Kafka副本
1. 副本概述
- Kafka 副本作用:提高数据可靠性。
- Kafka 默认副本 1个,生产环境一般配置为2个,保证数据可靠性;太多副本会增加磁盘存储空间,增加网络上数据传输,降低效率。
- Kafka 中副本分为:Leader和Follower。Kafka 生产者只会把数据发往 Leader,然后 Follower 找 Leader 进行同步数据。
- Kafka 分区中的所有副本统称为AR(Assigned Repllicas)。AR = ISR + OSR ISR表示和Leader保持同步的Follower集合。如果Follower长时间未向Leader发送通信请求或同步数据,则该Follower将被踢出ISR。该时间阈值由
replica.lag.time.max.ms参数设定,默认30s。Leader发生故障之后,就会从ISR中选举新的Leader。OSR表示Follower与Leader副本同步时,延迟过多的副本
2. Leader选举流程
Kafka集群中有一个Broker的Controller会被选举为Controller Leader,负责管理集群broker的上下线,所有 topic 的分区副本分配和 Leader 选举等工作。Controller的信息同步工作是依赖于Zookeeper的。 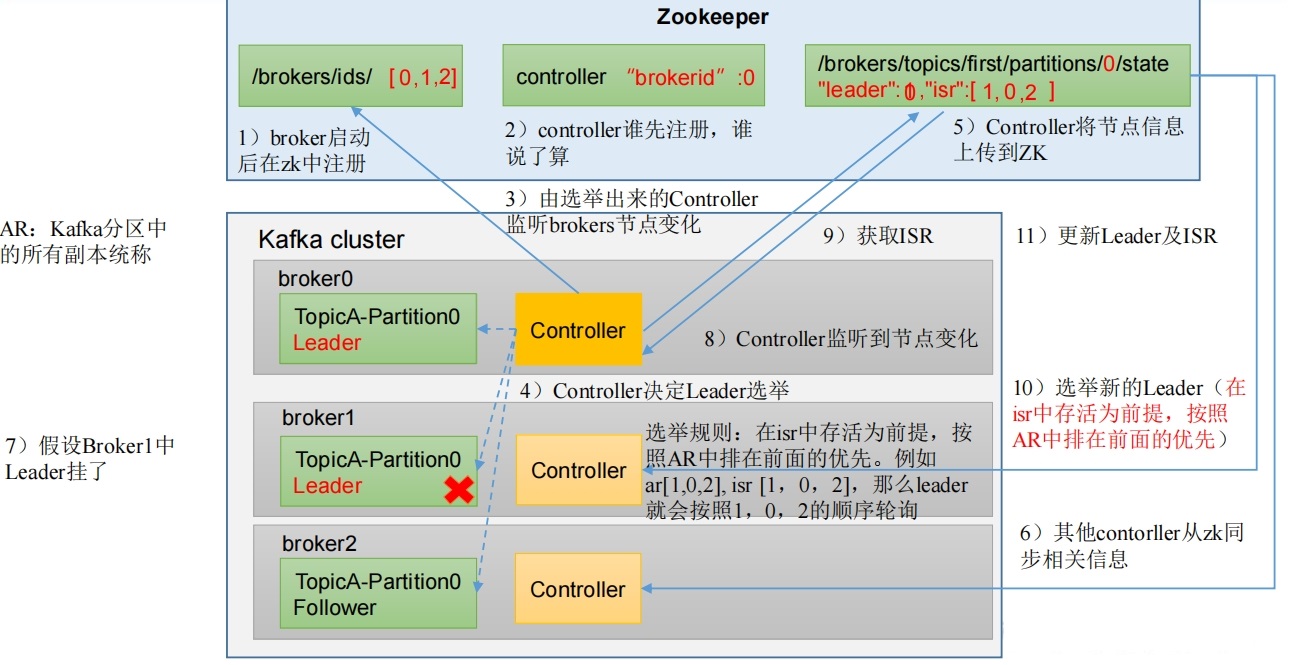
- 创建一个新的 topic,3 个分区,3 个副本
sh
[jack@hadoop105 kafka-3.6.1]$ ./bin/kafka-topics.sh --bootstrap-server 192.168.101.106:9092 --create --topic demo_1 --partitions 3 --replication-factor 3
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Created topic demo_1.- 查看Leader分布情况
sh
[jack@hadoop105 kafka-3.6.1]$ ./bin/kafka-topics.sh --bootstrap-server 192.168.101.106:9092 --describe --topic testtopic
Topic: testtopic TopicId: MnxtaR5OSxGVvnLX2c8KJQ PartitionCount: 3 ReplicationFactor: 3 Configs:
Topic: testtopic Partition: 0 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3
Topic: testtopic Partition: 1 Leader: 2 Replicas: 2,3,1 Isr: 2,3,1
Topic: testtopic Partition: 2 Leader: 3 Replicas: 3,1,2 Isr: 3,1,2- 停止掉hadoop106(broderid为2)的Kafka进程,并查看Leader分区情况
sh
[jack@hadoop105 kafka-3.6.1]$ ./bin/kafka-topics.sh --bootstrap-server 192.168.101.106:9092 --describe --topic testtopic
Topic: testtopic TopicId: MnxtaR5OSxGVvnLX2c8KJQ PartitionCount: 3 ReplicationFactor: 3 Configs:
Topic: testtopic Partition: 0 Leader: 1 Replicas: 1,2,3 Isr: 1,2
Topic: testtopic Partition: 1 Leader: 2 Replicas: 2,3,1 Isr: 2,1
Topic: testtopic Partition: 2 Leader: 1 Replicas: 3,1,2 Isr: 1,2- 停止掉hadoop107(broderid为3)的Kafka进程,并查看Leader分区情况
sh
[jack@hadoop105 kafka-3.6.1]$ ./bin/kafka-topics.sh --bootstrap-server 192.168.101.105:9092 --describe --topic testtopic
Topic: testtopic TopicId: MnxtaR5OSxGVvnLX2c8KJQ PartitionCount: 3 ReplicationFactor: 3 Configs:
Topic: testtopic Partition: 0 Leader: 1 Replicas: 1,2,3 Isr: 1
Topic: testtopic Partition: 1 Leader: 1 Replicas: 2,3,1 Isr: 1
Topic: testtopic Partition: 2 Leader: 1 Replicas: 3,1,2 Isr: 1- 依次启动hadoop107(broderid为3)、hadoop106(broderid为2)的Kafka进程,并查看Leader分区情况
sh
[jack@hadoop105 kafka-3.6.1]$ ./bin/kafka-topics.sh --bootstrap-server 192.168.101.105:9092 --describe --topic testtopic
Topic: testtopic TopicId: MnxtaR5OSxGVvnLX2c8KJQ PartitionCount: 3 ReplicationFactor: 3 Configs:
Topic: testtopic Partition: 0 Leader: 1 Replicas: 1,2,3 Isr: 1,3
Topic: testtopic Partition: 1 Leader: 1 Replicas: 2,3,1 Isr: 1,3
Topic: testtopic Partition: 2 Leader: 1 Replicas: 3,1,2 Isr: 1,3
## 此时Leader全是brokerid为1的节点
[jack@hadoop105 kafka-3.6.1]$ ./bin/kafka-topics.sh --bootstrap-server 192.168.101.105:9092 --describe --topic testtopic
Topic: testtopic TopicId: MnxtaR5OSxGVvnLX2c8KJQ PartitionCount: 3 ReplicationFactor: 3 Configs:
Topic: testtopic Partition: 0 Leader: 1 Replicas: 1,2,3 Isr: 1,3,2
Topic: testtopic Partition: 1 Leader: 1 Replicas: 2,3,1 Isr: 1,3,2
Topic: testtopic Partition: 2 Leader: 1 Replicas: 3,1,2 Isr: 1,3,2
## Kafka会自动重选Leader,Leader并不全是1, 片刻重新查询副本情况
[jack@hadoop105 kafka-3.6.1]$ ./bin/kafka-topics.sh --bootstrap-server 192.168.101.105:9092 --describe --topic testtopic
Topic: testtopic TopicId: MnxtaR5OSxGVvnLX2c8KJQ PartitionCount: 3 ReplicationFactor: 3 Configs:
Topic: testtopic Partition: 0 Leader: 1 Replicas: 1,2,3 Isr: 1,3,2
Topic: testtopic Partition: 1 Leader: 2 Replicas: 2,3,1 Isr: 1,3,2
Topic: testtopic Partition: 2 Leader: 3 Replicas: 3,1,2 Isr: 1,3,2- 停止掉hadoop105(broderid为1)的Kafka进程,,并查看Leader分区情况
sh
## Partition为0的分区并没有出现Leader为3(如果按照此时的Isr次序(1,3,2)看的话,1之后就是3),
## 实际是按照AR顺序(Replicas的顺序), 先根据Isr过滤AR列表,之后按照AR列表顺序选出Leader.
[jack@hadoop105 kafka-3.6.1]$ ./bin/kafka-topics.sh --bootstrap-server 192.168.101.106:9092 --describe --topic testtopic
Topic: testtopic TopicId: MnxtaR5OSxGVvnLX2c8KJQ PartitionCount: 3 ReplicationFactor: 3 Configs:
Topic: testtopic Partition: 0 Leader: 2 Replicas: 1,2,3 Isr: 3,2
Topic: testtopic Partition: 1 Leader: 2 Replicas: 2,3,1 Isr: 3,2
Topic: testtopic Partition: 2 Leader: 3 Replicas: 3,1,2 Isr: 3,23. Follower故障处理细节
LEO(Log End Offset):每个副本的最后一个offset,LEO其实就是最新的offset + 1。
HW(High Watermark):所有副本中最小的LEO 。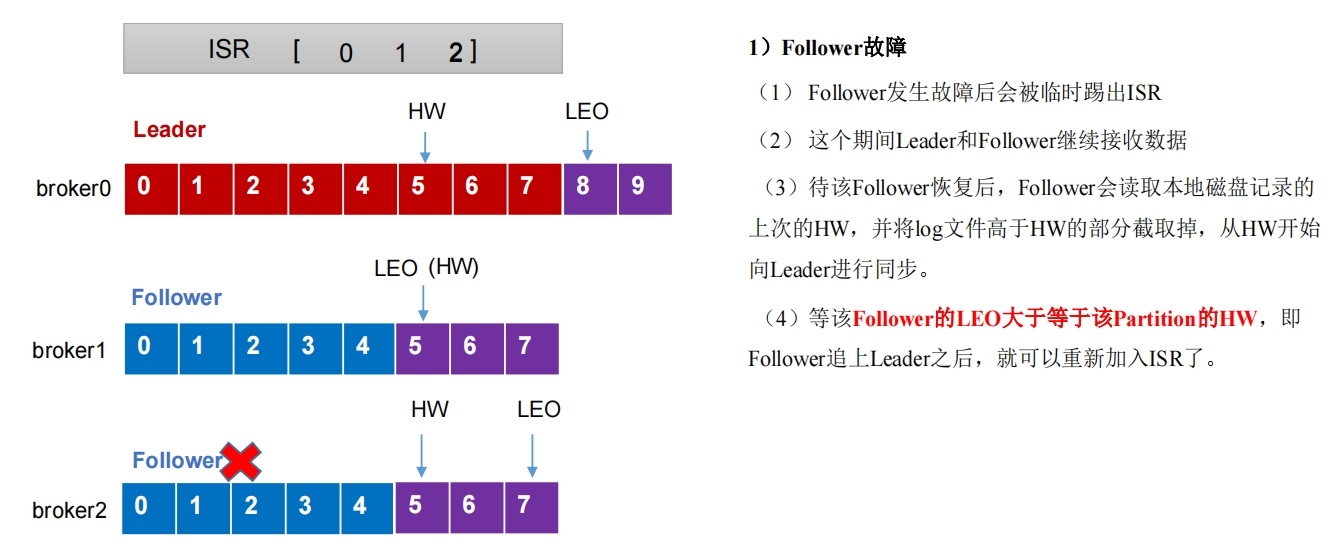
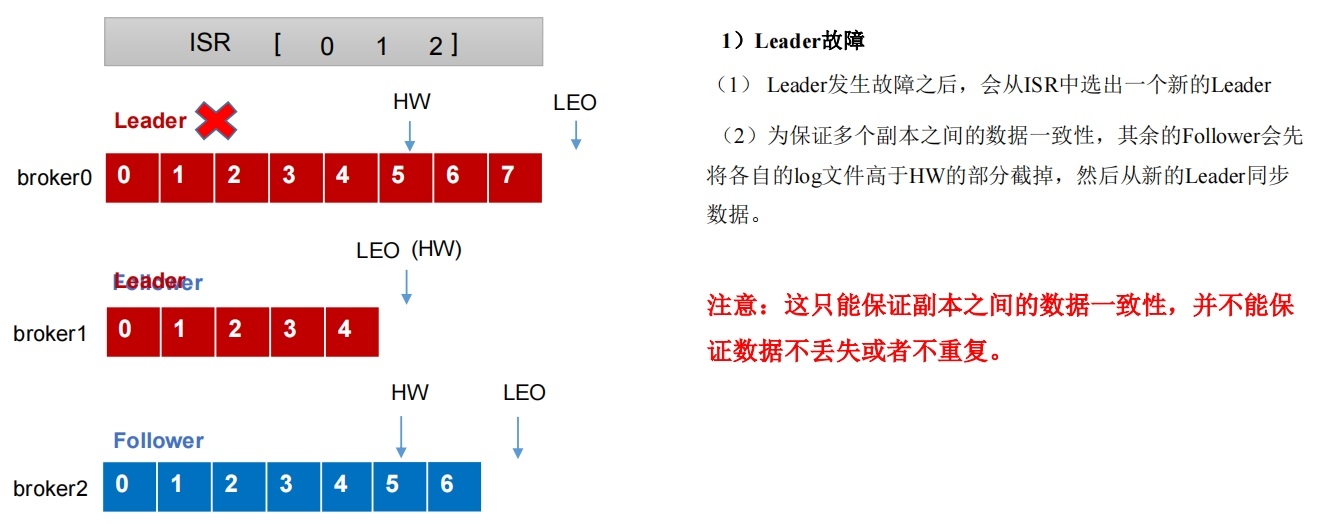
4. Leader故障处理细节
5. 手动调整分区副本存储
在生产环境中,每台服务器的配置和性能不一致,但是Kafka只会根据自己的代码规则创建对应的分区副本,就会导致个别服务器存储压力较大。所有需要手动调整分区副本的存储。
- 查看分区副本存储情况
sh
[jack@hadoop105 kafka-3.6.1]$ ./bin/kafka-topics.sh --bootstrap-server 192.168.101.106:9092 --describe --topic demo2
Topic: demo2 TopicId: 8z3pHJvxRDi5AdiYSy7GIw PartitionCount: 2 ReplicationFactor: 2 Configs:
Topic: demo2 Partition: 0 Leader: 4 Replicas: 4,2 Isr: 4,2
Topic: demo2 Partition: 1 Leader: 2 Replicas: 2,3 Isr: 2,3- 创建副本存储计划(所有副本都指定存储在broker2、broker3中)。
sh
[jack@hadoop105 kafka-3.6.1]$ vi change-replication-factor-demo.json
[jack@hadoop105 kafka-3.6.1]$ cat change-replication-factor-demo.json
{
"version":1,
"partitions":[
{"topic":"demo2","partition":0,"replicas":[2,3]},
{"topic":"demo2","partition":1,"replicas":[2,3]}
]
}- 执行副本存储计划
sh
[jack@hadoop105 kafka-3.6.1]$ ./bin/kafka-reassign-partitions.sh --bootstrap-server hadoop106:9092 --reassignment-json-file change-replication-factor-demo.json --execute
Current partition replica assignment
{"version":1,"partitions":[{"topic":"demo2","partition":0,"replicas":[4,2],"log_dirs":["any","any"]},{"topic":"demo2","partition":1,"replicas":[2,3],"log_dirs":["any","any"]}]}
Save this to use as the --reassignment-json-file option during rollback
Successfully started partition reassignments for demo2-0,demo2-1- 验证副本存储计划
sh
[jack@hadoop105 kafka-3.6.1]$ ./bin/kafka-reassign-partitions.sh --bootstrap-server hadoop106:9092 --reassignment-json-file change-replication-factor-demo.json --
verify
Status of partition reassignment:
Reassignment of partition demo2-0 is completed.
Reassignment of partition demo2-1 is completed.
[jack@hadoop105 kafka-3.6.1]$ ./bin/kafka-topics.sh --bootstrap-server 192.168.101.106:9092 --describe --topic demo2
Topic: demo2 TopicId: 8z3pHJvxRDi5AdiYSy7GIw PartitionCount: 2 ReplicationFactor: 2 Configs:
Topic: demo2 Partition: 0 Leader: 2 Replicas: 2,3 Isr: 2,3
Topic: demo2 Partition: 1 Leader: 2 Replicas: 2,3 Isr: 2,36. 负载平衡
正常情况下,Kafka本身会自动把Leader Partition均匀分散在各个机器上,来保证每台机器的读写吞吐量都是均匀的。但是如果某些broker宕机,会导致Leader Partition过于集中在其他少部分几台broker上,这会导致少数几台broker的读写请求压力过高,其他宕机的broker重启之后都是follower partition,读写请求很低,造成集群负载不均衡。
6.1 自动平衡触发条件
- auto.leader.rebalance.enable,默认是true。开启自动Leader Partition平衡
- leader.imbalance.per.broker.percentage,默认是10%。每个broker允许的不平衡的leader的比率。如果每个broker超过了这个值,控制器会触发leader的平衡。
- leader.imbalance.check.interval.seconds,默认值300秒。检查leader负载是否平衡的间隔时间。
假设集群有一个主题如下图所示: 针对Broker0节点,分区2的AR优先副本是0节点,但是0节点却不是Leader节点,所以不平衡数加1,AR副本总数是4, 所以broker0节点不平衡率为1/4>10%,需要再平衡。Broker2、Broker3节点和Broker0不平衡率一样,需要再平衡。Broker1的不平衡数为0,不需要再平衡。
针对Broker0节点,分区2的AR优先副本是0节点,但是0节点却不是Leader节点,所以不平衡数加1,AR副本总数是4, 所以broker0节点不平衡率为1/4>10%,需要再平衡。Broker2、Broker3节点和Broker0不平衡率一样,需要再平衡。Broker1的不平衡数为0,不需要再平衡。
提示
生产环境中,leader 重选举的代价比较大,可能会带来性能影响,建议设置为false关闭。
7. 增加副本因子
在生产环境当中,由于某个主题的重要等级需要提升,我们考虑增加副本。副本数的增加需要先制定计划,然后根据计划执行。
7.1 创建副本存储计划(所有副本都指定存储在 broker0、broker1、broker2 中)。
sh
[jack@hadoop105 kafka-3.6.1]$ vim increase-replication-factor.json输入如下内容:
json
{"version":1,"partitions":[{"topic":"four","partition":0,"replica
s":[0,1,2]},{"topic":"four","partition":1,"replicas":[0,1,2]},{"t
opic":"four","partition":2,"replicas":[0,1,2]}]}7.2 执行副本存储计划
sh
[jack@hadoop105 kafka-3.6.1]$ bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --reassignment-json-file
increase-replication-factor.json --execute