B+tree索引
1. B+树插入过程
访问在线B+树网站,插入100 65169 368 900 556 780 35 215 1200 234888 158 90 1000 88 120 268250 数据为例,插入效果如图所示: 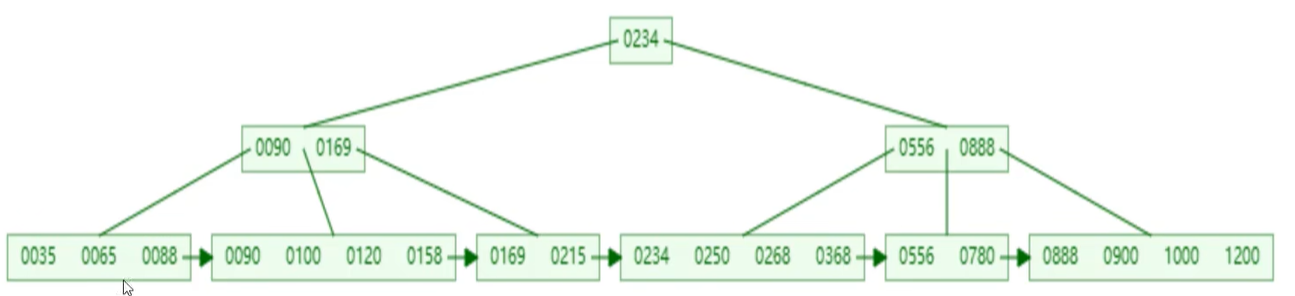 可以看出所有数据都会出现在叶子节点,非叶子节点起索引作用;所有叶子节点形成一个递增的单向链表。
可以看出所有数据都会出现在叶子节点,非叶子节点起索引作用;所有叶子节点形成一个递增的单向链表。
2. B+tree索引分类
2.1 通用分类
| 分类 | 含义 | 特点 | 关键字 |
|---|---|---|---|
| 主键索引 | 针对于表中主键创建的索引 | 默认自动创建, 只能有一个 | 必须有,而且只有一个 |
| 唯一索引 | 避免同一个表中某数据列中的值重复 | 可以有多个 | UNIQUE |
| 普通索引 | 快速定位特定数据 | 可以有多个 | |
| 全文索引 | 全文索引查找的是文本中的关键词, 而不是比较索引中的值 | 可以有多个 | FULLTEXT |
2.2 存储方式分类
在InnoDB存储引擎中,又可以分为以下两种:
| 分类 | 含义 | 特点 |
|---|---|---|
| 聚集索引(Clustered Index) | 将数据存储与索引放到一块, 索引结构的叶子节点存储整行记录数据 | 必须有,而且只有一个 |
| 二级索引(Secondary Index) | 将数据与索引分开存储, 索引结构的叶子节点关联的是对应的主键 | 可以存在多个 |
聚集索引和二级索引的具体结构如下: 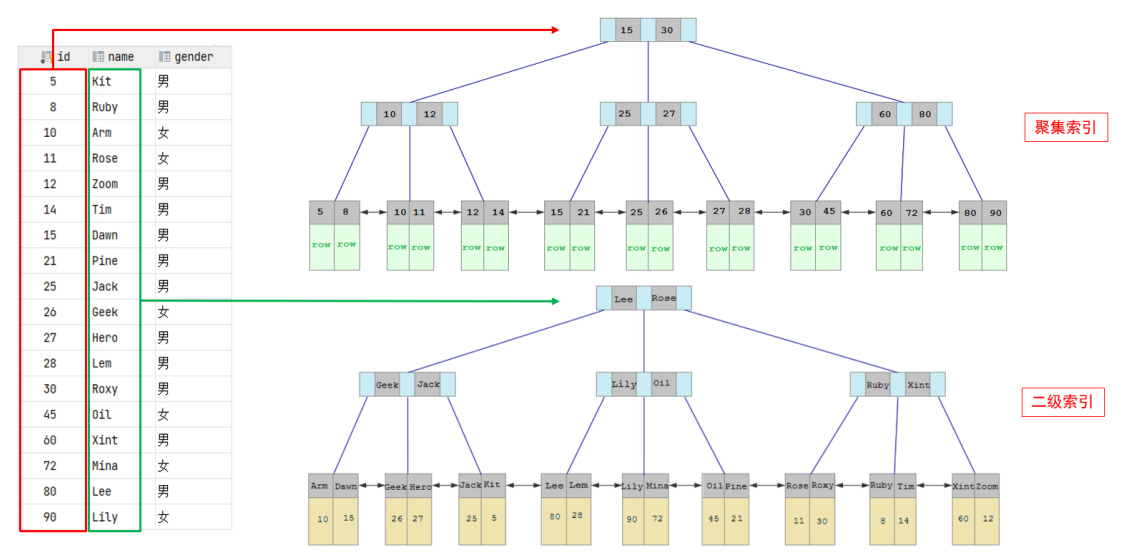
- 聚集索引的叶子节点下挂的是这一行的数据。
- 二级索引的叶子节点下挂的是该字段值对应的主键值。
所以根据主键查询会比二级索引查询更快。特别是类似这种回表情形:
sql
-- 二级索引,走索引只能拿到主键信息
select * from user where name='Arm';
-- 还需要回表, 根据jack对应的主键值再去查
select name, age from t_test where id=10;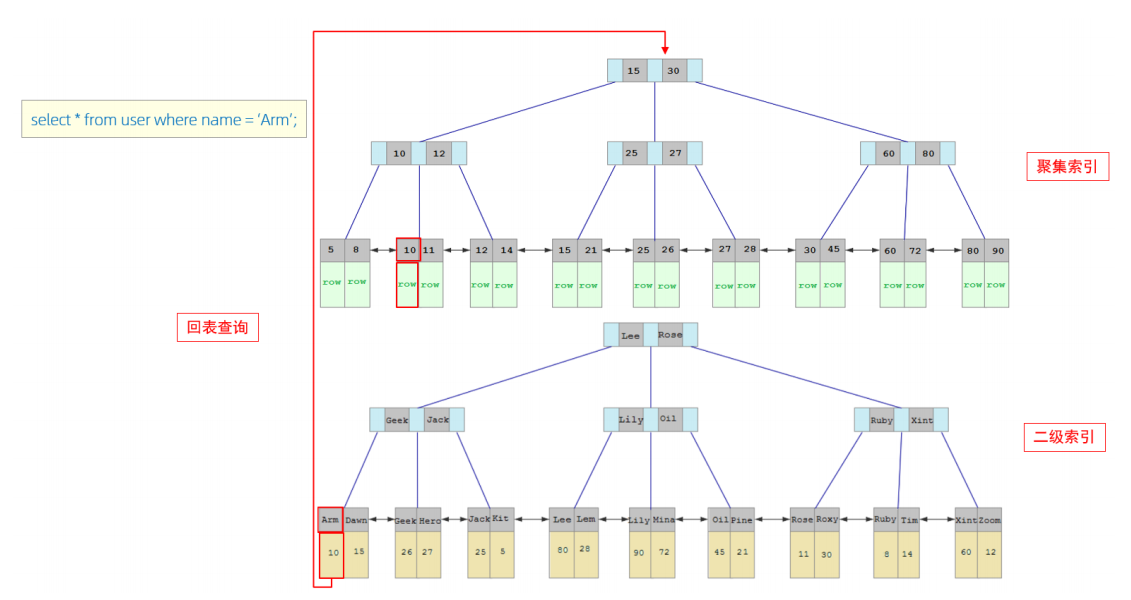
回表查询
这种先到二级索引中查找数据,找到主键值,然后再到聚集索引中根据主键值,获取 数据的方式,就称之为回表查询。
2.3 聚集索引选取规则
- 如果存在主键,主键索引就是聚集索引。
- 如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引。
- 如果表没有主键,或没有合适的唯一索引,则InnoDB会自动生成一个rowid作为隐藏的聚集索引。
3. 联合索引
索引支持多列组合的方式创建,原理和单个索引的数据结构一样: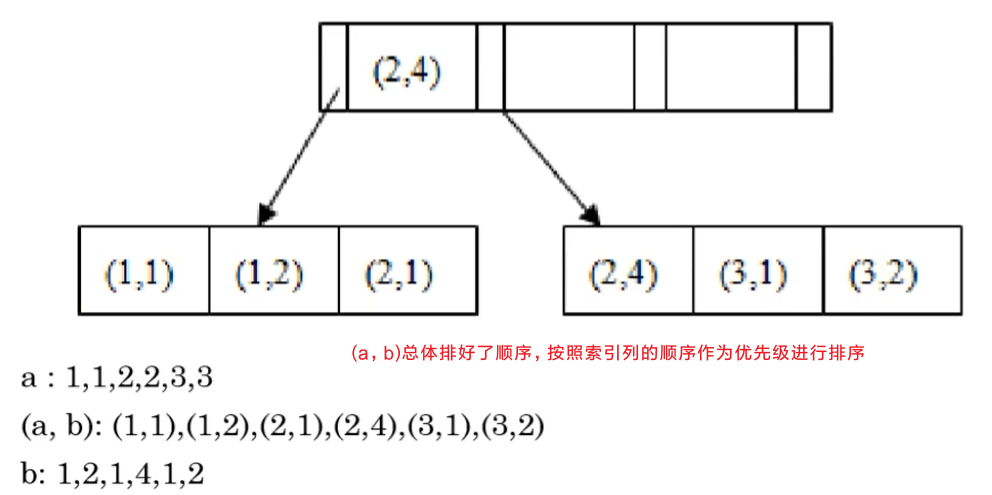 从图中可以看到b列直接拿出来是没有顺序的。如果创建的索引选择的列是a, b, c,那么顺序需要依据CARDINALITY字段的值高的在前面,需要注意的是,如果创建的联合索引是(a, b, c), 不能够被使用的情形是where表达式用到(b,c),(a,c), b, c的情形。
从图中可以看到b列直接拿出来是没有顺序的。如果创建的索引选择的列是a, b, c,那么顺序需要依据CARDINALITY字段的值高的在前面,需要注意的是,如果创建的联合索引是(a, b, c), 不能够被使用的情形是where表达式用到(b,c),(a,c), b, c的情形。
4. 索引覆盖
索引覆盖指的是获取数据的方式是直接从索引中获得,而不需要进行回表查询。
5. 索引的操作
5.1 创建索引
选择创建的索引列需要满足不重复数据占比很高,也就是具有高选择性。如果是性别、类型、类别,最好和其他列组成联合索引使用。判断高选择性可以查看CARDINALITY字段的值和总数据量的占比最好要大于10%:
sh
mysql> select *
-> from information_schema.STATISTICS
-> where TABLE_SCHEMA='gmall_v4'
-> and TABLE_NAME='user_info' limit 1\G;
*************************** 1. row ***************************
TABLE_CATALOG: def
TABLE_SCHEMA: gmall_v4
TABLE_NAME: user_info
NON_UNIQUE: 0
INDEX_SCHEMA: gmall_v4
INDEX_NAME: PRIMARY
SEQ_IN_INDEX: 1
COLUMN_NAME: id
COLLATION: A
CARDINALITY: 3714652
SUB_PART: NULL
PACKED: NULL
NULLABLE:
INDEX_TYPE: BTREE
COMMENT:
INDEX_COMMENT:
IS_VISIBLE: YES
EXPRESSION: NULL
1 row in set (0.00 sec)sql
CREATE [ UNIQUE | FULLTEXT ] INDEX index_name ON table_name (
index_col_name,... );5.2 查看索引
sql
SHOW INDEX FROM table_name;比如查询user_info的索引情况:
sh
mysql> SHOW INDEX FROM gmall_v4.user_info;
+-----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+-----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| user_info | 0 | PRIMARY | 1 | id | A | 3714652 | NULL | NULL | | BTREE | | | YES | NULL |
| user_info | 1 | idx_id | 1 | id | A | 3714652 | NULL | NULL | | BTREE | | | YES | NULL |
+-----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
2 rows in set (0.00 sec)5.3 删除索引
sql
DROP INDEX index_name ON table_name;5.4 禁用索引
有时候不想直接删除索引, 后续系统没影响再删除。在MySQL8.0之后提供:
sql
alter table xxx alter index index_name INVISIBLE/VISIBLE;5.5 指定索引排序
默认创建的所有索引里面的列都是升序的,如果遇到这种情况:
sql
-- 字段排序方向不同
select * from orders
where o_custkey=1 order by o_orderdate desc, o_status在MySQL8.0之后支持对索引排序自定义:
sql
alter table xxx add index idx_cust_date_status(o_custkey, o_orderdate desc, o_status);在MySQL5.7中虽然也能执行上述sql, 但是内容会忽略desc、asc。那么在MySQL5.7中如何解决呢:
sql
alter table tablename add column as (functionname(column)) virtual/stored6. 巡检索引
6.1 没加主键索引脚本
sql
select TABLE_NAME,
sum(case when INDEX_NAME='PRIMARY' then 1 else 0 end) as has_primary
from information_schema.STATISTICS
where TABLE_SCHEMA='gmall_v4'
group by TABLE_NAME;6.2 没有被用到的索引
sql
select
*
from sys.schema_unused_indexes
where object_schema not in ('performance_schema')6.3 查询冗余的索引
sql
select table_schema,
table_name,
redundant_index_name, -- 冗余索引名
redundant_index_columns, -- 列名
dominant_index_name, -- 主要的索引名
sql_drop_index -- 建议删除冗余索引的SQL语句
from
sys.schema_redundant_indexes;