SQL性能分析
1. SQL执行频率
通过show [session|global] status命令可以提供服务器状态信息。通过如下指令,可以查看当前数据库的INSERT、UPDATE、DELETE、SELECT的访问频次:
-- session 是查看当前会话 ;
-- global 是查询全局数据 ;
SHOW GLOBAL STATUS LIKE 'Com_______';执行结果: 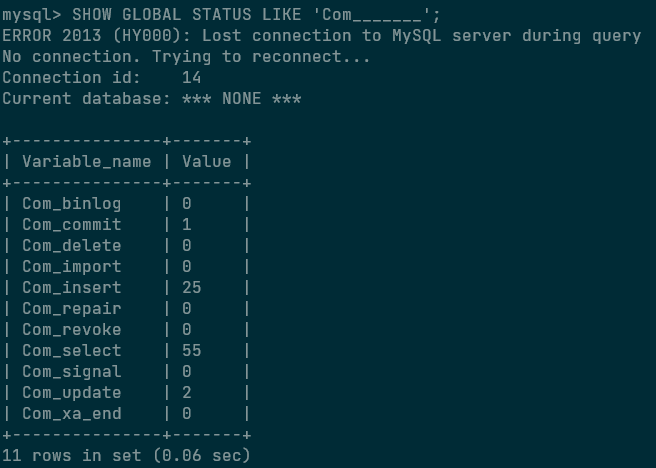
2. 慢查询日志
慢查询日志记录了所有执行时间超过指定参数(long_query_time,单位:秒,默认10秒)的所有SQL语句的日志。特别是针对线上生产上实际需要优化的sql可以通过慢查询日志进行优化。
2.1 配置慢查询日志
修改my.cnf文件:
## 开启慢查询
slow_querylog=1
## 日志保存文件
slow_query_log_file = slow.log
## 设置慢查询的阈值,比如为2秒,SQL语句执行时间超过2秒,就会视为慢查询
long_query_time =2
## 排除扫描行数极少,但因为其他原因导致很慢
min_examined_row_limit = 1000
## 记录未使用索引的查询
log-queries-not-using-indexes
## 限制每分钟记录到慢查询日志中的未使用索引查询的数量
## 当超过限制时,后续的同类查询将被忽略,直到下一分钟重新计数。
log_throttle_queries_not_using_indexes = 10
## 记录耗时较长的管理类语句
log-slow-admin-statements
## 将从库(Slave)上执行的慢查询 记录到慢查询日志中
log_slow_slave_statements2.2 下载慢日志
使用mysqldumpslow命令,用于分析和汇总慢查询日志, 使用这个工具可以快速找到执行时间最长、排序操作最多或锁定时间最长的查询。默认是分析全部sql。
## -s 指定排序方式:c:次数(默认) t:总时间
## -t N 只显示前N条结果
[root@hadoop104 bin]# mysqldumpslow -s t -t 10 /opt/module/mysql-8.0.39/logs/mysql-slow.log
Reading mysql slow query log from /opt/module/mysql-8.0.39/logs/mysql-slow.log
Count: 16 Time=212.09s (3393s) Lock=0.00s (0s) Rows=0.0 (0), root[root]@hadoop100
/* ApplicationName=DBeaver N.N.N - SQLEditor <Script-N.sql> */ INSERT INTO user_info(login_name, nick_name, passwd, name, phone_num, email, head_img, user_level, birthday, gender, create_time, operate_time, status)
SELECT login_name, nick_name, passwd, name, phone_num, email, head_img, user_level, birthday, gender, create_time, operate_time, status
FROM gmall_v4.user_info
Count: 24 Time=20.41s (489s) Lock=6.26s (150s) Rows=0.0 (0), root[root]@hadoop100
/* ApplicationName=DBeaver N.N.N - SQLEditor <Script-N.sql> */ DELETE from user_info WHERE id>N
Count: 1 Time=130.36s (130s) Lock=0.00s (0s) Rows=0.0 (0), root[root]@localhost
SELECT max(id) FROM user_info
Count: 1 Time=90.41s (90s) Lock=0.00s (0s) Rows=3737933.0 (3737933), root[root]@hadoop102
SELECT id,login_name,nick_name,passwd,name,phone_num,email,head_img,user_level,birthday,gender,create_time,operate_time FROM user_info
Count: 6 Time=8.00s (48s) Lock=0.00s (0s) Rows=100.0 (600), root[root]@2hosts
SELECT * FROM gmall_v4.user_info order by user_level desc limit N
Count: 1 Time=20.96s (20s) Lock=0.00s (0s) Rows=0.0 (0), root[root]@hadoop100
/* ApplicationName=DBeaver N.N.N - SQLEditor <Script-N.sql> */
DELETE from user_info WHERE id>N
Count: 1 Time=4.72s (4s) Lock=0.00s (0s) Rows=1.0 (1), root[root]@hadoop100
/* ApplicationName=DBeaver N.N.N - SQLEditor <Script-N.sql> */ SELECT date_format(create_time, 'S') , count(*) FROM user_info
GROUP BY date_format(create_time, 'S')
LIMIT N, N
Count: 1 Time=3.00s (3s) Lock=0.00s (0s) Rows=1.0 (1), root[root]@localhost
select sysdate(),sysdate(N), now(N),sleep(N)在拿到慢sql后,进行分析查看执行计划后,修复完毕后,需要将服务器上的重新记录慢日志,验证本次优化效果。
mv mysql-slow.log mysql-slow.log_20250626
## mysql会重新生成一个新文件mysql-slow.log
flush slow logs;3. sys库视图查慢sql
在MySQL8之后,提供sys数据库,里面有大量的视图,其中statement_analysis用于分析和监控SQL语句的执行情况。视图内部已经做好了排序,可以直接查询: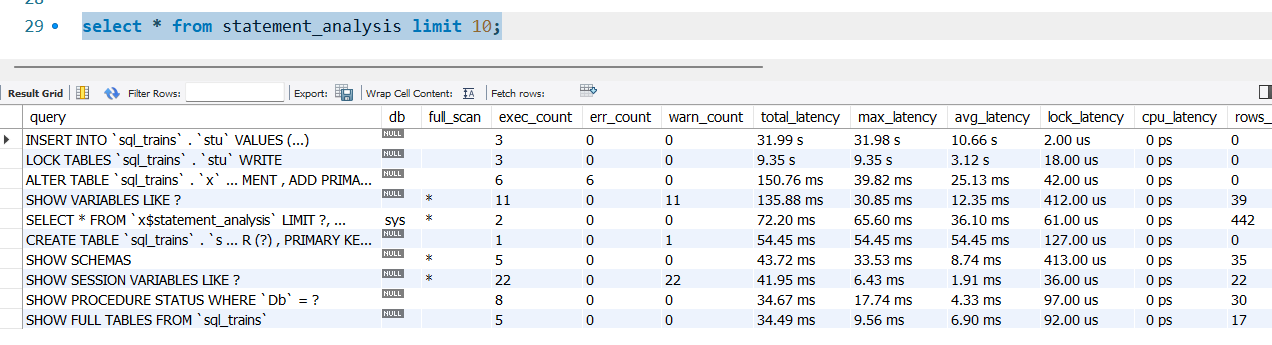 其中statements_with_errors_or_warnings用于汇总执行过程中产生错误或警告的SQL语句:
其中statements_with_errors_or_warnings用于汇总执行过程中产生错误或警告的SQL语句:
select * from statements_with_errors_or_warnings limit 10;其中statements_with_full_table_scans用于记录执行全表扫描的SQL语句:
select * from statements_with_full_table_scans limit 10;其中statements_with_sorting用于记录执行用到排序的SQL语句:
select * from statements_with_sorting limit 10;其中statements_with_temp_tables用于记录执行用到临时表的SQL语句:
select * from statements_with_temp_tables limit 10;其中schema_index_statistics用于监控和分析索引的使用效率: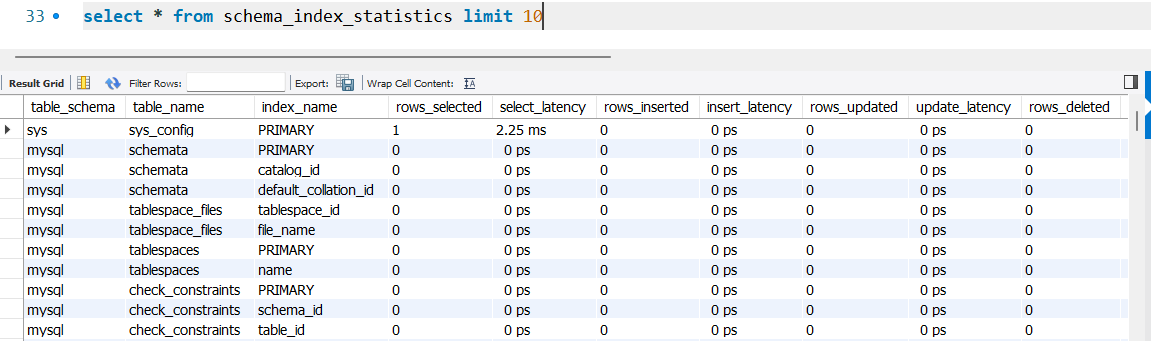 如果是mysql5.7和之前,可以访问https://github.com/mysql/mysql-sys ,执行对应数据库版本的脚本,会生成sys库:
如果是mysql5.7和之前,可以访问https://github.com/mysql/mysql-sys ,执行对应数据库版本的脚本,会生成sys库:
5. profile详情
show profiles能够在做SQL优化时帮助我们了解时间都耗费到哪里去了。
## 当前MySQL是否支持profile操作
mysql> SELECT @@have_profiling ;
+------------------+
| @@have_profiling |
+------------------+
| YES |
+------------------+
1 row in set, 1 warning (0.00 sec)
mysql> show variables like 'profiling';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| profiling | OFF |
+---------------+-------+
1 row in set, 1 warning (0.01 sec)可以看到,当前MySQL是支持 profile操作的,但是开关是关闭的。可以通过set语句在session/global级别开启profiling:
SET profiling = 1;接下来,我们所执行的SQL语句,都会被MySQL记录,并记录执行时间消耗到哪儿去了。 我们直接执行如下的SQL语句:
select * from tb_user;
select * from tb_user where id = 1;
select * from tb_user where name = '白起';
select count(*) from tb_sku;通过如下指令查看指令的执行耗时:
-- 查看每一条SQL的耗时基本情况
show profiles;
-- 查看指定query_id的SQL语句各个阶段的耗时情况
show profile for query query_id;
-- 查看指定query_id的SQL语句CPU的使用情况
show profile cpu for query query_id;6. 索引倾斜
索引倾斜(Index Skew)是数据库中一种常见的性能问题,指索引数据在各个索引键值或分区中的分布不均匀。这种不平衡会导致查询性能下降,因为数据库可能在某些区域执行大量I/O操作,而其他区域则被闲置。
6.1 索引倾斜的原因
- 数据分布不均:比如在用户表中,country字段的大部分数据集中在中国。
- 自增主键或时间戳作为索引:当使用自增主键时,新数据总是插入到索引的最后一个节点。
- 分区策略不当:比如按范围分区(如按年份),但某些年份数据量远超其他年份。
- 哈希冲突:哈希分区或哈希索引中,不同键值计算出相同哈希值。
6.2 解决办法之优化数据分布
- 重新设计表结构:将高频值拆分到单独的表或使用垂直分表。
- 数据预处理:对倾斜字段进行哈希处理(如加盐哈希),分散数据。
6.3 解决办法之调整索引策略
复合索引:在倾斜字段前添加其他字段,如 (region, country)。
前缀索引:对长字符串字段使用前缀索引(如 INDEX(col(10)))。
反转键索引(适用于自增主键)
6.4 解决办法之改进分区策略
哈希分区:替代范围分区,均匀分布数据。
复合分区:结合范围和哈希分区(如按年份范围 + 哈希子分区)。