源码环境准备
1. 源码下载地址
访问 http://kafka.apache.org/downloads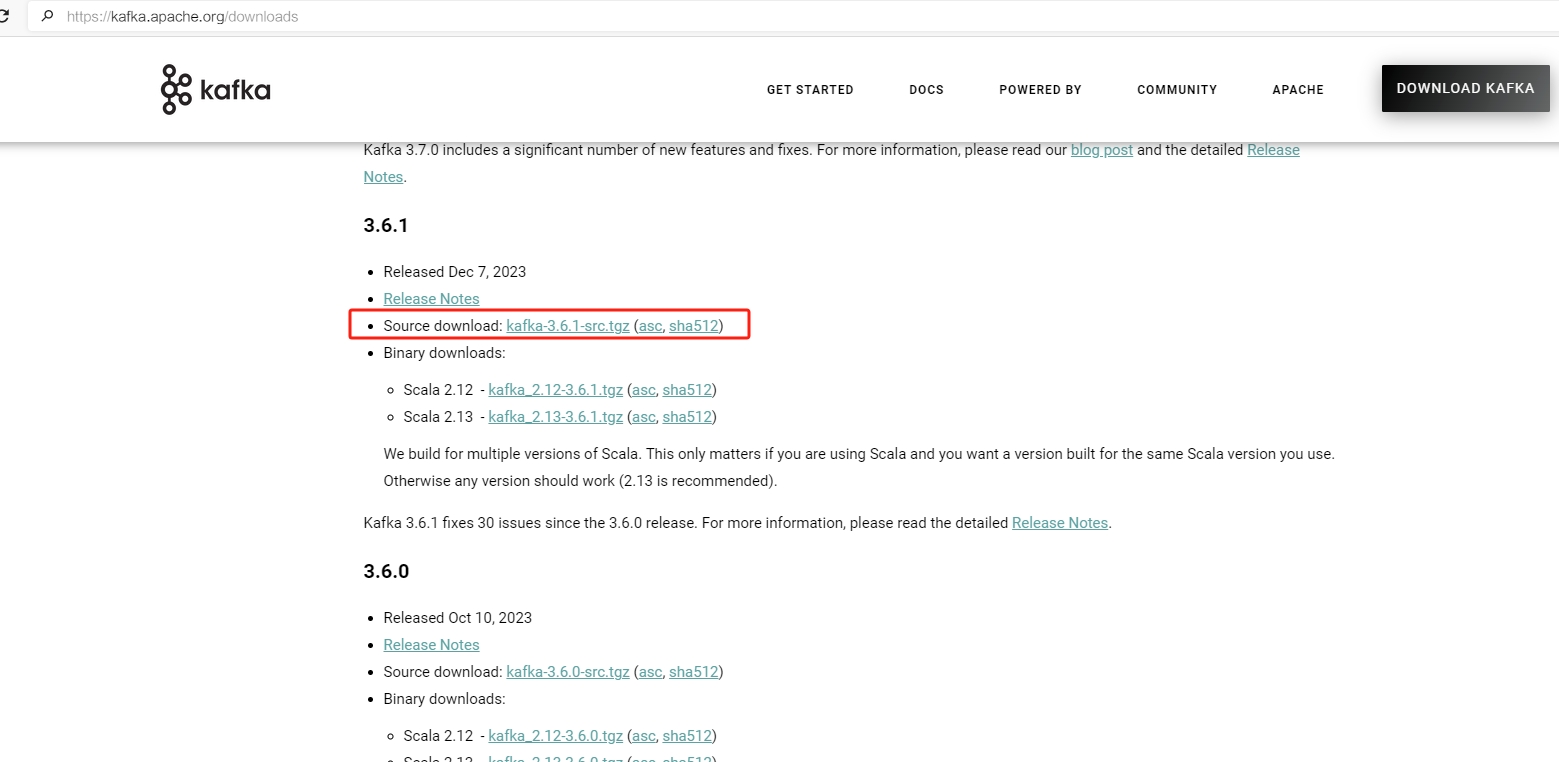
2. 安装JDK&Scala
3. 安装Gradle
Gradle是类似于Maven的代码管理工具。
进入Gradle官网下载地址:https://gradle.org/releases/
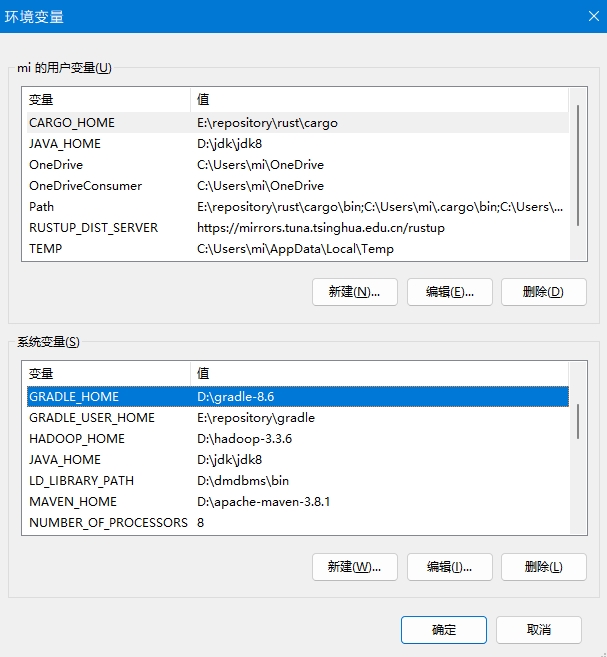
添加环境变量:
- GRADLE_HOME: gradle的文件夹路径
- GRADLE_USER_HOME:本地仓库路径
4. IDEA加载源码
- 将kafka-3.6.1-src.tgz源码包,解压到非中文目录。
- 打开IDEA,点击File->Open…->源码包解压的位置。
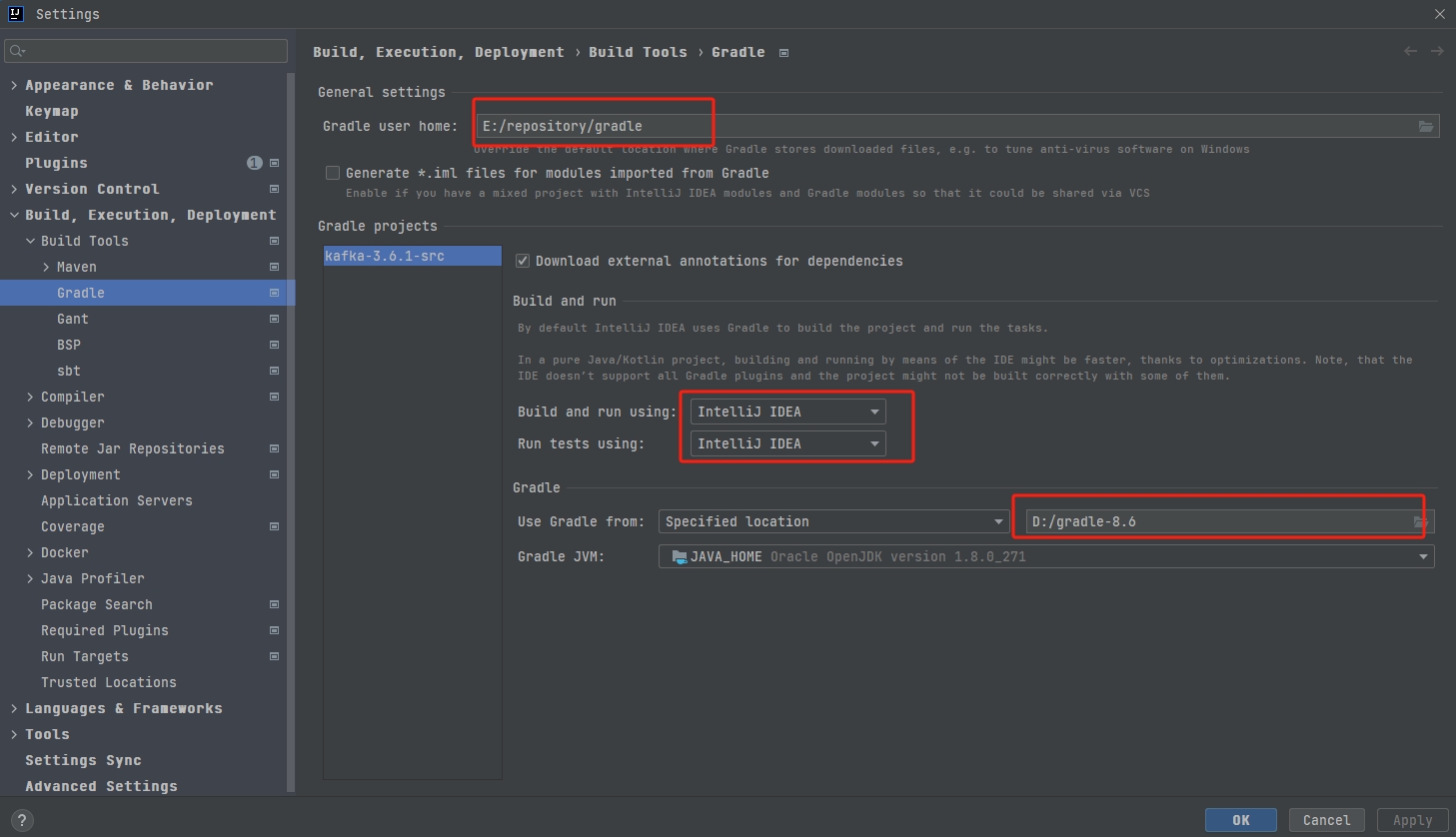
- 配置项目应用本地Gradle
5. 执行编译
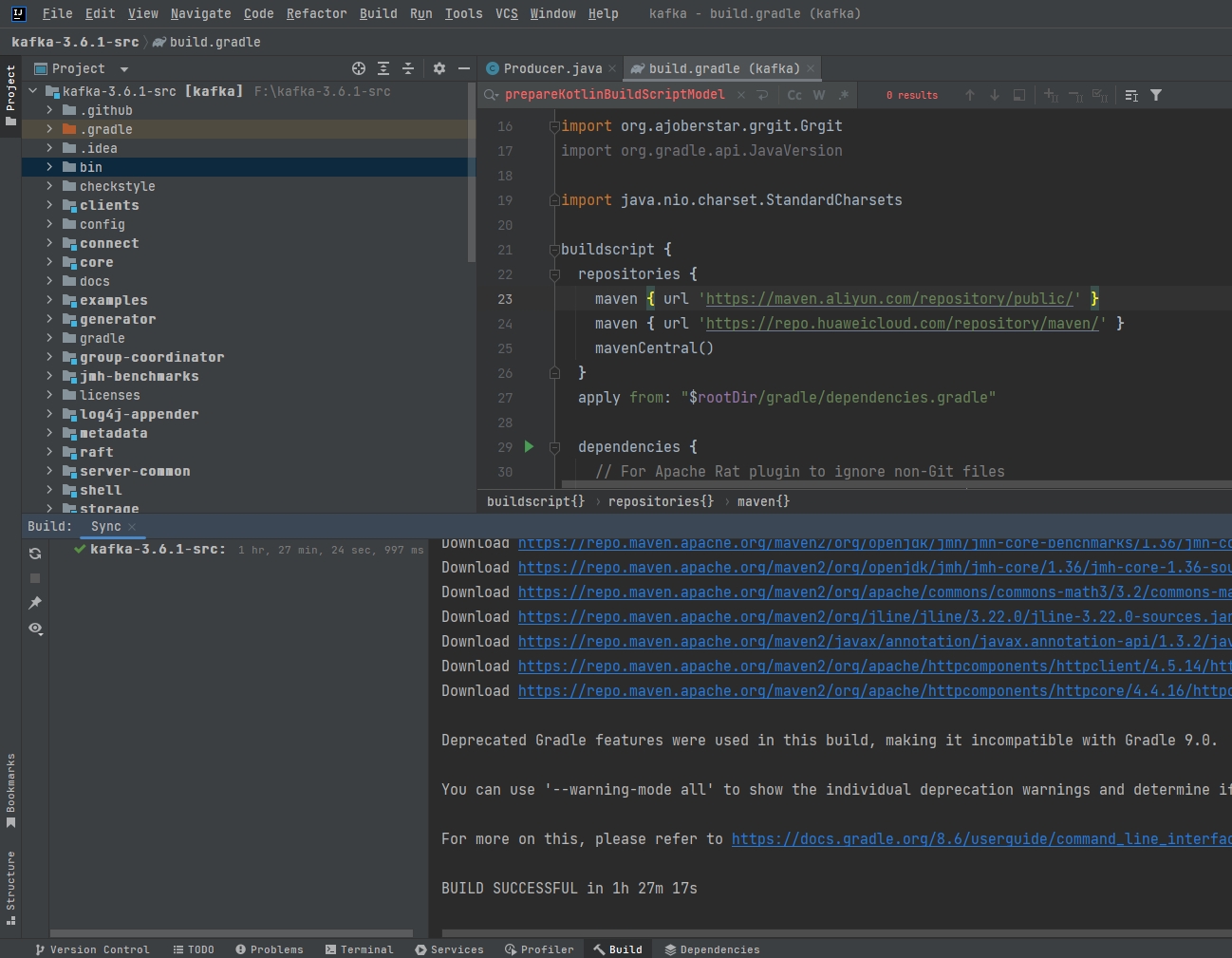
调整build.gradle的maven仓库地址:
buildscript {
repositories {
maven { url 'https://maven.aliyun.com/repository/public/' }
maven { url 'https://repo.huaweicloud.com/repository/maven/' }
mavenCentral()
}