Kafka-Kraft模式
1. Kafka-Kraft架构
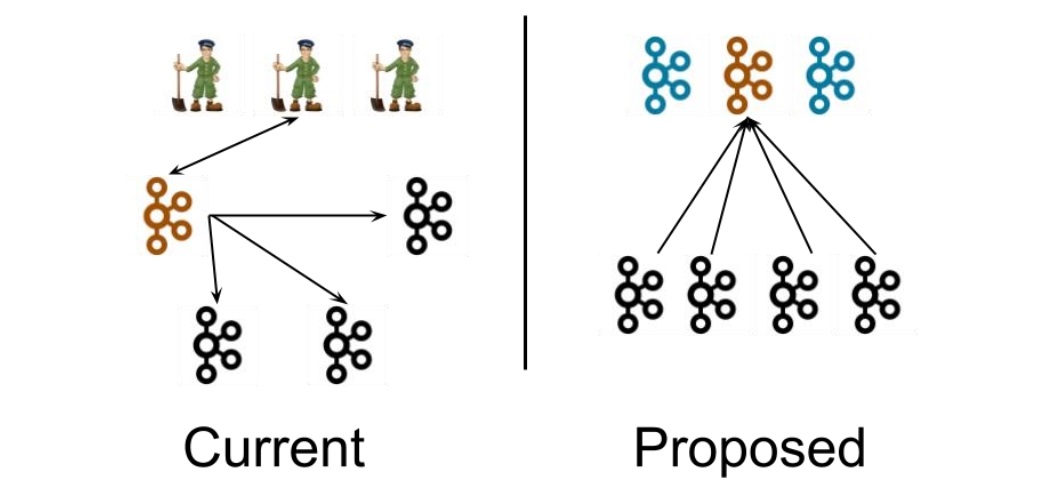 如图所示,左图为Kafka现有架构,元数据在Zookeeper中,运行时动态选举Controller,由Controller进行Kafka集群管理。集群使用KRaft算法选择一个领导者Leader,由Leader负责进行处理外部请求元数据。右图为kraft(Kafka Raft)模式架构,自Kafka在2.8版本加入该特性,Kafka3.3.1版本标记为生产稳定。图中不再依赖Zookeeper集群,而是用三台Controller节点代替Zookeeper,元数据保存在Controller中,由Controller直接进行Kafka集群管理。
如图所示,左图为Kafka现有架构,元数据在Zookeeper中,运行时动态选举Controller,由Controller进行Kafka集群管理。集群使用KRaft算法选择一个领导者Leader,由Leader负责进行处理外部请求元数据。右图为kraft(Kafka Raft)模式架构,自Kafka在2.8版本加入该特性,Kafka3.3.1版本标记为生产稳定。图中不再依赖Zookeeper集群,而是用三台Controller节点代替Zookeeper,元数据保存在Controller中,由Controller直接进行Kafka集群管理。
这样做的好处有以下几个:
- Kafka不再依赖外部框架,而是能够独立运行
- Controller管理集群时,不再需要从Zookeeper中先读取数据,集群性能上升
- 由于不依赖Zookeeper,集群扩展时不再受到Zookeeper读写能力限制
- Controller不再动态选举,而是由配置文件规定。这样我们可以有针对性的加强Controller节点的配置,而不是像以前一样对随机Controller节点的高负载束手无策。
在Kafka3.5之后版本,使用Zookeeper标记为过时。
2. Kafka-Kraft单机部署
2.1 上传文件
上传kafka_2.12-3.6.2.tgz到/opt/software目录下,解压到/opt/module目录:
sh
tar -xvf kafka_2.12-3.6.2.tgz -C ../module/2.2 修改配置
修改/opt/module/kafka-3.6.2/config/kraft/server.properties
sh
[jack@hadoop102 kraft]$ vim server.properties
## 修改如下内容
log.dirs=/opt/module/kafka-3.6.2/data/kraft-combined-logs
advertised.listeners=PLAINTEXT://192.168.101.102:90922.3 格式化存储目录
sh
[jack@hadoop102 kafka-3.6.2]$ bin/kafka-storage.sh random-uuid
[jack@hadoop102 kafka-3.6.2]$ bin/kafka-storage.sh format -t _VlAXKWlRym1XvWQA_Tw3A -c /opt/module/kafka-3.6.2/config/kraft/server.properties
Formatting /opt/module/kafka-3.6.2/data/kraft-combined-logs with metadata.version 3.6-IV2.2.4 配置kafka开机自启动
添加/etc/systemd/system/kafka.service文件:
sh
[jack@hadoop102 kafka-3.6.2]$ sudo vim /etc/systemd/system/kafka.service
[Unit]
Description=kafka
Requires=network.target
After=network.target
[Service]
Environment="JAVA_HOME=/opt/module/jdk1.8.0_391"
ExecStart=/opt/module/kafka-3.6.2/bin/kafka-server-start.sh /opt/module/kafka-3.6.2/config/kraft/server.properties
ExecStop=/opt/module/kafka-3.6.2/bin/kafka-server-stop.sh
[Install]
WantedBy=multi-user.target添加kafka开机自启动:
sh
sudo systemctl daemon-reload
systemctl enable kafka
systemctl start kafka
systemctl status kafka3. Kafka-Kraft集群部署
- 修改/opt/module/kafka-3.6.1/config/kraft/server.properties配置文件
sh
[jack@hadoop105 kraft]$ vi server.properties
#kafka 的角色(controller相当于主机、broker节点相当于从机,主机类似zk功能)
process.roles=broker, controller
#节点 ID
node.id=2
#全 Controller 列表
controller.quorum.voters=1@hadoop105:9093,2@hadoop106:9093,3@hadoop107:9093
#broker 对外暴露的地址
advertised.Listeners=PLAINTEXT://hadoop105:9092- 分发配置
sh
[jack@hadoop105 kraft]$ scp server.properties jack@hadoop106:/opt/module/kafka-3.6.1/config/kraft/
server.properties 100% 6338 1.6MB/s 00:00
[jack@hadoop105 kraft]$ scp server.properties jack@hadoop107:/opt/module/kafka-3.6.1/config/kraft/
server.properties分发完毕后需要在hadoop106和hadoop107上对node.id相应改变 ,值需要和controller.quorum.voters对应。修改相应的advertised.Listeners地址。
3. 初始化集群数据目录
sh
# 生成存储目录唯一 ID
[jack@hadoop105 kafka-3.6.1]$ bin/kafka-storage.sh random-uuid
8944kaw8QzGJerNcc6gfJg
# 用该ID格式化Kafka存储目录(三台节点)
[jack@hadoop105 kafka-3.6.1]$ bin/kafka-storage.sh format -t 8944kaw8QzGJerNcc6gfJg -c /opt/module/kafka-3.6.1/config/kraft/server.properties
Formatting /opt/module/kafka-3.6.1/data/ with metadata.version 3.6-IV2.
[jack@hadoop106 kafka-3.6.1]$ bin/kafka-storage.sh format -t 8944kaw8QzGJerNcc6gfJg -c /opt/module/kafka-3.6.1/config/kraft/server.properties
Formatting /opt/module/kafka-3.6.1/data/ with metadata.version 3.6-IV2.
[jack@hadoop107 kafka-3.6.1]$ bin/kafka-storage.sh format -t 8944kaw8QzGJerNcc6gfJg -c /opt/module/kafka-3.6.1/config/kraft/server.properties
Formatting /opt/module/kafka-3.6.1/data/ with metadata.version 3.6-IV2.- 启动Kafka集群
sh
[jack@hadoop105 kafka-3.6.1]$ bin/kafka-server-start.sh -daemon config/kraft/server.properties
[jack@hadoop105 kafka-3.6.1]$ jps
16499 KafkaEagle
57797 QuorumPeerMain
52728 Kafka
52831 Jps
[jack@hadoop106 kafka-3.6.1]$ bin/kafka-server-start.sh -daemon config/kraft/server.properties
[jack@hadoop106 kafka-3.6.1]$ jps
17112 Kafka
17229 Jps
[jack@hadoop107 kafka-3.6.1]$ bin/kafka-server-start.sh -daemon config/kraft/server.properties
[jack@hadoop107 kafka-3.6.1]$ jps
22088 Kafka
22217 Jps4. Kafka-Kraft集群启停脚本
在/home/jack/bin目录下创建文件kafka-kraft脚本文件
sh
[jack@hadoop105 bin]$ vi kafka-kraft脚本如下:
sh
#! /bin/bash
case $1 in
"start"){
for i in hadoop105 hadoop106 hadoop107
do
echo " --------启动 $i kafka-------"
ssh $i "/opt/module/kafka-3.6.1/bin/kafka-server-start.sh -daemon /opt/module/kafka-3.6.1/config/kraft/server.properties"
done
};;
"stop"){
for i in hadoop105 hadoop106 hadoop107
do
echo " --------停止 $i Kafka-------"
ssh $i "/opt/module/kafka-3.6.1/bin/kafka-server-stop.sh "
done
};;
esac- 添加执行权限
sh
[jack@hadoop105 bin]$ chmod +x kafka-kraft.sh- 启动集群命令
sh
[jack@hadoop105 bin]$ kafka-kraft start
--------启动 hadoop105 kafka-------
--------启动 hadoop106 kafka-------
--------启动 hadoop107 kafka-------- 停止集群命令
sh
[jack@hadoop105 bin]$ kafka-kraft stop
--------停止 hadoop105 Kafka-------
--------停止 hadoop106 Kafka-------
--------停止 hadoop107 Kafka-------