Kafka文件存储机制
1. Topic数据的存储机制
Topic是逻辑上的概念,而Partition是物理上的概念,每个Partition对应于一个log文件,该log文件中存储的就是Producer生产的数据。Producer生产的数据会被不断追加到该log文件末端,为防止log文件过大导致数据定位效率低下,Kafka采取了分片和索引机制,将每个Partition分为多个segment。每个segment包括:".index"文件、".log"文件和.timeindex等文件。这些文件位于一个文件夹下,该文件夹的命名规则为:topic名称+分区序号,例如:first-0。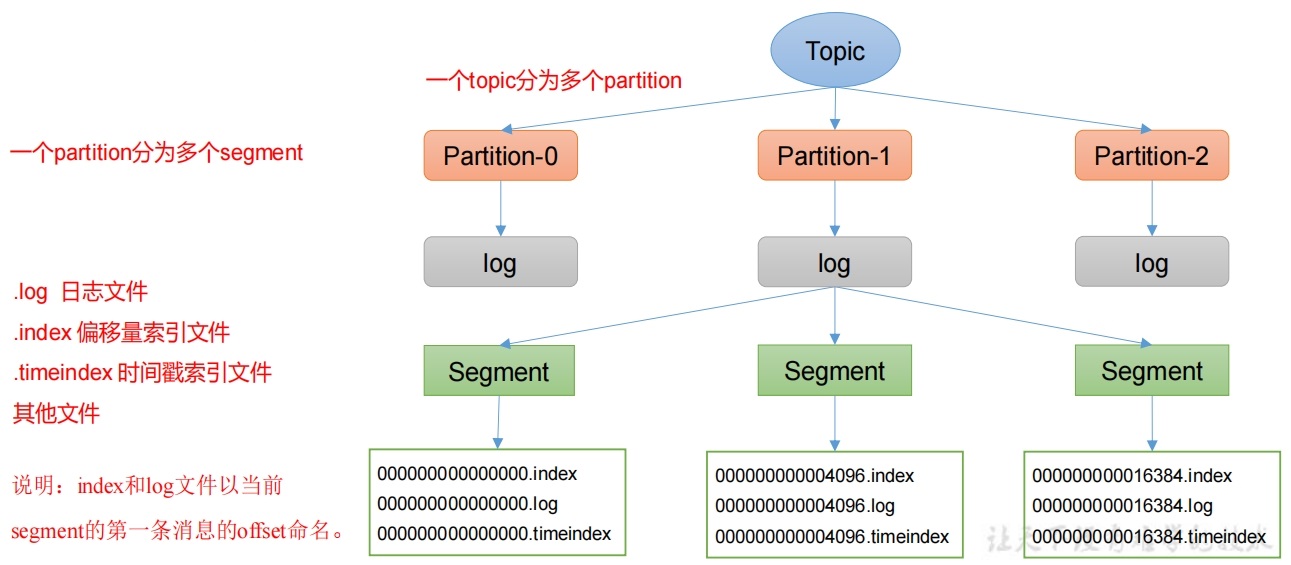
2. 查看Topic存储文件信息
2.1 查找hadoop主题文件
[jack@hadoop105 kafka-3.6.1./bin/kafka-topics.sh --bootstrap-server 192.168.101.106:9092 --describe --topic hadoop
Topic: hadoop TopicId: Rfd7moH4QOSMaDDFVi8Ofg PartitionCount: 1 ReplicationFactor: 1 Configs:
Topic: hadoop Partition: 0 Leader: 4 Replicas: 4 Isr: 4
## 可以看到Topic为hadoop的消息文件都存放在Broker4上面,也就是hadopp101。
[jack@hadoop101 data]$ ll
总用量 20
-rw-r--r--. 1 jack wheel 4 3月 17 21:36 cleaner-offset-checkpoint
drwxr-xr-x. 2 jack wheel 167 3月 17 22:45 hadoop-0
-rw-r--r--. 1 jack wheel 4 3月 17 22:51 log-start-offset-checkpoint
-rw-r--r--. 1 jack wheel 88 3月 17 20:25 meta.properties
-rw-r--r--. 1 jack wheel 15 3月 17 22:51 recovery-point-offset-checkpoint
-rw-r--r--. 1 jack wheel 15 3月 17 22:52 replication-offset-checkpoint
[jack@hadoop101 data]$ cd hadoop-0/
[jack@hadoop101 hadoop-0]$ ll
总用量 12
-rw-r--r--. 1 jack wheel 10485760 3月 17 22:45 00000000000000000000.index
-rw-r--r--. 1 jack wheel 378 3月 17 22:51 00000000000000000000.log
-rw-r--r--. 1 jack wheel 10485756 3月 17 22:45 00000000000000000000.timeindex
-rw-r--r--. 1 jack wheel 8 3月 17 22:45 leader-epoch-checkpoint
-rw-r--r--. 1 jack wheel 43 3月 17 22:45 partition.metadata2.2 查看相关主题文件
- 查看topic为hadoop的log日志,发现是乱码, 原因是底层Kafka用了序列化技术。
[jack@hadoop101 hadoop-0]$ cat 00000000000000000000.log
=LL忖
hello>´p՞LL忁
ni hao<뎄L䌞L.what>«ț©L䕥L䕥
hadpppIJ9ɷ."11111111111111111- 通过工具查看index和log信息。
[jack@hadoop101 hadoop-0]$ /opt/module/kafka-3.6.1/bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files ./00000000000000000000.index
Dumping ./00000000000000000000.index
offset: 0 position: 0
[jack@hadoop101 hadoop-0]$ ls
00000000000000000000.index 00000000000000000000.timeindex partition.metadata
00000000000000000000.log leader-epoch-checkpoint
## 需要往hadoop主题里面发送4kb的消息,才会在index文件中添加一条索引,目前不足4kb,因为index文件没有内容
[jack@hadoop101 hadoop-0]$ cat 00000000000000000000.index
[jack@hadoop101 hadoop-0]$ /opt/module/kafka-3.6.1/bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files ./00000000000000000000.log
Dumping ./00000000000000000000.log
Log starting offset: 0
baseOffset: 0 lastOffset: 0 count: 1 baseSequence: 0 lastSequence: 0 producerId: 1000 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 0 CreateTime: 1710686736181 size: 73 magic: 2 compresscodec: none crc: 2166165140 isvalid: true
baseOffset: 1 lastOffset: 1 count: 1 baseSequence: 1 lastSequence: 1 producerId: 1000 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 73 CreateTime: 1710686749772 size: 74 magic: 2 compresscodec: none crc: 3027293982 isvalid: true
baseOffset: 2 lastOffset: 2 count: 1 baseSequence: 0 lastSequence: 0 producerId: 1 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 147 CreateTime: 1710687079390 size: 72 magic: 2 compresscodec: none crc: 2582351492 isvalid: true
baseOffset: 3 lastOffset: 3 count: 1 baseSequence: 1 lastSequence: 1 producerId: 1 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 219 CreateTime: 1710687082085 size: 74 magic: 2 compresscodec: none crc: 2882100137 isvalid: true
baseOffset: 4 lastOffset: 4 count: 1 baseSequence: 2 lastSequence: 2 producerId: 1 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 293 CreateTime: 1710687088767 size: 85 magic: 2 compresscodec: none crc: 1245300983 isvalid: true3. index文件和log文件详解
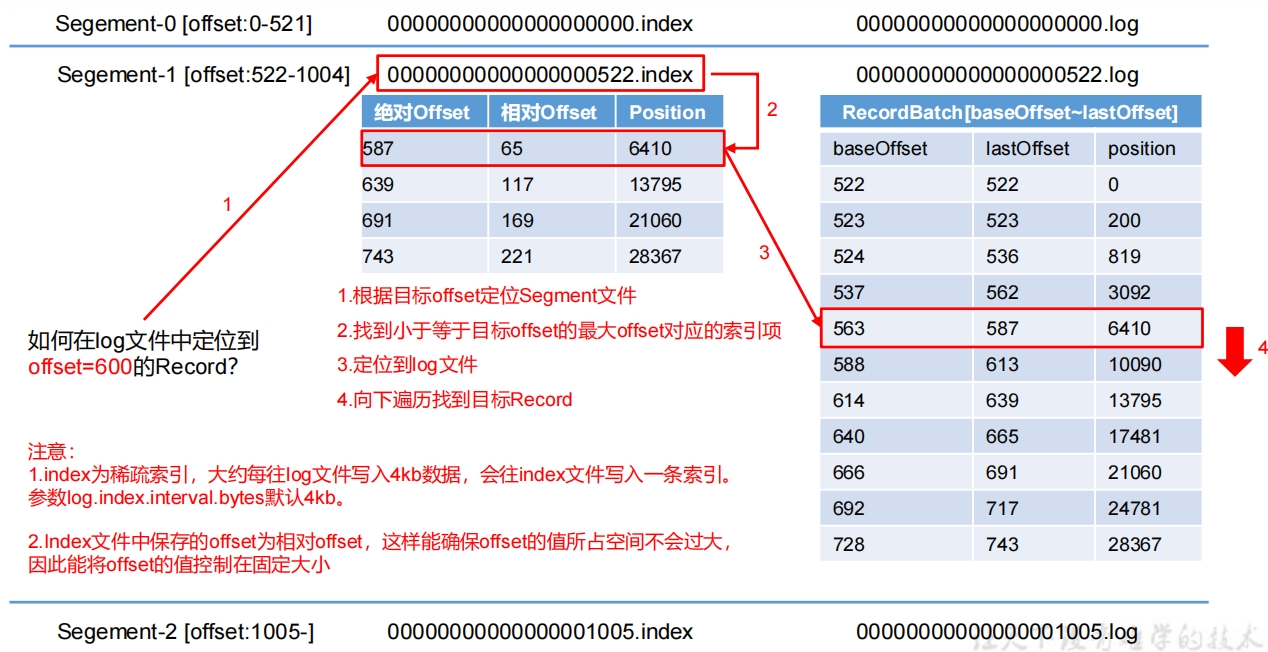 日志存储参数配置说明:
日志存储参数配置说明:
| 参数 | 描述 |
|---|---|
| log.segment.bytes | Kafka中log日志是分成一块块存储的,此配置是指log日志划分成块的大小,默认值1G。 |
| log.index.interval.bytes | 默认4kb,Kafka里面每当写入了4kb大小的日志(.log),然后就往index文件里面记录一个索引。稀疏索引。 |
4. 数据文件清理策略
将过期数据删除,Kafka提供两种删除触发条件:
- 基于时间:默认打开。以segment文件中所有记录中的最大时间戳作为该文件时间戳。
- 基于大小:默认关闭。超过设置的所有日志总大小,删除最早的segment文件。配置项log.retention.bytes可以指定总文件大小,默认等于-1,表示无穷大。
日志一旦触发删除条件,Kafka会进行日志清理,清理也提供了delete和compact两种方式:
- 直接删除文件,默认打开,配置项log.cleanup.policy=delete。
- 数据日志压缩,配置项log.cleanup.policy=compact表示所有数据启用压缩策略。
时间方式清理需要关注log.segment.bytes大小
log.segment.bytes设置指的是单个segment文件大小,如果log.segment.bytes设置的太大,就使得单个segment文件大小累积很长时间,之后Kafka才会写入下一个segment文件,基于时间的清理方式在这期间会持续很长时间都在同一个segment文件中检测,而此时segment文件由于持续写入就导致最大时间戳肯定是当前时间戳,因此不会触发文件清理。
4.1 基于时间检测数据
Kafka 中默认的日志保存时间为7天,可以通过调整如下参数修改保存时间:
- log.retention.hours,最低优先级小时,默认7天。
- log.retention.minutes,分钟。
- log.retention.ms,最高优先级毫秒。
- log.retention.check.interval.ms,负责设置检查周期,默认5分钟。
4.2 基于大小检测数据
该参数作用于每个分区,而非整个主题。每个分区的所有日志段文件(.log、.index等)的总大小超过log.retention.bytes时触发。
4.3 delete方式日志清理
将过期数据删除,配置项log.cleanup.policy=delete所有数据启用删除策略,Kafka默认使用删除策略。
4.4 compact方式日志清理
对于相同key的不同value值,只保留最后一个版本。log.cleanup.policy=compact所有数据启用压缩策略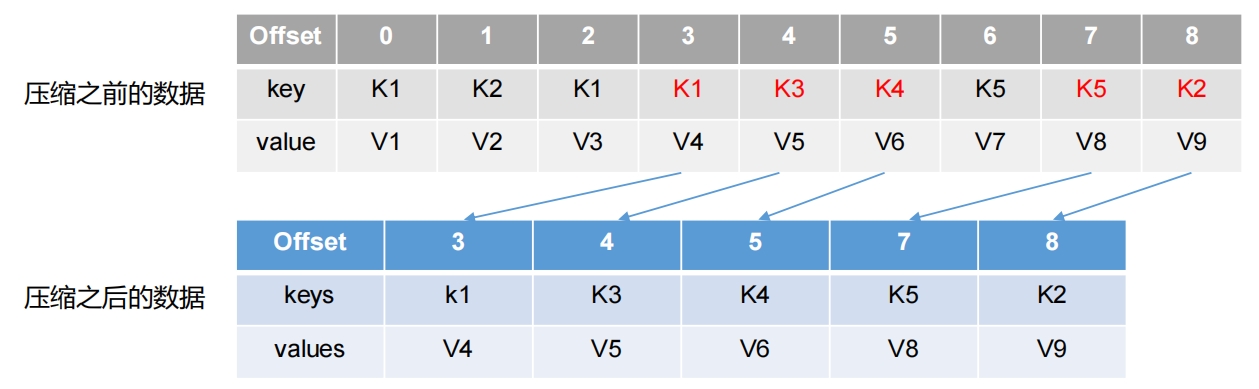 压缩后的offset可能是不连续的,比如上图中没有6,当从这些offset消费消息时,将会拿到比这个offset大的offset对应的消息,实际上会拿到offset为7的消息,并从这个位置开始消费。这种策略只适合特殊场景,比如消息的key是用户ID,value是用户的资料,通过这种压缩策略,整个消息集里就保存了所有用户最新的资料。Kafka内部的主题_consumer_offsets就是采用这种策略保存每个消费者最新的不同分区的offset
压缩后的offset可能是不连续的,比如上图中没有6,当从这些offset消费消息时,将会拿到比这个offset大的offset对应的消息,实际上会拿到offset为7的消息,并从这个位置开始消费。这种策略只适合特殊场景,比如消息的key是用户ID,value是用户的资料,通过这种压缩策略,整个消息集里就保存了所有用户最新的资料。Kafka内部的主题_consumer_offsets就是采用这种策略保存每个消费者最新的不同分区的offset
5. Kafka读写数据高效总结
- Kafka本身是分布式集群,可以采用分区技术,并行度高
- 读数据采用稀疏索引,可以快速定位要消费的数据
- 顺序写磁盘
Kafka的Producer生产数据,要写入到log文件中,写的过程是一直追加到文件末端,为顺序写。官网有数据表明,同样的磁盘,顺序写能到600M/s,而随机写只有100K/s。这与磁盘的机械机构有关,顺序写之所以快,是因为其省去了大量磁头寻址的时间。 - 页缓存+零拷贝技术
零拷贝:Kafka的数据加工处理操作交由Kafka生产者和Kafka消费者处理。Kafka Broker应用层不关心存储的数据,所以就不用走应用层,传输效率高。
PageCache页缓存:Kafka重度依赖底层操作系统提供的PageCache功能。当上层有写操作时,操作系统只是将数据写入PageCache。当读操作发生时,先从PageCache中查找,如果找不到,再去磁盘中读取。实际上是把PageCache尽可能多的空闲内存当做了磁盘缓存来使用。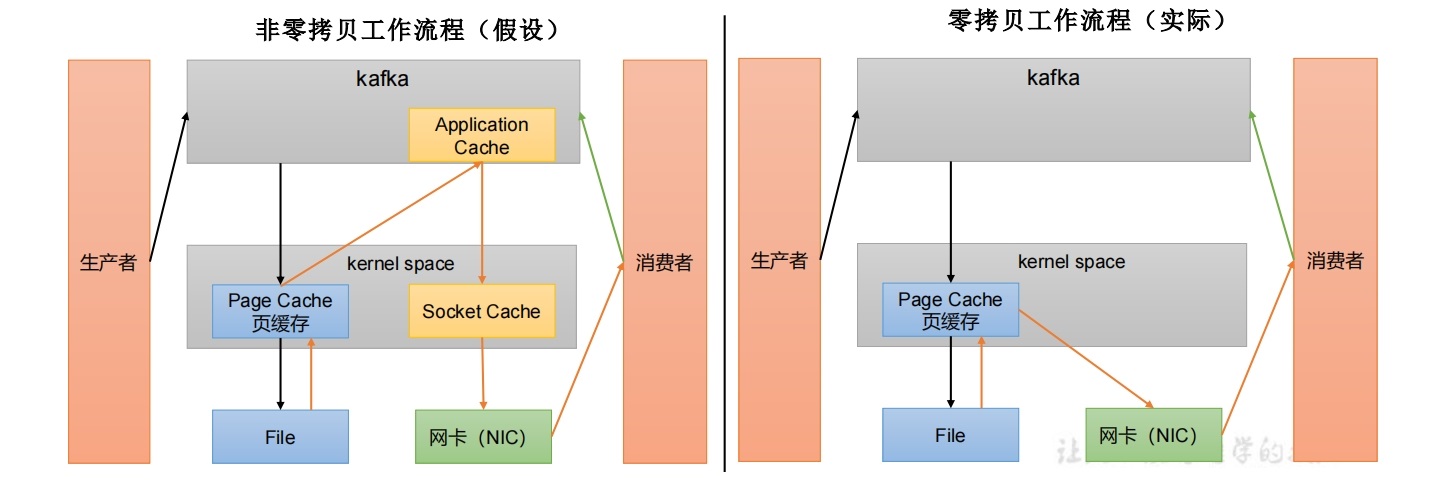
| 参数 | 描述 |
|---|---|
| log.flush.interval.messages | 强制页缓存刷写到磁盘的条数,默认是long的最大值,9223372036854775807。一般不建议修改,交给系统自己管理。 |
| log.flush.interval.ms | 每隔多久,刷数据到磁盘,默认是null。一般不建议修改,交给系统自己管理。 |