CM6常见配置
1. HDFS配置域名访问
Hadoop集群必须用域名访问,不能用IP访问,开启如下配置dfs.client.use.datanode.hostname。 
2. 设置物理核和虚拟核占比
每台机器物理核4核虚拟成8核(集群中机器性能不同,为了更好发挥,将更强的CPU设置1:2,弱一点的就是1:1,就这两种比例),修改配置yarn.nodemanager.resource.cpu-vcores。 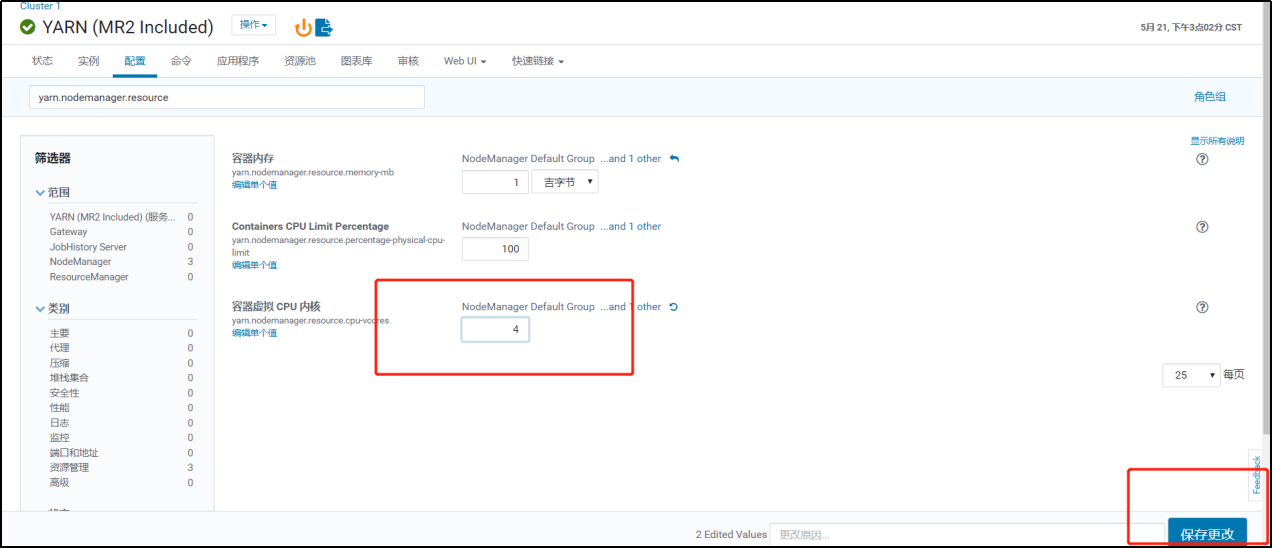
3. 修改单个容器下最大cpu申请资源
修改yarn.scheduler.maximum-allocation-vcores参数调整8核 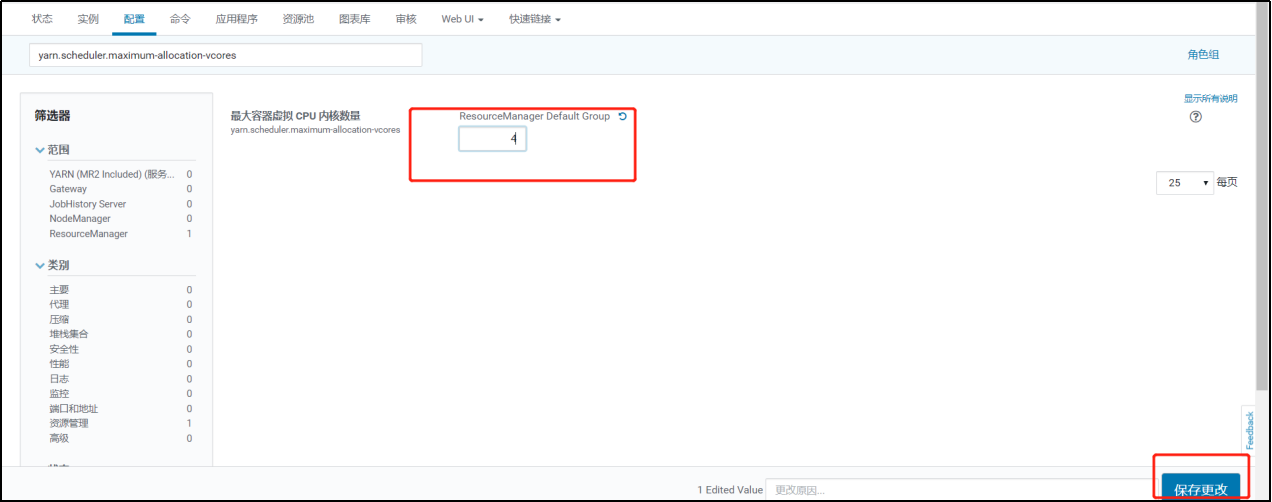
4. 设置每个任务容器内存大小和单节点大小
将每个任务容器默认大小从1G调大至8G,当前集群环境下每个节点的物理内存为16G,设置每个yarn可用每个节点内存为14G。修改yarn.scheduler.maximum-allocation-mb每个任务容器内存所需大小。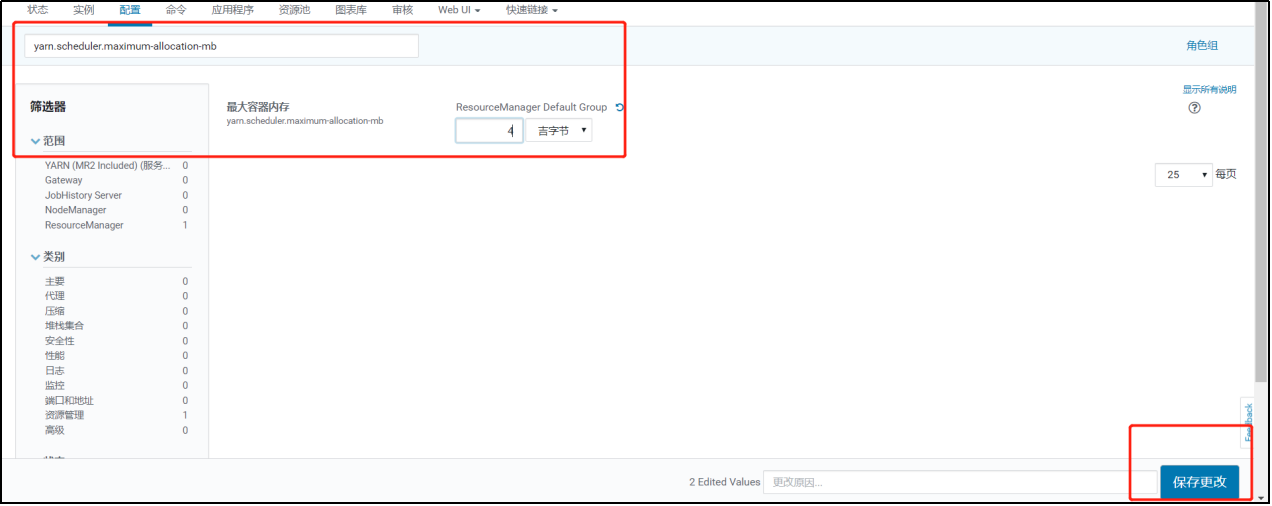 修改
修改yarn.nodemanager.resource.memory-mb每个节点内存所需大小。 
5. 关闭Spark动态分配资源参数
关闭spark.dynamicAllocation.enabled参数否则分配的资源不受控制。

6. 修改HDFS副本数
修改副本数为1。 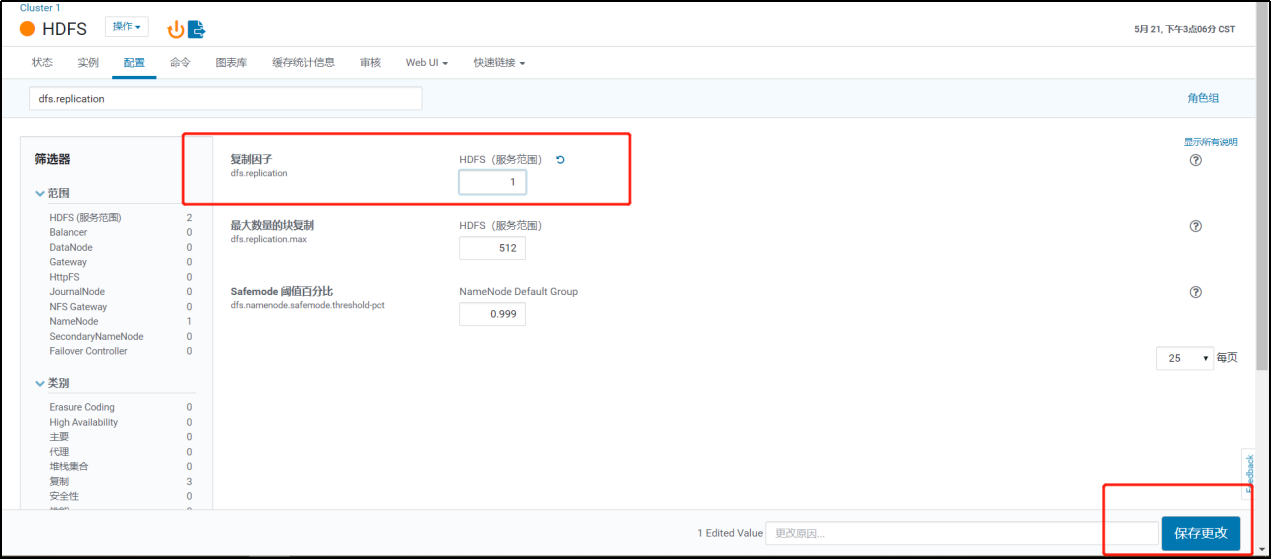
7. 设置动态分区模式
Hive动态分区非严格模式,默认是严格模式,严格模式下,动态分区至少要有一个静态分区字段。 hive.exec.dynamic.partition.mode = nonstrict
8. Hive on Spark配置
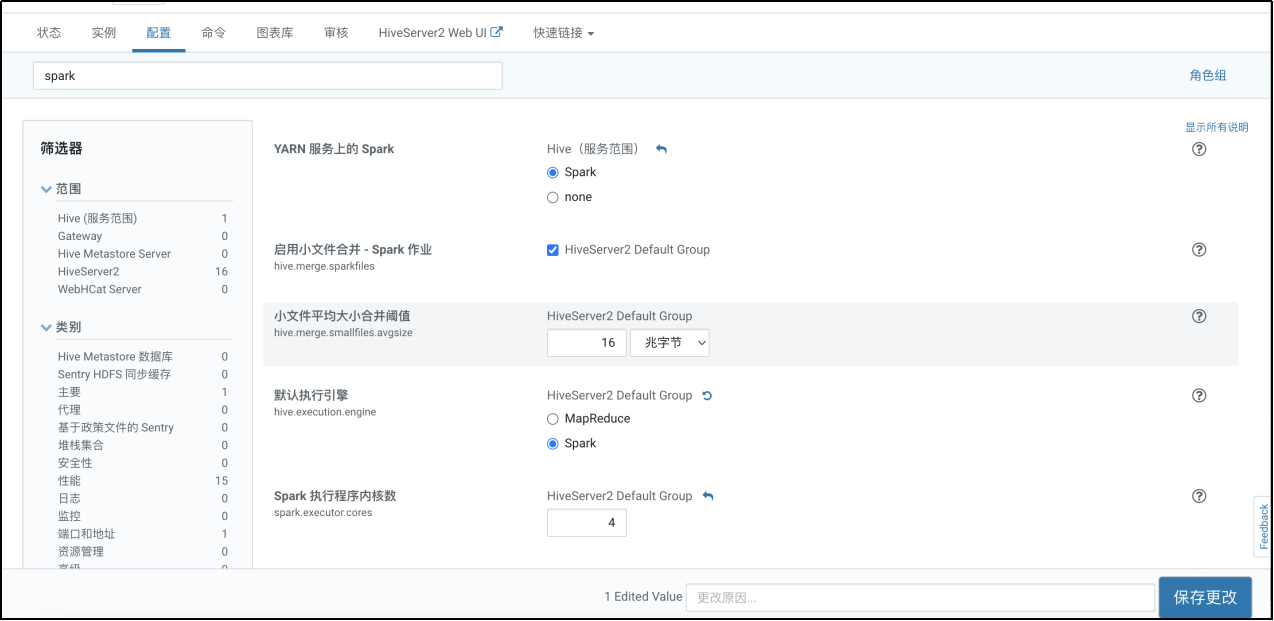
9. 设置容量调度器
CDH默认公平调度器,修改为容量调度器  默认root队列,可以进行修改,添加3个队列spark,hive,flink,spark资源设置占yarn集群40%,hive设置占yarn集群20%,flink设置占40%。
默认root队列,可以进行修改,添加3个队列spark,hive,flink,spark资源设置占yarn集群40%,hive设置占yarn集群20%,flink设置占40%。
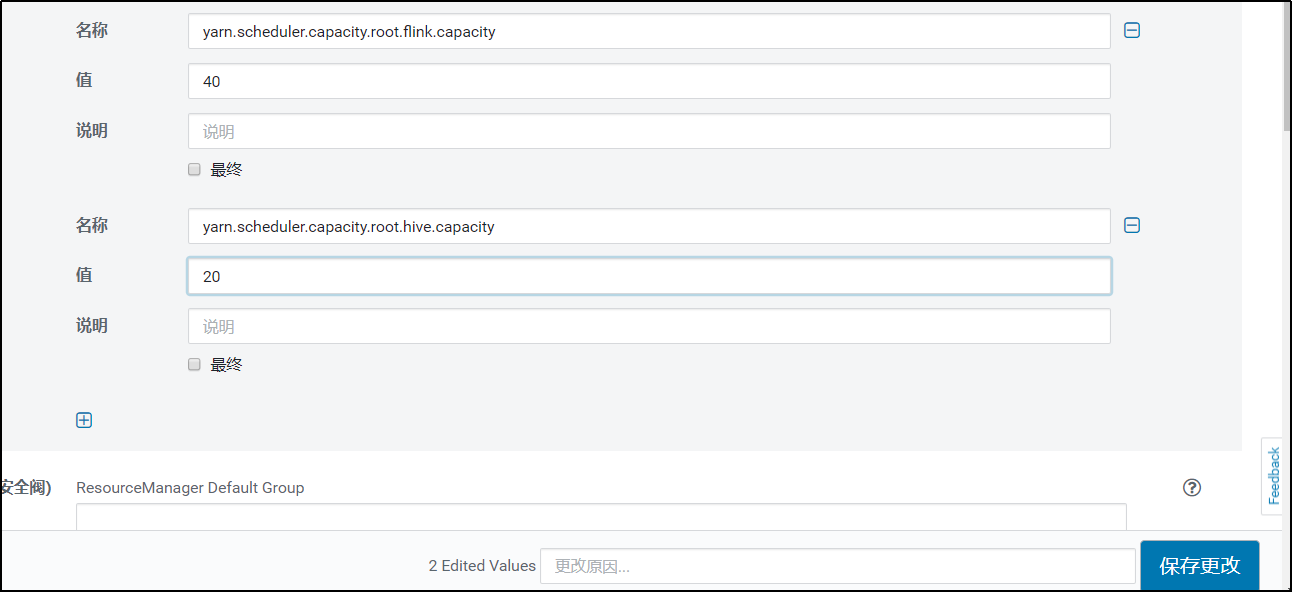 配置完毕后重启服务,到yarn界面查看调度器,已经发生变化有hive队列和spark队列。
配置完毕后重启服务,到yarn界面查看调度器,已经发生变化有hive队列和spark队列。 
10. 配置yarn环境变量
为了解决hue在执行调度任务时找不到环境变量, PATH=$PATH:$JAVA_HOME/bin 
11. HUE和HDFS HA配置
由于HDFS开启了HA,导致Hue识别失败active节点和standby节点,故需配置HTTPFS角色。 





12. 取消向量化执行
向量化执行是hive优化的一种方式,但是他必须要求执行引擎是Tez,文件格式是orc,一次批量执行1024行而非一行来提高扫描、聚合、过滤器和连接等操作的性能。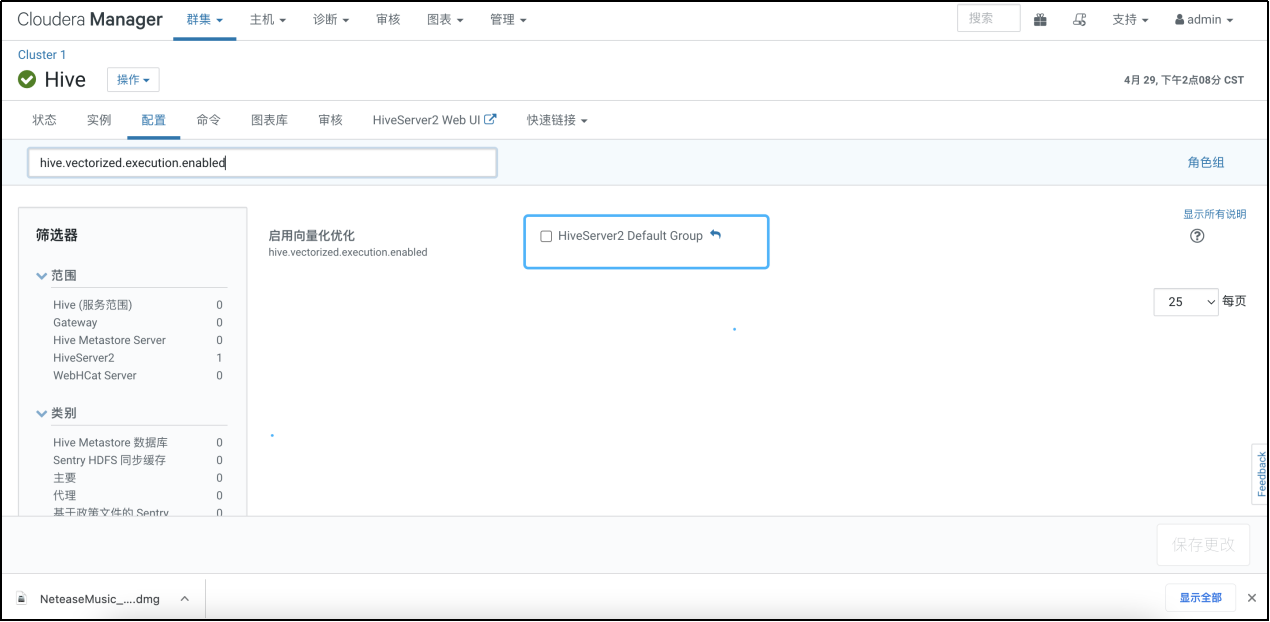
13. 设置Yarn AppMaster资源限制
yarn.scheduler.capacity.maximum-am-resource-percent=0.6,设置有多少资源可以用来运行app master,即控制当前激活状态的应用(防止提交任务数太多),默认是10%。 