Join算法
1. Simple nested_loop join
简称SNLP, 算法逻辑如下,基本上不会用到。
sh
For each row r in R do
For each row s in S do
If r and s satisfy the join condition
Then output the tuple <r,s>匹配如下图所示,扫描成本为O(Rn x Sn) 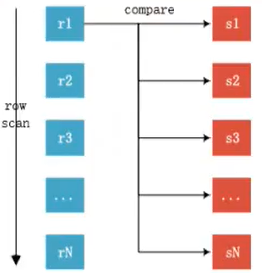
2. index nested_loop join
算法逻辑如下,
sh
For each row r in R do
lookup r in S index
if found s ==r
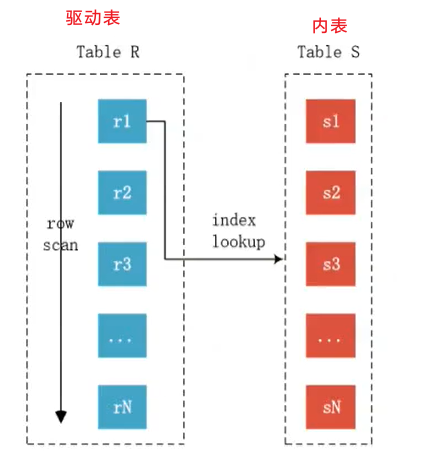
Then output the tuple <rs>扫描成本为O(Rn),优化器倾向于使用小表作为驱动表。
- 对于left join的话,左边的表就是驱动表,因为会保留左表所有数据。
- 对于inner join, 因为查询内表是通过索引查询的,所以关联的字段只要那张表建有索引,就会使用它作为内表。为了提高性能,需要将大表作为内表,需要在大表上面建立索引。
3. block nested_loop join
简称BNLP, 优化Simple nested_loop join算法,减少内部表的扫描次数,适用于没有索引或者用不到索引的场景:
sh
For each tuple rin R do
store used columns as p from R in join buffer
For each tuple s in S do
If p and s satisfy the join condition
Then output the tuple <p,s>可以看到相比Simple nested_loop join,其实只多了一个join buffer: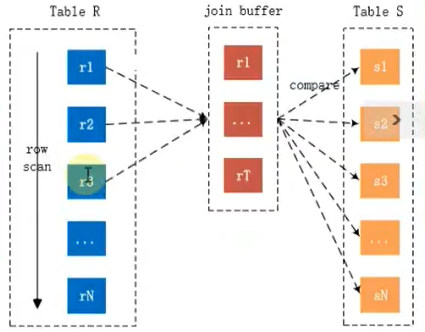 系统变量join_buffer_size决定了Join Buffer的大小, Join Buffer可被用于联接是ALL,index,range的类型, Join Buffer只存储需要进行查询操作的相关列数据,而不是整行的记录,但是join比较次数不变:
系统变量join_buffer_size决定了Join Buffer的大小, Join Buffer可被用于联接是ALL,index,range的类型, Join Buffer只存储需要进行查询操作的相关列数据,而不是整行的记录,但是join比较次数不变:
sh
## 默认大小为256k
mysql> show variables like '%join_buffer_size%';
+------------------+--------+
| Variable_name | Value |
+------------------+--------+
| join_buffer_size | 262144 |
+------------------+--------+
1 row in set, 1 warning (0.02 sec)4. Hash Join
4.1 原理
分为两个阶段:
- 构建阶段(Build):将小表(驱动表)的连接键构建哈希表。
- 探测阶段(Probe):扫描大表(被驱动表),通过哈希表快速匹配。
sql
-- MySQL 8默认开启
SET optimizer_switch = 'hash_join=on';仅适用于INNER JOIN、LEFT JOIN、RIGHT JOIN,不支持FULL OUTER JOIN。
4.2 适用场景:
两张表都很大,无法使用索引。 内存充足,能容纳哈希表。