession.sql(sqlstr).explain(mode = "extended")
println("============================explain(mode = \"codegen\")-展示可执行java代码===================================")
sparkSession.sql(sqlstr).explain(mode = "codegen")
println("============================explain(mode = \"formatted\")-展示格式化的物理执行计划=============================")
sparkSession.sql(sqlstr).explain(mode = "formatted")
}执行结果:
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- HashAggregate(keys=[courseid#3L, coursename#5], functions=[sum(cast(sellmoney#22 as double))])
+- Exchange hashpartitioning(courseid#3L, coursename#5, 200), ENSURE_REQUIREMENTS, [plan_id=43]
+- HashAggregate(keys=[courseid#3L, coursename#5], functions=[partial_sum(cast(sellmoney#22 as double))])
+- Project [courseid#3L, coursename#5, sellmoney#22]
+- BroadcastHashJoin [courseid#3L, dt#15, dn#16], [courseid#17L, dt#23, dn#24], Inner, BuildLeft, false
:- BroadcastExchange HashedRelationBroadcastMode(List(input[0, bigint, false], input[2, string, true], input[3, string, true]),false), [plan_id=38]
: +- Filter isnotnull(courseid#3L)
: +- FileScan parquet spark_catalog.sparktuning.sale_course[courseid#3L,coursename#5,dt#15,dn#16] Batched: true, DataFilters: [isnotnull(courseid#3L)], Format: Parquet, Location: InMemoryFileIndex(1 paths)[hdfs://hadoop102:8020/hive3/warehouse/sparktuning.db/sale_course/dt=20..., PartitionFilters: [isnotnull(dt#15), isnotnull(dn#16)], PushedFilters: [IsNotNull(courseid)], ReadSchema: struct<courseid:bigint,coursename:string>
+- Filter isnotnull(courseid#17L)
+- FileScan parquet spark_catalog.sparktuning.course_shopping_cart[courseid#17L,sellmoney#22,dt#23,dn#24] Batched: true, DataFilters: [isnotnull(courseid#17L)], Format: Parquet, Location: InMemoryFileIndex(1 paths)[hdfs://hadoop102:8020/hive3/warehouse/sparktuning.db/course_shopping_c..., PartitionFilters: [isnotnull(dt#23), isnotnull(dn#24)], PushedFilters: [IsNotNull(courseid)], ReadSchema: struct<courseid:bigint,sellmoney:string>
===============================explain(mode = "simple")-只展示物理执行计划=================================
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- HashAggregate(keys=[courseid#3L, coursename#5], functions=[sum(cast(sellmoney#22 as double))])
+- Exchange hashpartitioning(courseid#3L, coursename#5, 200), ENSURE_REQUIREMENTS, [plan_id=85]
+- HashAggregate(keys=[courseid#3L, coursename#5], functions=[partial_sum(cast(sellmoney#22 as double))])
+- Project [courseid#3L, coursename#5, sellmoney#22]
+- BroadcastHashJoin [courseid#3L, dt#15, dn#16], [courseid#17L, dt#23, dn#24], Inner, BuildLeft, false
:- BroadcastExchange HashedRelationBroadcastMode(List(input[0, bigint, false], input[2, string, true], input[3, string, true]),false), [plan_id=80]
: +- Filter isnotnull(courseid#3L)
: +- FileScan parquet spark_catalog.sparktuning.sale_course[courseid#3L,coursename#5,dt#15,dn#16] Batched: true, DataFilters: [isnotnull(courseid#3L)], Format: Parquet, Location: InMemoryFileIndex(1 paths)[hdfs://hadoop102:8020/hive3/warehouse/sparktuning.db/sale_course/dt=20..., PartitionFilters: [isnotnull(dt#15), isnotnull(dn#16)], PushedFilters: [IsNotNull(courseid)], ReadSchema: struct<courseid:bigint,coursename:string>
+- Filter isnotnull(courseid#17L)
+- FileScan parquet spark_catalog.sparktuning.course_shopping_cart[courseid#17L,sellmoney#22,dt#23,dn#24] Batched: true, DataFilters: [isnotnull(courseid#17L)], Format: Parquet, Location: InMemoryFileIndex(1 paths)[hdfs://hadoop102:8020/hive3/warehouse/sparktuning.db/course_shopping_c..., PartitionFilters: [isnotnull(dt#23), isnotnull(dn#24)], PushedFilters: [IsNotNull(courseid)], ReadSchema: struct<courseid:bigint,sellmoney:string>
============================explain(mode = "extended")-展示逻辑和物理执行计划==============================
== Parsed Logical Plan ==
'Aggregate ['sc.courseid, 'sc.coursename], ['sc.courseid, 'sc.coursename, 'sum('sellmoney) AS totalsell#40]
+- 'Join Inner, ((('sc.courseid = 'csc.courseid) AND ('sc.dt = 'csc.dt)) AND ('sc.dn = 'csc.dn))
:- 'SubqueryAlias sc
: +- 'UnresolvedRelation [sale_course], [], false
+- 'SubqueryAlias csc
+- 'UnresolvedRelation [course_shopping_cart], [], false
== Analyzed Logical Plan ==
courseid: bigint, coursename: string, totalsell: double
Aggregate [courseid#3L, coursename#5], [courseid#3L, coursename#5, sum(cast(sellmoney#22 as double)) AS totalsell#40]
+- Join Inner, (((courseid#3L = courseid#17L) AND (dt#15 = dt#23)) AND (dn#16 = dn#24))
:- SubqueryAlias sc
: +- SubqueryAlias spark_catalog.sparktuning.sale_course
: +- Relation spark_catalog.sparktuning.sale_course[chapterid#1L,chaptername#2,courseid#3L,coursemanager#4,coursename#5,edusubjectid#6L,edusubjectname#7,majorid#8L,majorname#9,money#10,pointlistid#11L,status#12,teacherid#13L,teachername#14,dt#15,dn#16] parquet
+- SubqueryAlias csc
+- SubqueryAlias spark_catalog.sparktuning.course_shopping_cart
+- Relation spark_catalog.sparktuning.course_shopping_cart[courseid#17L,coursename#18,createtime#19,discount#20,orderid#21,sellmoney#22,dt#23,dn#24] parquet
== Optimized Logical Plan ==
Aggregate [courseid#3L, coursename#5], [courseid#3L, coursename#5, sum(cast(sellmoney#22 as double)) AS totalsell#40]
+- Project [courseid#3L, coursename#5, sellmoney#22]
+- Join Inner, (((courseid#3L = courseid#17L) AND (dt#15 = dt#23)) AND (dn#16 = dn#24))
:- Project [courseid#3L, coursename#5, dt#15, dn#16]
: +- Filter ((isnotnull(courseid#3L) AND isnotnull(dt#15)) AND isnotnull(dn#16))
: +- Relation spark_catalog.sparktuning.sale_course[chapterid#1L,chaptername#2,courseid#3L,coursemanager#4,coursename#5,edusubjectid#6L,edusubjectname#7,majorid#8L,majorname#9,money#10,pointlistid#11L,status#12,teacherid#13L,teachername#14,dt#15,dn#16] parquet
+- Project [courseid#17L, sellmoney#22, dt#23, dn#24]
+- Filter ((isnotnull(courseid#17L) AND isnotnull(dt#23)) AND isnotnull(dn#24))
+- Relation spark_catalog.sparktuning.course_shopping_cart[courseid#17L,coursename#18,createtime#19,discount#20,orderid#21,sellmoney#22,dt#23,dn#24] parquet
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- HashAggregate(keys=[courseid#3L, coursename#5], functions=[sum(cast(sellmoney#22 as double))], output=[courseid#3L, coursename#5, totalsell#40])
+- Exchange hashpartitioning(courseid#3L, coursename#5, 200), ENSURE_REQUIREMENTS, [plan_id=127]
+- HashAggregate(keys=[courseid#3L, coursename#5], functions=[partial_sum(cast(sellmoney#22 as double))], output=[courseid#3L, coursename#5, sum#46])
+- Project [courseid#3L, coursename#5, sellmoney#22]
+- BroadcastHashJoin [courseid#3L, dt#15, dn#16], [courseid#17L, dt#23, dn#24], Inner, BuildLeft, false
:- BroadcastExchange HashedRelationBroadcastMode(List(input[0, bigint, false], input[2, string, true], input[3, string, true]),false), [plan_id=122]
: +- Filter isnotnull(courseid#3L)
: +- FileScan parquet spark_catalog.sparktuning.sale_course[courseid#3L,coursename#5,dt#15,dn#16] Batched: true, DataFilters: [isnotnull(courseid#3L)], Format: Parquet, Location: InMemoryFileIndex(1 paths)[hdfs://hadoop102:8020/hive3/warehouse/sparktuning.db/sale_course/dt=20..., PartitionFilters: [isnotnull(dt#15), isnotnull(dn#16)], PushedFilters: [IsNotNull(courseid)], ReadSchema: struct<courseid:bigint,coursename:string>
+- Filter isnotnull(courseid#17L)
+- FileScan parquet spark_catalog.sparktuning.course_shopping_cart[courseid#17L,sellmoney#22,dt#23,dn#24] Batched: true, DataFilters: [isnotnull(courseid#17L)], Format: Parquet, Location: InMemoryFileIndex(1 paths)[hdfs://hadoop102:8020/hive3/warehouse/sparktuning.db/course_shopping_c..., PartitionFilters: [isnotnull(dt#23), isnotnull(dn#24)], PushedFilters: [IsNotNull(courseid)], ReadSchema: struct<courseid:bigint,sellmoney:string>
============================explain(mode = "codegen")-展示可执行java代码===================================
Found 0 WholeStageCodegen subtrees.
============================explain(mode = "formatted")-展示格式化的物理执行计划=============================
== Physical Plan ==
AdaptiveSparkPlan (11)
+- HashAggregate (10)
+- Exchange (9)
+- HashAggregate (8)
+- Project (7)
+- BroadcastHashJoin Inner BuildLeft (6)
:- BroadcastExchange (3)
: +- Filter (2)
: +- Scan parquet spark_catalog.sparktuning.sale_course (1)
+- Filter (5)
+- Scan parquet spark_catalog.sparktuning.course_shopping_cart (4)
(1) Scan parquet spark_catalog.sparktuning.sale_course
Output [4]: [courseid#3L, coursename#5, dt#15, dn#16]
Batched: true
Location: InMemoryFileIndex [hdfs://hadoop102:8020/hive3/warehouse/sparktuning.db/sale_course/dt=20190722/dn=webA]
PartitionFilters: [isnotnull(dt#15), isnotnull(dn#16)]
PushedFilters: [IsNotNull(courseid)]
ReadSchema: struct<courseid:bigint,coursename:string>
(2) Filter
Input [4]: [courseid#3L, coursename#5, dt#15, dn#16]
Condition : isnotnull(courseid#3L)
(3) BroadcastExchange
Input [4]: [courseid#3L, coursename#5, dt#15, dn#16]
Arguments: HashedRelationBroadcastMode(List(input[0, bigint, false], input[2, string, true], input[3, string, true]),false), [plan_id=206]
(4) Scan parquet spark_catalog.sparktuning.course_shopping_cart
Output [4]: [courseid#17L, sellmoney#22, dt#23, dn#24]
Batched: true
Location: InMemoryFileIndex [hdfs://hadoop102:8020/hive3/warehouse/sparktuning.db/course_shopping_cart/dt=20190722/dn=webA]
PartitionFilters: [isnotnull(dt#23), isnotnull(dn#24)]
PushedFilters: [IsNotNull(courseid)]
ReadSchema: struct<courseid:bigint,sellmoney:string>
(5) Filter
Input [4]: [courseid#17L, sellmoney#22, dt#23, dn#24]
Condition : isnotnull(courseid#17L)
(6) BroadcastHashJoin
Left keys [3]: [courseid#3L, dt#15, dn#16]
Right keys [3]: [courseid#17L, dt#23, dn#24]
Join type: Inner
Join condition: None
(7) Project
Output [3]: [courseid#3L, coursename#5, sellmoney#22]
Input [8]: [courseid#3L, coursename#5, dt#15, dn#16, courseid#17L, sellmoney#22, dt#23, dn#24]
(8) HashAggregate
Input [3]: [courseid#3L, coursename#5, sellmoney#22]
Keys [2]: [courseid#3L, coursename#5]
Functions [1]: [partial_sum(cast(sellmoney#22 as double))]
Aggregate Attributes [1]: [sum#59]
Results [3]: [courseid#3L, coursename#5, sum#60]
(9) Exchange
Input [3]: [courseid#3L, coursename#5, sum#60]
Arguments: hashpartitioning(courseid#3L, coursename#5, 200), ENSURE_REQUIREMENTS, [plan_id=211]
(10) HashAggregate
Input [3]: [courseid#3L, coursename#5, sum#60]
Keys [2]: [courseid#3L, coursename#5]
Functions [1]: [sum(cast(sellmoney#22 as double))]
Aggregate Attributes [1]: [sum(cast(sellmoney#22 as double))#55]
Results [3]: [courseid#3L, coursename#5, sum(cast(sellmoney#22 as double))#55 AS totalsell#54]
(11) AdaptiveSparkPlan
Output [3]: [courseid#3L, coursename#5, totalsell#54]
Arguments: isFinalPlan=false总体执行计划流程如下: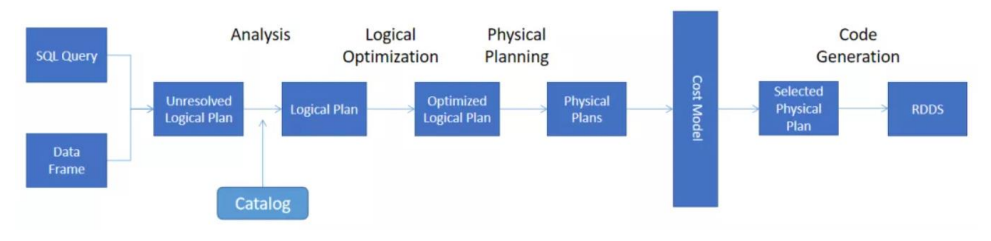 核心的执行过程一共有5个步骤:
核心的执行过程一共有5个步骤: 这些操作和计划都是Spark SQL自动处理的并生成。
这些操作和计划都是Spark SQL自动处理的并生成。
1.3 Unresolved逻辑执行计划
内容开头是:== Parsed Logical Plan ==
Parser组件检查SQL语法上是否有问题,然后生成Unresolved(未决断)的逻辑计划,不检查表名、不检查列名。
1.4 Resolved逻辑执行计划
内容开头是:== Analyzed Logical Plan ==
通过访问Spark中的Catalog存储库来解析验证语义、列名、类型、表名等。
1.5 优化后的逻辑执行计划
内容开头是:== Optimized Logical Plan ==
Catalyst优化器根据各种规则进行优化。
1.6 物理执行计划
内容开头是:== Physical Plan ==
1. HashAggregate运算符表示数据聚合,一般HashAggregate是成对出现,第一个HashAggregate是将执行节点本地的数据进行局部聚合,另一个HashAggregate是将各个分区的数据进一步进行聚合计算。
2. Exchange运算符其实就是shuffle,表示需要在集群上移动数据。很多时候HashAggregate会以Exchange分隔开来。
3. Project运算符是SQL中的投影操作,就是选择列(例如:select name, age…)。
4. BroadcastHashJoin运算符表示通过基于广播方式进行HashJoin。
5. LocalTableScan运算符就是全表扫描本地的表。
1.3 web上查看执行计划
调整下我们的执行程序,重新执行:
def main( args: Array[String] ): Unit = {
val sparkConf = new SparkConf().setAppName("ExplainDemo")
.setMaster("local[*]") //TODO 要打包提交集群执行,注释掉
val sparkSession: SparkSession = InitUtil.initSparkSession(sparkConf)
val sqlstr =
"""
|select
| sc.courseid,
| sc.coursename,
| sum(sellmoney) as totalsell
|from sale_course sc join course_shopping_cart csc
| on sc.courseid=csc.courseid and sc.dt=csc.dt and sc.dn=csc.dn
|group by sc.courseid,sc.coursename
""".stripMargin
sparkSession.sql("use sparktuning;")
sparkSession.sql(sqlstr).show()
}执行后马上访问http://localhost:4040/ ,点击SQL菜单: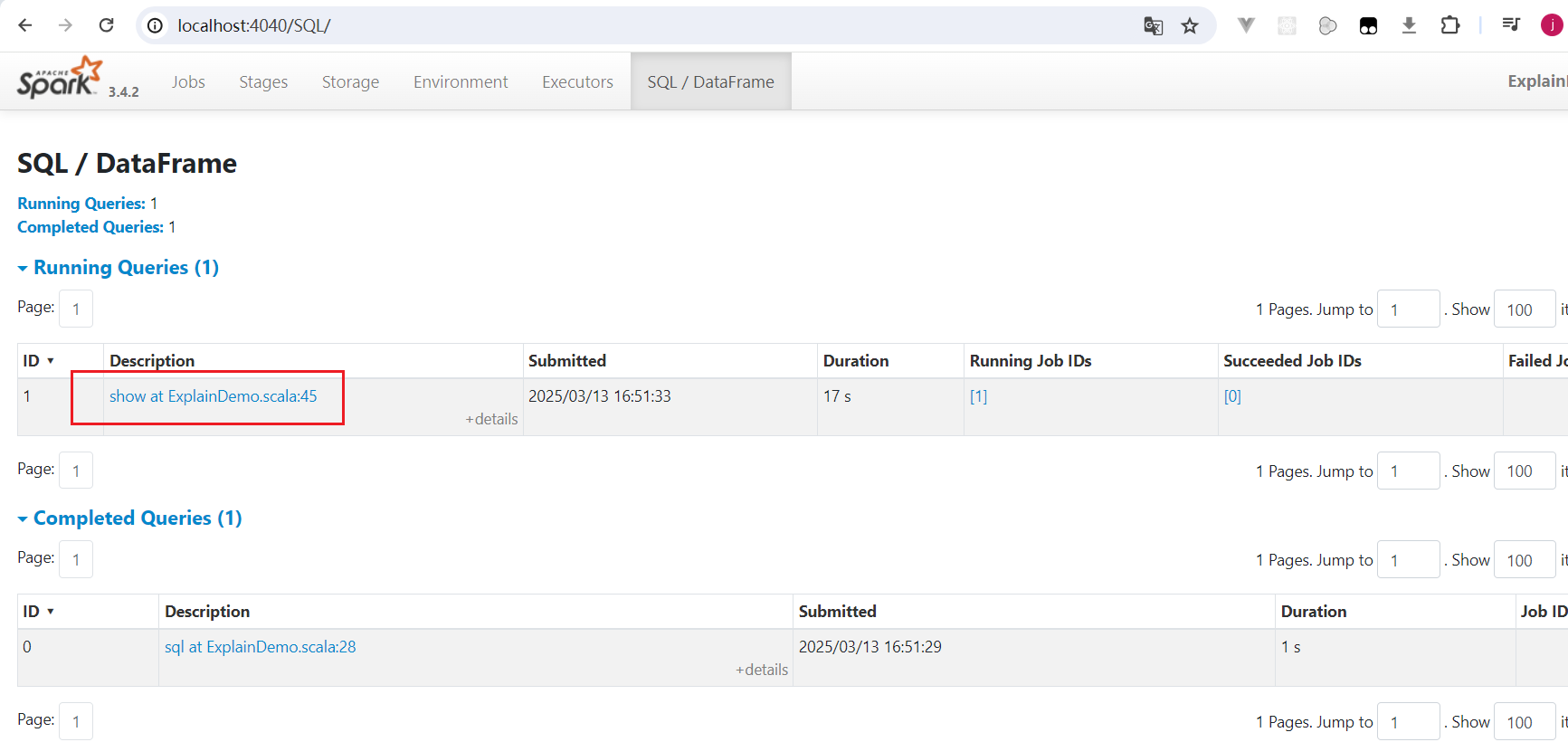 点击show的那个SQL,跳转到SQL物理执行计划可视化页面:
点击show的那个SQL,跳转到SQL物理执行计划可视化页面: 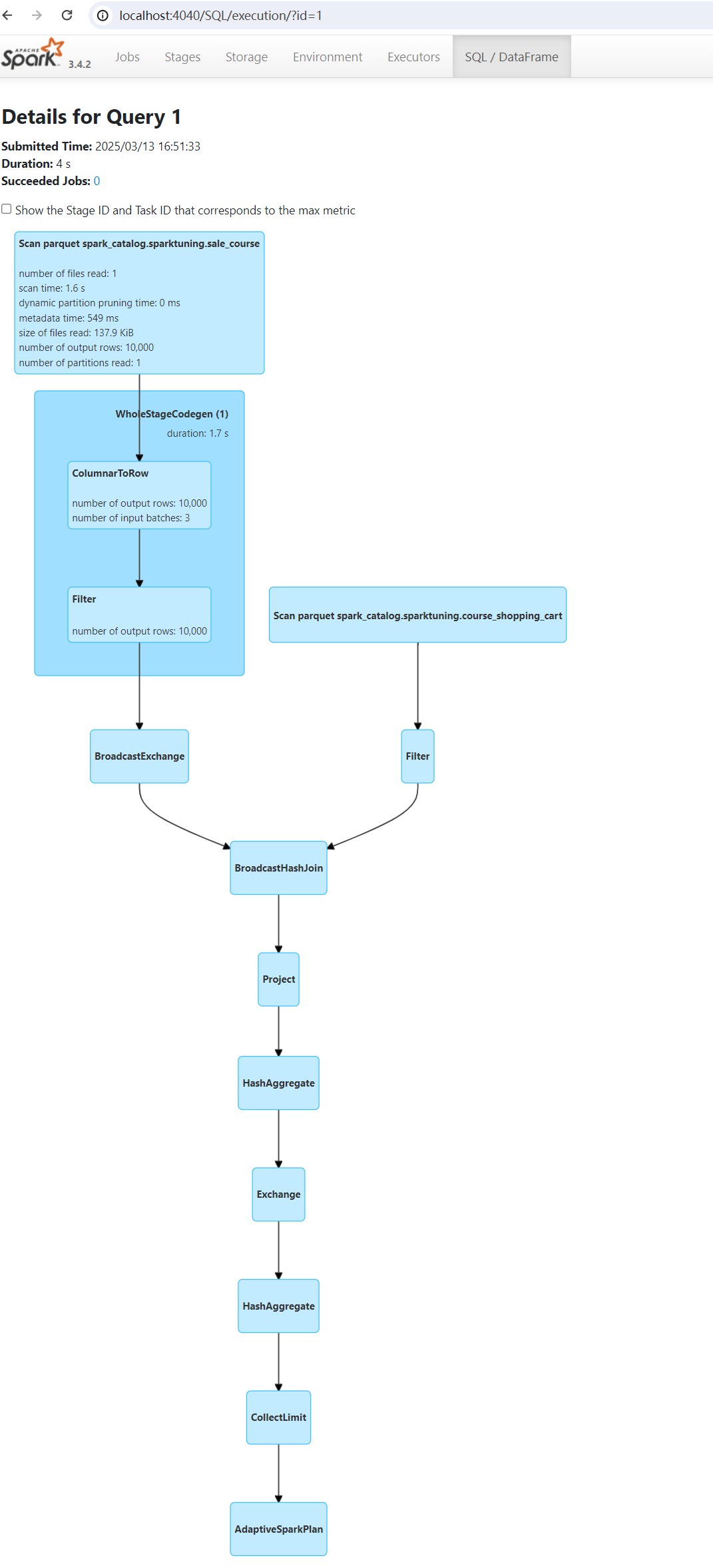
2. 资源调优
2.1 资源设定考虑
- 总体原则
以单台服务器128G内存,32线程为例。
先设定单个Executor核数,根据Yarn配置得出每个节点最多的Executor数量,每个节点的yarn内存/每个节点数量=单个节点的数量。
总的executor数=单节点数量*节点数。 - 具体提交参数
1)executor-cores
每个executor的最大核数。根据经验实践,设定在3~6之间比较合理。
2)num-executors
该参数值=每个节点的executor数*work节点数
每个node的executor数=单节点yarn总核数/每个executor的最大cpu核数。考虑到系统基础服务和HDFS等组件的余量,yarn.nodemanager.resource.cpu-vcores配置为:28,参数executor-cores的值为:4,那么每个node的executor数=28/4=7,假设集群节点为10,那么num-executors=7*10=70
3)executor-memory
该参数值=yarn-nodemanager.resource.memory-mb/每个节点的executor数量
如果yarn的参数配置为100G,那么每个Executor大概就是100G/7≈14G,同时要注意yarn配置中每个容器允许的最大内存是否匹配。
2.2 内存估算
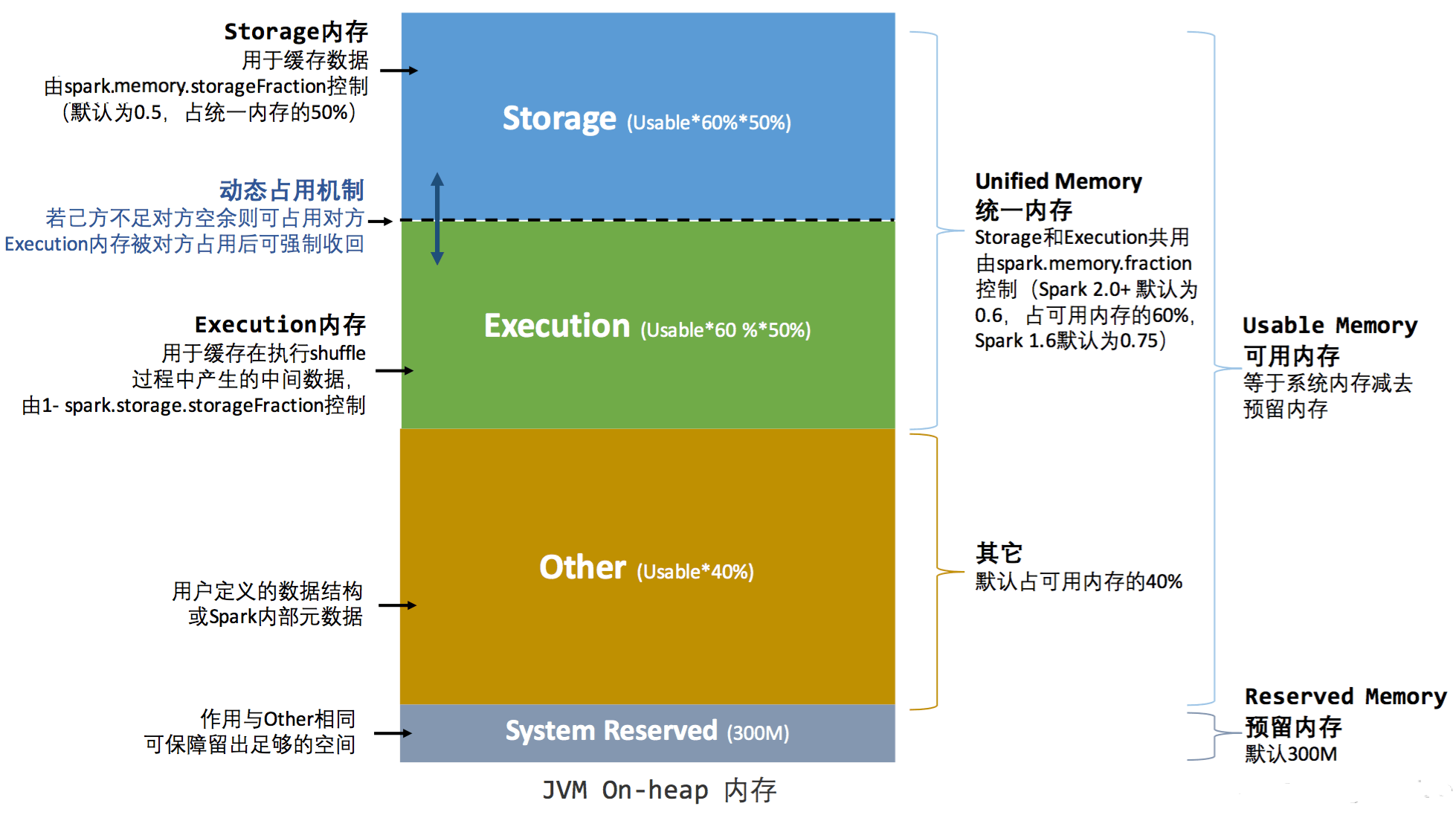 ➢ 估算Other内存 = 自定义数据结构*每个Executor核数
➢ 估算Other内存 = 自定义数据结构*每个Executor核数
➢ 估算Storage内存 = 广播变量 + cache/Executor数量
➢ 估算Executor内存 = 每个Executor核数 * (数据集大小/并行度)
2.3 调整内存配置项
一般情况下,各个区域的内存比例保持默认值即可。如果需要更加精确的控制内存分配,可以按照如下思路: spark.memory.fraction=(估算storage内存+估算Execution内存)/(估算storage内存 +估算Execution内存+估算Other内存)得到
spark.memory.storageFraction=(估算storage内存)/(估算storage内存+估算Execution内存) 代入公式计算:
Storage堆内内存=(spark.executor.memory–300MB)*spark.memory.fraction*spark.memory.storageFraction
Execution堆内内存=(spark.executor.memory–300MB)*spark.memory.fraction*(1-spark.memory.storageFraction)3. 持久化和序列化
3.1 RDD内存占用分析
编写RddCacheDemo:
object RddCacheDemo {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("RddCacheDemo")
val sparkSession: SparkSession = InitUtil.initSparkSession(sparkConf)
// 转换成rdd
val result = sparkSession.sql("select * from sparktuning.course_pay").rdd
// 缓存到内存中
result.cache()
result.foreachPartition((p: Iterator[Row]) => p.foreach(item => println(item.get(0))))
while (true) {
//因为历史服务器上看不到,storage内存占用,所以这里加个死循环 不让sparkcontext立马结束
}
}
}打包发布到hadoop集群上:
[jack@hadoop103 software]$ spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 2 --executor-memory 6g --class com.rocket.sparktuning.cache.RddCacheDemo spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar访问ResourceManager的UI页面,点击ApplicationMaster连接,跳转查看SparkUI: 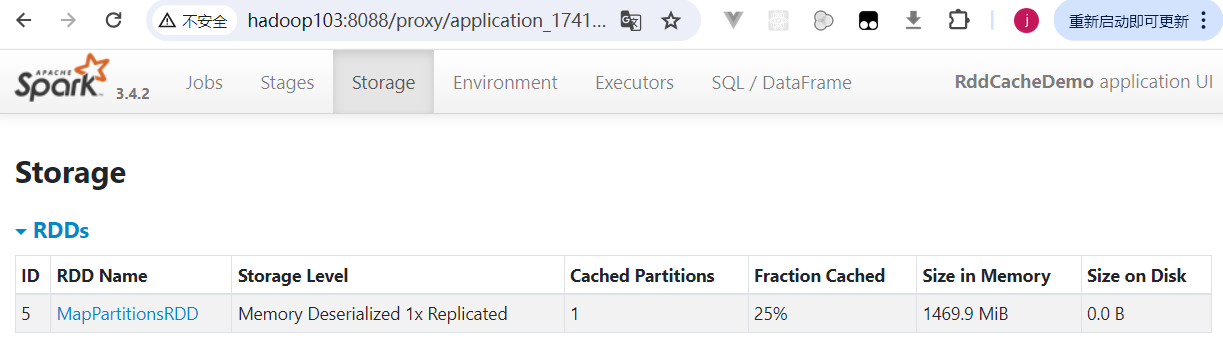 通过spark ui看到,rdd使用默认cache缓存级别,占用内存1.5GB,并且storage内存还不够,只缓存了29%。
通过spark ui看到,rdd使用默认cache缓存级别,占用内存1.5GB,并且storage内存还不够,只缓存了29%。
3.2 Rdd使用kryo+序列化缓存
只增加序列化代码,重新打包:
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf()
.setAppName("RddCacheKryoDemo")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.registerKryoClasses(Array(classOf[CoursePay]))
val sparkSession: SparkSession = InitUtil.initSparkSession(sparkConf)
import sparkSession.implicits._
// 转换成rdd
val result = sparkSession.sql("select * from sparktuning.course_pay").as[CoursePay].rdd
// 缓存到内存中,指明使用序列化方式
result.persist(StorageLevel.MEMORY_ONLY_SER)
result.foreachPartition((p: Iterator[CoursePay]) => p.foreach(item => println(item.orderid)))
while (true) {
//因为历史服务器上看不到,storage内存占用,所以这里加个死循环 不让sparkcontext立马结束
}
}再次部署到yarn中,观察spark ui: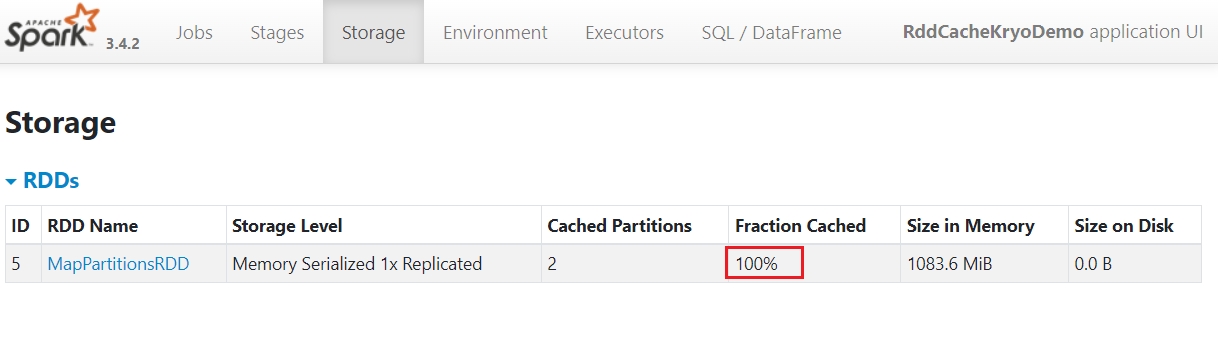
查看storage所占内存,内存占用了1083.6mb, 并且缓存了100%。使用序列化缓存配合kryo序列化,可以优化存储内存占用。
总结:如果yarn内存资源充足情况下,使用默认级别MEMORY_ONLY是对CPU的支持最好的。但是序列化缓存可以让体积更小,那么当yarn内存资源不充足情况下可以考虑使用MEMORY_ONLY_SER配合kryo使用序列化缓存。
3.3 DF和DS内存占用分析
编写DatasetCacheDemo代码:
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("DataSetCacheDemo")
val sparkSession: SparkSession = InitUtil.initSparkSession(sparkConf)
import sparkSession.implicits._
// 使用Dataset的cache方法
val result = sparkSession.sql("select * from sparktuning.course_pay").as[CoursePay]
result.cache()
result.foreachPartition((p: Iterator[CoursePay]) => p.foreach(item => println(item.orderid)))
while (true) {
}
}打包发布到hadoop集群上:
[jack@hadoop103 software]$ spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 2 --executor-memory 6g --class com.rocket.sparktuning.cache.DatasetCacheDemo spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar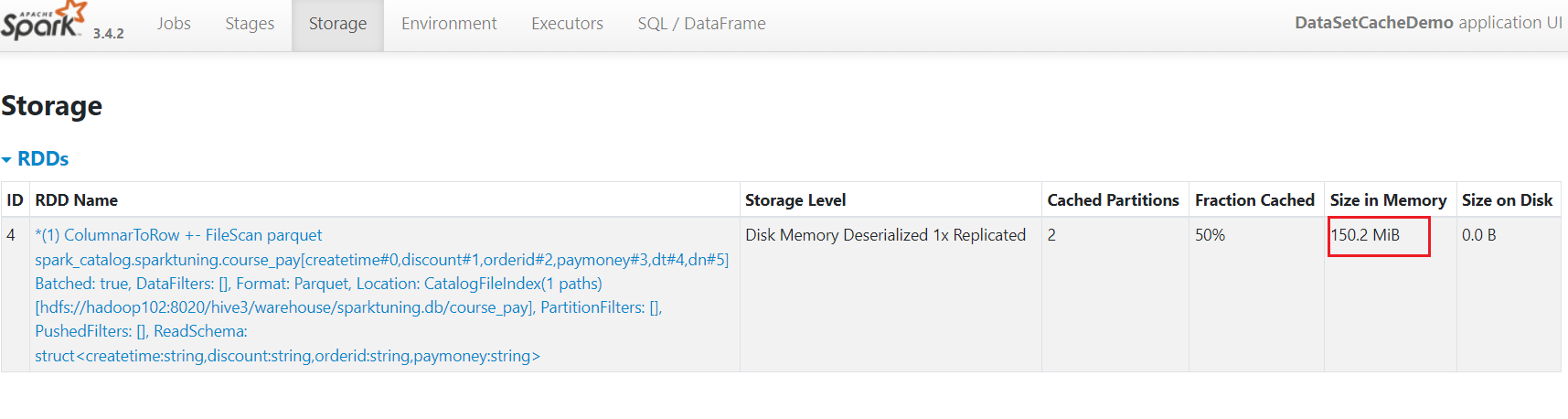 DataSet的cache默认缓存级别与RDD不一样,是MEMORY_AND_DISK(RDD的默认缓存级别是MEMORY_ONLY),所以占用缓存才只有150.2M。
DataSet的cache默认缓存级别与RDD不一样,是MEMORY_AND_DISK(RDD的默认缓存级别是MEMORY_ONLY),所以占用缓存才只有150.2M。
3.4 DF和DS使用序列化缓存
DataSet并不使用JAVA序列化也不使用Kryo序列化,而是使用一种特有的编码器进行序列化对象。  调整代码如下:
调整代码如下:
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf()
.setAppName("DatasetCacheSerDemo")
val sparkSession: SparkSession = InitUtil.initSparkSession(sparkConf)
import sparkSession.implicits._
val result = sparkSession.sql("select * from sparktuning.course_pay").as[CoursePay]
// 指明使用序列化方式缓存
result.persist(StorageLevel.MEMORY_AND_DISK_SER)
result.foreachPartition((p: Iterator[CoursePay]) => p.foreach(item => println(item.orderid)))
while (true) {
//因为历史服务器上看不到,storage内存占用,所以这里加个死循环 不让sparkcontext立马结束
}
}打成jar包,提交yarn。查看spark ui,storage占用内存341.3M,但是cache全部使用的是内存。所以DataSet可以直接使用cache。 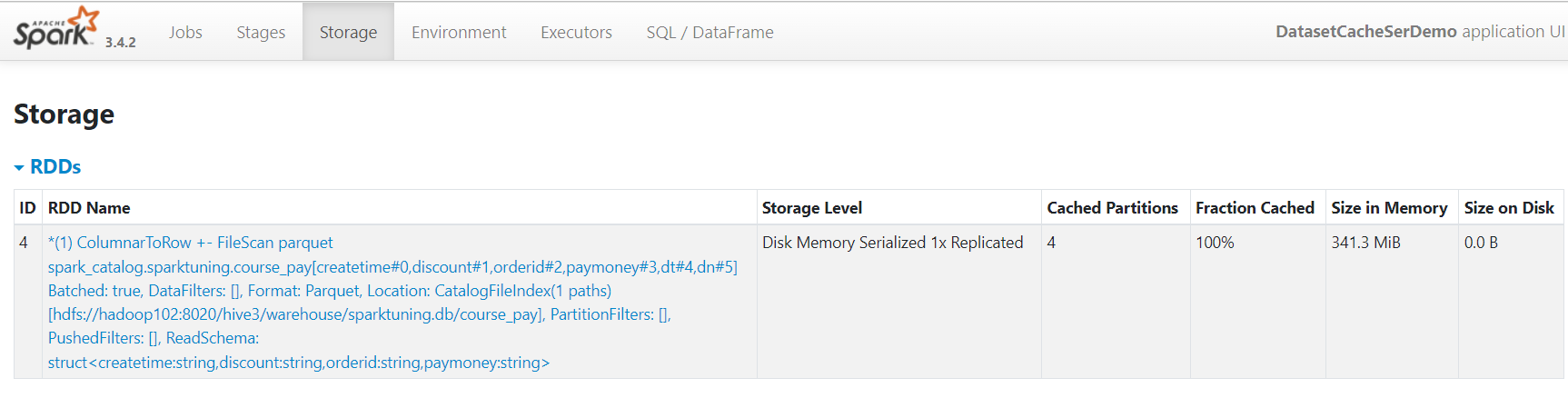 从性能上来讲,DataSet,DataFrame大于RDD,建议开发中使用DataSet、DataFrame。
从性能上来讲,DataSet,DataFrame大于RDD,建议开发中使用DataSet、DataFrame。
4. CPU低效优化
4.1 spark.default.parallelism
如果没有设置RDD的默认并行度时,由join、reduceByKey和parallelize等转换决定。
4.2 spark.sql.shuffle.partitions
适用SparkSQL时,Shuffle Reduce阶段默认的并行度,默认200。此参数只能控制Spark sql、DataFrame、DataSet分区个数。不能控制RDD分区个数。
4.3 CPU低效原因
1)并行度较低、数据分片较大容易导致CPU线程挂起
2)并行度过高、数据过于分散会让调度开销更多
数据过于分散会让调度开销的原因:Executor接收到TaskDescription之后,首先需要对TaskDescription反序列化才能读取任务信息,然后将任务代码再反序列化得到可执行代码,最后再结合其他任务信息创建TaskRunner。当数据过于分散,分布式任务数量会大幅增加,但每个任务需要处理的数据量却少之又少,就CPU消耗来说,相比花在数据处理上的比例,任务调度上的开销几乎与之分庭抗礼。显然,在这种情况下,CPU的有效利用率也是极低的。
4.4 合理利用CPU资源
每个并行度的数据量(总数据量/并行度)在(Executor内存/core数/2, Executor内存/core数)区间。为了合理利用资源,一般会将并行度(task 数)设置成并发度(vcore数)的2倍到3倍。
编写PartitionTuning代码:
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("PartitionTuning")
.set("spark.sql.autoBroadcastJoinThreshold", "-1") //为了演示效果,先禁用了广播join
.set("spark.sql.shuffle.partitions", "36")
val sparkSession: SparkSession = InitUtil.initSparkSession(sparkConf)
//查询出三张表 并进行join 插入到最终表中
val saleCourse = sparkSession.sql("select * from sparktuning.sale_course")
val coursePay = sparkSession.sql("select * from sparktuning.course_pay")
.withColumnRenamed("discount", "pay_discount")
.withColumnRenamed("createtime", "pay_createtime")
val courseShoppingCart = sparkSession.sql("select * from sparktuning.course_shopping_cart")
.drop("coursename")
.withColumnRenamed("discount", "cart_discount")
.withColumnRenamed("createtime", "cart_createtime")
saleCourse
.join(courseShoppingCart, Seq("courseid", "dt", "dn"), "right")
.join(coursePay, Seq("orderid", "dt", "dn"), "left")
.select("courseid", "coursename", "status", "pointlistid", "majorid", "chapterid", "chaptername", "edusubjectid"
, "edusubjectname", "teacherid", "teachername", "coursemanager", "money", "orderid", "cart_discount", "sellmoney",
"cart_createtime", "pay_discount", "paymoney", "pay_createtime", "dt", "dn")
.write.mode(SaveMode.Overwrite).saveAsTable("sparktuning.salecourse_detail")
}提交参数执行:
## 总共使用12个core
[jack@hadoop103 software]$ spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 4 --executor-memory 6g --class com.rocket.sparktuning.partition.PartitionTuning spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar打成jar包,提交yarn。查看spark ui: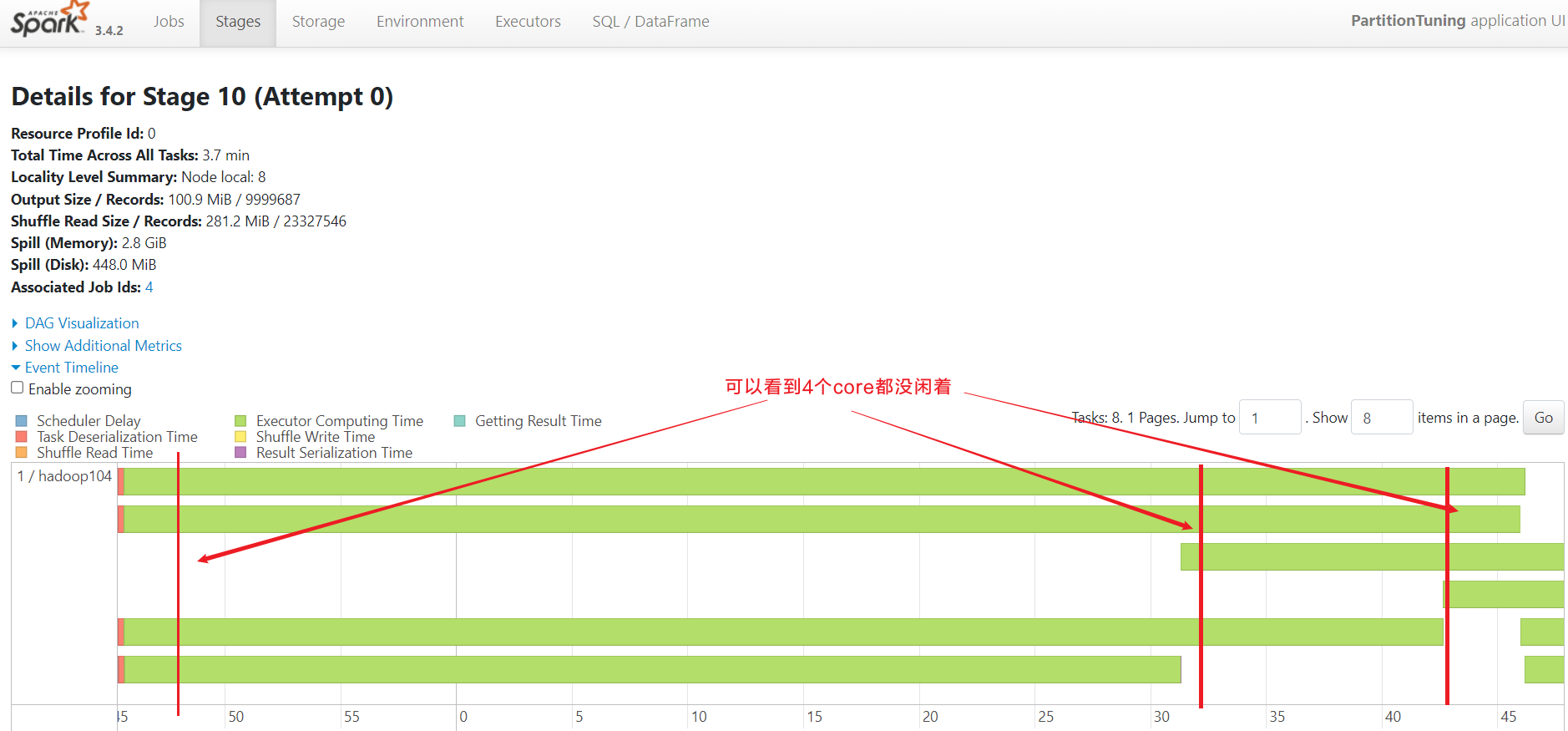
5. SparkSQL语法优化
SparkSQL在整个执行计划处理的过程中,使用了Catalyst优化器。
5.1 基于RBO的优化
在Spark3.0版本中,Catalyst总共有81条优化规则(Rules),分成27组(Batches),其中有些规则会被归类到多个分组里。因此,如果不考虑规则的重复性,27组算下来总共会有129个优化规则。
如果从优化效果的角度出发,这些规则可以归纳到以下3个范畴:谓词下推、列剪裁、常量替换
5.2 谓词下推
将过滤条件的谓词逻辑都尽可能提前执行,减少下游处理的数据量。对应PushDownPredicte优化规则,对于Parquet、ORC这类存储格式,结合文件注脚(Footer)中的统计信息,下推的谓词能够大幅减少数据扫描量,降低磁盘I/O开销。
所谓谓词就是where后的条件和on后的条件。
左表inner join右表时候: 两表都下推。
左表left join右表时候: where条件两表都下推,on条件只下推右表。
5.3 列剪裁(Column Pruning)
列剪裁就是扫描数据源的时候,只读取那些与查询相关的字段(查看执行计划中Project节点信息)。
5.4 常量替换(Constant Folding)
假设我们在年龄上加的过滤条件是“age < 12 + 18”,Catalyst会使用ConstantFolding规则,自动帮我们把条件变成“age < 30”。再比如,我们在select语句中,掺杂了一些常量表达式,Catalyst也会自动地用表达式的结果进行替换。
5.5 基于CBO的优化
CBO优化主要在物理计划层面,原理是计算所有可能的物理计划的代价,并挑选出代价最小的物理执行计划。充分考虑了数据本身的特点(如大小、分布)以及操作算子的特点(中间结果集的分布及大小)及代价,从而更好的选择执行代价最小的物理执行计划。
每个执行节点的代价,分为两个部分:
- 该执行节点对数据集的影响,即该节点输出数据集的大小与分布
- 该执行节点操作算子的代价
每个操作算子的代价相对固定,可用规则来描述。而执行节点输出数据集的大小与分布,分为两个部分:
- 初始数据集,也即原始表,其数据集的大小与分布可直接通过统计得到。
- 中间节点输出数据集的大小与分布可由其输入数据集的信息与操作本身的特点推算。
5.6 Statistics收集
需要先执行特定的SQL语句来收集所需的表和列的统计信息。生成表级别统计信息(扫表):
ANALYZE TABLE 表名 COMPUTE STATISTICS生成文件大小sizeInBytes和行数rowCount。需要注意的是使用ANALYZE语句收集统计信息时,无法计算非HDFS数据源的表的文件大小。
生成列级别统计信息:
ANALYZE TABLE 表名 COMPUTE STATISTICS FOR COLUMNS 列 1,列 2,列 3生成列统计信息,为保证一致性,会同步更新表统计信息。目前不支持复杂数据类型(如 Seq, Map等)和 HiveStringType的统计信息生成。 生成统计信息后,可以使用DESC命令进行查看:
DESC FORMATTED 表名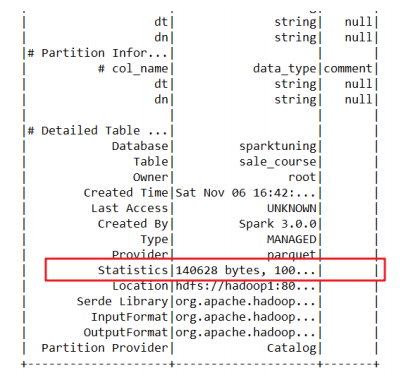 编写StaticsCollect代码:
编写StaticsCollect代码:
object StaticsCollect {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("CBOTunning")
.setMaster("local[*]") // 要打包提交集群执行,注释掉
val sparkSession: SparkSession = InitUtil.initSparkSession(sparkConf)
AnalyzeTableAndColumn(sparkSession, "sparktuning.sale_course", "courseid,dt,dn")
AnalyzeTableAndColumn(sparkSession, "sparktuning.course_shopping_cart", "courseid,orderid,dt,dn")
AnalyzeTableAndColumn(sparkSession, "sparktuning.course_pay", "orderid,dt,dn")
}
private def AnalyzeTableAndColumn(sparkSession: SparkSession, tableName: String, columnListStr: String): Unit = {
// 查看 表级别 信息
println("=========================================查看" + tableName + "表级别 信息========================================")
sparkSession.sql("DESC FORMATTED " + tableName).show(100)
// 统计 表级别 信息
println("=========================================统计 " + tableName + "表级别 信息========================================")
sparkSession.sql("ANALYZE TABLE " + tableName + " COMPUTE STATISTICS").show()
// 再查看 表级别 信息
println("======================================查看统计后 " + tableName + "表级别 信息======================================")
sparkSession.sql("DESC FORMATTED " + tableName).show(100)
// 查看 列级别 信息
println("=========================================查看 " + tableName + "表的" + columnListStr + "列级别 信息========================================")
val columns: Array[String] = columnListStr.split(",")
for (column <- columns) {
sparkSession.sql("DESC FORMATTED " + tableName + " " + column).show()
}
// 统计 列级别 信息
println("=========================================统计 " + tableName + "表的" + columnListStr + "列级别 信息========================================")
sparkSession.sql(
s"""
|ANALYZE TABLE ${tableName}
|COMPUTE STATISTICS
|FOR COLUMNS $columnListStr
""".stripMargin).show()
// 再查看 列级别 信息
println("======================================查看统计后 " + tableName + "表的" + columnListStr + "列级别 信息======================================")
for (column <- columns) {
sparkSession.sql("DESC FORMATTED " + tableName + " " + column).show()
}
}
}5.7 使用CBO
通过"spark.sql.cbo.enabled"来开启,默认是false。配置开启CBO后,CBO优化器可以基于表和列的统计信息,进行一系列的估算,最终选择出最优的查询计划。比如:Build侧选择、优化Join类型、优化多表Join顺序等。
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("CBOTuning")
// 开启cbo
.set("spark.sql.cbo.enabled", "true")
// .set("spark.sql.cbo.joinReorder.enabled", "true")
.setMaster("local[*]")
val sparkSession: SparkSession = InitUtil.initSparkSession(sparkConf)
val sqlstr =
"""
|select
| csc.courseid,
| sum(cp.paymoney) as coursepay
|from course_shopping_cart csc,course_pay cp
|where csc.orderid=cp.orderid
|and cp.orderid ='odid-0'
|group by csc.courseid
""".stripMargin
sparkSession.sql("use sparktuning;")
sparkSession.sql(sqlstr).show()
while (true) {}
}5.8 广播Join
Spark join策略中,如果当一张小表足够小并且可以先缓存到内存中,那么可以使用Broadcast Hash Join,其原理就是先将小表聚合到driver端,再广播到各个大表分区中,那么再次进行join的时候,就相当于大表的各自分区的数据与小表进行本地join,从而规避了shuffle。(类似Hive中的MapJoin)
- 通过参数指定自动广播
广播join默认值为10MB,由spark.sql.autoBroadcastJoinThreshold参数控制。
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("BroadcastJoinTuning")
// .set("spark.sql.autoBroadcastJoinThreshold","10m")
.setMaster("local[*]") // 要打包提交集群执行,注释掉
val sparkSession: SparkSession = InitUtil.initSparkSession(sparkConf)
val sqlstr =
"""
|select
| sc.courseid,
| csc.courseid
|from sale_course sc join course_shopping_cart csc
|on sc.courseid=csc.courseid
""".stripMargin
sparkSession.sql("use sparktuning;")
sparkSession.sql(sqlstr).show()
while (true) {}
}- 强行广播
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("ForceBroadcastJoinTuning")
.set("spark.sql.autoBroadcastJoinThreshold", "-1") // 关闭自动广播
.setMaster("local[*]") // 要打包提交集群执行,注释掉
val sparkSession: SparkSession = InitUtil.initSparkSession(sparkConf)
// SQL Hint方式
val sqlstr1 =
"""
|select /*+ BROADCASTJOIN(sc) */
| sc.courseid,
| csc.courseid
|from sale_course sc join course_shopping_cart csc
|on sc.courseid=csc.courseid
""".stripMargin
val sqlstr2 =
"""
|select /*+ BROADCAST(sc) */
| sc.courseid,
| csc.courseid
|from sale_course sc join course_shopping_cart csc
|on sc.courseid=csc.courseid
""".stripMargin
val sqlstr3 =
"""
|select /*+ MAPJOIN(sc) */
| sc.courseid,
| csc.courseid
|from sale_course sc join course_shopping_cart csc
|on sc.courseid=csc.courseid
""".stripMargin
sparkSession.sql("use sparktuning;")
println("=======================BROADCASTJOIN Hint=============================")
sparkSession.sql(sqlstr1).explain()
println("=======================BROADCAST Hint=============================")
sparkSession.sql(sqlstr2).explain()
println("=======================MAPJOIN Hint=============================")
sparkSession.sql(sqlstr3).explain()
// API的方式
val sc: DataFrame = sparkSession.sql("select * from sale_course").toDF()
val csc: DataFrame = sparkSession.sql("select * from course_shopping_cart").toDF()
println("=======================DF API=============================")
import org.apache.spark.sql.functions._
broadcast(sc)
.join(csc, Seq("courseid"))
.select("courseid")
.explain()
}5.9 SMB Join
SMB JOIN是sort merge bucket操作,需要进行分桶,首先会进行排序,然后根据key值合并,把相同key的数据放到同一个bucket中(按照key进行hash)。分桶的目的其实就是把大表化成小表。相同key的数据都在同一个桶中之后,再进行join操作,那么在联合的时候就会大幅度的减小无关项的扫描。使用条件:
(1)两表进行分桶,桶的个数必须相等
(2)两边进行join时,join列=排序列=分桶列
使用SMB Join:
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("SMBJoinTuning")
.set("spark.sql.shuffle.partitions", "36")
val sparkSession: SparkSession = InitUtil.initSparkSession(sparkConf)
useSMBJoin(sparkSession)
}
def useSMBJoin(sparkSession: SparkSession) = {
//查询出三张表 并进行join 插入到最终表中
val saleCourse = sparkSession.sql("select * from sparktuning.sale_course")
val coursePay = sparkSession.sql("select * from sparktuning.course_pay_cluster")
.withColumnRenamed("discount", "pay_discount")
.withColumnRenamed("createtime", "pay_createtime")
val courseShoppingCart = sparkSession.sql("select * from sparktuning.course_shopping_cart_cluster")
.drop("coursename")
.withColumnRenamed("discount", "cart_discount")
.withColumnRenamed("createtime", "cart_createtime")
// 要大表优先和大表join, 如果分桶表和其他表join结果就不再是分桶表,再使用就不能使用SMB Join
val tmpdata = courseShoppingCart.join(coursePay, Seq("orderid"), "left")
val result = broadcast(saleCourse).join(tmpdata, Seq("courseid"), "right")
result
.select("courseid", "coursename", "status", "pointlistid", "majorid", "chapterid", "chaptername", "edusubjectid"
, "edusubjectname", "teacherid", "teachername", "coursemanager", "money", "orderid", "cart_discount", "sellmoney",
"cart_createtime", "pay_discount", "paymoney", "pay_createtime", "sparktuning.sale_course.dt", "sparktuning.sale_course.dn")
.write
.mode(SaveMode.Overwrite)
.saveAsTable("sparktuning.salecourse_detail_2")
}6. 数据倾斜
6.1 数据倾斜现象
绝大多数task任务运行速度很快,但是就是有那么几个task任务运行极其缓慢,慢慢的可能就接着报内存溢出的问题。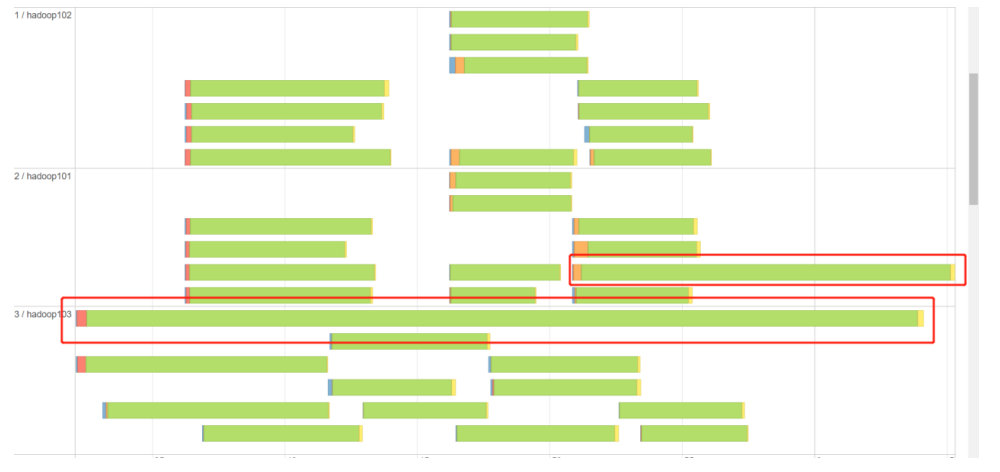 原因: 数据倾斜一般是发生在shuffle类的算子,比如distinct、groupByKey、reduceByKey、 aggregateByKey、join、cogroup等,涉及到数据重分区,如果其中某一个key数量特别大,就发生了数据倾斜。
原因: 数据倾斜一般是发生在shuffle类的算子,比如distinct、groupByKey、reduceByKey、 aggregateByKey、join、cogroup等,涉及到数据重分区,如果其中某一个key数量特别大,就发生了数据倾斜。
6.2 数据倾斜大key定位
从所有key中,把其中每一个key随机取出来一部分,然后进行一个百分比的推算,这是用局部取推算整体,虽然有点不准确,但是在整体概率上来说,我们只需要大概就可以定位那个最多的key了。
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("BigJoinDemo")
.set("spark.sql.shuffle.partitions", "36")
.setMaster("local[*]")
val sparkSession: SparkSession = InitUtil.initSparkSession(sparkConf)
println("=============================================csc courseid sample=============================================")
val cscTopKey: Array[(Int, Row)] = sampleTopKey(sparkSession, "sparktuning.course_shopping_cart", "courseid")
println(cscTopKey.mkString("\n"))
println("=============================================sc courseid sample=============================================")
val scTopKey: Array[(Int, Row)] = sampleTopKey(sparkSession, "sparktuning.sale_course", "courseid")
println(scTopKey.mkString("\n"))
println("=============================================cp orderid sample=============================================")
val cpTopKey: Array[(Int, Row)] = sampleTopKey(sparkSession, "sparktuning.course_pay", "orderid")
println(cpTopKey.mkString("\n"))
println("=============================================csc orderid sample=============================================")
val cscTopOrderKey: Array[(Int, Row)] = sampleTopKey(sparkSession, "sparktuning.course_shopping_cart", "orderid")
println(cscTopOrderKey.mkString("\n"))
}
def sampleTopKey(sparkSession: SparkSession, tableName: String, keyColumn: String): Array[(Int, Row)] = {
val df: DataFrame = sparkSession.sql("select " + keyColumn + " from " + tableName)
val top10Key = df
.select(keyColumn).sample(false, 0.1).rdd // 对key不放回采样
.map(k => (k, 1)).reduceByKey(_ + _) // 统计不同key出现的次数
.map(k => (k._2, k._1)).sortByKey(false) // 统计的key进行排序
.take(10)
top10Key
}执行结果: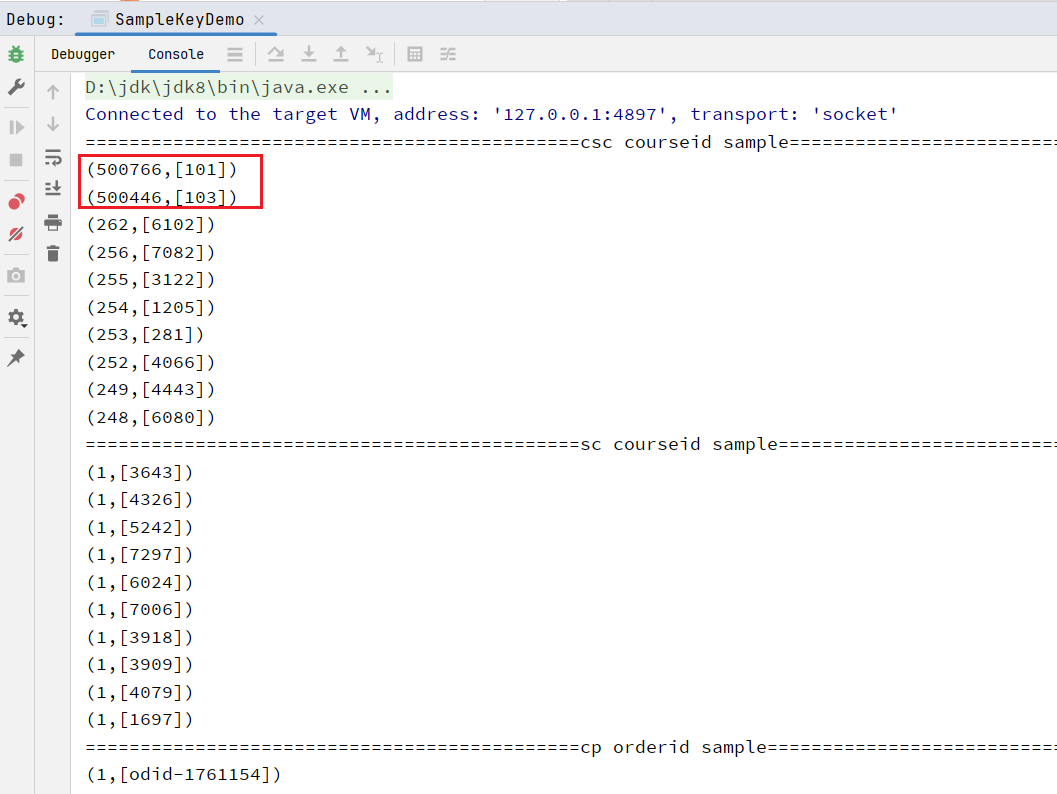 可以看出course_shopping_cart表中courseid列有数据不均现象。
可以看出course_shopping_cart表中courseid列有数据不均现象。
6.3 单表数据倾斜优化
为了减少shuffle数据量以及reduce端的压力,通常Spark SQL在map端会做一个partial aggregate(通常叫做预聚合或者偏聚合),即在shuffle前将同一分区内所属同key的记录先进行一个预结算,再将结果进行shuffle,发送到 reduce端做一个汇总,类似MR的提前Combiner,所以执行计划中HashAggregate通常成对出现。
- 适用场景
聚合类的shuffle操作,部分key数据量较大,且大key的数据分布在很多不同的切片。 - 解决逻辑
两阶段聚合(加盐局部聚合+去盐全局聚合)
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("SkewAggregationTuning")
.set("spark.sql.shuffle.partitions", "36")
// .setMaster("local[*]")
val sparkSession: SparkSession = InitUtil.initSparkSession(sparkConf)
sparkSession.udf.register("random_prefix", (value: Int, num: Int) => randomPrefixUDF(value, num))
sparkSession.udf.register("remove_random_prefix", (value: String) => removeRandomPrefixUDF(value))
val sql1 =
"""
|select
| courseid,
| sum(course_sell) totalSell
|from
| (
| select
| remove_random_prefix(random_courseid) courseid,
| course_sell
| from
| (
| select
| random_courseid,
| sum(sellmoney) course_sell
| from
| (
| select
| random_prefix(courseid, 6) random_courseid,
| sellmoney
| from
| sparktuning.course_shopping_cart
| ) t1
| group by random_courseid
| ) t2
| ) t3
|group by
| courseid
""".stripMargin
sparkSession.sql(sql1).show(10000)
// while(true){}
}
def randomPrefixUDF(value: Int, num: Int): String = {
new Random().nextInt(num).toString + "_" + value
}
def removeRandomPrefixUDF(value: String): String = {
value.toString.split("_")(1)
}6.4 Join数据倾斜优化
6.4.1 广播Join
- 适用场景: 适用于小表join大表。小表足够小,可被加载进Driver并通过Broadcast方法广播到各个Executor中。
- 解决逻辑
在小表join大表时如果产生数据倾斜,那么广播join可以直接规避掉此shuffle阶段。直接优化掉stage。并且广播join也是Spark Sql中最常用的优化方案。
6.4.2 拆分大key打散大表扩容小表
- 适用场景: 适用于join时出现数据倾斜。
- 解决逻辑:
1)将存在倾斜的表,根据抽样结果,拆分为倾斜key(skew表)和没有倾斜key(common)的两个数据集。 2)将skew表的key全部加上随机前缀,然后对另外一个不存在严重数据倾斜的数据集(old表)整体与随机前缀集作笛卡尔乘积(即将数据量扩大N倍,得到new表)。 3)打散的skew表join扩容的new表
4)使用union合并(common表join old表的结果集)
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("SkewJoinTuning")
.set("spark.sql.autoBroadcastJoinThreshold", "-1")
.set("spark.sql.shuffle.partitions", "36")
.setMaster("local[*]")
val sparkSession: SparkSession = InitUtil.initSparkSession(sparkConf)
scatterBigAndExpansionSmall(sparkSession)
// while(true){}
}
// 打散大表 扩容小表 解决数据倾斜
def scatterBigAndExpansionSmall(sparkSession: SparkSession): Unit = {
import sparkSession.implicits._
val saleCourse = sparkSession.sql("select *from sparktuning.sale_course")
val coursePay = sparkSession.sql("select * from sparktuning.course_pay")
.withColumnRenamed("discount", "pay_discount")
.withColumnRenamed("createtime", "pay_createtime")
val courseShoppingCart = sparkSession.sql("select * from sparktuning.course_shopping_cart")
.withColumnRenamed("discount", "cart_discount")
.withColumnRenamed("createtime", "cart_createtime")
// 1、拆分 倾斜的key
val commonCourseShoppingCart: Dataset[Row] = courseShoppingCart.filter(item => item.getAs[Long]("courseid") != 101 && item.getAs[Long]("courseid") != 103)
val skewCourseShoppingCart: Dataset[Row] = courseShoppingCart.filter(item => item.getAs[Long]("courseid") == 101 || item.getAs[Long]("courseid") == 103)
// 2、将倾斜的key打散 打散36份
val newCourseShoppingCart = skewCourseShoppingCart.mapPartitions((partitions: Iterator[Row]) => {
partitions.map(item => {
val courseid = item.getAs[Long]("courseid")
val randInt = Random.nextInt(36)
CourseShoppingCart(courseid, item.getAs[String]("orderid"),
item.getAs[String]("coursename"), item.getAs[String]("cart_discount"),
item.getAs[String]("sellmoney"), item.getAs[String]("cart_createtime"),
item.getAs[String]("dt"), item.getAs[String]("dn"), randInt + "_" + courseid)
})
})
// 3、小表进行扩容 扩大36倍
val newSaleCourse = saleCourse.flatMap(item => {
val list = new ArrayBuffer[SaleCourse]()
val courseid = item.getAs[Long]("courseid")
val coursename = item.getAs[String]("coursename")
val status = item.getAs[String]("status")
val pointlistid = item.getAs[Long]("pointlistid")
val majorid = item.getAs[Long]("majorid")
val chapterid = item.getAs[Long]("chapterid")
val chaptername = item.getAs[String]("chaptername")
val edusubjectid = item.getAs[Long]("edusubjectid")
val edusubjectname = item.getAs[String]("edusubjectname")
val teacherid = item.getAs[Long]("teacherid")
val teachername = item.getAs[String]("teachername")
val coursemanager = item.getAs[String]("coursemanager")
val money = item.getAs[String]("money")
val dt = item.getAs[String]("dt")
val dn = item.getAs[String]("dn")
for (i <- 0 until 36) {
list.append(SaleCourse(courseid, coursename, status, pointlistid, majorid, chapterid, chaptername, edusubjectid,
edusubjectname, teacherid, teachername, coursemanager, money, dt, dn, i + "_" + courseid))
}
list
})
// 4、倾斜的大key 与 扩容后的表 进行join
val df1: DataFrame = newSaleCourse
.join(newCourseShoppingCart.drop("courseid").drop("coursename"), Seq("rand_courseid", "dt", "dn"), "right")
.join(coursePay, Seq("orderid", "dt", "dn"), "left")
.select("courseid", "coursename", "status", "pointlistid", "majorid", "chapterid", "chaptername", "edusubjectid"
, "edusubjectname", "teacherid", "teachername", "coursemanager", "money", "orderid", "cart_discount", "sellmoney",
"cart_createtime", "pay_discount", "paymoney", "pay_createtime", "dt", "dn")
// 5、没有倾斜大key的部分 与 原来的表 进行join
val df2: DataFrame = saleCourse
.join(commonCourseShoppingCart.drop("coursename"), Seq("courseid", "dt", "dn"), "right")
.join(coursePay, Seq("orderid", "dt", "dn"), "left")
.select("courseid", "coursename", "status", "pointlistid", "majorid", "chapterid", "chaptername", "edusubjectid"
, "edusubjectname", "teacherid", "teachername", "coursemanager", "money", "orderid", "cart_discount", "sellmoney",
"cart_createtime", "pay_discount", "paymoney", "pay_createtime", "dt", "dn")
// 6、将 倾斜key join后的结果 与 普通key join后的结果,uinon起来
df1
.union(df2)
.write.mode(SaveMode.Overwrite).insertInto("sparktuning.salecourse_detail")
}以下为打散大key和扩容小表的实现思路
1)打散大表:实际就是数据一进一出进行处理,对大key前拼上随机前缀实现打散
2)扩容小表:实际就是将DataFrame中每一条数据,转成一个集合,并往这个集合里循环添加10条数据,最后使用 flatmap压平此集合,达到扩容的效果.
小技巧: 打散和扩容的时候,可以增加字段,旧的字段不用动,避免结果还要还原key的值。
6.4.3 参设开启AQE
7. Map端优化
RDD建议使用reduceByKey或者aggregateByKey算子来替代掉groupByKey算子。因为reduceByKey和 aggregateByKey算子都会使用用户自定义的函数对每个节点本地的相同key进行预聚合。而groupByKey算子是不会进行预聚合的,全量的数据会在集群的各个节点之间分发和传输,性能相对来说比较差。
SparkSQL的话本身的HashAggregte就会实现本地预聚合+全局聚合。
7.1 读取小文件优化
读取的数据源有很多小文件,会造成查询性能的损耗,大量的数据分片信息以及对应产生的Task元信息也会给Spark Driver的内存造成压力,带来单点问题。设置参数可以实现:
## 参数(单位都是 bytes)
spark.sql.files.maxPartitionBytes=128MB #一个分区最大字节数 默认128m
spark.files.openCostInBytes=4194304 #打开一个文件的开销 默认4m源码理解: FilePartition.maxSplitBytes() 
即满足: N个小文件总大小+(N-1)*openCostInBytes <= maxPartitionBytes的话,就合并小文件:
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("MapSmallFileTuning")
.set("spark.files.openCostInBytes", "0") //默认4m
.set("spark.sql.files.maxPartitionBytes", "128MB") //默认128M
.setMaster("local[1]") //TODO 要打包提交集群执行,注释掉
val sparkSession: SparkSession = InitUtil.initSparkSession(sparkConf)
sparkSession.sql("select * from sparktuning.course_shopping_cart")
.write
.mode(SaveMode.Overwrite)
.saveAsTable("sparktuning.test_cart")
// while (true) {}
}7.2 增大map溢写时输出流buffer
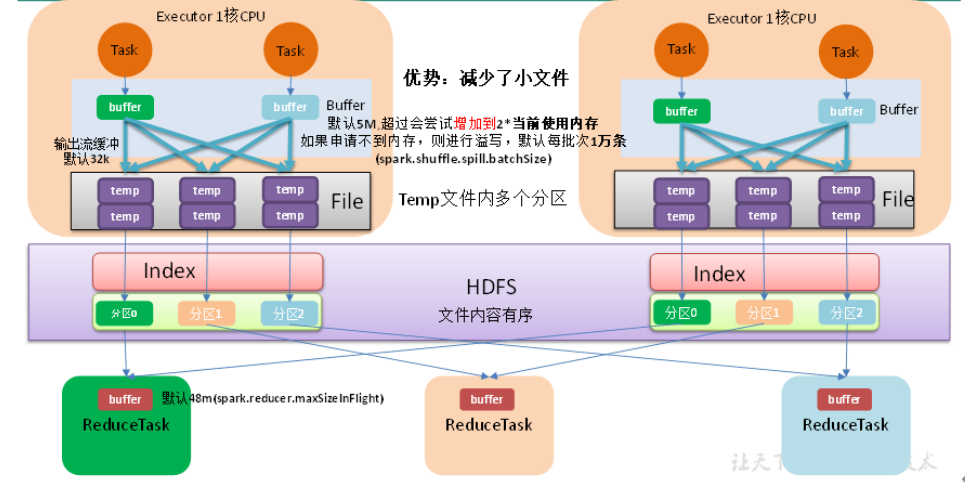 1)map端Shuffle Write有一个缓冲区,初始阈值5m(参数值为
1)map端Shuffle Write有一个缓冲区,初始阈值5m(参数值为spark.shuffle.spill.initalMemoryThreshold,没有开放出来),超过会尝试增加到2*当前使用内存。如果申请不到内存,则进行溢写。
2)溢写时使用输出流缓冲区默认32k(参数值为spark.shuffle.file.buffer,开放可以修改,输出流缓冲区可以理解为输出管道的粗细大小),这些缓冲区减少了磁盘搜索和系统调用次数,适当提高可以提升溢写效率。 3)Shuffle文件涉及到序列化,是采取批的方式读写,默认按照每批次1万条(参数值为spark.shuffle.spill.bathSize,没有开放出来)去读写。设置得太低会导致在序列化时过度复制,因为一些序列化器通过增长和复制的方式来翻倍内部数据结构。
综合以上分析,我们可以调整的只有输出缓冲区的大小。
8. Reduce端优化
8.1 合理设置Reduce数
过多的cpu资源出现空转浪费,过少影响任务性能。关于并行度的设置请参考cpu低效优化
8.2 输出产生小文件优化
Reduce端输出小文件主要场景有:Join后的结果插入新表,动态分区插入数据。
8.3 Join后的结果插入新表
join结果插入新表,生成的文件数等于shuffle并行度,默认就是200份文件插入到hdfs上。
解决方式:
- 可以在插入表数据前进行缩小分区操作来解决小文件过多问题,如coalesce、repartition算子。
- 调整shuffle并行度。cpu低效优化原则来设置。
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("PartitionTuning")
.set("spark.sql.shuffle.partitions", "36")
val sparkSession: SparkSession = InitUtil.initSparkSession(sparkConf)
//查询出三张表 并进行join 插入到最终表中
val saleCourse = sparkSession.sql("select * from sparktuning.sale_course")
val coursePay = sparkSession.sql("select * from sparktuning.course_pay")
.withColumnRenamed("discount", "pay_discount")
.withColumnRenamed("createtime", "pay_createtime")
val courseShoppingCart = sparkSession.sql("select * from sparktuning.course_shopping_cart")
.drop("coursename")
.withColumnRenamed("discount", "cart_discount")
.withColumnRenamed("createtime", "cart_createtime")
saleCourse
.join(courseShoppingCart, Seq("courseid", "dt", "dn"), "right")
.join(coursePay, Seq("orderid", "dt", "dn"), "left")
// 不牺牲sheuffle的前提下,尽可能的减少分区数
// 手动调整分区数, 或者api调用.repartition(6), 重分区缺点是额外需要合并分区
.coalesce(6)
.select("courseid", "coursename", "status", "pointlistid", "majorid", "chapterid", "chaptername", "edusubjectid"
, "edusubjectname", "teacherid", "teachername", "coursemanager", "money", "orderid", "cart_discount", "sellmoney",
"cart_createtime", "pay_discount", "paymoney", "pay_createtime", "dt", "dn")
.write.mode(SaveMode.Overwrite).saveAsTable("sparktuning.salecourse_detail")
}8.4 动态分区插入数据
- 没有Shuffle的情况下。最差的情况下,每个Task中都有表各个分区的记录,那文件数最终文件数将达到Task数量*表分区数。这种情况下是极易产生小文件的。
- 有Shuffle的情况下,上面的Task数量就变成了
spark.sql.shuffle.partitions(默认值200)。那么最差情况就会有spark.sql.shuffle.partitions* 表分区数。
当spark.sql.shuffle.partitions设置过大时,小文件问题就产生了;当`spark.sql.shuffle.partitions 设置过小时,任务的并行度就下降了,性能随之受到影响。
解决办法是: 将入库的SQL拆成(where分区!=倾斜分区键)和(where分区=倾斜分区键)几个部分,非倾斜分区键的部分正常distribute by分区字段,倾斜分区键的部分distribute by随机数。这样sql中加上distribute by aa。把同一分区的记录都哈希到同一个分区中去,还避免出现数据倾斜的问题。
-- 1.非倾斜键部分
INSERT overwrite table A partition ( aa )
SELECT *
FROM B where aa != 大 key
distribute by aa;
-- 2.倾斜键部分
INSERT overwrite table A partition ( aa )
SELECT *
FROM B where aa = 大 key
distribute by cast(rand() * 5 as int);执行后: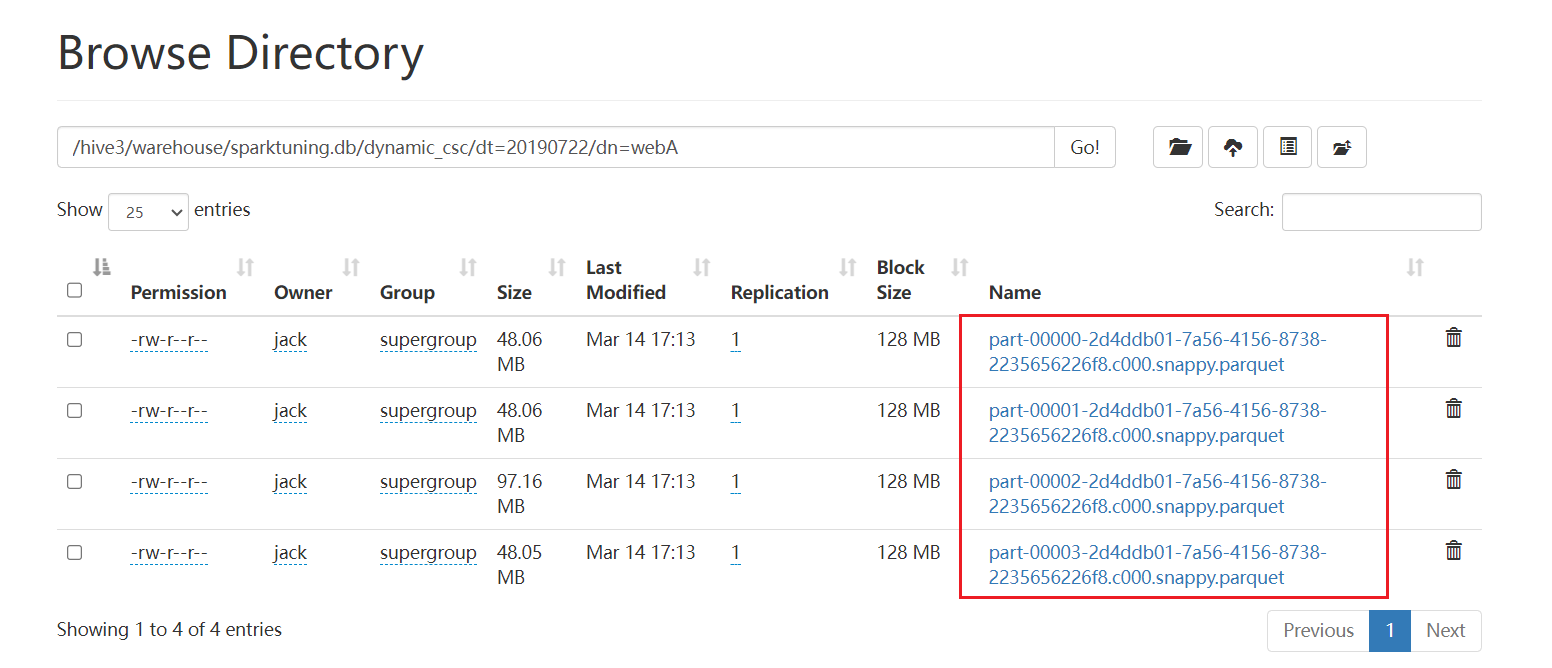
8.5 增大reduce缓冲区,减少拉取次数
Spark Shuffle过程中,shuffle reduce task的buffer缓冲区大小决定了reduce task每次能够缓冲的数据量,也就是每次能够拉取的数据量,如果内存资源较为充足,适当增加拉取数据缓冲区的大小,可以减少拉取数据的次数,也就可以减少网络传输的次数,进而提升性能。
reduce端数据拉取缓冲区的大小可以通过spark.reducer.maxSizeInFlight参数进行设置,默认为48MB。但是调整过大的话需要谨慎,如果并行度很高将占用大量内存。
8.6 调节reduce端拉取数据重试次数
Spark Shuffle过程中,reduce task拉取属于自己的数据时,如果因为网络异常等原因导致失败会自动进行重试。对于那些包含了特别耗时的shuffle操作的作业,建议增加重试最大次数(比如60次),以避免由于JVM的full gc或者网络不稳定等因素导致的数据拉取失败。在实践中发现,对于针对超大数据量(数十亿~上百亿)的shuffle过程,调节该参数可以大幅度提升稳定性。
reduce端拉取数据重试次数可以通过spark.shuffle.io.maxRetries参数进行设置,该参数就代表了可以重试的最大次数。如果在指定次数之内拉取还是没有成功,就可能会导致作业执行失败,默认为3。如果网络环境确实不好可以调整大一些, 但不建议超过6次。
8.7 调节reduce端拉取数据等待间隔
Spark Shuffle过程中,reduce task拉取属于自己的数据时,如果因为网络异常等原因导致失败会自动进行重试,在一次失败后,会等待一定的时间间隔再进行重试,可以通过加大间隔时长(比如60s),以增加shuffle操作的稳定性。
reduce端拉取数据等待间隔可以通过spark.shuffle.io.retryWait参数进行设置,默认值为5s。
8.8 合理利用bypass
当ShuffleManager为SortShuffleManager时,如果shuffle read task的数量(spark.sql.shuffle.partitions)小于spark.shuffle.sort.bypassMergeThreshold阈值(默认是200)且不需要map端进行合并操作,则shuffle write过程中不会进行排序操作,使用BypassMergeSortShuffleWriter去写数据,但是最后会将每个task产生的所有临时磁盘文件都合并成一个文件,并会创建单独的索引文件。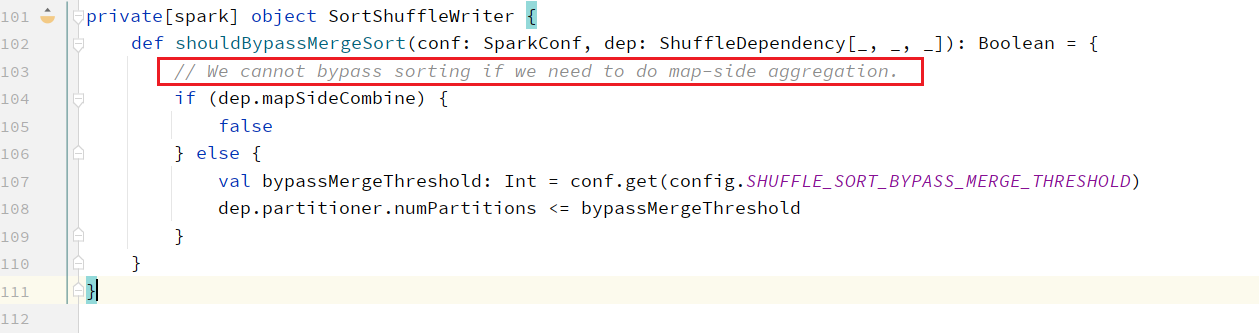 当你使用SortShuffleManager时,如果确实不需要排序操作,那么建议将这个参数调大一些,大于shuffle read task的数量。那么此时就会自动启用bypass机制,map-side就不会进行排序了,减少了排序的性能开销。但是这种方式下,依然会产生大量的磁盘文件,因此shuffle write性能有待提高。
当你使用SortShuffleManager时,如果确实不需要排序操作,那么建议将这个参数调大一些,大于shuffle read task的数量。那么此时就会自动启用bypass机制,map-side就不会进行排序了,减少了排序的性能开销。但是这种方式下,依然会产生大量的磁盘文件,因此shuffle write性能有待提高。
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("BypassTuning")
.set("spark.sql.shuffle.partitions", "36")
.set("spark.shuffle.sort.bypassMergeThreshold", "200") //bypass阈值,默认200,改成30对比效果
.setMaster("local[*]") //TODO 要打包提交集群执行,注释掉
val sparkSession: SparkSession = InitUtil.initSparkSession(sparkConf)
//查询出三张表 并进行join 插入到最终表中
val saleCourse = sparkSession.sql("select * from sparktuning.sale_course")
val coursePay = sparkSession.sql("select * from sparktuning.course_pay")
.withColumnRenamed("discount", "pay_discount")
.withColumnRenamed("createtime", "pay_createtime")
val courseShoppingCart = sparkSession.sql("select * from sparktuning.course_shopping_cart")
.drop("coursename")
.withColumnRenamed("discount", "cart_discount")
.withColumnRenamed("createtime", "cart_createtime")
saleCourse
.join(courseShoppingCart, Seq("courseid", "dt", "dn"), "right")
.join(coursePay, Seq("orderid", "dt", "dn"), "left")
.select("courseid", "coursename", "status", "pointlistid", "majorid", "chapterid", "chaptername", "edusubjectid"
, "edusubjectname", "teacherid", "teachername", "coursemanager", "money", "orderid", "cart_discount", "sellmoney",
"cart_createtime", "pay_discount", "paymoney", "pay_createtime", "dt", "dn")
.write.mode(SaveMode.Overwrite).saveAsTable("sparktuning.salecourse_detail")
// while (true) {}
}9. 整体优化
9.1 调节数据本地化等待时长
在Spark项目开发阶段,可以使用client模式对程序进行测试,此时可以在本地看到比较全的日志信息,日志信息中有明确的Task数据本地化的级别,如果大部分都是PROCESS_LOCAL、NODE_LOCAL,那么就无需进行调节,但是如果发现很多的级别都是RACK_LOCAL、ANY,那么需要对本地化的等待时长进行调节,应该是反复调节,每次调节完以后,再来运行观察日志,看看大部分的task的本地化级别有没有提升;看看整个Spark作业的运行时间有没有缩短。
注意过犹不及,不要将本地化等待时长延长地过长,导致因为大量的等待时长,使得Spark作业的运行时间反而增加了。下面几个参数,默认都是 3s,可以改成如下:
spark.locality.wait #建议 6s、10s
spark.locality.wait.process #建议 60s
spark.locality.wait.node #建议 30s
spark.locality.wait.rack #建议 20s匹配规则是spark.locality.wait.process不满足就去找spark.locality.wait.node还是不满足就去spark.locality.wait.rack。修改参数后,可以观察日志了解当前Task分布情况: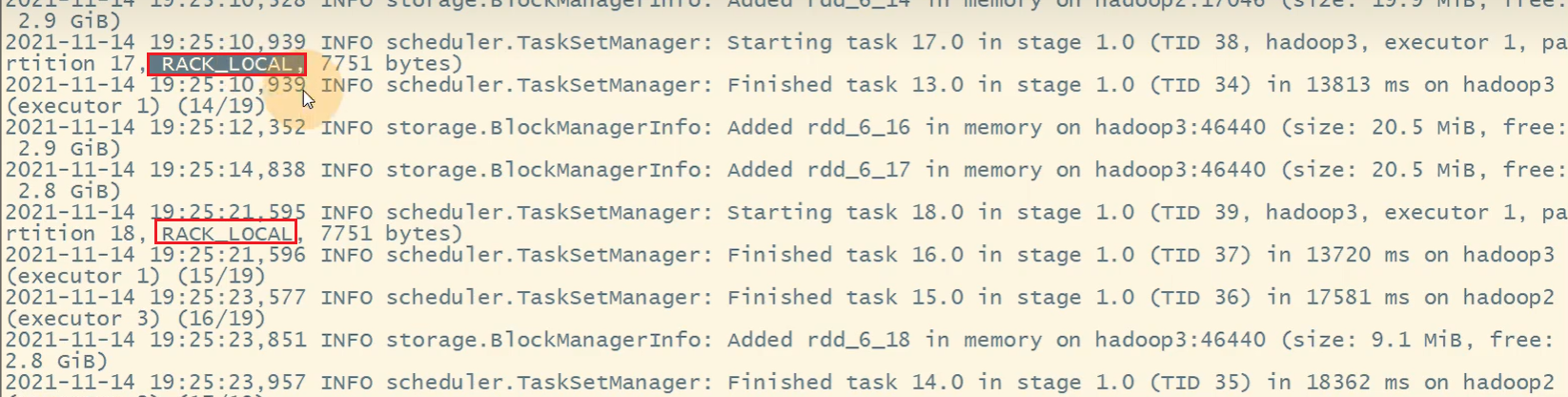
9.2 使用堆外内存
一个容器最多可以申请多大资源,是由yarn参数yarn.scheduler.maximum-allocation-mb决定, 需要满足:
`spark.executor.memoryOverhead` + `spark.executor.memory` + `spark.memory.offHeap.size`
≤ `yarn.scheduler.maximum-allocation-mb`➢ spark.executor.memory:提交任务时指定的堆内内存。
➢ spark.executor.memoryOverhead:堆外内存参数,内存额外开销。默认开启,默认值为spark.executor.memory*0.1并且会与最小值384mb做对比,取最大值。所以spark on yarn任务堆内内存申请1个g,而实际去 yarn申请的内存大于1个g的原因。
➢ spark.memory.offHeap.size:堆外内存参数,spark中默认关闭, 需要将spark.memory.enable.offheap.enable参数设置为true。
讲到堆外内存,对yarn申请资源的Spark3.0之后就发生改变,实际去yarn申请的内存资源由三个参数相加。
测试申请容器上限:
yarn.scheduler.maximum-allocation-mb修改为7G,将三个参数设为如下,大于7G,会报错:
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 4 --conf spark.memory.offHeap.enabled=true --conf spark.memory.offHeap.size=2g --executor-memory 5g --class com.rocket.sparktuning.join.SMBJoinTuning
spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar- 将
spark.memory.offHeap.size修改为1g后再次提交:
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 4 --conf spark.memory.offHeap.enabled=true --conf spark.memory.offHeap.size=1g --executor-memory 5g --class com.rocket.sparktuning.join.SMBJoinTuning
spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar9.3 使用堆外缓存
使用堆外内存可以减轻垃圾回收的工作,也加快了复制的速度。
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("OFFHeapCache")
.setMaster("local[*]")
val sparkSession: SparkSession = InitUtil.initSparkSession(sparkConf)
useOFFHeapMemory(sparkSession)
}
def useOFFHeapMemory(sparkSession: SparkSession): Unit = {
import sparkSession.implicits._
val result = sparkSession.sql("select * from sparktuning.course_pay").as[CoursePay]
// 指定持久化到 堆外内存
result.persist(StorageLevel.OFF_HEAP)
result.foreachPartition((p: Iterator[CoursePay]) => p.foreach(item => println(item.orderid)))
// while (true) {}
}打包发布到yarn:
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 2 --conf spark-memory.offHeap.enabled=true --conf spark.memory.offHeap.size=1g --executor-memory 3g --class com.rocket.sparktuning.job.OFFHeapCache spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar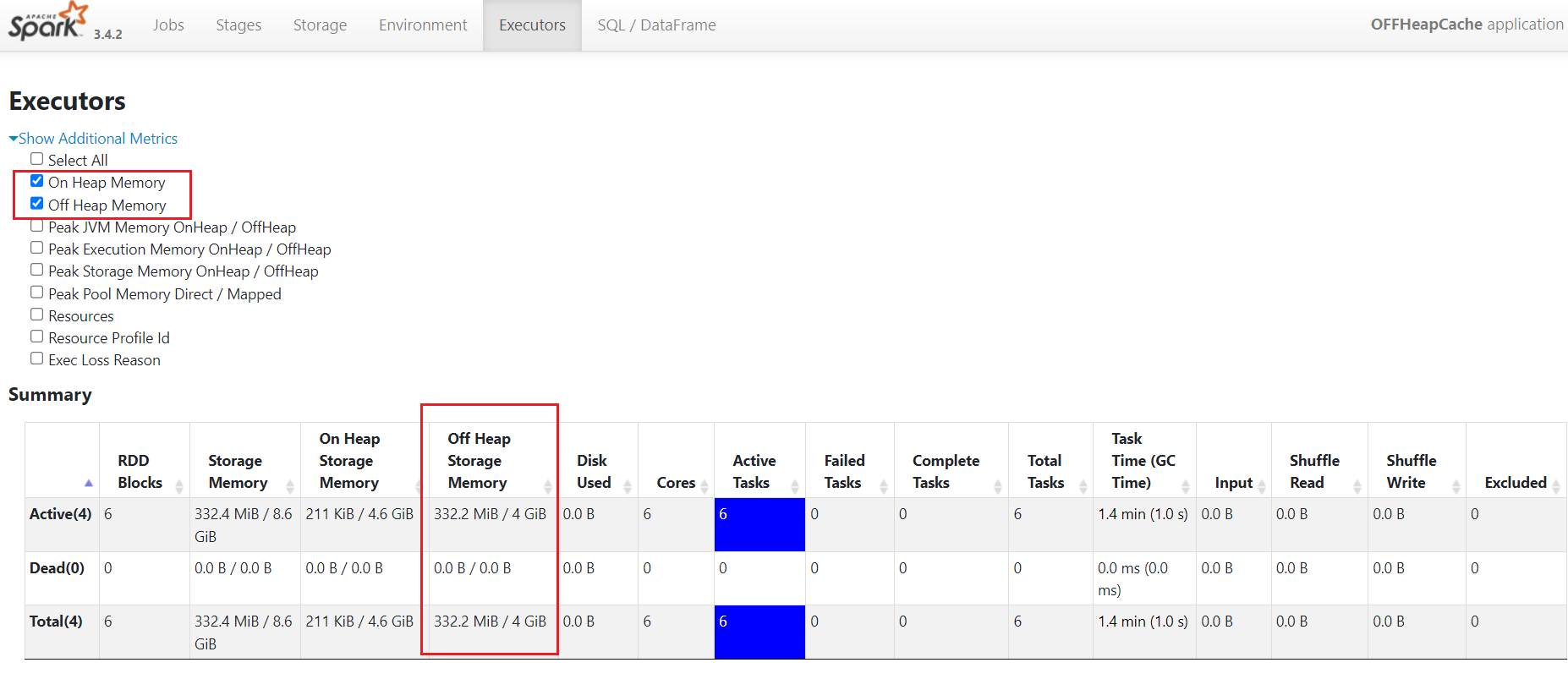
9.4 调节连接等待时长
在Spark作业运行过程中,Executor优先从自己本地关联的BlockManager中获取某份数据(比如广播、缓存数据),如果本地BlockManager没有的话,会通过TransferService远程连接其他节点上Executor的BlockManager来获取数据。
如果task在运行过程中创建大量对象或者创建的对象较大,会占用大量的内存,这回导致频繁的垃圾回收,但是垃圾回收会导致工作现场全部停止,也就是说,垃圾回收一旦执行,Spark的Executor进程就会停止工作,无法提供相应,此时,由于没有响应,无法建立网络连接,会导致网络连接超时。
在生产环境下,有时会遇到file not found、file lost这类错误,在这种情况下,很有可能是Executor的 BlockManager在拉取数据的时候,无法建立连接,然后超过默认的连接等待时长120s后,宣告数据拉取失败,如果反复尝试都拉取不到数据,可能会导致Spark作业的崩溃。这种情况也可能会导致DAGScheduler反复提交几次stage,TaskScheduler反复提交几次task,大大延长了我们的Spark作业的运行时间。
为了避免长时间暂停(如GC)导致的超时,可以考虑调节连接的超时时长,连接等待时长需要在 spark-submit 脚本中进行设置,设置方式可以在提交时指定:
--conf spark.core.connection.ack.wait.timeout=300s10. Spark3.0 AQE
Spark在3.0版本推出了AQE(Adaptive Query Execution),即自适应查询执行。AQE是Spark SQL的一种动态优化机制,在运行时,每当Shuffle Map阶段执行完毕,AQE都会结合这个阶段的统计信息,基于既定的规则动态地调整、修正尚未执行的逻辑计划和物理计划,来完成对原始查询语句的运行时优化。
10.1 动态合并分区
在Spark中运行查询处理非常大的数据时,shuffle通常会对查询性能产生非常重要的影响。shuffle是非常昂贵的操作,因为它需要进行网络传输移动数据,以便下游进行计算。最好的分区取决于数据,但是每个查询的阶段之间的数据大小可能相差很大,这使得该数字难以调整:
(1)如果分区太少,则每个分区的数据量可能会很大,处理这些数据量非常大的分区,可能需要将数据溢写到磁盘(例如,排序和聚合),降低了查询。
(2)如果分区太多,则每个分区的数据量大小可能很小,读取大量小的网络数据块,这也会导致I/O效率低而降低了查询速度。拥有大量的task(一个分区一个task)也会给Spark任务计划程序带来更多负担。
为了解决这个问题,我们可以在任务开始时先设置较多的shuffle分区个数,然后在运行时通过查看shuffle文件统计信息将相邻的小分区合并成更大的分区。
例如,假设正在运行select max(i) from tbl group by j。输入tbl很小,在分组前只有2个分区。那么任务刚初始化时,我们将分区数设置为5,如果没有AQE,Spark将启动五个任务来进行最终聚合,但是其中会有三个非常小的分区,为每个分区启动单独的任务这样就很浪费。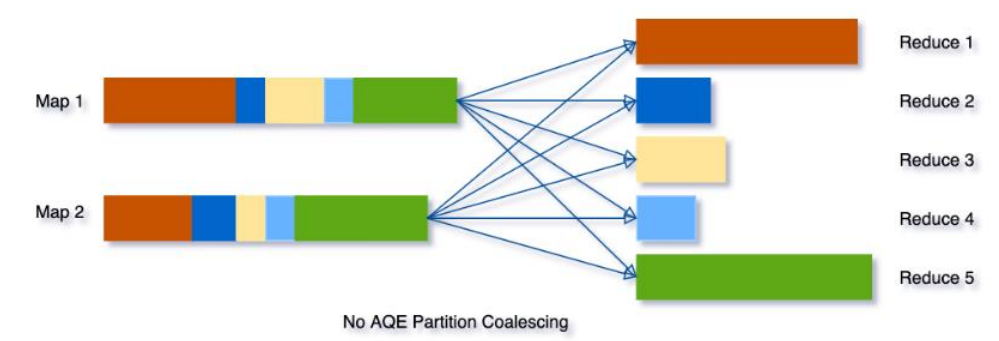 取而代之的是,AQE将这三个小分区合并为一个,因此最终聚只需三个task而不是五个。
取而代之的是,AQE将这三个小分区合并为一个,因此最终聚只需三个task而不是五个。 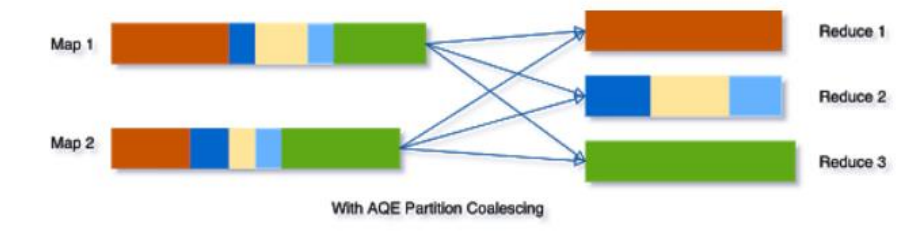
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("AQEPartitionTunning")
.set("spark.sql.autoBroadcastJoinThreshold", "-1") //为了演示效果,禁用广播join
.set("spark.sql.adaptive.enabled", "true")
.set("spark.sql.adaptive.coalescePartitions.enabled", "true") // 合并分区的开关
.set("spark.sql.adaptive.coalescePartitions.initialPartitionNum", "100") // 初始的并行度
.set("spark.sql.adaptive.coalescePartitions.minPartitionNum", "10") // 合并后的最小分区数
.set("spark.sql.adaptive.advisoryPartitionSizeInBytes", "40mb") // 合并后的分区,期望有多大
val sparkSession: SparkSession = InitUtil.initSparkSession(sparkConf)
useJoin(sparkSession)
}
def useJoin(sparkSession: SparkSession) = {
val saleCourse = sparkSession.sql("select *from sparktuning.sale_course")
val coursePay = sparkSession.sql("select * from sparktuning.course_pay")
.withColumnRenamed("discount", "pay_discount")
.withColumnRenamed("createtime", "pay_createtime")
val courseShoppingCart = sparkSession.sql("select *from sparktuning.course_shopping_cart")
.drop("coursename")
.withColumnRenamed("discount", "cart_discount")
.withColumnRenamed("createtime", "cart_createtime")
saleCourse.join(courseShoppingCart, Seq("courseid", "dt", "dn"), "right")
.join(coursePay, Seq("orderid", "dt", "dn"), "left")
.select("courseid", "coursename", "status", "pointlistid", "majorid", "chapterid", "chaptername", "edusubjectid"
, "edusubjectname", "teacherid", "teachername", "coursemanager", "money", "orderid", "cart_discount", "sellmoney",
"cart_createtime", "pay_discount", "paymoney", "pay_createtime", "dt", "dn")
.write.mode(SaveMode.Overwrite).insertInto("sparktuning.salecourse_detail_1")
}打包交给yarn执行:
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 2 --executor-memory 2g --class com.rocket.sparktuning.aqe.AQEPartitionTunning spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar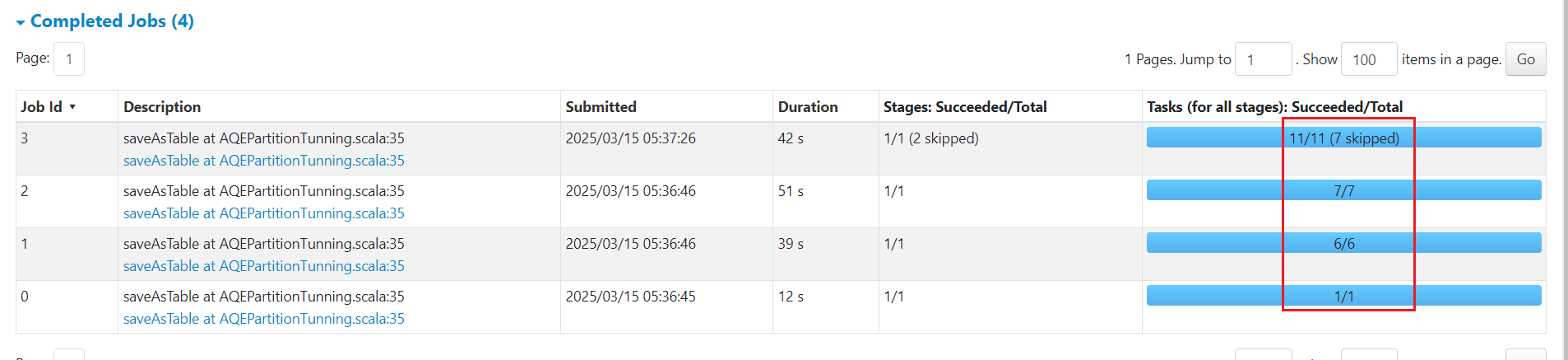 发现任务并没有100个,发生了合并。
发现任务并没有100个,发生了合并。 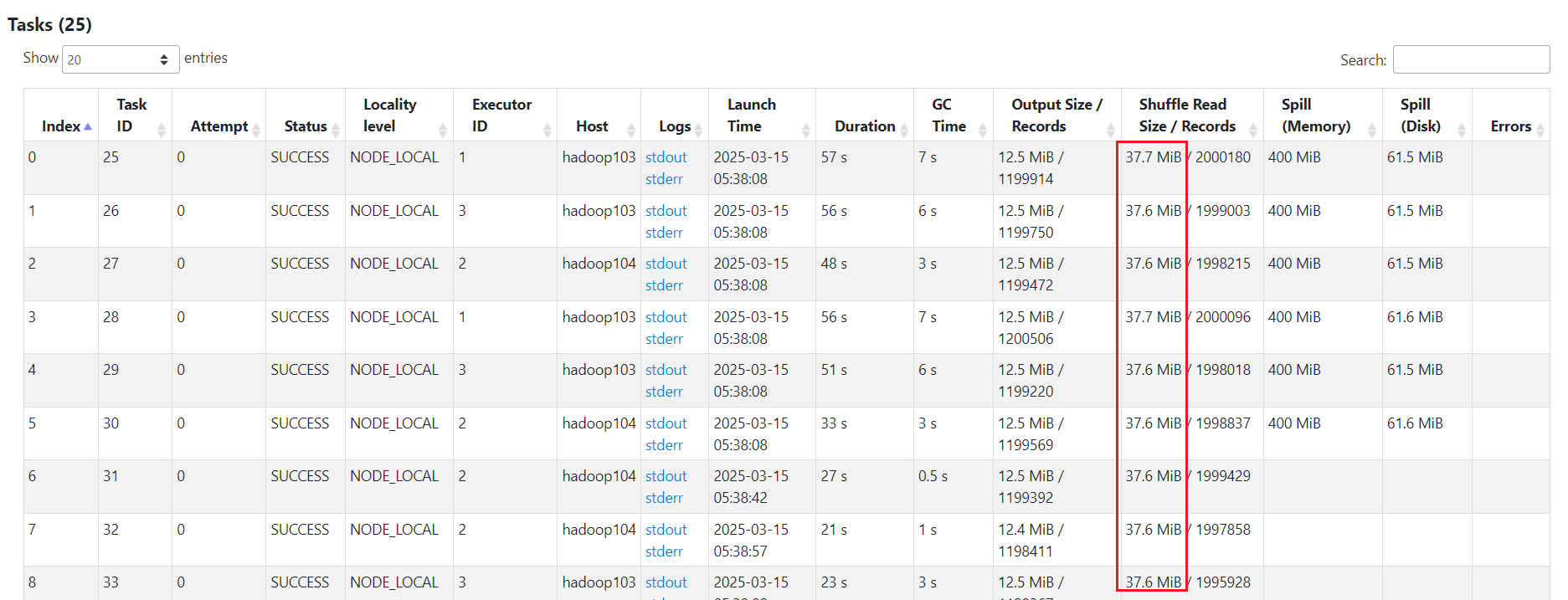 合并后没有继续合并是因为我们设置分区最大为40M, 再次合并肯定会超过。下面增加两行设置:
合并后没有继续合并是因为我们设置分区最大为40M, 再次合并肯定会超过。下面增加两行设置:
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("DynamicAllocationTunning")
.set("spark.sql.autoBroadcastJoinThreshold", "-1")
.set("spark.sql.adaptive.enabled", "true")
.set("spark.sql.adaptive.coalescePartitions.enabled", "true")
.set("spark.sql.adaptive.coalescePartitions.initialPartitionNum", "1000")
.set("spark.sql.adaptive.coalescePartitions.minPartitionNum", "10")
.set("spark.sql.adaptive.advisoryPartitionSizeInBytes", "40mb")
.set("spark.dynamicAllocation.enabled", "true") // 动态申请资源
// shuffle动态跟踪开启后,申请资源时,会根据跟踪的shuffle的大小,来决定申请资源的大小
.set("spark.dynamicAllocation.shuffleTracking.enabled", "true")
val sparkSession: SparkSession = InitUtil.initSparkSession(sparkConf)
useJoin(sparkSession)
}
def useJoin(sparkSession: SparkSession) = {
val saleCourse = sparkSession.sql("select *from sparktuning.sale_course")
val coursePay = sparkSession.sql("select * from sparktuning.course_pay")
.withColumnRenamed("discount", "pay_discount")
.withColumnRenamed("createtime", "pay_createtime")
val courseShoppingCart = sparkSession.sql("select *from sparktuning.course_shopping_cart")
.drop("coursename")
.withColumnRenamed("discount", "cart_discount")
.withColumnRenamed("createtime", "cart_createtime")
saleCourse.join(courseShoppingCart, Seq("courseid", "dt", "dn"), "right")
.join(coursePay, Seq("orderid", "dt", "dn"), "left")
.select("courseid", "coursename", "status", "pointlistid", "majorid", "chapterid", "chaptername", "edusubjectid"
, "edusubjectname", "teacherid", "teachername", "coursemanager", "money", "orderid", "cart_discount", "sellmoney",
"cart_createtime", "pay_discount", "paymoney", "pay_createtime", "dt", "dn")
.write.mode(SaveMode.Overwrite).insertInto("sparktuning.salecourse_detail_1")
}但是一般不会开启动态申请资源,因为申请资源不可控,资源充足的情况下可以考虑开启。
10.2 动态切换Join策略
Spark支持多种join策略,其中如果join的一张表可以很好的插入内存,那么broadcast shah join通常性能最高。因此,spark join中,如果小表小于广播大小阀值(默认10mb),Spark将计划进行broadcast hash join。但是,很多事情都会使这种大小估计出错(例如存在选择性很高的过滤器),或者join关系是一系列的运算符而不是简单的扫描表操作。
为了解决此问题,AQE现在根据最准确的join大小运行时重新计划join策略。从下图实例中可以看出,发现连接的右侧表比左侧表小的多,并且足够小可以进行广播,那么AQE会重新优化,将sort merge join转换成为broadcast hash join。
如下代码,并没有开启CBO,但是开启了AQE和本地shuffle读取器:
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("AqeDynamicSwitchJoin")
.set("spark.sql.adaptive.enabled", "true")
// 在不需要进行shuffle重分区时,尝试使用本地shuffle读取器。
// 将sort-merge join 转换为广播join
.set("spark.sql.adaptive.localShuffleReader.enabled", "true")
val sparkSession: SparkSession = InitUtil.initSparkSession(sparkConf)
switchJoinStartegies(sparkSession)
}
def switchJoinStartegies(sparkSession: SparkSession) = {
val coursePay = sparkSession.sql("select * from sparktuning.course_pay")
.withColumnRenamed("discount", "pay_discount")
.withColumnRenamed("createtime", "pay_createtime")
.where("orderid between 'odid-9999000' and 'odid-9999999'")
val courseShoppingCart = sparkSession.sql("select *from sparktuning.course_shopping_cart")
.drop("coursename")
.withColumnRenamed("discount", "cart_discount")
.withColumnRenamed("createtime", "cart_createtime")
val tmpdata = coursePay.join(courseShoppingCart, Seq("orderid"), "right")
tmpdata.show()
}10.3 动态优化Join倾斜
当数据在群集中的分区之间分布不均匀时,就会发生数据倾斜。严重的倾斜会大大降低查询性能,尤其对于join。AQE skew join优化会从随机shuffle文件统计信息自动检测到这种倾斜。然后它将倾斜分区拆分成较小的子分区。
例如,下图A join B, A表中分区A0明细大于其他分区: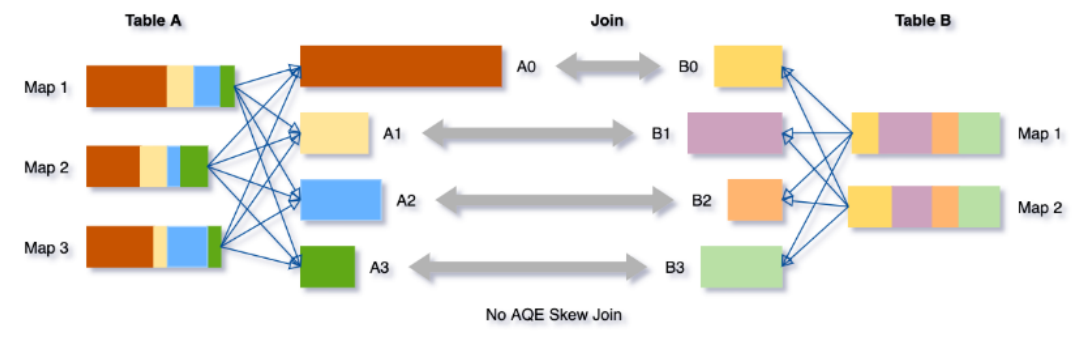 因此skew join会将A0分区拆分成两个子分区,并且对应连接B0分区:
因此skew join会将A0分区拆分成两个子分区,并且对应连接B0分区: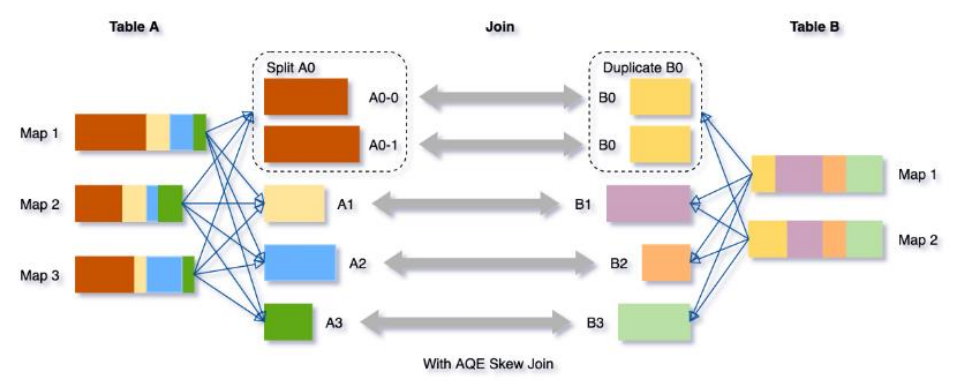 Spark3.0有了AQE机制就可以交给Spark自行解决。Spark3.0增加了以下参数:
Spark3.0有了AQE机制就可以交给Spark自行解决。Spark3.0增加了以下参数:
spark.sql.adaptive.skewJoin.enabled: 是否开启倾斜join检测,如果开启了,那么会将倾斜的分区数据拆成多个分区,默认是开启的,但是得打开aqe。spark.sql.adaptive.skewJoin.skewedPartitionFactor: 默认值5,此参数用来判断分区数据量是否数据倾斜,当任务中最大数据量分区对应的数据量大于的分区中位数乘以此参数,并且也大于spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes参数,那么此任务是数据倾斜。(比如abc3个分区的大小分别是2M,3M,12M,那么最大分区为12M,中位数就是3M, 判断12M>3M*5)spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes: 默认值256mb,用于判断是否数据倾斜。(12M不满足,这两个条件都需要满足才会触发AQE处理倾斜)spark.sql.adaptive.advisoryPartitionSizeInBytes: 此参数用来告诉spark进行拆分后推荐分区大小是多少。
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("AqeOptimizingSkewJoin")
.set("spark.sql.autoBroadcastJoinThreshold", "-1") //为了演示效果,禁用广播join
.set("spark.sql.adaptive.coalescePartitions.enabled", "true") // 为了演示效果,关闭自动合并分区
.set("spark.sql.adaptive.enabled", "true")
.set("spark.sql.adaptive.skewJoin.enable", "true")
.set("spark.sql.adaptive.skewJoin.skewedPartitionFactor", "2")
.set("spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes", "20mb")
.set("spark.sql.adaptive.advisoryPartitionSizeInBytes", "8mb")
val sparkSession: SparkSession = InitUtil.initSparkSession(sparkConf)
useJoin(sparkSession)
}
def useJoin(sparkSession: SparkSession) = {
val saleCourse = sparkSession.sql("select *from sparktuning.sale_course")
val coursePay = sparkSession.sql("select * from sparktuning.course_pay")
.withColumnRenamed("discount", "pay_discount")
.withColumnRenamed("createtime", "pay_createtime")
val courseShoppingCart = sparkSession.sql("select *from sparktuning.course_shopping_cart")
.drop("coursename")
.withColumnRenamed("discount", "cart_discount")
.withColumnRenamed("createtime", "cart_createtime")
saleCourse.join(courseShoppingCart, Seq("courseid", "dt", "dn"), "right")
.join(coursePay, Seq("orderid", "dt", "dn"), "left")
.select("courseid", "coursename", "status", "pointlistid", "majorid", "chapterid", "chaptername", "edusubjectid"
, "edusubjectname", "teacherid", "teachername", "coursemanager", "money", "orderid", "cart_discount", "sellmoney",
"cart_createtime", "pay_discount", "paymoney", "pay_createtime", "dt", "dn")
.write.mode(SaveMode.Overwrite).insertInto("sparktuning.salecourse_detail_1")
}但是如果同时开启了spark.sql.adaptive.coalescePartitions.enabled动态合并分区功能,那么会先合并分区,再去判断倾斜,可能不触发AQE处理倾斜。
11. Spark3.0 DPP
Spark3.0支持动态分区裁剪Dynamic Partition Pruning,简称DPP,核心思路就是先将join一侧作为子查询计算出来,再将其所有分区用到join另一侧作为表过滤条件,从而实现对分区的动态修剪。如下图所示: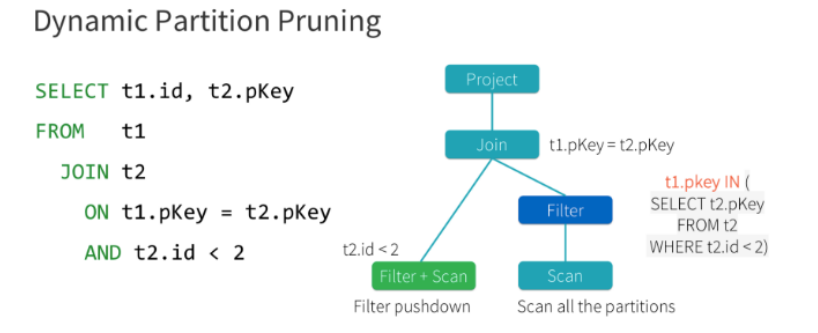
select t1.id,t2.pkey
from t1
join t2
on t1.pkey = t2.pkey and t2.id<2
-- 优化成了
select
t1.id,t2.pkey
from t1
join t2
on t1.pkey=t2.pkey
and t1.pkey in(
select t2.pkey
from t2
where t2.id<2
)触发条件:
(1)待裁剪的表join的时候,join条件里必须有分区字段
(2)如果是需要修剪左表,那么join必须是inner join ,left semi join或right join,反之亦然。但如果是left out join,无论右边有没有这个分区,左边的值都存在,就不需要被裁剪
(3)另一张表需要存在至少一个过滤条件,比如a join b on a.key=b.key and a.id<2
DPP功能使用参数spark.sql.optimizer.dynamicPartitionPruning.enabled控制默认开启。
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("DPPTest")
.set("spark.sql.optimizer.dynamicPartitionPruning.enabled", "true")
// .setMaster("local[*]")
val sparkSession: SparkSession = InitUtil.initSparkSession(sparkConf)
val result = sparkSession.sql(
"""
|select a.id,a.name,a.age,b.name
|from sparktuning.test_student a
|inner join sparktuning.test_school b
|on a.partition=b.partition and b.id<1000
""".stripMargin)
// .explain(mode="extended")
result.foreach(item => println(item.get(1)))
}12. Spark3.0 Hint增强
在spark2.4的时候就有了hint功能,不过只有broadcasthash join的hint,这次3.0又增加了sort merge join,shuffle_hash join,shuffle_replicate nested loop join。
12.1 broadcasthast join
Broadcast Hash Join主要包括两个阶段:
- Broadcast阶段 :小表被缓存在executor中
- Hash Join阶段:在每个executor中执行Hash Join
sparkSession.sql("select /*+ BROADCAST(school) */ * from test_student
student left join test_school school on student.id=school.id").show()
sparkSession.sql("select /*+ BROADCASTJOIN(school) */ * from
test_student student left join test_school school on
student.id=school.id").show()
sparkSession.sql("select /*+ MAPJOIN(school) */ * from test_student
student left join test_school school on student.id=school.id").show()Broadcast Hash Join相比其他的JOIN机制而言,效率更高。但是Broadcast Hash Join属于网络密集型的操作(数据冗余传输),除此之外,需要在Driver端缓存数据,所以当小表的数据量较大时,会出现OOM的情况
12.2 sort merge join
该JOIN机制是Spark默认的,可以通过参数spark.sql.join.preferSortMergeJoin进行配置,默认是true,即优先使用Sort Merge Join。一般在两张大表进行JOIN时,使用该方式。Sort Merge Join主要包括三个阶段:
Shuffle Phase: 两张大表根据Join key进行Shuffle重分区
Sort Phase: 每个分区内的数据进行排序
Merge Phase: 对来自不同表的排序好的分区数据进行JOIN,通过遍历元素,连接具有相同Join key值的行来合并数据集
sparkSession.sql("select /*+ SHUFFLE_MERGE(school) */ * from
test_student student left join test_school school on
student.id=school.id").show()
sparkSession.sql("select /*+ MERGEJOIN(school) */ * from test_student
student left join test_school school on student.id=school.id").show()
sparkSession.sql("select /*+ MERGE(school) */ * from test_student
student left join test_school school on student.id=school.id").show()条件是仅支持等值连接。
12.3 shuffle_hash join
Shuffle Hash Join的基本步骤主要有以下两点:
首先,对于两张参与JOIN的表,分别按照join key进行重分区,该过程会涉及Shuffle,其目的是将相同join key的数据发送到同一个分区,方便分区内进行join。
其次,对于每个Shuffle之后的分区,会将小表的分区数据构建成一个Hash table,然后根据join key与大表的分区数据记录进行匹配。
sparkSession.sql("select /*+ SHUFFLE_HASH(school) */ * from test_student
student left join test_school school on student.id=school.id").show()仅支持等值连接,join key不需要排序。
12.4 shuffle_replicate_nl join
shuffle_replicate_nl join优先级在所有join中最低,使用条件非常苛刻,驱动表(school表)必须小,且很容易被spark执行成sort merge join。
sparkSession.sql("select /*+ SHUFFLE_REPLICATE_NL(school) */ * from
test_student student inner join test_school school on
student.id=school.id").show()优先级为:Broadcast Hash Join > Sort Merge Join > Shuffle Hash Join > cartesian Join > Broadcast Nested Loop Join。在Cartesian Join(可以理解是笛卡尔积那种,没有连接条件)与Broadcast Nested Loop Join之间,如果是内连接,或者非等值连接,则优先选择Broadcast Nested Loop策略,当时非等值连接并且一张表可以被广播时,会选择Cartesian Join。