Kafka消费者优化
1. 消费者事务
1.1 重复消费与漏消费
重复消费:已经消费了数据,但是Offset没提交。
漏消费:先提交Offset后消费,有可能会造成数据的漏消费。 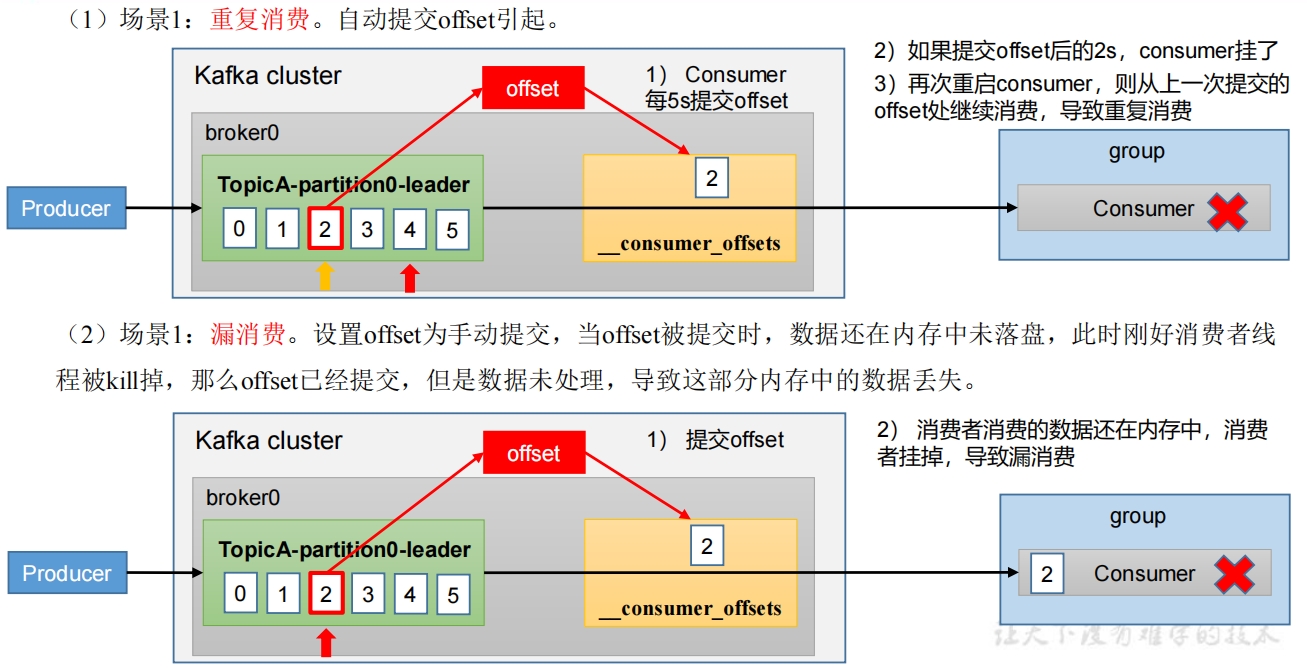
1.2 解决方案之消费者事务
先提交Offset还是先消费数据都是问题,因为分别会造成漏消费和重复消费问题,如果想完成Consumer端的精准一次性消费,那么需要Kafka消费端将消费过程和提交Offset过程做原子绑定。仅仅靠双方(提交Offset、消费数据)不能解决问题,需要事务来解决,要么全部失败,要么全部成功。此时我们需要将Kafka的offset保存到支持事务的自定义介质(比如MySQL)。 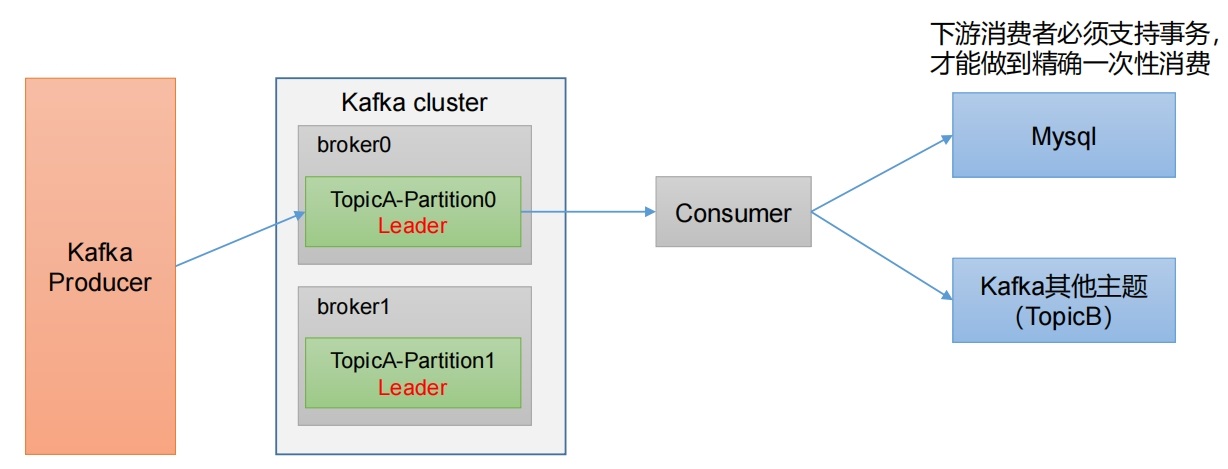 问题与限制:
问题与限制:
- 数据必须都要放在一个关系型数据库中,无法使用其他功能强大的nosql数据库。
- 事务本身性能不好。
- 如果保存的数据量较大一个数据库节点不够,多个节点的话,还要考虑分布式事务的问题。分布式事务会带来管理的复杂性,一般企业不选择使用,有的企业会把分布式事务变成本地事务,例如把Executor上的数据通过rdd.collect算子提取到Driver端,由Driver 端统一写入数据库,这样会将分布式事务变成本地事务的单线程操作,降低了写入的吞吐量。
使用场景:数据足够少(通常经过聚合后的数据量都比较小,明细数据一般数据量都比较大),并且支持事务的数据库。
java
static Logger logger = LoggerFactory.getLogger(Test02.class);
public static void main(String[] args) {
String topic = "ods_qjk_data";
String groupId = "default_group";
// 获取 Kafka 消费者实例
try (KafkaConsumer<String, byte[]> kafkaConsumer = KafkaUtil.getConsumerInstance(groupId)) {
Set<TopicPartition> assignment = new HashSet<>();
// 订阅主题
kafkaConsumer.subscribe(List.of(topic));
/**
* 主动联系Kafka,获取分配给自己的分区信息
*/
while (assignment.isEmpty()){
// poll方法的主要目的并非拉取消息,而是触发Kafka进行分区分配操作。
// 这里代码的确拿了一些Kafka消息,但是此时的消息是没有任何意义的,因为还没有指定offset
kafkaConsumer.poll(Duration.ofSeconds(1));
// 获取主题分区信息, 获取分区信息后退出while循环
assignment = kafkaConsumer.assignment();
}
RedissonClient redisClient = RedisUtil.initValidConnection();
RMap<Integer, Long> map = redisClient.<Integer, Long>getMap(topic+"-"+groupId);
// 遍历已分配分区信息,并设置每个分区的消费位置
for (TopicPartition topicPartition : assignment) {
Long lastOffset = map.get(topicPartition.partition());
if(lastOffset == null){
lastOffset = 0L;
}
// 指定offset从指定的位置开始消费
kafkaConsumer.seek(topicPartition, lastOffset);
}
while (true) {
// 真正拉取未消费的消息, 拉取消息超时时间为1秒,一秒内默认最多拿500条消息,默认最多50M大小
// Kafka客户端底层收到数据负责组装消息
ConsumerRecords<String, byte[]> records = kafkaConsumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, byte[]> record : records) {
RTransaction transaction = redisClient.createTransaction(TransactionOptions.defaults());
// 获取事务中的 RMap 对象
RMap<Integer, Long> rmap = transaction.<Integer, Long>getMap(topic+"-"+groupId);
// 获取消息的时间戳
long ts = record.timestamp();
int partition = record.partition();
long offset = record.offset();
try {
logger.debug("正在处理kafka消息:ts: {}, partition:{}, offset: {}", ts, partition, offset);
// TODO 业务逻辑
// 处理一条消息 记录一条最新offset
rmap.put(partition, offset);
// 提交事务
transaction.commit();
}catch (Exception e){
logger.error("处理kafka消息失败", e);
// 出现异常,回滚事务
transaction.rollback();
break;
}
}
}
}
}java
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.101.102:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, StickyAssignor.class.getName());
// 配置消费者组(组名任意起名)
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test999");
// 是否自动提交 offset
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false); // 默认就是true
// 提交 offset 的时间周期 1000ms,默认 5s
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 1000);// 设置1s
Set<TopicPartition> assignment = new HashSet<>();
// 创建消费者
try (KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties)) {
List<String> topics = Collections.singletonList("sparkTopic");
kafkaConsumer.subscribe(topics);
while (assignment.isEmpty()){
kafkaConsumer.poll(Duration.ofSeconds(1));
// 获取消费者分区分配信息(有了分区分配信息才能开始消费)
assignment = kafkaConsumer.assignment();
}
long offset = DBUtil.getMaxOffset("sparkTopic")
// 遍历所有分区,并指定offset从指定的位置开始消费
for (TopicPartition topicPartition : assignment) {
kafkaConsumer.seek(topicPartition, offset);
}
// 拉取数据打印
while (true) {
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(2));
for (ConsumerRecord<String, String> msg : consumerRecords) {
System.out.println("偏移量: " + msg.offset() + "\t分区:" + msg.partition() + "\t消息key: " + msg.key() + "\t消息内容: " + msg.value());
DbUtil.startTranstion();
// 数据表上新增一列offset, 记录消费位置
DBUtil.insertData(msg.value(), msg.offset());
// 提交 offset
kafkaConsumer.commitSync();
DbUtil.commit();
}
}
}
}java
1.3 解决方案之后置提交Offset+幂等方案
首先解决数据丢失问题,办法就是要等数据保存成功后再提交偏移量,所以就必须手工来控制偏移量的提交时机。保证了at least once(数据至少消费一次),把数据的保存做成幂等性保存,即同一批数据反复保存多次,数据不会翻倍,保存一次和保存一百次的效果是一样的。
使用场景:处理数据较多,或者数据保存在不支持事务的数据库上。
2. 消费者提高吞吐量
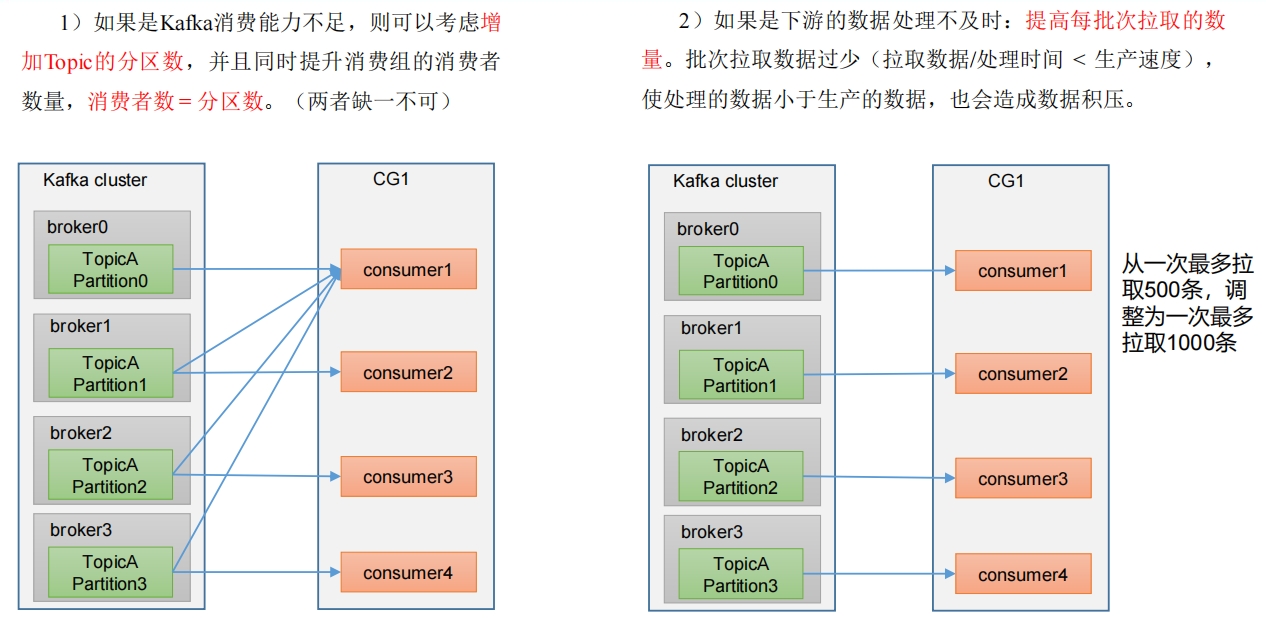
| 参数名称 | 描述 |
|---|---|
| fetch.max.bytes | 默认 Default: 52428800(50M)。 消费者获取服务器端一批消息最大的字节数。 如果服务器端一批次的数据大于该值(50M)仍然可以拉取回来这批数据, 因此这不是一个绝对最大值。 一批次的大小受 message.max.bytes 和max.message.bytes共同影响。 |
| max.poll.records | 一次 poll拉取数据返回消息的最大条数,默认是500条 |