Spark运行机制总结
1. YARN Cluster模式
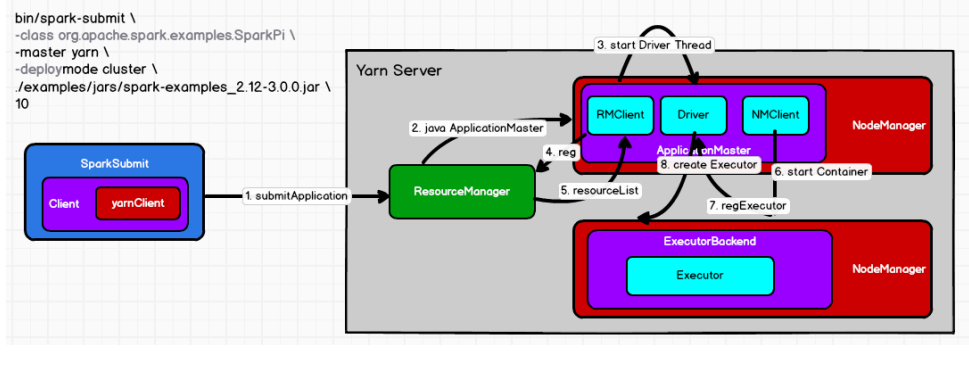
- 执行脚本提交任务,实际是启动一个SparkSubmit的JVM进程;
- SparkSubmit类中的main方法反射调用YarnClusterApplication的main方法;
- YarnClusterApplication创建Yarn客户端,然后向Yarn服务器发送执行指令:
bin/java ApplicationMaster - Yarn框架收到指令后会在指定的NM中启动ApplicationMaster;
- ApplicationMaster启动Driver线程,执行用户的作业;
- AM向RM注册,申请资源;
- 获取资源后AM向NM发送指令:
bin/java YarnCoarseGrainedExecutorBackend; - CoarseGrainedExecutorBackend进程会接收消息,跟Driver通信,注册已经启动的Executor;然后启动计算对象Executor等待接收任务。
- Driver线程继续执行完成作业的调度和任务的执行。
- Driver分配任务并监控任务的执行。
提示
SparkSubmit、ApplicationMaster和CoarseGrainedExecutorBackend是独立的进程;Driver是独立的线程;Executor和YarnClusterApplication是对象。
2. YARN Client模式
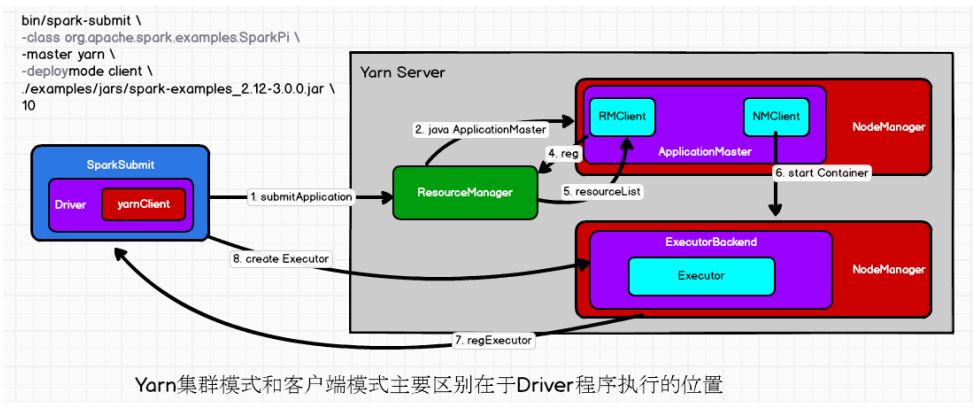
- 执行脚本提交任务,实际是启动一个SparkSubmit的JVM进程;
- SparkSubmit类中的main方法反射调用用户代码的main方法;
- 启动Driver线程,执行用户的作业,并创建ScheduleBackend;
- YarnClientSchedulerBackend向RM发送指令:
bin/java ExecutorLauncher; - Yarn框架收到指令后会在指定的NM中启动ExecutorLauncher(实际上还是调用ApplicationMaster的main方法);
object ExecutorLauncher {
def main(args: Array[String]): Unit = {
ApplicationMaster.main(args)
}
}- AM向RM注册,申请资源;
- 获取资源后AM向NM发送指令:
bin/java CoarseGrainedExecutorBackend; - CoarseGrainedExecutorBackend进程会接收消息,跟Driver通信,注册已经启动的Executor;然后启动计算对象Executor等待接收任务
- Driver分配任务并监控任务的执行。
提示
SparkSubmit、ApplicationMaster和YarnCoarseGrainedExecutorBackend是独立的进程;Executor和Driver是对象。
3. Standalone模式运行机制
Standalone 集群有2个重要组成部分,分别是:
- Master(RM):是一个进程,主要负责资源的调度和分配,并进行集群的监控等职责;
- Worker(NM):是一个进程,一个Worker运行在集群中的一台服务器上,主要负责两个职责:
- 一个是用自己的内存存储RDD的某个或某些partition;
- 另一个是启动其他进程和线程(Executor),对RDD上的partition进行并行的处理和计算。
3.1 Standalone Cluster模式
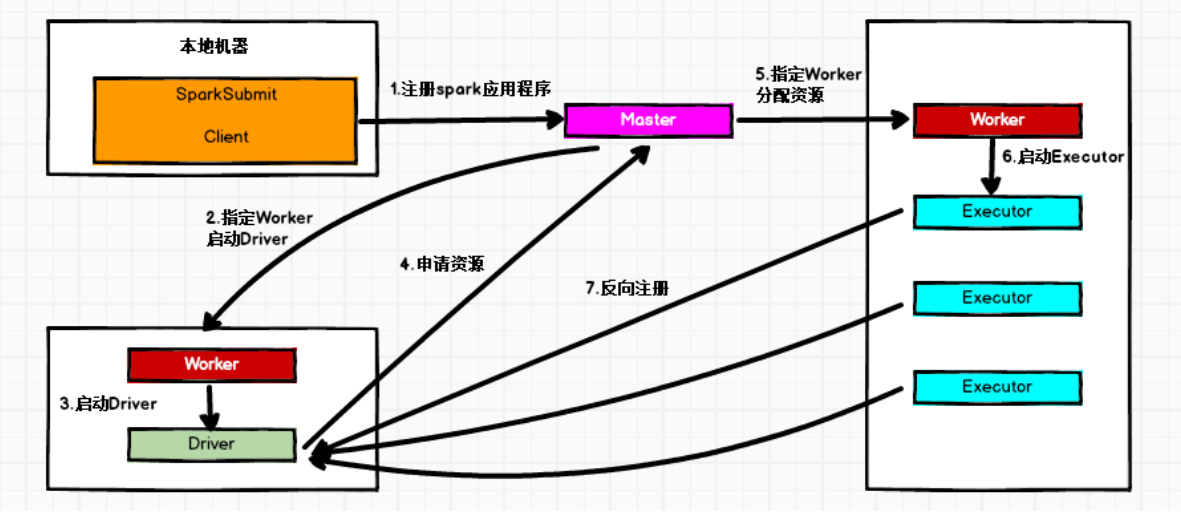 在Standalone Cluster模式下,任务提交后,Master会找到一个Worker启动Driver。
在Standalone Cluster模式下,任务提交后,Master会找到一个Worker启动Driver。
Driver启动后向Master注册应用程序,Master根据submit脚本的资源需求找到内部资源至少可以启动一个Executor的所有Worker,然后在这些Worker之间分配Executor,Worker上的Executor启动后会向Driver反向注册,所有的Executor注册完成后,Driver开始执行main函数,之后执行到Action算子时,开始划分Stage,每个Stage生成对应的taskSet,之后将Task分发到各个Executor上执行。
3.2 Standalone Client模式
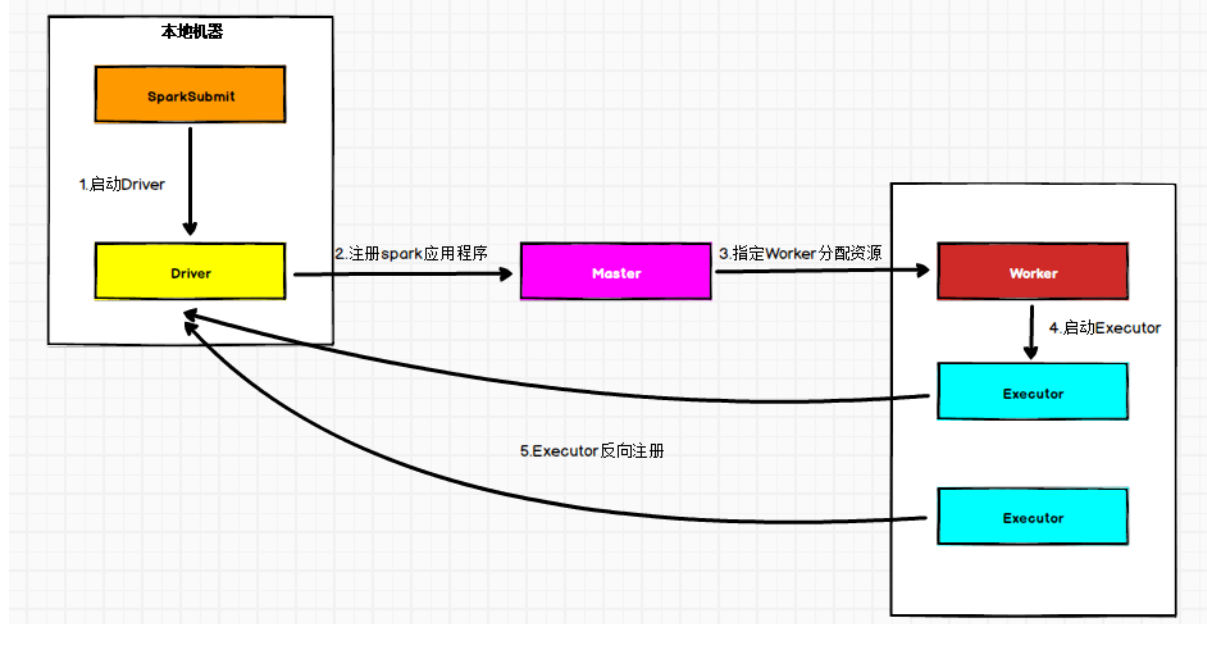 在Standalone Client模式下,Driver在任务提交的本地机器上运行。
在Standalone Client模式下,Driver在任务提交的本地机器上运行。
Driver启动后向Master注册应用程序,Master根据submit脚本的资源需求找到内部资源至少可以启动一个Executor的所有Worker,然后在这些Worker之间分配Executor,Worker上的Executor启动后会向Driver反向注册,所有的Executor注册完成后,Driver开始执行main函数,之后执行到Action算子时,开始划分Stage,每个Stage生成对应的TaskSet,之后将Task分发到各个Executor上执行。