电商数据仓库搭建
1. Hadoop安装
学习目的,可以这样集群规划:
| 服务器hadoop102 | 服务器hadoop103 | 服务器hadoop104 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | DataNodeSecondary NameNode |
| Yarn | NodeManager | Resourcemanager NodeManager | NodeManager |
具体安装可以参考hadoop集群搭建
1.2 HDFS存储多目录
- 生产环境服务器磁盘情况
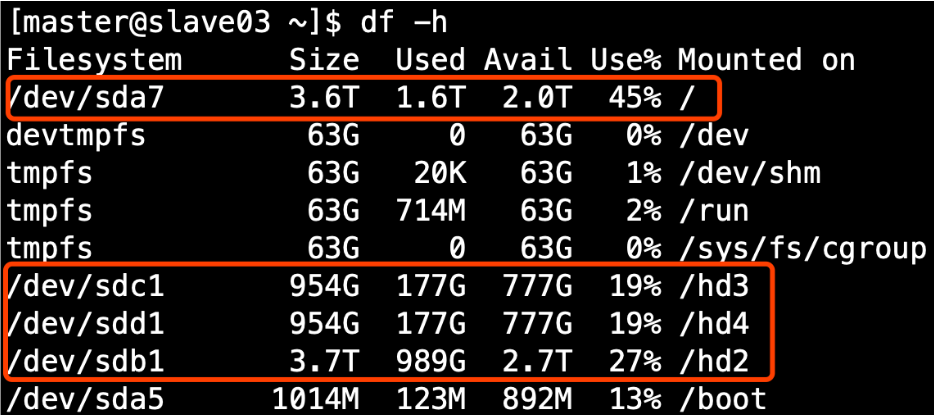
- 在hdfs-site.xml文件中配置多目录,注意新挂载磁盘的访问权限问题。HDFS的DataNode节点保存数据的路径由dfs.datanode.data.dir参数决定,其默认值为file://${hadoop.tmp.dir}/dfs/data,若服务器有多个磁盘,必须对该参数进行修改。如服务器磁盘如上图所示,则该参数应修改为如下的值。
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///dfs/data1,file:///hd2/dfs/data2,file:///hd3/dfs/data3,file:///hd4/dfs/data4</value>
</property>注意
因为每台服务器节点的磁盘情况不同,所以这个配置配完之后,不需要分发
1.3 集群数据均衡
- 开启数据均衡命令:
start-balancer.sh -threshold 10对于参数10,代表的是集群中各个节点的磁盘空间利用率相差不超过10%,可根据实际情况进行调整。
2. 停止数据均衡命令:
stop-balancer.sh注意
由于HDFS需要启动单独的Rebalance Server来执行Rebalance操作,所以尽量不要在NameNode上执行start-balancer.sh,而是找一台比较空闲的机器。
1.4 hadoop支持LZO压缩
- 环境准备 下载配置maven
[jack@hadoop102 ~]$ wget https://dlcdn.apache.org/maven/maven-3/3.9.6/binaries/apache-maven-3.9.6-bin.tar.gz
## 配置环境变量
[jack@hadoop102 software]$ tar -xvf apache-maven-3.9.6-bin.tar.gz -C /opt/module/
[jack@hadoop102 profile.d]$ sudo vi maven_env.sh
## 加上以下配置信息
#set Maven environment
export MAVEN_HOME=/opt/module/apache-maven-3.9.6
export PATH=$MAVEN_HOME/bin:$PATH
[jack@hadoop102 profile.d]$ source /etc/profile
[jack@hadoop102 profile.d]$ mvn -v
Apache Maven 3.9.6 (bc0240f3c744dd6b6ec2920b3cd08dcc295161ae)
Maven home: /opt/module/apache-maven-3.9.6
Java version: 1.8.0_391, vendor: Oracle Corporation, runtime: /opt/module/jdk1.8.0_391/jre
Default locale: zh_CN, platform encoding: UTF-8
OS name: "linux", version: "3.10.0-1160.105.1.el7.x86_64", arch: "amd64", family: "unix"
## 按照阿里云镜像配置说明https://developer.aliyun.com/mvn/guide
[jack@hadoop102 software]$ cd ../module/apache-maven-3.9.6/conf
[jack@hadoop102 conf]$ vi settings.xml
## 在<mirrors></mirrors>标签中添加 mirror 子节点:
<mirror>
<id>aliyunmaven</id>
<mirrorOf>*</mirrorOf>
<name>阿里云公共仓库</name>
<url>https://maven.aliyun.com/repository/public</url>
</mirror>安装以下依赖:
gcc-c++
zlib-devel
autoconf
automake
libtool
[jack@hadoop102 ~]$ sudo yum -y install gcc-c++ lzo-devel zlib-devel autoconf automake libtool- 下载、安装并编译LZO
wget http://www.oberhumer.com/opensource/lzo/download/lzo-2.10.tar.gz
tar -zxvf lzo-2.10.tar.gz
cd lzo-2.10
./configure -prefix=/opt/module/lzo
make
make install- 编译hadoop-lzo源码 下载hadoop-lzo的源码,下载地址:https://github.com/twitter/hadoop-lzo/archive/master.zip
解压之后,修改pom.xml
<hadoop.current.version>3.3.6</hadoop.current.version>声明两个临时环境变量
export C_INCLUDE_PATH=/opt/module/lzo/include
export LIBRARY_PATH=/opt/module/lzo/lib编译进入hadoop-lzo-master,执行maven编译命令
[jack@hadoop102 hadoop-lzo-master]$ mvn package -Dmaven.test.skip=true
## 进入target, hadoop-lzo-0.4.21-SNAPSHOT.jar 即编译成功的hadoop-lzo组件
[jack@hadoop102 hadoop-lzo-master]$ cd target/ && ls
antrun generated-sources hadoop-lzo-0.4.21-SNAPSHOT-sources.jar native
apidocs hadoop-lzo-0.4.21-SNAPSHOT.jar javadoc-bundle-options test-classes
classes hadoop-lzo-0.4.21-SNAPSHOT-javadoc.jar maven-archiver
[jack@hadoop102 target]$ cp hadoop-lzo-0.4.21-SNAPSHOT.jar /opt/module/hadoop-3.3.6/share/hadoop/common/
## 同步hadoop-lzo-0.4.21-SNAPSHOT.jar到hadoop103、hadoop104
[jack@hadoop102 common]$ xsync hadoop-lzo-0.4.21-SNAPSHOT.jar- core-site.xml增加配置支持LZO压缩
<property>
<name>io.compression.codecs</name>
<value>
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec
</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>- 同步core-site.xml到hadoop103、hadoop104
[jack@hadoop102 common]$ cd /opt/module/hadoop-3.3.6/etc/hadoop
[jack@hadoop102 hadoop]$ xsync core-site.xml- 启动hadoop集群
[jack@hadoop102 hadoop]$ hadoop_helper start
=================== 启动 hadoop集群 ===================
--------------- 启动 hdfs ---------------
Starting namenodes on [hadoop102]
Starting datanodes
Starting secondary namenodes [hadoop104]
--------------- 启动 yarn ---------------
Starting resourcemanager
Starting nodemanagers
--------------- 启动 historyserver ---------------1.5 使用LZO创建索引
创建LZO文件的索引,LZO压缩文件的可切片特性依赖于其索引,故我们需要手动为LZO压缩文件创建索引。若无索引,则LZO文件的切片只有一个。现需要导入lzo格式的文件到hdfs文件系统中去:
- 安装lzop工具
## 安装lzop工具是基于lzo算法实现的压缩和解压工具,目前只支持压缩文件,不支持压缩文件夹
[jack@hadoop102 tmp]$ sudo yum install lzop
## 本人在网上找到4本小说放到xiaoshuo.txt文件中,上传到服务器
[jack@hadoop102 tmp]$ ll
总用量 383372
-rw-r--r--. 1 jack jack 252868427 5月 2 21:07 xiaoshuo.txt
[jack@hadoop102 tmp]$ lzop xiaoshuo.txt
[jack@hadoop102 tmp]$ ll
-rw-r--r--. 1 jack jack 252868427 5月 2 21:07 xiaoshuo.txt
-rw-r--r--. 1 jack jack 146573766 5月 2 21:07 xiaoshuo.txt.lzo- 将xiaoshuo.txt.lzo上传到集群上传到hdfs集群
[jack@hadoop102 tmp]$ hadoop fs -put xiaoshuo.txt.lzo /user/jack/input/txt- 执行wordcount程序
[jack@hadoop102 tmp]$ hadoop jar /opt/module/hadoop-3.3.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount /user/jack/input/txt/xiaoshuo.txt.lzo /user/jack/output1
2024-05-02 21:22:15,409 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at hadoop103/192.168.101.103:8032
2024-05-02 21:22:17,265 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/jack/.staging/job_1714646521708_0001
2024-05-02 21:22:18,017 INFO input.FileInputFormat: Total input files to process : 1
2024-05-02 21:22:18,058 INFO lzo.GPLNativeCodeLoader: Loaded native gpl library from the embedded binaries
2024-05-02 21:22:18,060 INFO lzo.LzoCodec: Successfully loaded & initialized native-lzo library [hadoop-lzo rev 23ecd03e1dbad11e377a1d9ac0b13611874ca693]
2024-05-02 21:22:18,205 INFO mapreduce.JobSubmitter: number of splits:1
2024-05-02 21:22:18,584 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1714646521708_0001
2024-05-02 21:22:18,584 INFO mapreduce.JobSubmitter: Executing with tokens: []
2024-05-02 21:22:18,909 INFO conf.Configuration: resource-types.xml not found
2024-05-02 21:22:18,909 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2024-05-02 21:22:19,673 INFO impl.YarnClientImpl: Submitted application application_1714646521708_0001
.....- 对上传的LZO文件建索引
[jack@hadoop102 tmp]$ hadoop jar /opt/module/hadoop-3.3.6/share/hadoop/common/hadoop-lzo-0.4.21-SNAPSHOT.jar com.hadoop.compression.lzo.DistributedLzoIndexer /user/jack/input/txt/xiaoshuo.txt.lzo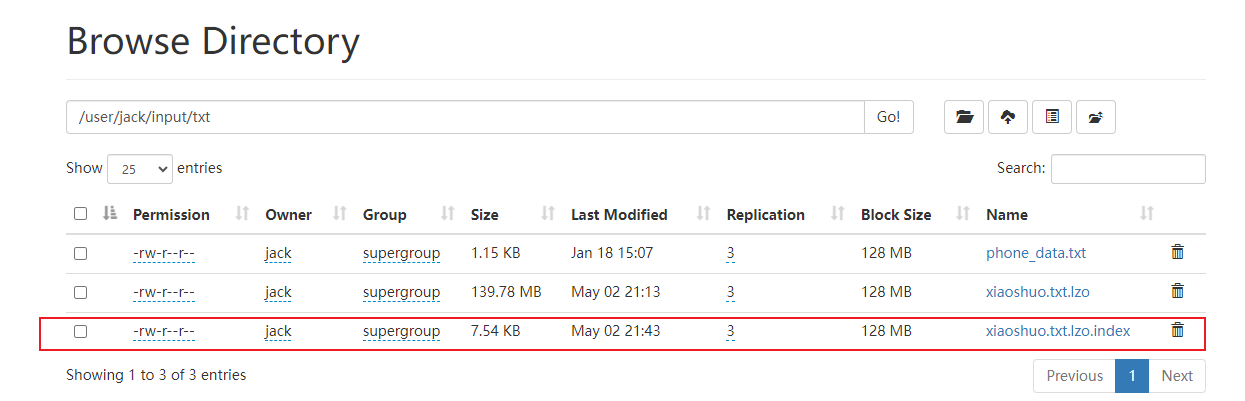 5. 再次执行WordCount程序
5. 再次执行WordCount程序
[jack@hadoop102 hadoop-lzo-master]$ hadoop jar /opt/module/hadoop-3.3.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount -Dmapreduce.job.inputformat.class=com.hadoop.mapreduce.LzoTextInputFormat /user/jack/input/txt/bigtable.lzo /user/jack/output3
2024-05-03 08:38:31,817 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at hadoop103/192.168.101.103:8032
2024-05-03 08:38:33,630 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/jack/.staging/job_1714659894202_0011
2024-05-03 08:38:34,556 INFO input.FileInputFormat: Total input files to process : 1
2024-05-03 08:38:34,946 INFO mapreduce.JobSubmitter: number of splits:2
2024-05-03 08:38:35,453 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1714659894202_0011
2024-05-03 08:38:35,453 INFO mapreduce.JobSubmitter: Executing with tokens: []
2024-05-03 08:38:36,000 INFO conf.Configuration: resource-types.xml not found
2024-05-03 08:38:36,001 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2024-05-03 08:38:36,254 INFO impl.YarnClientImpl: Submitted application application_1714659894202_0011
2024-05-03 08:38:36,383 INFO mapreduce.Job: The url to track the job: http://hadoop103:8088/proxy/application_1714659894202_0011/
2024-05-03 08:38:36,384 INFO mapreduce.Job: Running job: job_1714659894202_0011
2024-05-03 08:38:49,967 INFO mapreduce.Job: Job job_1714659894202_0011 running in uber mode : false
2024-05-03 08:38:49,968 INFO mapreduce.Job: map 0% reduce 0%
2024-05-03 08:39:21,956 INFO mapreduce.Job: map 18% reduce 0%
2024-05-03 08:39:28,158 INFO mapreduce.Job: map 33% reduce 0%
2024-05-03 08:39:40,675 INFO mapreduce.Job: map 46% reduce 0%
2024-05-03 08:39:45,849 INFO mapreduce.Job: map 47% reduce 0%
2024-05-03 08:39:52,050 INFO mapreduce.Job: map 58% reduce 0%
2024-05-03 08:39:58,239 INFO mapreduce.Job: map 61% reduce 0%
2024-05-03 08:40:03,409 INFO mapreduce.Job: map 74% reduce 0%
2024-05-03 08:40:04,434 INFO mapreduce.Job: map 81% reduce 0%
2024-05-03 08:40:10,644 INFO mapreduce.Job: map 83% reduce 0%
2024-05-03 08:40:14,797 INFO mapreduce.Job: map 100% reduce 0%
......1.6 基准测试
- 测试HDFS写性能 测试内容:向HDFS集群写10个128M的文件
[jack@hadoop102 mapreduce]$ hadoop jar /opt/module/hadoop-3.3.6/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.3.6-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 128MB
2024-05-02 22:57:11,778 INFO fs.TestDFSIO: ----- TestDFSIO ----- : write
2024-05-02 22:57:11,778 INFO fs.TestDFSIO: Date & time: Thu May 02 22:57:11 CST 2024
2024-05-02 22:57:11,778 INFO fs.TestDFSIO: Number of files: 10
2024-05-02 22:57:11,784 INFO fs.TestDFSIO: Total MBytes processed: 1280
2024-05-02 22:57:11,785 INFO fs.TestDFSIO: Throughput mb/sec: 5.74
2024-05-02 22:57:11,785 INFO fs.TestDFSIO: Average IO rate mb/sec: 5.81
2024-05-02 22:57:11,785 INFO fs.TestDFSIO: IO rate std deviation: 0.75
2024-05-02 22:57:11,785 INFO fs.TestDFSIO: Test exec time sec: 104.68
2024-05-02 22:57:11,785 INFO fs.TestDFSIO:- 测试HDFS读性能 测试内容:读取HDFS集群10个128M的文件
[jack@hadoop102 mapreduce]$ hadoop jar /opt/module/hadoop-3.3.6/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.3.6-tests.jar TestDFSIO -read -nrFiles 10 -fileSize 128MB
2024-05-02 23:00:14,419 INFO fs.TestDFSIO: ----- TestDFSIO ----- : read
2024-05-02 23:00:14,419 INFO fs.TestDFSIO: Date & time: Thu May 02 23:00:14 CST 2024
2024-05-02 23:00:14,419 INFO fs.TestDFSIO: Number of files: 10
2024-05-02 23:00:14,420 INFO fs.TestDFSIO: Total MBytes processed: 1280
2024-05-02 23:00:14,420 INFO fs.TestDFSIO: Throughput mb/sec: 19.95
2024-05-02 23:00:14,420 INFO fs.TestDFSIO: Average IO rate mb/sec: 23.8
2024-05-02 23:00:14,420 INFO fs.TestDFSIO: IO rate std deviation: 13.09
2024-05-02 23:00:14,420 INFO fs.TestDFSIO: Test exec time sec: 79.411.7 Hadoop参数调优
- HDFS参数调优hdfs-site.xml
NameNode有一个工作线程池,用来处理不同DataNode的并发心跳以及客户端并发的元数据操作。
对于大集群或者有大量客户端的集群来说,通常需要增大参数dfs.namenode.handler.count的默认值10。
<property>
<name>dfs.namenode.handler.count</name>
<value>10</value>
</property>可以参考计算心跳并发量设置具体的值。
2. YARN参数调优yarn-site.xml
情景描述:总共7台机器,每天几亿条数据,数据源->Flume->Kafka->HDFS->Hive
面临问题:数据统计主要用HiveSQL,没有数据倾斜,小文件已经做了合并处理,开启的JVM重用,而且IO没有阻塞,内存用了不到50%。但是还是跑的非常慢,而且数据量洪峰过来时,整个集群都会宕掉。基于这种情况有没有优化方案。
解决办法:
内存利用率不够。这个一般是Yarn的2个配置造成的,单个任务可以申请的最大内存大小,和Hadoop单个节点可用内存大小。调节这两个参数能提高系统内存的利用率。
(a)yarn.nodemanager.resource.memory-mb
表示该节点上YARN可使用的物理内存总量,默认是8192(MB),注意如果你的节点内存资源不够8GB,则需要调减小这个值,而YARN不会智能的探测节点的物理内存总量。
(b)yarn.scheduler.maximum-allocation-mb
单个任务可申请的最多物理内存量,默认是8192(MB)。
3. Hadoop宕机
(a)如果MR造成系统宕机。此时要控制Yarn同时运行的任务数,和每个任务申请的最大内存。调整参数:yarn.scheduler.maximum-allocation-mb(单个任务可申请的最多物理内存量,默认是8192MB
(b)如果写入文件过量造成NameNode宕机。那么调高Kafka的存储大小,控制从Kafka到HDFS的写入速度。高峰期的时候用Kafka进行缓存,高峰期过去数据同步会自动跟上。
2. Hive环境搭建
2.1 Hive引擎简介
Hive引擎包括: 默认MR、tez、spark
Hive on Spark: Hive既作为存储元数据又负责SQL的解析优化,语法是HQL语法,执行引擎变成了Spark,Spark负责采用RDD执行。
Spark on Hive: Hive只作为存储元数据,Spark负责SQL解析优化,语法是Spark SQL语法,Spark负责采用RDD执行。
2.2 Hive搭建
参考Hive安装教程
3. Hive On Spark搭建
需要留意的是Hive4.x版本不再官方支持Hive on Spark特性,并将Tez作为底层计算引擎。官网资料请参考:https://issues.apache.org/jira/browse/HIVE-26134 。
3. Hive On Tez搭建
Tez是一个Hive的运行引擎,性能优于MR。Tez基于内存计算,可以将多个有依赖的作业转换为一个作业,这样只需写一次HDFS,且中间节点较少,从而大大提升作业的计算性能。
3.1 下载安装Tez
- 访问https://dlcdn.apache.org/tez/0.10.4/ ,下载apache-tez-0.10.4-bin.tar.gz包,并上传到hadoop105机器上。
- 解压安装包apache-tez-0.10.4-bin.tar.gz
[jack@hadoop105 software]$ tar -xvf apache-tez-0.10.4-bin.tar.gz -C ../module/- 重命名文件夹
[jack@hadoop105 software]$ cd ../module
[jack@hadoop105 module]$ mv apache-tez-0.10.4-bin tez-0.10.43.2 配置Tez
在Hive的/conf下面创建一个tez-site.xml文件:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>tez.lib.uris</name>
<value>${fs.defaultFS}/tez/apache-tez-0.10.4-bin.tar.gz</value>
</property>
<property>
<name>tez.use.cluster.hadoop-libs</name>
<value>true</value>
</property>
<property>
<name>tez.history.logging.service.class</name>
<value>org.apache.tez.dag.history.logging.ats.ATSHistoryLoggingService</value>
</property>
</configuration>- 在hive-env.sh文件中添加tez环境变量配置和依赖包环境变量配置
export TEZ_HOME=/opt/module/tez-0.10.4 #是你的 tez 的解压目录
export TEZ_JARS=""
for jar in `ls $TEZ_HOME |grep jar`; do
export TEZ_JARS=$TEZ_JARS:$TEZ_HOME/$jar
done
for jar in `ls $TEZ_HOME/lib`; do
export TEZ_JARS=$TEZ_JARS:$TEZ_HOME/lib/$jar
done
export HIVE_AUX_JARS_PATH=/opt/module/hadoop-3.3.6/share/hadoop/common/hadoop-lzo-0.4.21-SNAPSHOT.jar$TEZ_JARS- 在hive-site.xml文件中更改hive计算引擎
<property>
<name>hive.execution.engine</name>
<value>tez</value>
</property>8.3 测试整合Tez
- 启动Hive客户端:
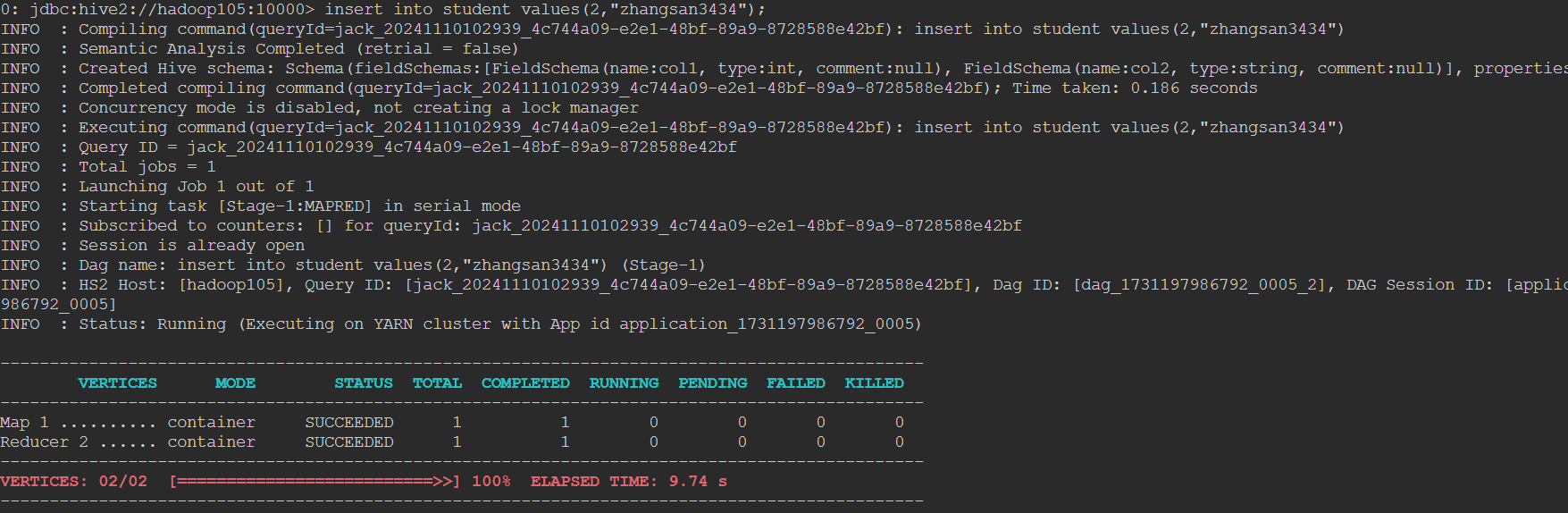
[jack@hadoop105 software]$ beeline -u jdbc:hive2://hadoop105:10000 -n jack- 执行插入一条数据,观察日志。
4. 电商仓库总体设计
数据仓库,并不是数据的最终目的地,而是为数据最终的目的地做好准备。这些准备包括对数据的:备份、清洗、聚合、统计等。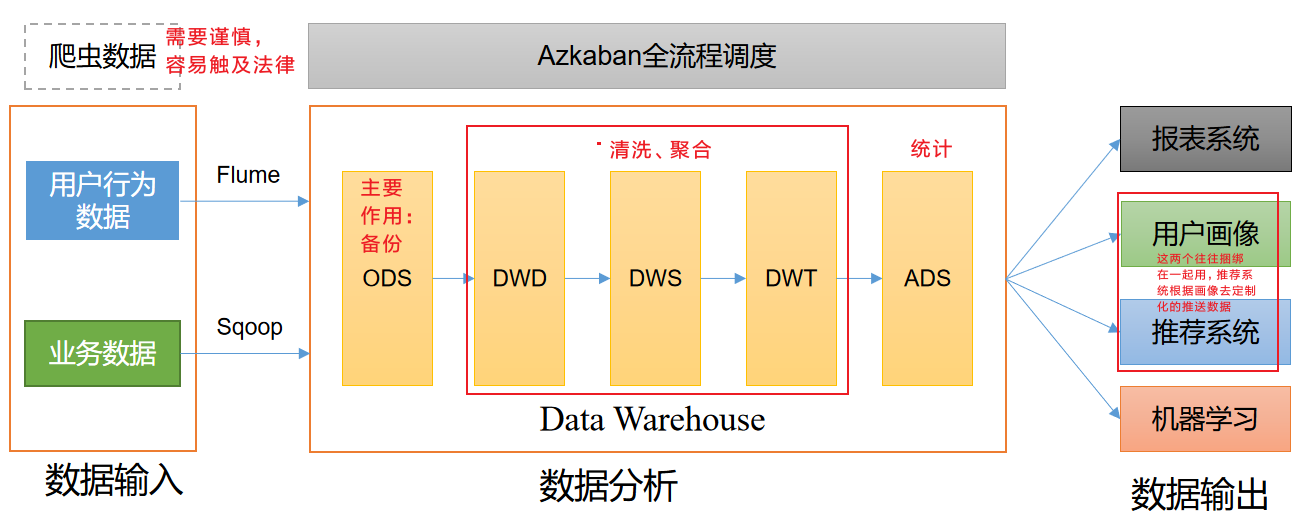
接下来按照数据仓库分层搭建。