🐝Hive概述
1. Hive简介
Hive是由Facebook开源,基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。Hive的出现简化了Hadoop的MapReduce程序处理数据。
2. Hive本质
Hive是一个Hadoop客户端,用于将HQL(Hive SQL)转化成MapReduce程序。
- Hive中每张表的数据存储在HDFS
- Hive分析数据底层的实现是MapReduce(也可配置为Spark或者Tez)
- 执行程序运行在Yarn上
3. Hive架构原理
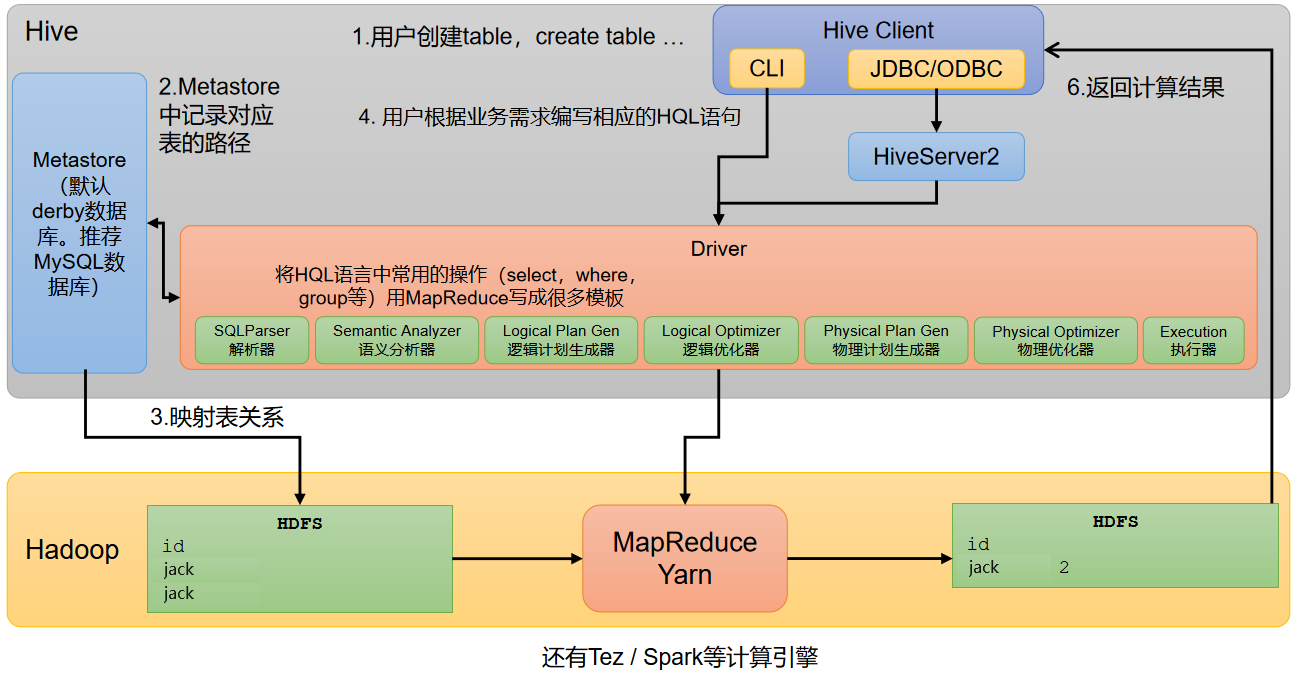
- Client(用户接口):
CLI(命令行)、JDBC/ODBC。 - Metastore(元数据): 元数据包括:数据库(默认是default)、表名、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等。
默认存储在自带的derby数据库中,由于derby数据库只支持单客户端访问,生产环境中为了多人开发,推荐使用MySQL存储Metastore。 - Driver(驱动器):
- 解析器(SQLParser):将SQL字符串转换成抽象语法树(AST),如下图
SQL语法树
比如查询SQL为:
select count(*) from test group by id;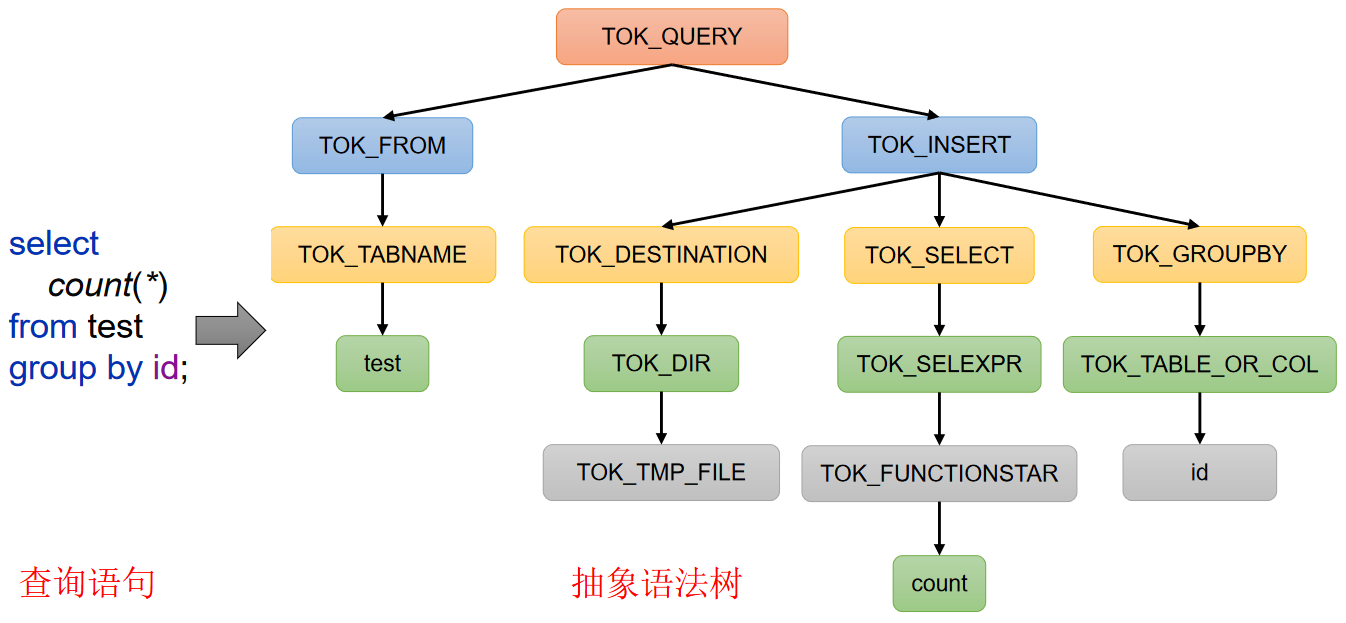
- 语义分析(Semantic Analyzer):将AST进一步划分为QueryBlock
- 逻辑计划生成器(Logical Plan Gen):将语法树生成逻辑计划,如下图执行计划
- 逻辑优化器(Logical Optimizer):对逻辑计划进行优化(比如谓词下推)
- 物理计划生成器(Physical Plan Gen):根据优化后的逻辑计划生成物理计划,如下图执行计划
执行物理计划过程
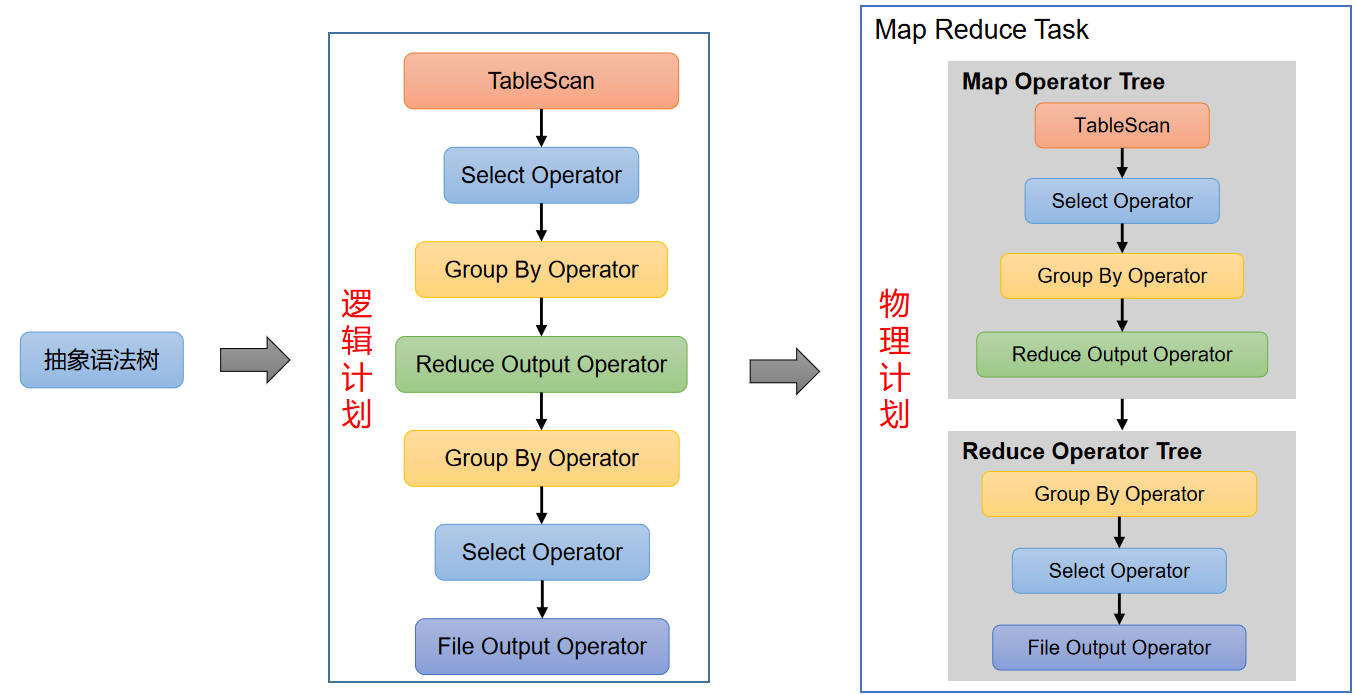
- 物理优化器(Physical Optimizer):对物理计划进行优化
- 执行器(Execution):执行该计划,得到查询结果并返回给客户端
- 底层基于Hadoop:
使用HDFS进行存储,可以选择MapReduce/Tez/Spark进行计算。