Kafka消费者工作流程
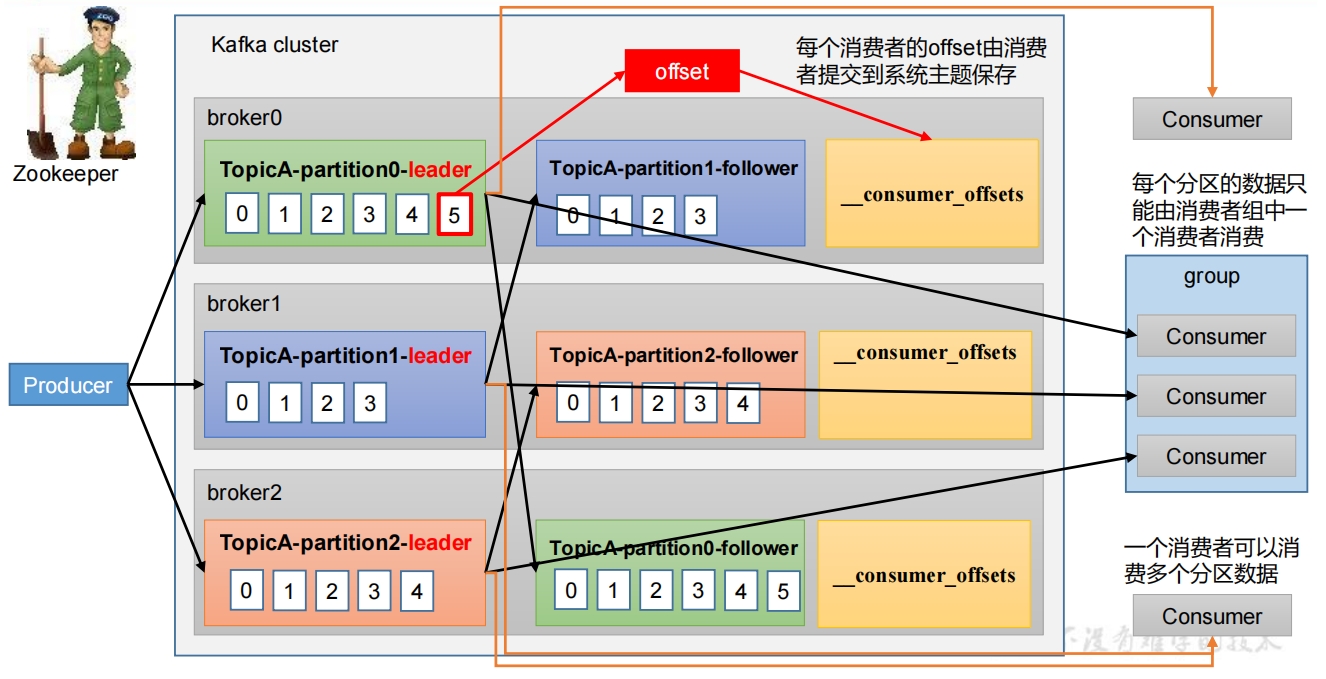
1. 消费者消费消息流程图
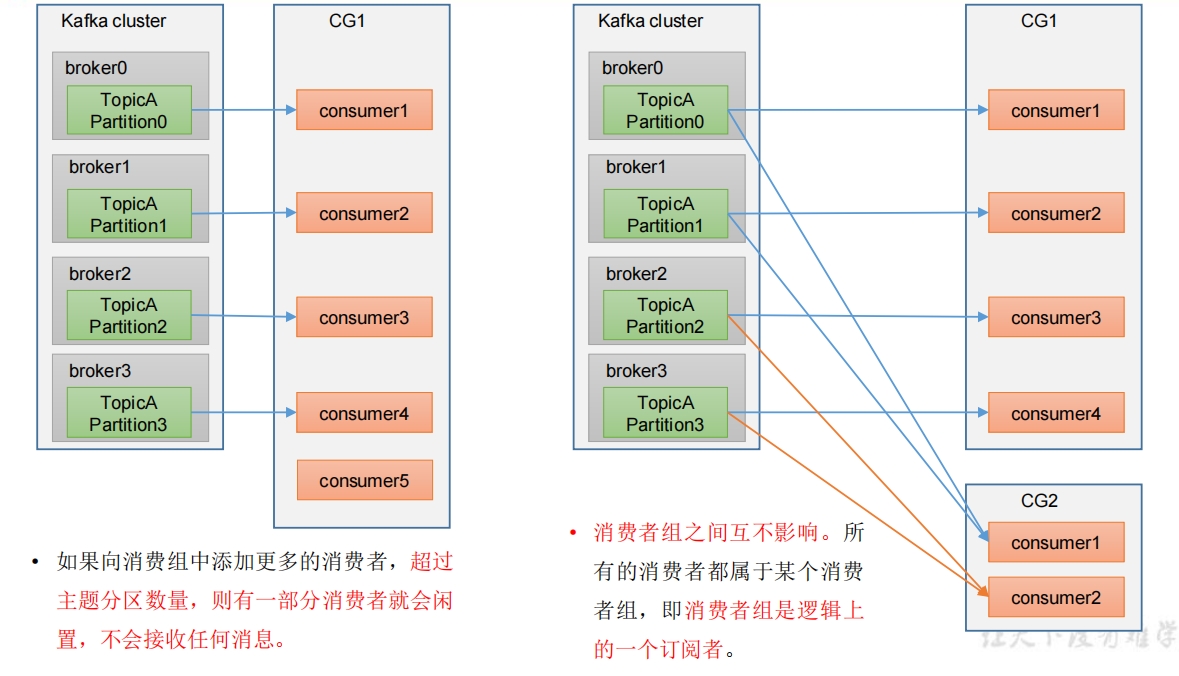
2. 消费者组原理
Consumer Group(CG):消费者组,由多个consumer组成。形成一个消费者组的条件,是所有消费者的groupid相同。
- 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费。
- 消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
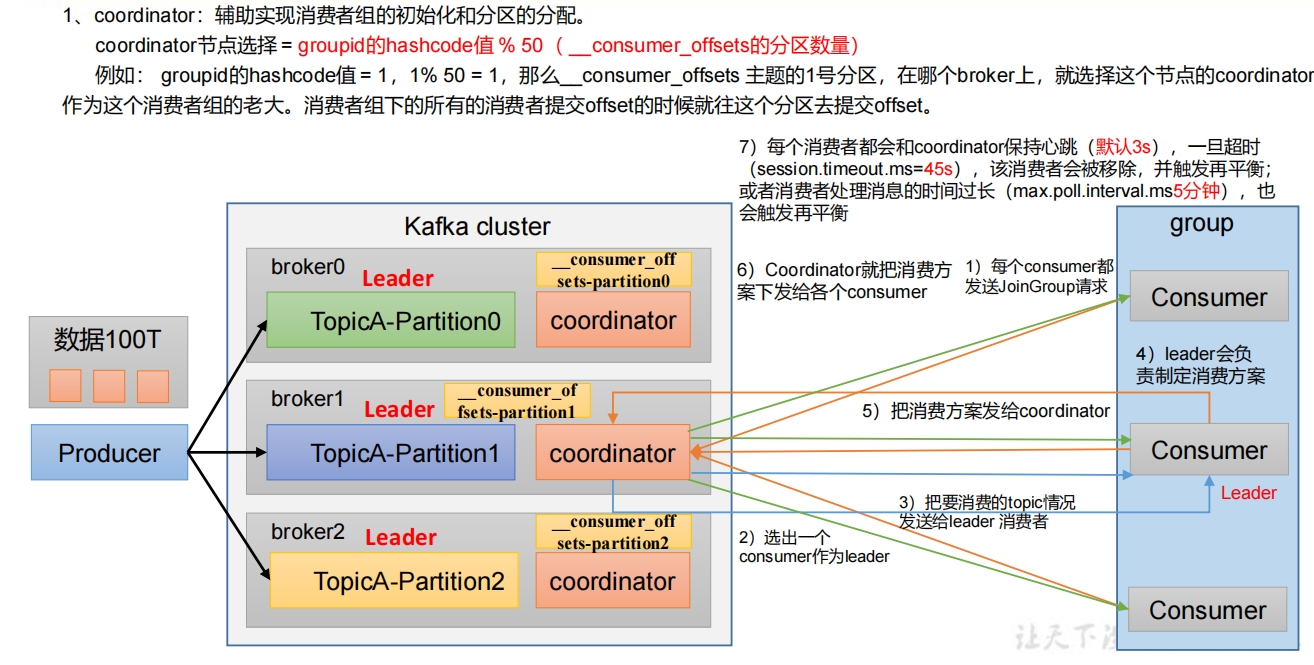
3. 消费者组初始化流程
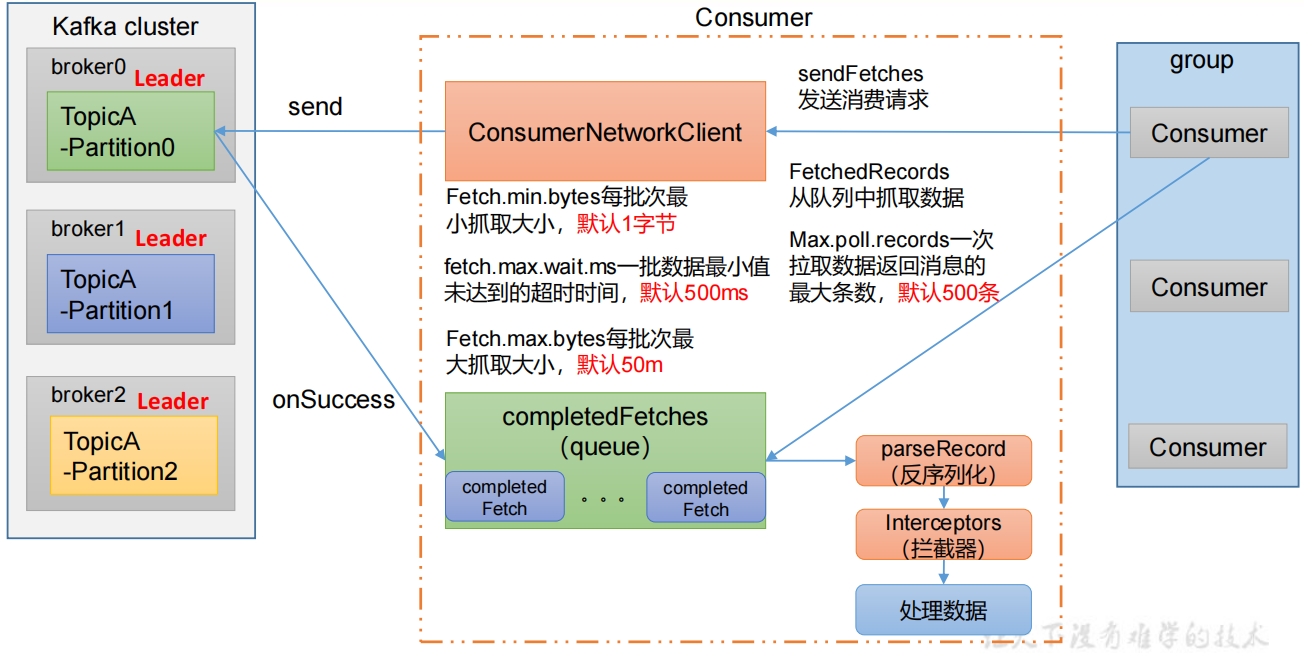
4. 消费者组详细消费流程
5. 消费者重要参数
| 参数 | 描述 |
|---|---|
| --bootstrap-server ip:port | 向Kafka集群建立初始连接用到的host/port列表。 |
| key.deserializer 和value.deserializer | 指定接收消息的key和value的反序列化类型。一定要写全类名。 |
| group.id | 标记消费者所属的消费者组。 |
| enable.auto.commit | 默认值为true,消费者会自动周期性地向服务器提交偏移量。 |
| auto.commit.interval.ms | 如果设置了enable.auto.commit的值为true, 则该值定义了消费者偏移量向Kafka提交的频率,默认5s。 |
| auto.offset.reset | 当Kafka中没有初始偏移量或当前偏移量在服务器中不存在,(比如数据被删除了),该如何处理? earliest:自动重置偏移量到最早的偏移量。 latest:默认,自动重置偏移量为最新的偏移量。 none:如果消费组原来的(previous)偏移量不存在,则向消费者抛异常。 anything:向消费者抛异常。 |
| key.deserializer和value.deserializer | 指定接收消息的key和value的反序列化类型。一定要写全类名。 |
| offsets.topic.num.partitions | __consumer_offsets的分区数,默认是50个分区。 |
| heartbeat.interval.ms | Kafka消费者和coordinator之间的心跳时间,默认3s。 该条目的值必须小于session.timeout.ms ,也不应该高于session.timeout.ms的1/3。 |
| session.timeout.ms | Kafka消费者和coordinator之间连接超时时间,默认45s。 超过该值,该消费者被移除,消费者组执行再平衡。 |
| max.poll.interval.ms | 消费者处理消息的最大时长,默认是5分钟。超过该值, 该消费者被移除,消费者组执行再平衡。 |
| fetch.min.bytes | 默认1个字节。消费者获取服务器端一批消息最小的字节数。 |
| fetch.max.wait.ms | 默认500ms。如果没有从服务器端获取到一批数据的最小字节数。 该时间到,仍然会返回数据。 |
| fetch.max.bytes | 默认Default: 52428800(50 m)。消费者获取服务器端一批消息最大的字节数。 如果服务器端一批次的数据大于该值(50m)仍然可以拉取回来这批数据, 因此这不是一个绝对最大值。 一批次的大小受 message.max.bytes或者max.message.bytes影响。 |
| max.poll.records | 一次poll拉取数据返回消息的最大条数,默认是500条。 |