Hive安装
1. 下载Hive
- 访问网址https://dlcdn.apache.org/hive/hive-4.0.0 ,下载hive
- 将apache-hive-4.0.0-bin.tar.gz上传服务器解压
[jack@hadoop102 module]$ cd /opt/software/
[jack@hadoop102 software]$ ll
总用量 1742368
-rw-r--r--. 1 jack jack 458782861 5月 28 22:03 apache-hive-4.0.0-bin.tar.gz
-rw-r--r--. 1 jack jack 730107476 1月 15 16:38 hadoop-3.3.6.tar.gz
-rw-rw-r--. 1 jack jack 141887242 1月 15 16:52 jdk-8u391-linux-x64.tar.gz
[jack@hadoop102 software]$ tar -xvf apache-hive-4.0.0-bin.tar.gz -C /opt/module/
[jack@hadoop102 module]$ mv apache-hive-4.0.0-bin/ hive-4.0.0
[jack@hadoop102 hive-4.0.0]$ ll
总用量 224
drwxrwxr-x. 3 jack jack 177 5月 28 22:25 bin
drwxrwxr-x. 2 jack jack 4096 5月 28 23:21 conf
drwxrwxr-x. 2 jack jack 36 5月 28 22:25 contrib
drwxrwxr-x. 4 jack jack 34 5月 28 22:25 examples
drwxrwxr-x. 7 jack jack 68 5月 28 22:25 hcatalog
drwxrwxr-x. 2 jack jack 44 5月 28 22:25 jdbc
drwxrwxr-x. 4 jack jack 16384 5月 28 23:11 lib
-rw-r--r--. 1 jack jack 18827 1月 22 2020 LICENSE
drwxrwxr-x. 2 jack jack 4096 5月 28 22:25 licenses
-rw-r--r--. 1 jack jack 148405 1月 22 2020 licenses.xml
-rw-r--r--. 1 jack jack 165 1月 22 2020 NOTICE
-rw-r--r--. 1 jack jack 23396 1月 22 2020 RELEASE_NOTES.txt
drwxrwxr-x. 4 jack jack 35 5月 28 22:25 scripts- 配置Hive环境变量
[jack@hadoop102 profile.d]$ sudo vi hive_env.sh
# 添加以下内容
# HIVE_HOME
export HIVE_HOME=/opt/module/hive-4.0.0
export PATH=$PATH:$HIVE_HOME/bin
# 配置立即生效
[jack@hadoop102 profile.d]$ source /etc/profile
[jack@hadoop102 profile.d]$ echo $HIVE_HOME
/opt/module/hive-4.0.02. Hive元数据存储到MySQL
Hive默认使用的元数据库为derby。derby数据库的特点是同一时间只允许一个客户端访问。如果多个Hive客户端同时访问,就会报错。由于在企业开发中,都是多人协作开发,需要多客户端同时访问Hive,怎么解决呢?我们可以将Hive的元数据改为用MySQL存储,MySQL支持多客户端同时访问。
MySQL数据库安装请参考笔记MySQL安装进行操作。
2.1 新建Hive元数据库
mysql> CREATE DATABASE `metastore` DEFAULT CHARACTER SET utf8mb4 DEFAULT COLLATE utf8mb4_zh_0900_as_cs;
## #创建数据库用户 hive 为其设置密码
mysql> CREATE USER 'hive'@'%' IDENTIFIED BY 'hive';
## 授予metastore数据库的所有访问权限
mysql> GRANT ALL PRIVILEGES ON metastore.* TO 'hive'@'%';
mysql> flush privileges;
mysql> quit;提示
MySql8以上版本支持排序规则【utf8mb4_zh_0900_as_cs】这种规则汉字是按拼音排序的,顺序是【null、空、字符+-.、汉字拼音序、字母abc】,并且where语句能区分开全角和半角,其他排序规则会把全角()和半角()当成一样的。
【utf8mb4_general_ci】数据大小写不敏感。
【utf8mb4_0900_ai_ci】区分大小写,但是这种规则下汉字排序不是按拼音顺序,并且不区分全角半角字符。
2.2 将MySQL的JDBC驱动拷贝到Hive的lib目录下
[jack@hadoop102 software]$ cp mysql-connector-java-8.0.30.jar /opt/module/hive-4.0.0/lib/2.3 在$HIVE_HOME/conf目录下新建hive-site.xml文件
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- jdbc连接的URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value>
</property>
<!-- jdbc连接的Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc连接的username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<!-- jdbc连接的password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
</property>
<!-- Hive默认在HDFS的工作目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
</configuration>💡注意
配置hive.metastore.uris需要改为metastore服务所在节点,端口号无需修改,metastore服务的默认端口就是9083
2.4 初始化Hive元数据库
[jack@hadoop102 profile.d]$ sh $HIVE_HOME/bin/schematool -dbType mysql -initSchema -verbose
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/hive-4.0.0/lib/log4j-slf4j-impl-2.18.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.3.6/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Initializing the schema to: 4.0.0
Metastore connection URL: jdbc:mysql://hadoop105:3306/metastore?useSSL=false
Metastore connection Driver : com.mysql.jdbc.Driver
Metastore connection User: root
Loading class `com.mysql.jdbc.Driver'. This is deprecated. The new driver class is `com.mysql.cj.jdbc.Driver'. The driver is automatically registered via the SPI and manual loading of the driver class is generally unnecessary.
Starting metastore schema initialization to 4.0.0
Initialization script hive-schema-4.0.0.mysql.sql
Connecting to jdbc:mysql://hadoop105:3306/metastore?useSSL=false
Connected to: MySQL (version 8.0.35)
Driver: MySQL Connector/J (version mysql-connector-java-8.0.30 (Revision: 1de2fe873fe26189564c030a343885011412976a))
Transaction isolation: TRANSACTION_READ_COMMITTED
......
0: jdbc:mysql://hadoop105:3306/metastore> !closeall
Closing: 0: jdbc:mysql://hadoop105:3306/metastore?useSSL=false
beeline>
beeline> Initialization script completed执行完成后,查看metastore库的表 
2.5 解决日志Jar包冲突
从上面初始化元数据的执行日志可以看出,日志门面现在有两个,分别在hive、hadoop中,优先去掉hive中的日志门面。
[jack@hadoop102 ~]$ mv $HIVE_HOME/lib/log4j-slf4j-impl-2.18.0.jar $HIVE_HOME/lib/log4j-slf4j-impl-2.18.0.bak
## 查看日志效果,一下子日志打印干爽了
[jack@hadoop102 ~]$ hive --version
Hive 4.0.0
Git git://MacBook-Pro.local/Users/denyskuzmenko/projects/hive/fork/hive -r 183f8cb41d3dbed961ffd27999876468ff06690c
Compiled by denyskuzmenko on Mon Mar 25 12:44:09 CET 2024
From source with checksum e3c64bec52632c61cf7214c8b545b5643. 配置Hadoop
Hive需要依赖Hadoop服务来运行,因此需要确保Hadoop服务已经启动,
3.1 配置相关Hive访问和优化
在hadoop102、hadoop103、hadoop104中添加以下内容:
<!-- 允许 Hive 代理用户访问 Hadoop 文件系统设置 -->
<property>
<name>hadoop.proxyuser.jack.hosts</name>
<value>*</value>
</property>
<!-- 允许 Hive 代理用户访问 Hadoop 文件系统设置 -->
<property>
<name>hadoop.proxyuser.jack.groups</name>
<value>*</value>
</property>
<!--配置jack用户能够代理的用户为任意用户-->
<property>
<name>hadoop.proxyuser.jack.users</name>
<value>*</value>
</property>
<!--开启hdfs垃圾回收机制,可以将删除数据从其中回收,单位为分钟-->
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property><!-- Hadoop小文件解决: 开启uber模式,默认关闭 -->
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<!-- uber模式中最大的mapTask数量,可向下修改 -->
<property>
<name>mapreduce.job.ubertask.maxmaps</name>
<value>9</value>
</property>
<!-- uber模式中最大的reduce数量,可向下修改 -->
<property>
<name>mapreduce.job.ubertask.maxreduces</name>
<value>1</value>
</property>上面配置项hadoop.proxyuser.xxxx.hosts、hadoop.proxyuser.xxxx.groups、hadoop.proxyuser.xxxx.users是hivesever2的模拟用户功能,依赖于Hadoop提供的proxy user(代理用户功能),只有Hadoop中的代理用户才能模拟其他用户的身份访问Hadoop集群。因此,需要将hiveserver2的启动用户设置为Hadoop的代理用户。
3.2 启动hadoop集群
[jack@hadoop102 ~]$ hadoop_helper start
=================== 启动 hadoop集群 ===================
--------------- 启动 hdfs ---------------
Starting namenodes on [hadoop102]
Starting datanodes
Starting secondary namenodes [hadoop104]
--------------- 启动 yarn ---------------
Starting resourcemanager
Starting nodemanagers
--------------- 启动 historyserver ---------------4. Hiveserver2介绍
Hive的hiveserver2服务的作用是提供jdbc/odbc接口,为用户提供远程访问Hive数据的功能,例如用户期望在个人电脑中访问远程服务中的Hive数据,就需要用到Hiveserver2。
4.1 用户说明
在远程访问Hive数据时,客户端并未直接访问Hadoop集群,而是由Hivesever2代理访问。由于Hadoop集群中的数据具备访问权限控制,所以此时需考虑一个问题:那就是访问Hadoop集群的用户身份是谁?是Hiveserver2的启动用户?还是客户端的登录用户?
答案是都有可能,具体是谁,由Hiveserver2的hive.server2.enable.doAs参数决定,该参数的含义是是否启用Hiveserver2用户模拟的功能。若启用,则Hiveserver2会模拟成客户端的登录用户去访问Hadoop集群的数据,不启用,则Hivesever2会直接使用启动用户访问Hadoop集群数据。模拟用户的功能,默认是开启的。hive.server2.enable.doAs=false的情况: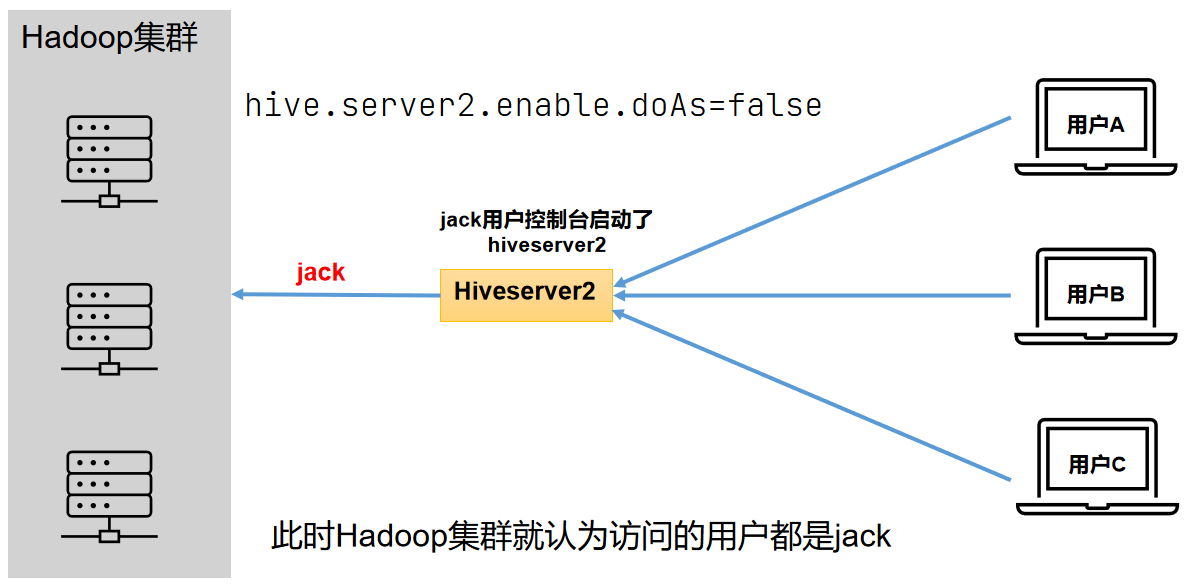
hive.server2.enable.doAs=true的情况: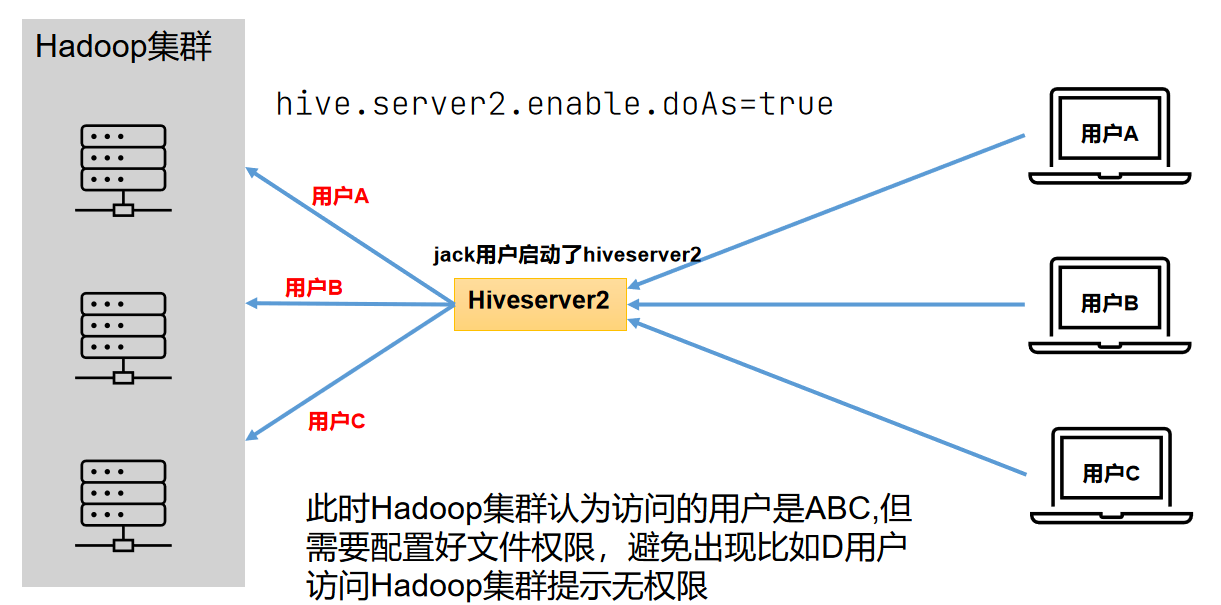
4.2 配置Hiveserver2服务
编辑hive-site.xml文件
<!-- 指定存储元数据要连接的地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop102:9083</value>
</property>
<!-- 指定hiveserver2连接的host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop102</value>
</property>
<!-- 指定hiveserver2连接的端口号 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<!-- hiveserver2的高可用参数,如果不开会导致了开启tez session导致hiveserver2无法启动 -->
<property>
<name>hive.server2.active.passive.ha.enable</name>
<value>true</value>
</property>
<!--解决Error initializing notification event poll问题-->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>4.3 启动HiveServer2服务
HiveServer2是Hive的查询服务,需要确保HiveServer2服务已经启动。
- 启动方法1
[jack@hadoop102 ~]$ hive --service hiveserver2 &
[2] 84306
[jack@hadoop102 ~]$ which: no hbase in (/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/opt/module/jdk1.8.0_391/bin:/opt/module/hadoop-3.3.6/bin:/opt/module/hadoop-3.3.6/sbin:/opt/module/hive-4.0.0/bin:/home/jack/.local/bin:/home/jack/bin)
[jack@hadoop102 ~]$ 2024-05-29 23:28:13: Starting HiveServer2
[jack@hadoop102 ~]$ Hive Session ID = f3eafa11-603b-4a53-9e1b-de64f1647eb5- 启动方式2,利用hiveserver2脚本启动
[jack@hadoop102 ~]$ cd /opt/module/hive-4.0.0/bin
[jack@hadoop102 bin]$ ll
总用量 52
-rwxr-xr-x. 1 jack jack 881 1月 22 2020 beeline
drwxrwxr-x. 3 jack jack 4096 5月 28 22:25 ext
-rwxr-xr-x. 1 jack jack 10835 1月 22 2020 hive
-rwxr-xr-x. 1 jack jack 2085 1月 22 2020 hive-config.sh
-rwxr-xr-x. 1 jack jack 885 1月 22 2020 hiveserver2
-rwxr-xr-x. 1 jack jack 880 1月 22 2020 hplsql
-rwxr-xr-x. 1 jack jack 3064 1月 22 2020 init-hive-dfs.sh
-rwxr-xr-x. 1 jack jack 832 1月 22 2020 metatool
-rwxr-xr-x. 1 jack jack 5891 1月 22 2020 replstats.sh
-rwxr-xr-x. 1 jack jack 884 1月 22 2020 schematool访问Hive2的Web控制界面: http://hadoop102:10002/ ,如下图所示,HiveServer2启动完毕 
5. Metastore服务
Hive的metastore服务的作用是为Hive CLI或者Hiveserver2提供元数据访问接口。
5.1 metastore运行模式
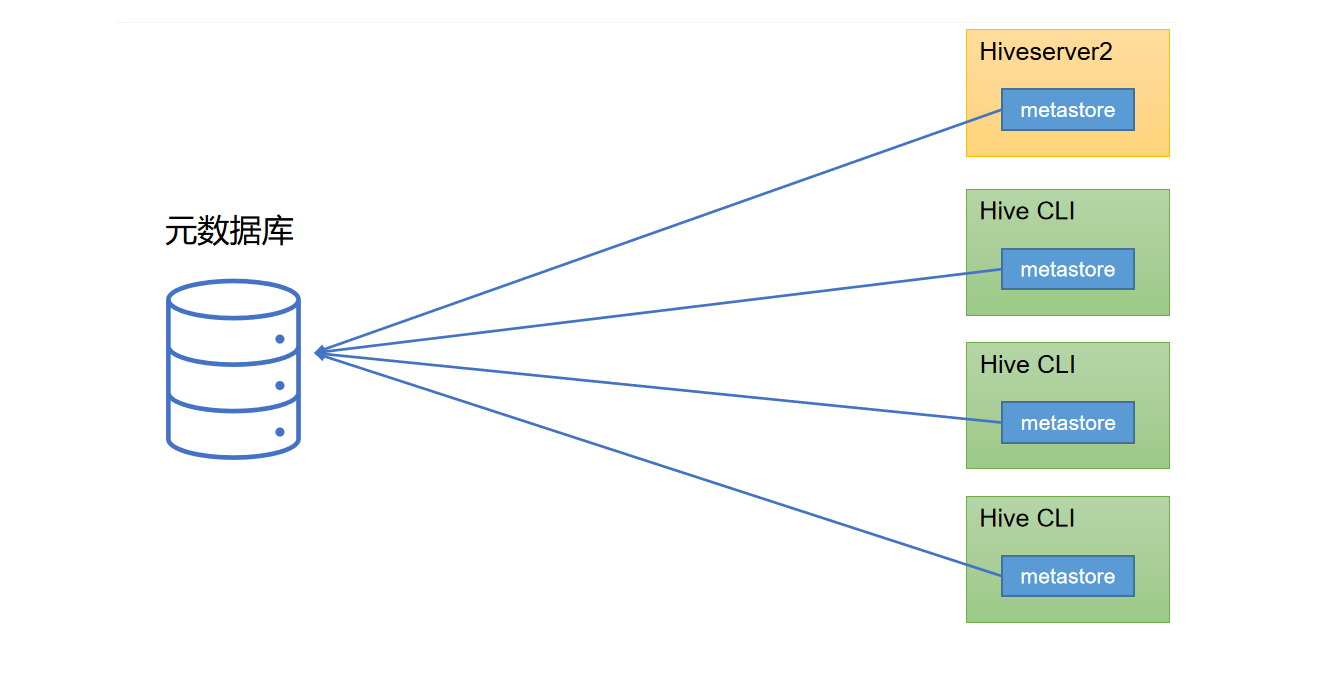
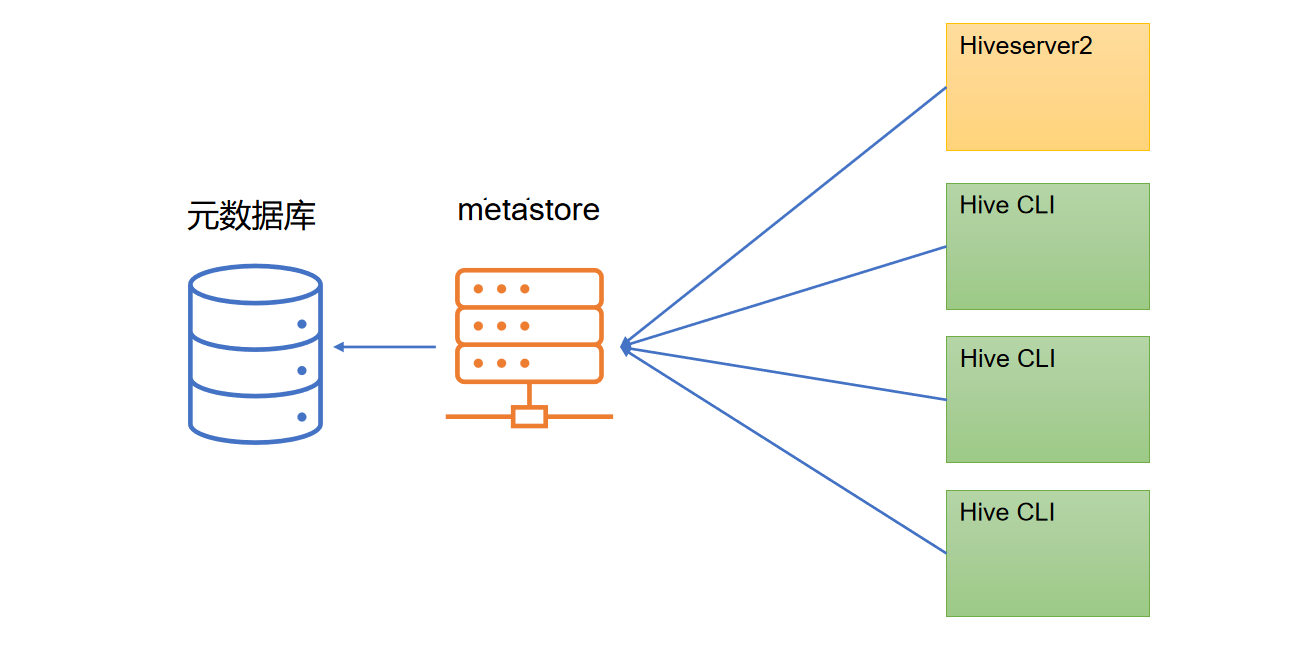
metastore有两种运行模式,分别为嵌入式模式和独立服务模式。下面分别对两种模式进行说明:
- 嵌入式模式
- 独立服务模式
 生产环境中,不推荐使用嵌入式模式。因为其存在以下两个问题:
生产环境中,不推荐使用嵌入式模式。因为其存在以下两个问题:
(1)嵌入式模式下,每个Hive CLI都需要直接连接元数据库,当Hive CLI较多时,数据库压力会比较大。
(2)每个客户端都需要用户元数据库的读写权限,元数据库的安全得不到很好的保证。
5.2 配置Metastore
编辑hive-site.xml文件
<!-- jdbc连接的URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value>
</property>
<!-- jdbc连接的Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc连接的username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<!-- jdbc连接的password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
</property>
<!-- 独立服务模式的配置,指定存储元数据要连接的地址-->
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop102:9083</value>
</property>5.3 启动Hive Metastore服务
Hive Metastore是Hive的元数据存储服务,需要确保Metastore服务已经启动。
[jack@hadoop102 ~]$ hive --service metastore &
[1] 84146
[jack@hadoop102 ~]$ which: no hbase in (/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/opt/module/jdk1.8.0_391/bin:/opt/module/hadoop-3.3.6/bin:/opt/module/hadoop-3.3.6/sbin:/opt/module/hive-4.0.0/bin:/home/jack/.local/bin:/home/jack/bin)
[jack@hadoop102 ~]$ 2024-05-29 23:27:25: Starting Hive Metastore Server6. 命令行连接Hive
在Hive 4.0.0中,Hive CLI已经被弃用,取而代之的是Beeline。启动Hive 4.0.0时,你会默认进入Beeline命令行界面,而不是Hive CLI。因此如果你想使用Hive CLI,你可以考虑降低Hive的版本,或者在Hive 4.0.0中使用Beeline命令行。Beeline连接Hive需要用到Metastore服务和HiveServer2服务。
6.1 执行hive命令
[jack@hadoop102 ~]$ hive
Beeline version 4.0.0 by Apache Hive
beeline>连接hive的第二种方式: 使用beeline命令进行控制台
beeline -u jdbc:hive2://hadoop102:10000 -n jack6.2 输入建立连接命令
由于没有开启hive的用户身份验证功能,用户密码可以不填或者随机输入都可以,hive不会判断密码的正确性,输入的用户名将会作为实际的hadoop集群的访问用户。
beeline> !connect jdbc:hive2://hadoop102:10000
Connecting to jdbc:hive2://hadoop102:10000
Enter username for jdbc:hive2://hadoop102:10000: jack
Enter password for jdbc:hive2://hadoop102:10000: ****
Connected to: Apache Hive (version 4.0.0)
Driver: Hive JDBC (version 4.0.0)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://hadoop102:10000> show databases;
INFO : Compiling command(queryId=jack_20240529235311_e2cf1e0a-77af-4360-9836-88ca2acd5da9): show databases
INFO : Semantic Analysis Completed (retrial = false)
INFO : Created Hive schema: Schema(fieldSchemas:[FieldSchema(name:database_name, type:string, comment:from deserializer)], properties:null)
INFO : Completed compiling command(queryId=jack_20240529235311_e2cf1e0a-77af-4360-9836-88ca2acd5da9); Time taken: 3.156 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=jack_20240529235311_e2cf1e0a-77af-4360-9836-88ca2acd5da9): show databases
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=jack_20240529235311_e2cf1e0a-77af-4360-9836-88ca2acd5da9); Time taken: 0.144 seconds
+----------------+
| database_name |
+----------------+
| default |
+----------------+
1 row selected (4.074 seconds)
0: jdbc:hive2://hadoop102:10000> show tables;
INFO : Compiling command(queryId=jack_20240529235659_0f6e48d3-6404-4df7-91b0-cbe808c3301b): show tables
INFO : Semantic Analysis Completed (retrial = false)
INFO : Created Hive schema: Schema(fieldSchemas:[FieldSchema(name:tab_name, type:string, comment:from deserializer)], properties:null)
INFO : Completed compiling command(queryId=jack_20240529235659_0f6e48d3-6404-4df7-91b0-cbe808c3301b); Time taken: 0.041 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=jack_20240529235659_0f6e48d3-6404-4df7-91b0-cbe808c3301b): show tables
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=jack_20240529235659_0f6e48d3-6404-4df7-91b0-cbe808c3301b); Time taken: 0.075 seconds
+-----------+
| tab_name |
+-----------+
+-----------+
No rows selected (0.163 seconds)
0: jdbc:hive2://hadoop102:10000> !quit7. 建表测试
0: jdbc:hive2://hadoop102:10000> create table stu(id int, name string);
INFO : Compiling command(queryId=jack_20240529235715_ae5fc1d9-b37d-4955-8690-2ef6038f0bbe): create table stu(id int, name string)
INFO : Semantic Analysis Completed (retrial = false)
INFO : Created Hive schema: Schema(fieldSchemas:null, properties:null)
INFO : Completed compiling command(queryId=jack_20240529235715_ae5fc1d9-b37d-4955-8690-2ef6038f0bbe); Time taken: 0.07 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=jack_20240529235715_ae5fc1d9-b37d-4955-8690-2ef6038f0bbe): create table stu(id int, name string)
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=jack_20240529235715_ae5fc1d9-b37d-4955-8690-2ef6038f0bbe); Time taken: 0.463 seconds
No rows affected (0.554 seconds)
0: jdbc:hive2://hadoop102:10000> insert into stu values(1,"ss");
INFO : Compiling command(queryId=jack_20240529235726_6662e95f-0ef7-45dd-94e1-fe995ff0a917): insert into stu values(1,"ss")
INFO : Semantic Analysis Completed (retrial = false)
INFO : Created Hive schema: Schema(fieldSchemas:[FieldSchema(name:col1, type:int, comment:null), FieldSchema(name:col2, type:string, comment:null)], properties:null)
INFO : Completed compiling command(queryId=jack_20240529235726_6662e95f-0ef7-45dd-94e1-fe995ff0a917); Time taken: 5.189 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=jack_20240529235726_6662e95f-0ef7-45dd-94e1-fe995ff0a917): insert into stu values(1,"ss")
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. tez) or using Hive 1.X releases.
INFO : Query ID = jack_20240529235726_6662e95f-0ef7-45dd-94e1-fe995ff0a917
INFO : Total jobs = 3
INFO : Launching Job 1 out of 3
INFO : Starting task [Stage-1:MAPRED] in serial mode
INFO : Number of reduce tasks determined at compile time: 1
INFO : In order to change the average load for a reducer (in bytes):
INFO : set hive.exec.reducers.bytes.per.reducer=<number>
INFO : In order to limit the maximum number of reducers:
INFO : set hive.exec.reducers.max=<number>
INFO : In order to set a constant number of reducers:
INFO : set mapreduce.job.reduces=<number>
INFO : number of splits:1
INFO : Submitting tokens for job: job_1716995414086_0001
INFO : Executing with tokens: []
INFO : The url to track the job: http://hadoop103:8088/proxy/application_1716995414086_0001/
INFO : Starting Job = job_1716995414086_0001, Tracking URL = http://hadoop103:8088/proxy/application_1716995414086_0001/
INFO : Kill Command = /opt/module/hadoop-3.3.6/bin/mapred job -kill job_1716995414086_0001
INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
INFO : 2024-05-29 23:57:58,120 Stage-1 map = 0%, reduce = 0%
INFO : 2024-05-29 23:58:13,036 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 5.34 sec
INFO : 2024-05-29 23:58:36,109 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 10.97 sec
INFO : MapReduce Total cumulative CPU time: 10 seconds 970 msec
INFO : Ended Job = job_1716995414086_0001
INFO : Starting task [Stage-7:CONDITIONAL] in serial mode
INFO : Stage-4 is selected by condition resolver.
INFO : Stage-3 is filtered out by condition resolver.
INFO : Stage-5 is filtered out by condition resolver.
INFO : Starting task [Stage-4:MOVE] in serial mode
INFO : Moving data to directory hdfs://hadoop102:8020/user/hive/warehouse/stu/.hive-staging_hive_2024-05-29_23-57-26_802_4392586933345008842-1/-ext-10000 from hdfs://hadoop102:8020/user/hive/warehouse/stu/.hive-staging_hive_2024-05-29_23-57-26_802_4392586933345008842-1/-ext-10002
INFO : Starting task [Stage-0:MOVE] in serial mode
INFO : Loading data to table default.stu from hdfs://hadoop102:8020/user/hive/warehouse/stu/.hive-staging_hive_2024-05-29_23-57-26_802_4392586933345008842-1/-ext-10000
INFO : Starting task [Stage-2:STATS] in serial mode
INFO : Executing stats task
INFO : Table default.stu stats: [numFiles=1, numRows=1, totalSize=5, rawDataSize=4, numFilesErasureCoded=0]
INFO : MapReduce Jobs Launched:
INFO : Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 10.97 sec HDFS Read: 21606 HDFS Write: 232 HDFS EC Read: 0 SUCCESS
INFO : Total MapReduce CPU Time Spent: 10 seconds 970 msec
INFO : Completed executing command(queryId=jack_20240529235726_6662e95f-0ef7-45dd-94e1-fe995ff0a917); Time taken: 66.722 seconds
1 row affected (71.947 seconds)可以看出Hive并不擅长数据录入,数据批量最好还是走Hadoop直接导入。
在hadoop的historyserver上面查看mapreduce执行记录: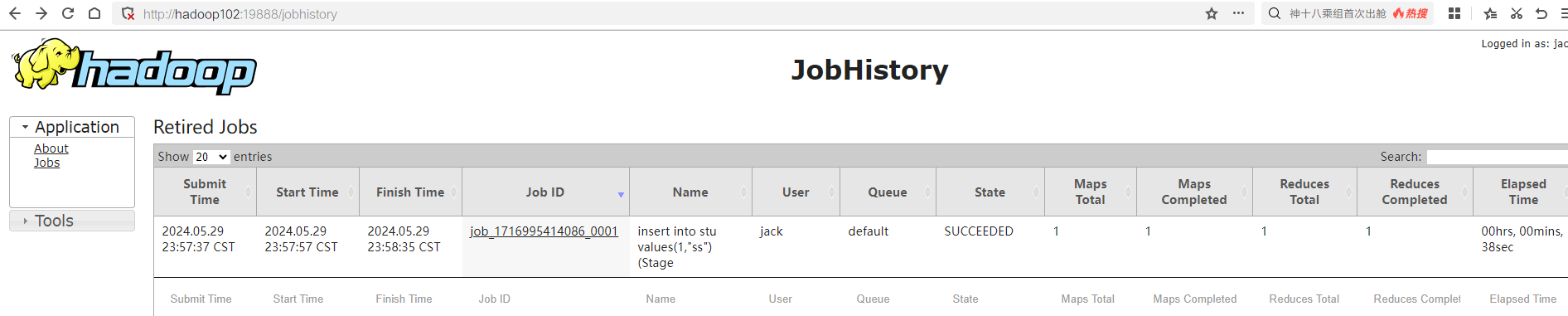 在hadoop的HDFS上面查看文件信息:
在hadoop的HDFS上面查看文件信息: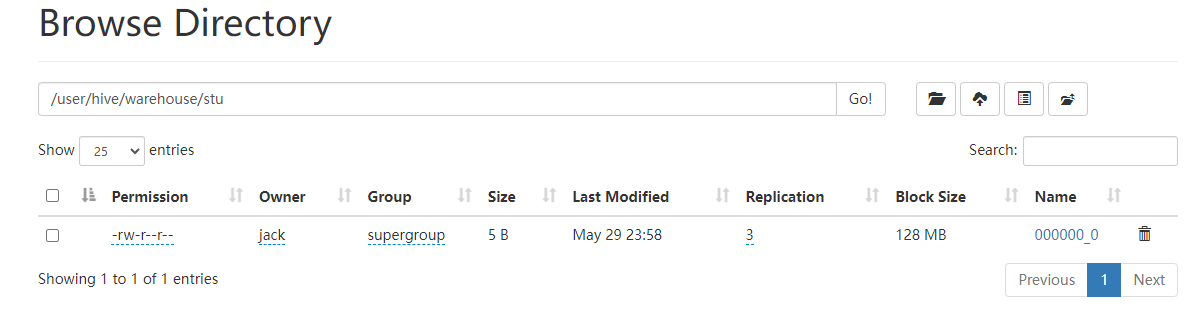
8. 查看MySQL中的元数据
- 登录MySQL
[jack@hadoop105 ~]$ mysql -uroot -proot
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 2480
Server version: 8.0.35 MySQL Community Server - GPL
Copyright (c) 2000, 2023, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.- 查看元数据库中存储的库信息
mysql> use metastore;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> select * from DBS;
+-------+-----------------------+-------------------------------------------+---------+------------+------------+-----------+-------------+-------------------------+--------+--------------------+---------------+
| DB_ID | DESC | DB_LOCATION_URI | NAME | OWNER_NAME | OWNER_TYPE | CTLG_NAME | CREATE_TIME | DB_MANAGED_LOCATION_URI | TYPE | DATACONNECTOR_NAME | REMOTE_DBNAME |
+-------+-----------------------+-------------------------------------------+---------+------------+------------+-----------+-------------+-------------------------+--------+--------------------+---------------+
| 1 | Default Hive database | hdfs://hadoop102:8020/user/hive/warehouse | default | public | ROLE | hive | 1716996457 | NULL | NATIVE | NULL | NULL |
+-------+-----------------------+-------------------------------------------+---------+------------+------------+-----------+-------------+-------------------------+--------+--------------------+---------------+
1 row in set (0.00 sec)- 查看元数据库中存储的表信息
mysql> select * from TBLS;
+--------+-------------+-------+------------------+-------+------------+-----------+-------+----------+----------------+--------------------+--------------------+----------------------------------------+----------+
| TBL_ID | CREATE_TIME | DB_ID | LAST_ACCESS_TIME | OWNER | OWNER_TYPE | RETENTION | SD_ID | TBL_NAME | TBL_TYPE | VIEW_EXPANDED_TEXT | VIEW_ORIGINAL_TEXT | IS_REWRITE_ENABLED | WRITE_ID |
+--------+-------------+-------+------------------+-------+------------+-----------+-------+----------+----------------+--------------------+--------------------+----------------------------------------+----------+
| 1 | 1716998235 | 1 | 0 | jack | USER | 0 | 1 | stu | EXTERNAL_TABLE | NULL | NULL | 0x00 | 0 |
+--------+-------------+-------+------------------+-------+------------+-----------+-------+----------+----------------+--------------------+--------------------+----------------------------------------+----------+
1 row in set (0.00 sec)- 查看元数据库中存储的表中列相关信息
mysql> select * from COLUMNS_V2;
+-------+---------+-------------+-----------+-------------+
| CD_ID | COMMENT | COLUMN_NAME | TYPE_NAME | INTEGER_IDX |
+-------+---------+-------------+-----------+-------------+
| 1 | NULL | id | int | 0 |
| 1 | NULL | name | string | 1 |
+-------+---------+-------------+-----------+-------------+
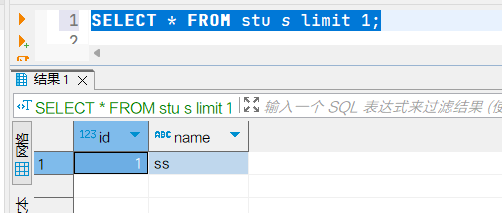
2 rows in set (0.00 sec)9. 使用图形化客户端进行远程访问
9.1 配置DBeaver连接
- 新建连接

- 配置属性
 初次使用,配置过程会提示缺少JDBC驱动,按照提示下载即可。
初次使用,配置过程会提示缺少JDBC驱动,按照提示下载即可。
9.2 测试sql执行