优雅关闭和启动恢复
流式任务需要7*24小时执行,但是有时涉及到升级代码需要主动停止程序,但是分布式程序,没办法做到一个个进程去杀死,所有配置优雅的关闭就显得至关重要了。使用外部文件系统来控制内部程序关闭。
1. 优雅关闭
scala
package com.rocket.spark.streaming
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext, StreamingContextState}
import java.net.URI
object DStreamByGracefulStop {
def main(args: Array[String]): Unit = {
//1.初始化 Spark 配置信息
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("DStreamByRddQueue")
//2.初始化 SparkStreamingContext
val ssc = new StreamingContext(sparkConf, Seconds(3))
// 设置检查点,因为有状态过后需要保存累计数据
ssc.checkpoint("ck")
val lines = ssc.socketTextStream("hadoop102", 7777)
val wordRdd: DStream[(String, Int)] = lines.flatMap(_.split(" ")).map((_, 1))
// 窗口的采集范围应该式采集周期的整数倍, 设置步长避免数据重复计算
val windowDS: DStream[(String, Int)] = wordRdd.window(Seconds(6), Seconds(6))
val wordCountRdd: DStream[(String, Int)] = windowDS.reduceByKey(_ + _)
wordCountRdd.print()
new Thread(()=>{
// 优雅的关闭
// 计算节点不再接受新的数据,而是将现有的数据处理完毕, 然后关闭
// 在Mysql ,Redis, HDFS, ZK读取数据,获取关闭信号
val fs: FileSystem = FileSystem.get(new URI("hdfs://hadoop102:8020/spark"), new Configuration(), "jack")
while (true){
val closeFlag: Boolean = fs.exists(new Path("hdfs://hadoop102:8020/spark/stopSpark"))
if(closeFlag){
if(ssc.getState == StreamingContextState.ACTIVE){
ssc.stop(true, true)
System.exit(0)
}
}
try
Thread.sleep(5000)
catch {
case e => e.printStackTrace()
}
}
}).start()
// 启动任务
ssc.start()
ssc.awaitTermination()
}
}在HDFS上面创建文件stopSpark: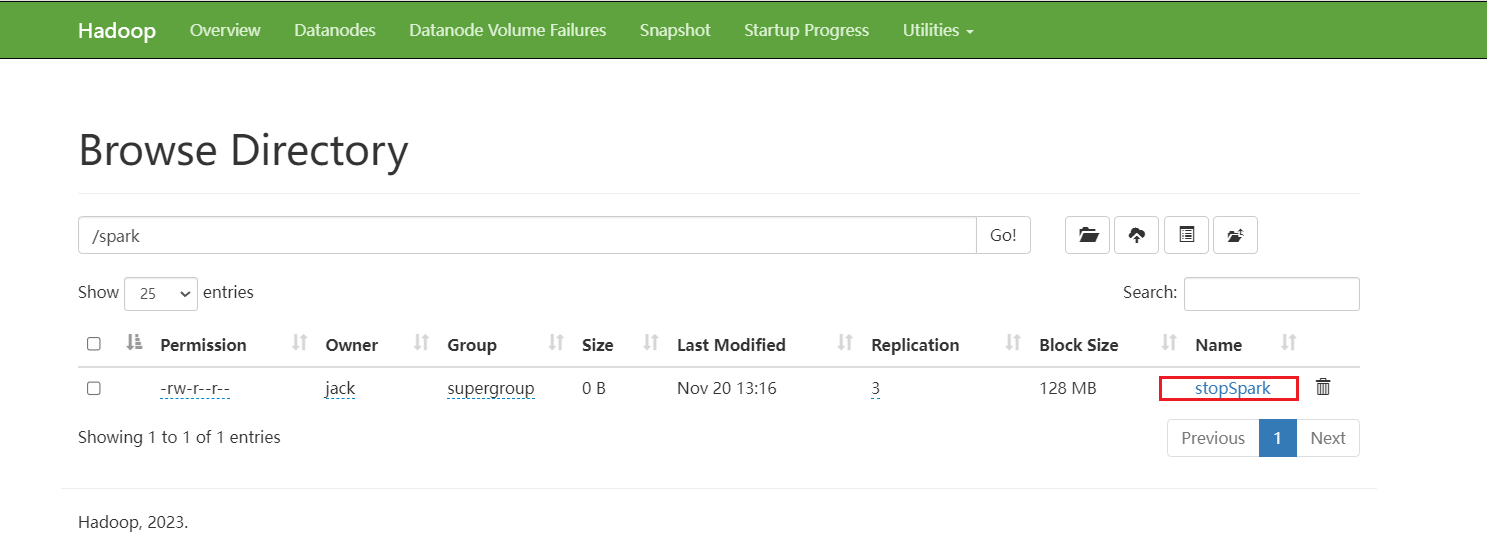 查看控制台:
查看控制台: 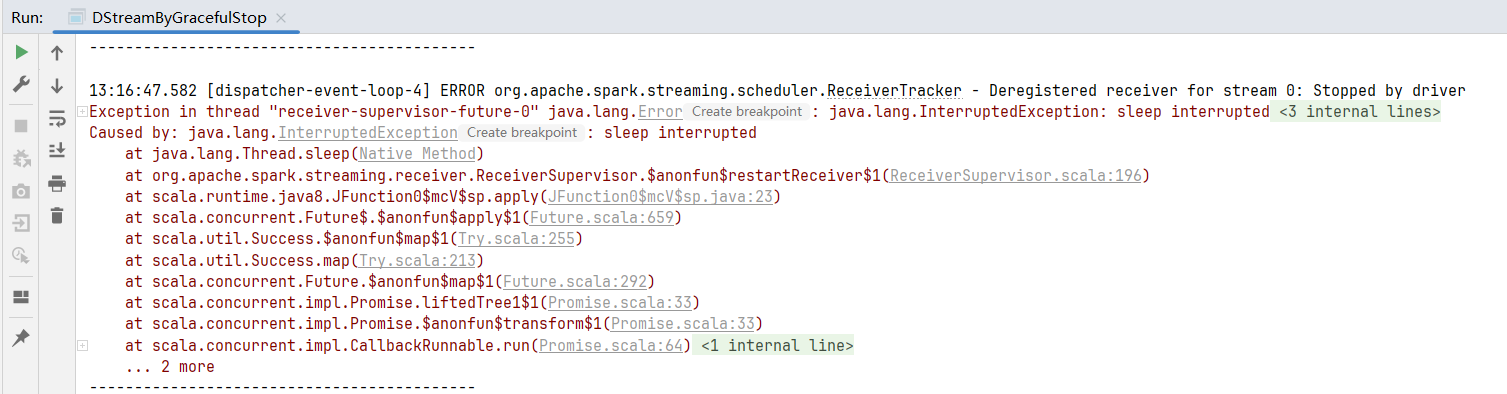
2. 启动恢复
scala
package com.rocket.spark.streaming
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext, StreamingContextState}
import java.net.URI
object DStreamByGracefulStop {
def createSSC(): _root_.org.apache.spark.streaming.StreamingContext = {
val update: (Seq[Int], Option[Int]) => Some[Int] = (values: Seq[Int], status:
Option[Int]) => {
//当前批次内容的计算
val sum: Int = values.sum
//取出状态信息中上一次状态
val lastStatu: Int = status.getOrElse(0)
Some(sum + lastStatu)
}
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("DStreamByGracefulStop")
//设置优雅的关闭
sparkConf.set("spark.streaming.stopGracefullyOnShutdown", "true")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.checkpoint("ck")
val lines = ssc.socketTextStream("hadoop102", 7777)
val wordRdd: DStream[(String, Int)] = lines.flatMap(_.split(" ")).map((_, 1))
// 窗口的采集范围应该式采集周期的整数倍, 设置步长避免数据重复计算
val windowDS: DStream[(String, Int)] = wordRdd.window(Seconds(6), Seconds(6))
val wordCountRdd: DStream[(String, Int)] = windowDS.reduceByKey(_ + _)
wordCountRdd.print()
ssc
}
def main(args: Array[String]): Unit = {
val ssc: StreamingContext = StreamingContext.getActiveOrCreate("ck", () =>
createSSC())
new Thread(new MonitorStop(ssc)).start()
// 启动任务
ssc.start()
ssc.awaitTermination()
}
private class MonitorStop(ssc: StreamingContext) extends Runnable{
override def run(): Unit = {
// 优雅的关闭
// 计算节点不再接受新的数据,而是将现有的数据处理完毕, 然后关闭
// 在Mysql ,Redis, HDFS, ZK读取数据,获取关闭信号
val fs: FileSystem = FileSystem.get(new URI("hdfs://hadoop102:8020/spark"), new Configuration(), "jack")
while (true){
val closeFlag: Boolean = fs.exists(new Path("hdfs://hadoop102:8020/spark/stopSpark"))
if(closeFlag){
if(ssc.getState == StreamingContextState.ACTIVE){
ssc.stop(true, true)
System.exit(0)
}
}
try
Thread.sleep(5000)
catch {
case e => e.printStackTrace()
}
}
}
}
}