CM6整合Flink
CDH6由于官方没有提供Flink
1. 上传Flink包
上传Flink1.14.6的安装包和源码包、maven安装包到/opt/software, 需要指定scala版本为2.11(因为只做parcels工具不支持2.12)
[root@hadoop105 ~]# mkdir /opt/software /opt/module && cd /opt/software
## 上传完成后
[root@hadoop105 software]# ll
total 2602952
-rw-r--r-- 1 root root 9506321 Feb 15 2023 apache-maven-3.6.3-bin.tar.gz
-rw-r--r-- 1 root root 314015504 Feb 15 2023 flink-1.14.6-bin-scala_2.11.tgz
-rw-r--r-- 1 root root 30661804 Feb 15 2023 flink-1.14.6-src.tgz
-rw-r--r-- 1 root root 2311231436 Feb 15 2023 repository.zip2. 安装maven
2.1 解压安装
[root@hadoop105 software]# tar -zxvf apache-maven-3.6.3-bin.tar.gz -C /opt/module添加环境变量
[root@hadoop105 software]# vim /etc/profile.d/my_env.sh
##添加以下变量
#MAVEN_HOME
export MAVEN_HOME=/opt/module/apache-maven-3.6.3
export PATH=$PATH:$MAVEN_HOME/bin
## 退出保存后配置生效
[root@hadoop105 software]# source /etc/profile.d/my_env.sh
## 测试安装结果2.2 配置Maven镜像
[root@hadoop105 software]# cd /opt/module/apache-maven-3.6.3/conf/
[root@hadoop105 conf]# rm -rf settings.xml
[root@hadoop105 conf]# wget https://bigdata-1308108754.cos.ap-guangzhou.myqcloud.com/conf/maven-setting/settings.xml3. 编译配置
3.1 解压Flink源码包
[root@hadoop105 software]# tar -zxvf flink-1.14.6-src.tgz -C /opt/module
[root@hadoop105 software]# mv /opt/module/flink-1.14.6/ /opt/module/flink-1.14.6-src
[root@hadoop105 software]# tar -zxvf flink-1.14.6-bin-scala_2.11.tgz -C /opt/module3.2 修改pom.xml文件
修改flink-1.14.6-src中的pom.xml:
[root@hadoop101 flink-1.14.6-src]# vim /opt/module/flink-1.14.6-src/pom.xml
## 修改hadoop版本 96行
<hadoop.version>3.0.0-cdh6.3.2</hadoop.version>
## 修改hive版本 149行
<hive.version>2.1.1-cdh6.3.2</hive.version>
## 156行
<hivemetastore.hadoop.version>3.0.0-cdh6.3.2</hivemetastore.hadoop.version>
## </build>标签之后 </project>之前 添加
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
<repository>
<id>confluent-repo</id>
<url>https://packages.confluent.io/maven/</url>
</repository>
</repositories>修改flink-sql-connector-hive-2.2.0的pom.xml文件
[root@hadoop105 flink-1.14.6-src]# vim flink-connectors/flink-sql-connector-hive-2.2.0/pom.xml
## 修改hive-exec版本 48行
<version>2.1.1-cdh6.3.2</version>3.3 解压maven仓库包
[root@hadoop105 software]# unzip repository.zip
[root@hadoop105 module]# vim apache-maven-3.6.3/conf/settings.xml
## 添加本地仓库地址
<localRepository>/opt/software/repository</localRepository>4. 编译Flink
[root@hadoop105 flink-1.14.6-src]# mvn clean install -DskipTests -Dfast -Drat.skip=true -Dhaoop.version=3.0.0-cdh6.3.2 -Dinclude-hadoop -Dscala-2.12 -T10C 编译后flink-dist/target/flink-1.14.6-bin/flink-1.14.6文件夹就是flink官方提供二进制包文件。
编译后flink-dist/target/flink-1.14.6-bin/flink-1.14.6文件夹就是flink官方提供二进制包文件。
拷贝编译成功connector后的包放入Flink运行包的lib中
cp /opt/module/flink-1.14.6-src/flink-connectors/flink-sql-connector-hive-2.2.0/target/flink-sql-connector-hive-2.2.0_2.11-1.14.6.jar /opt/module/flink-1.14.6/lib/
cp /opt/cloudera/parcels/CDH/jars/hive-exec-2.1.1-cdh6.3.2.jar /opt/module/flink-1.14.6/lib/
cp /opt/cloudera/parcels/CDH/jars/libfb303-0.9.3.jar /opt/module/flink-1.14.6/lib/
cp /opt/cloudera/parcels/CDH/jars/hadoop-common-3.0.0-cdh6.3.2.jar /opt/module/flink-1.14.6/lib/
cp /opt/cloudera/parcels/CDH/jars/hadoop-mapreduce-client-common-3.0.0-cdh6.3.2.jar /opt/module/flink-1.14.6/lib/
cp /opt/cloudera/parcels/CDH/jars/hadoop-mapreduce-client-core-3.0.0-cdh6.3.2.jar /opt/module/flink-1.14.6/lib/
cp /opt/cloudera/parcels/CDH/jars/hadoop-mapreduce-client-hs-3.0.0-cdh6.3.2.jar /opt/module/flink-1.14.6/lib/
cp /opt/cloudera/parcels/CDH/jars/hadoop-mapreduce-client-jobclient-3.0.0-cdh6.3.2.jar /opt/module/flink-1.14.6/lib/拷贝后/opt/module/flink-1.14.6/lib路径下应该包含以下包
[root@hadoop105 ~]# ll /opt/module/flink-1.14.6/lib
total 276272
-rw-r--r-- 1 502 games 85586 Sep 10 2022 flink-csv-1.14.6.jar
-rw-r--r-- 1 502 games 143701139 Sep 10 2022 flink-dist_2.11-1.14.6.jar
-rw-r--r-- 1 502 games 153148 Sep 10 2022 flink-json-1.14.6.jar
-rw-r--r-- 1 502 games 7709731 Jun 9 2022 flink-shaded-zookeeper-3.4.14.jar
-rw-r--r-- 1 root root 43784906 Mar 7 08:41 flink-sql-connector-hive-2.2.0_2.11-1.14.6.jar
-rw-r--r-- 1 502 games 42348280 Sep 10 2022 flink-table_2.11-1.14.6.jar
-rw-r--r-- 1 root root 3993717 Mar 7 08:36 hadoop-common-3.0.0-cdh6.3.2.jar
-rw-r--r-- 1 root root 770504 Mar 7 08:36 hadoop-mapreduce-client-common-3.0.0-cdh6.3.2.jar
-rw-r--r-- 1 root root 1644597 Mar 7 08:36 hadoop-mapreduce-client-core-3.0.0-cdh6.3.2.jar
-rw-r--r-- 1 root root 182762 Mar 7 08:36 hadoop-mapreduce-client-hs-3.0.0-cdh6.3.2.jar
-rw-r--r-- 1 root root 51302 Mar 7 08:36 hadoop-mapreduce-client-jobclient-3.0.0-cdh6.3.2.jar
-rw-r--r-- 1 root root 35803898 Mar 7 08:40 hive-exec-2.1.1-cdh6.3.2.jar
-rw-r--r-- 1 root root 313702 Mar 7 08:36 libfb303-0.9.3.jar
-rw-r--r-- 1 502 games 208006 Jun 9 2022 log4j-1.2-api-2.17.1.jar
-rw-r--r-- 1 502 games 301872 Jun 9 2022 log4j-api-2.17.1.jar
-rw-r--r-- 1 502 games 1790452 Jun 9 2022 log4j-core-2.17.1.jar
-rw-r--r-- 1 502 games 24279 Jun 9 2022 log4j-slf4j-impl-2.17.1.jar5. 制作parcel包和csd文件
将Flink完整包进行压缩:
[root@hadoop105 ~]# cd /opt/module
[root@hadoop105 module]# tar -zcvf flink-1.14.6-cdh6.3.2.tgz flink-1.14.6安装git, 参考CICD中安装git
下载工具包源码
[root@hadoop105 module]# git clone https://github.com/YUjichang/flink-parcel.git(可更换成加速地址https://gitclone.com/github.com/YUjichang/flink-parcel.git) 修改脚本配置
[root@hadoop101 module]# cd flink-parcel/
[root@hadoop101 flink-parcel]# vim flink-parcel.properties
#FLINk 下载地址
FLINK_URL= /opt/module/flink-1.14.6-cdh6.3.2.tgz
#flink版本号
FLINK_VERSION=1.14.6
#扩展版本号
EXTENS_VERSION=CDH6.3.2
#操作系统版本,以centos为例
OS_VERSION=7
#CDH 小版本
CDH_MIN_FULL=6.0
CDH_MAX_FULL=6.4
#CDH大版本
CDH_MIN=5
CDH_MAX=6运行build.sh脚本,开始构建parcel和csd
[root@hadoop101 flink-parcel]# ./build.sh parcel
[root@hadoop101 flink-parcel]# ./build.sh csd编译完成后,生成的Flink的parcel和csd文件
[root@hadoop105 flink-parcel]# ll
total 434184
drwxr-xr-x 5 root root 4096 Mar 7 08:43 aux
drwxr-xr-x 2 root root 4096 Mar 7 08:43 bin
-rwxr-xr-x 1 root root 4028 Mar 7 08:43 build.sh
drwxr-xr-x 5 root root 4096 Mar 7 08:43 cm_ext
drwxr-xr-x 2 root root 4096 Mar 7 08:43 descriptor
drwxr-xr-x 3 root root 4096 Mar 7 08:43 etc
drwxr-xr-x 6 root root 4096 Mar 7 08:45 FLINK-1.14.6-CDH6.3.2
drwxr-xr-x 2 root root 4096 Mar 7 08:46 FLINK-1.14.6-CDH6.3.2_build
-rw-r--r-- 1 root root 444518251 Mar 7 08:45 flink-1.14.6-cdh6.3.2.tgz
drwxr-xr-x 6 root root 4096 Mar 7 08:46 flink_csd_build
-rw-r--r-- 1 root root 21123 Mar 7 08:46 FLINK_ON_YARN-1.14.6.jar
-rwxr-xr-x 1 root root 286 Mar 7 08:45 flink-parcel.properties
drwxr-xr-x 2 root root 4096 Mar 7 08:43 images
drwxr-xr-x 2 root root 4096 Mar 7 08:43 meta
-rw-r--r-- 1 root root 371 Mar 7 08:43 README.md
drwxr-xr-x 2 root root 4096 Mar 7 08:43 scripts发现多了FLINK-1.14.6-CDH6.3.2_build文件夹和FLINK_ON_YARN-1.14.6.jar文件,并且在FLINK-1.14.6-CDH6.3.2_build文件夹中parcel已经生成。
[root@hadoop105 flink-parcel]# cd FLINK-1.14.6-CDH6.3.2_build
[root@hadoop105 FLINK-1.14.6-CDH6.3.2_build]# ll
total 438596
-rw-r--r-- 1 root root 449108689 Mar 7 08:46 FLINK-1.14.6-CDH6.3.2-el7.parcel
-rw-r--r-- 1 root root 40 Mar 7 08:46 FLINK-1.14.6-CDH6.3.2-el7.parcel.sha
-rw-r--r-- 1 root root 840 Mar 7 08:46 manifest.json6. 向CM中添加Flink的安装包
- 将parcel包到cloudera的parcel-repo中
[root@hadoop105 FLINK-1.14.6-CDH6.3.2_build]# scp FLINK-1.14.6-CDH6.3.2-el7.parcel* root@hadoop101:/opt/cloudera/parcel-repo/
[root@hadoop105 FLINK-1.14.6-CDH6.3.2_build]# cd ../- 在cloudera的parcel-repo中的manifest.json文件添加Flink.parcel相关得加载依赖配置
## 回到hadoop101上执行
[root@hadoop101 parcel-repo]# vim manifest.json
## 添加hadoop105中FLINK-1.14.6-CDH6.3.2_build目录下的manifest.json内容到hadoop101中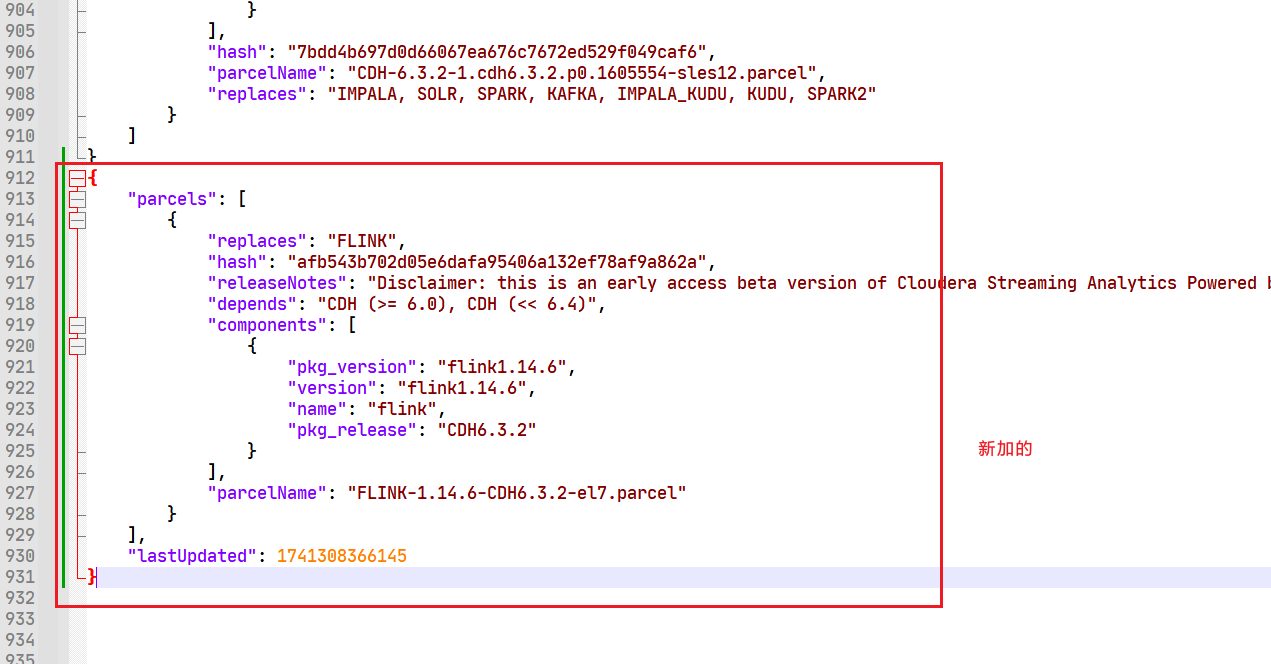 3. 拷贝FLINK_ON_YARN-1.14.6.jar到hadoop101的cloudera的csd中
3. 拷贝FLINK_ON_YARN-1.14.6.jar到hadoop101的cloudera的csd中
[root@hadoop105 flink-parcel]# scp FLINK_ON_YARN-1.14.6.jar root@hadoop101:/opt/cloudera/csd/- 重启hadoop101上的CM
[root@hadoop101 parcel-repo]# systemctl restart cloudera-scm-server7. 在CM上添加Flink服务
重启后登录CM,点击群集->Parcel: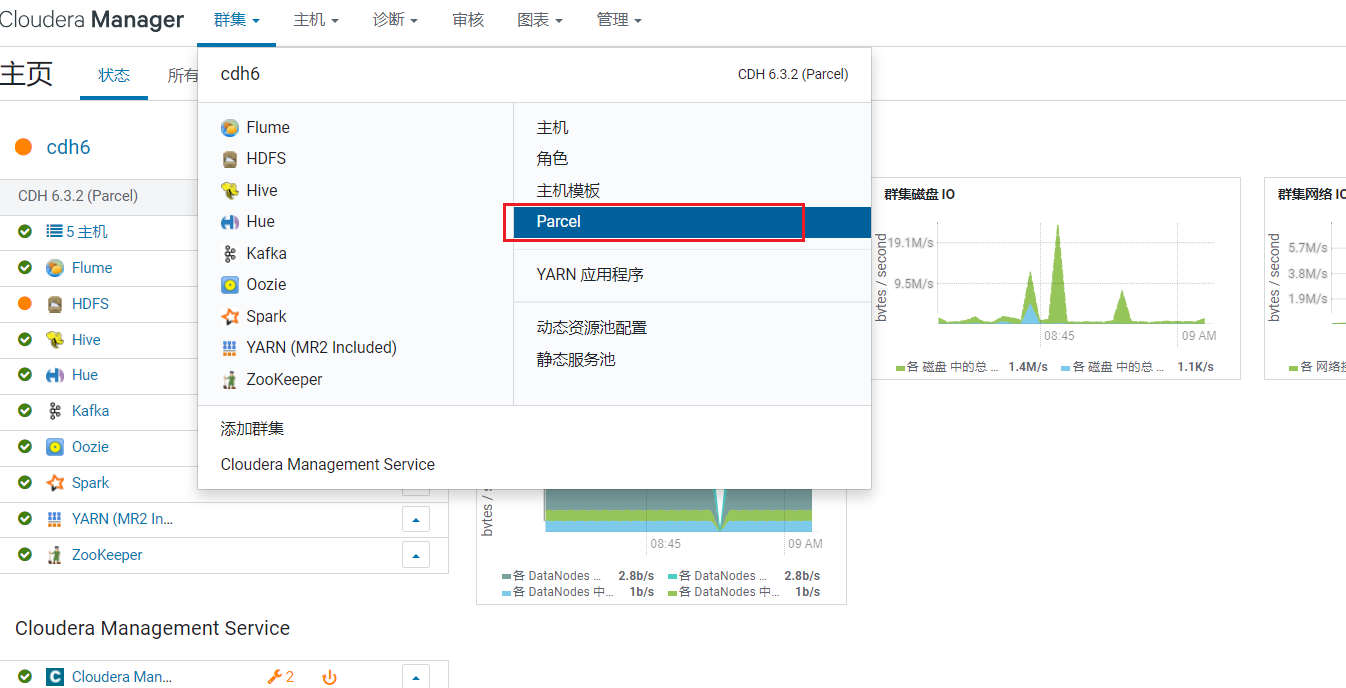 可以看到Parcels列表中多了FLink:
可以看到Parcels列表中多了FLink: 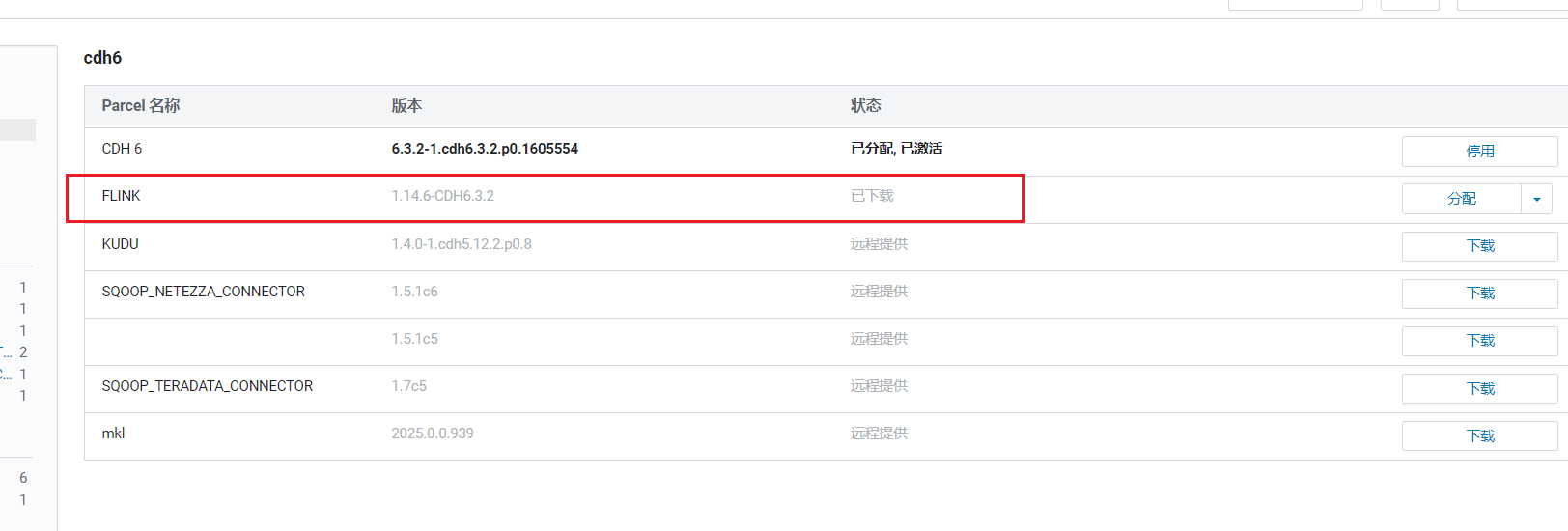 点击右边的分配,分配后点击激活:
点击右边的分配,分配后点击激活: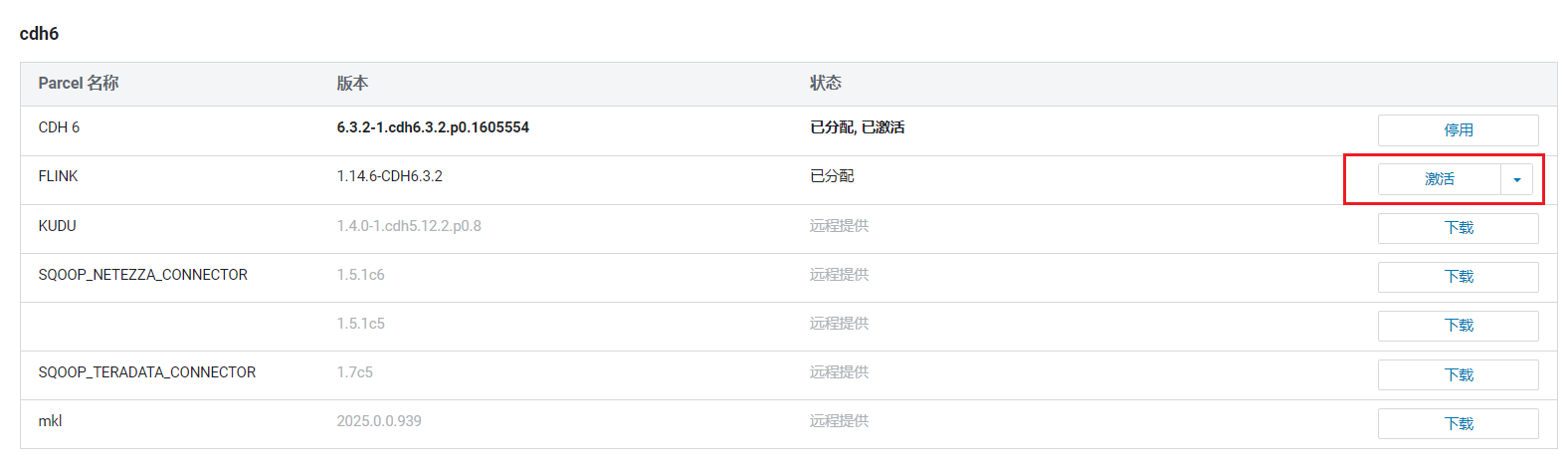 激活后,Flink服务就处于可用状态:
激活后,Flink服务就处于可用状态: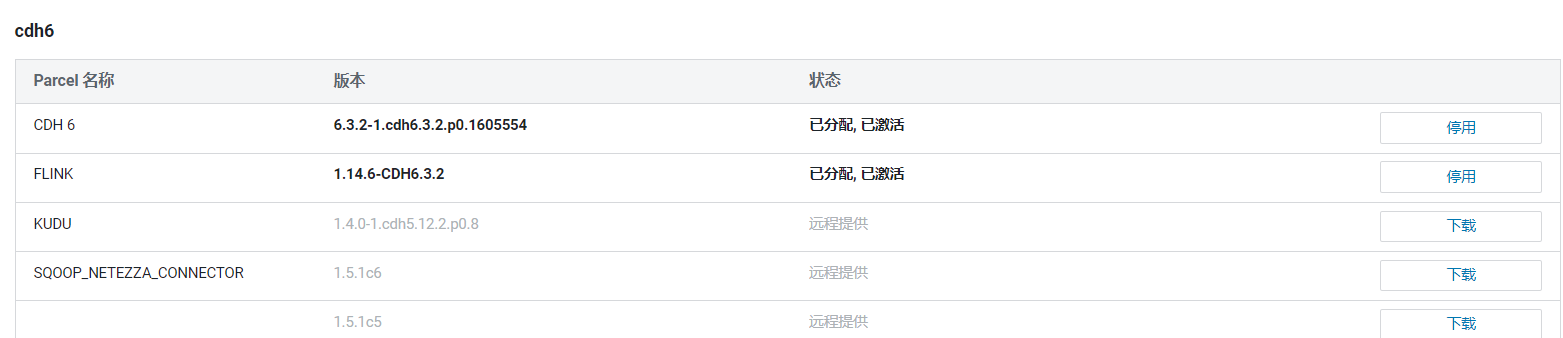 回到首页,点击添加服务:
回到首页,点击添加服务: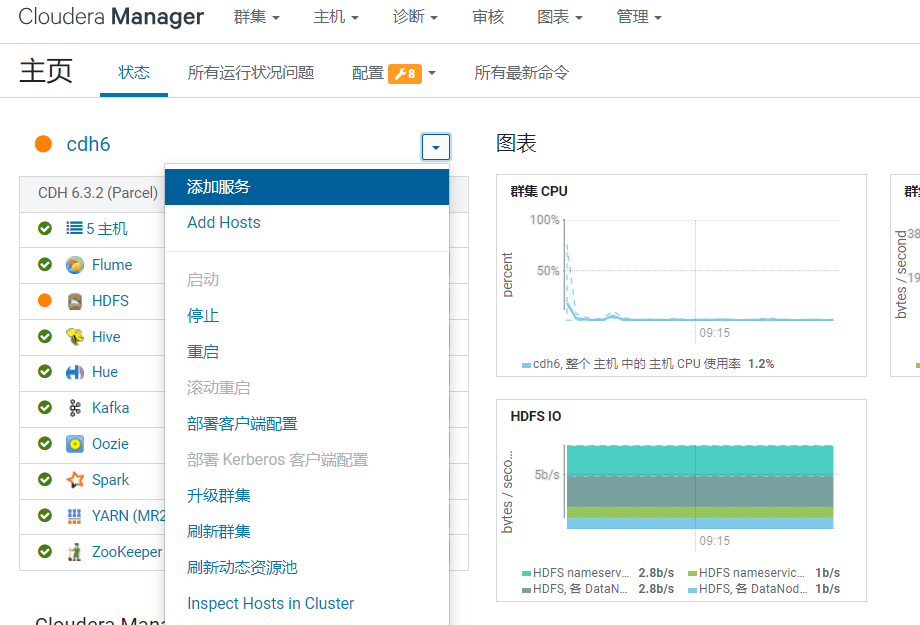 可以看到Flink服务已经有了:
可以看到Flink服务已经有了: 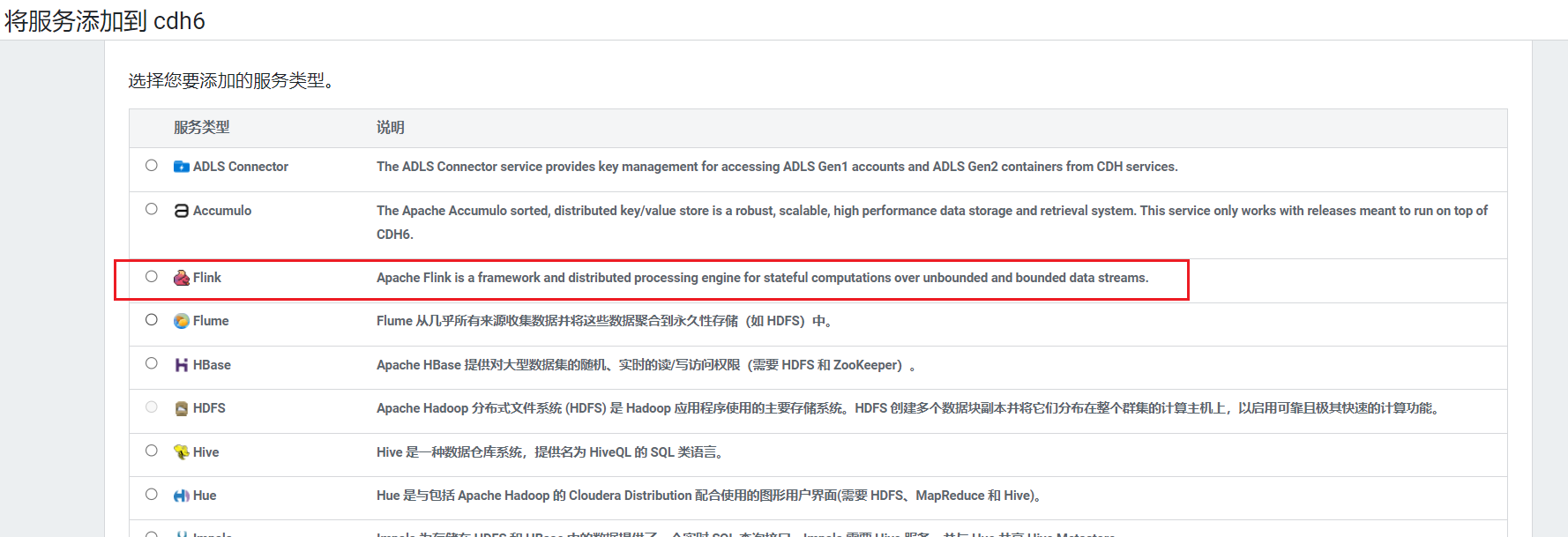 点击继续,选择没有hive的依赖项:
点击继续,选择没有hive的依赖项: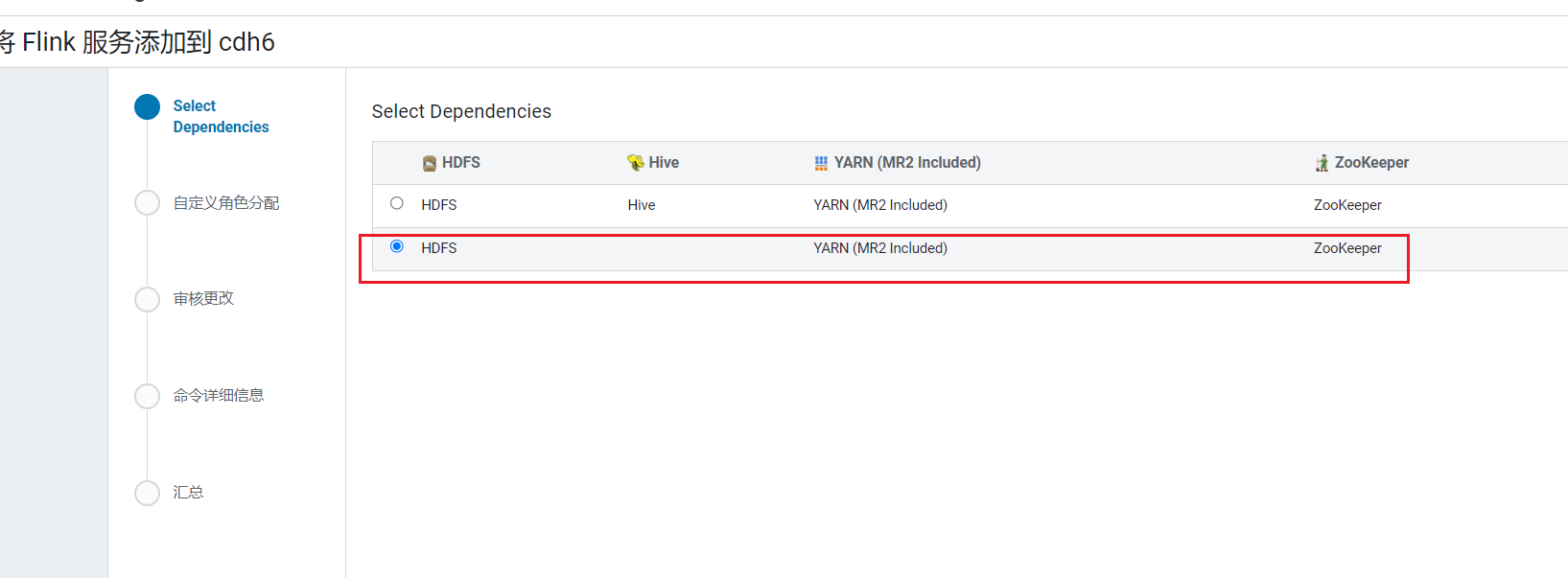 我们把flink安装在hadoop105上,点击继续:
我们把flink安装在hadoop105上,点击继续: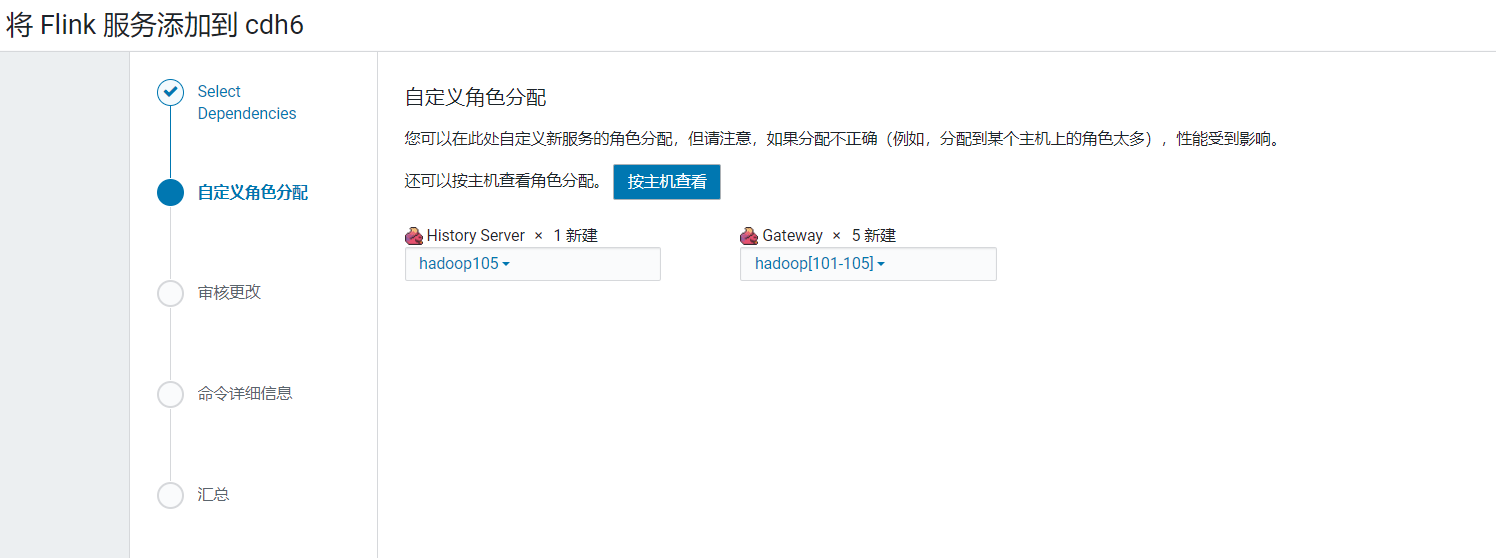 使用默认配置,点击继续:
使用默认配置,点击继续: 进入flink安装启动界面:
进入flink安装启动界面: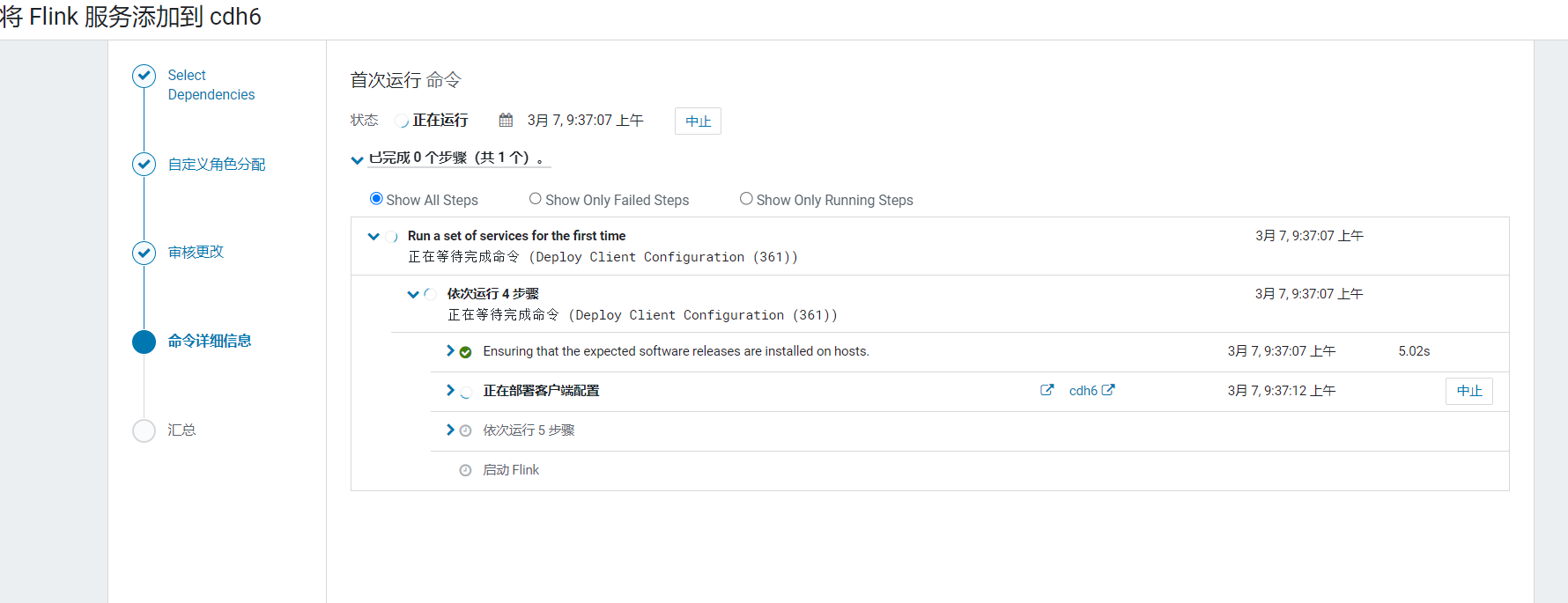 启动完成后点击完成:
启动完成后点击完成: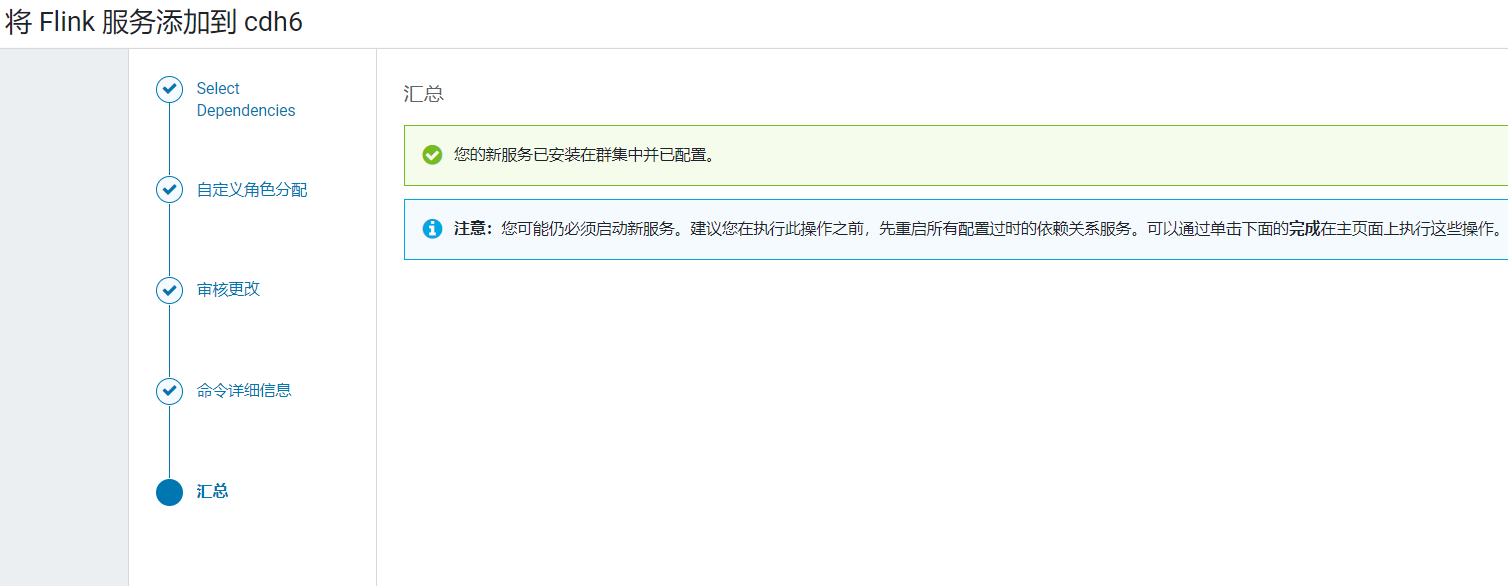 回到首页,发现flink并没有受到CDH的管控:
回到首页,发现flink并没有受到CDH的管控: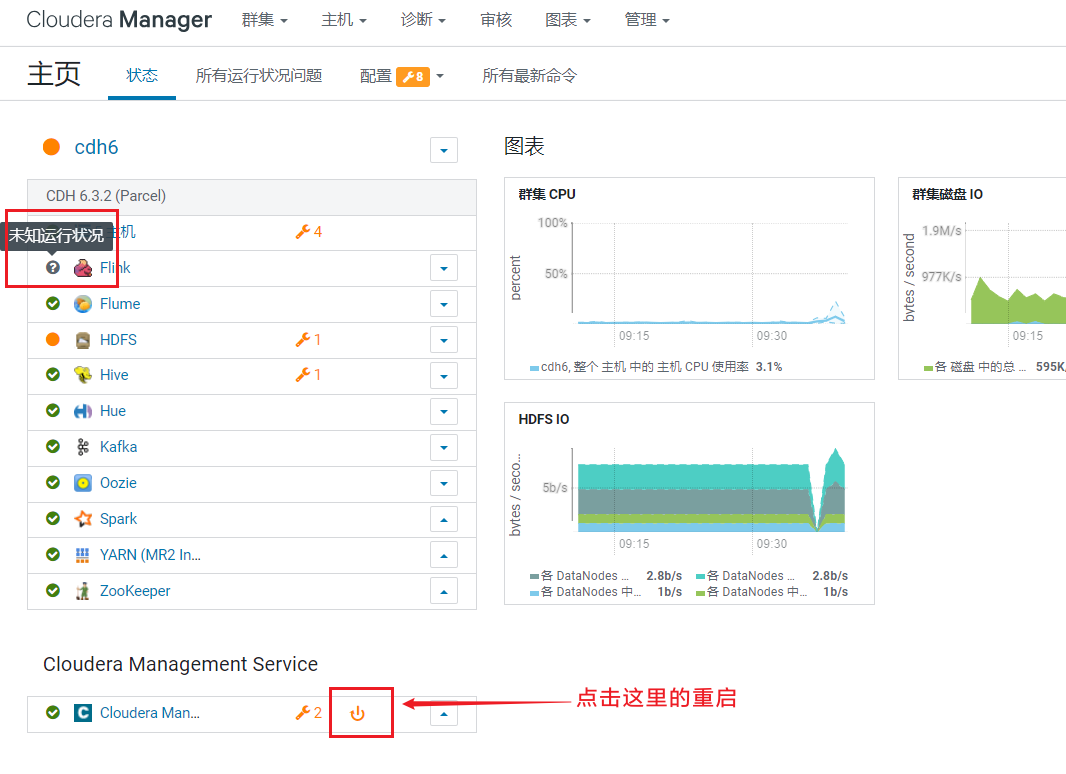 点击重启CM,进入配置确认页面:
点击重启CM,进入配置确认页面: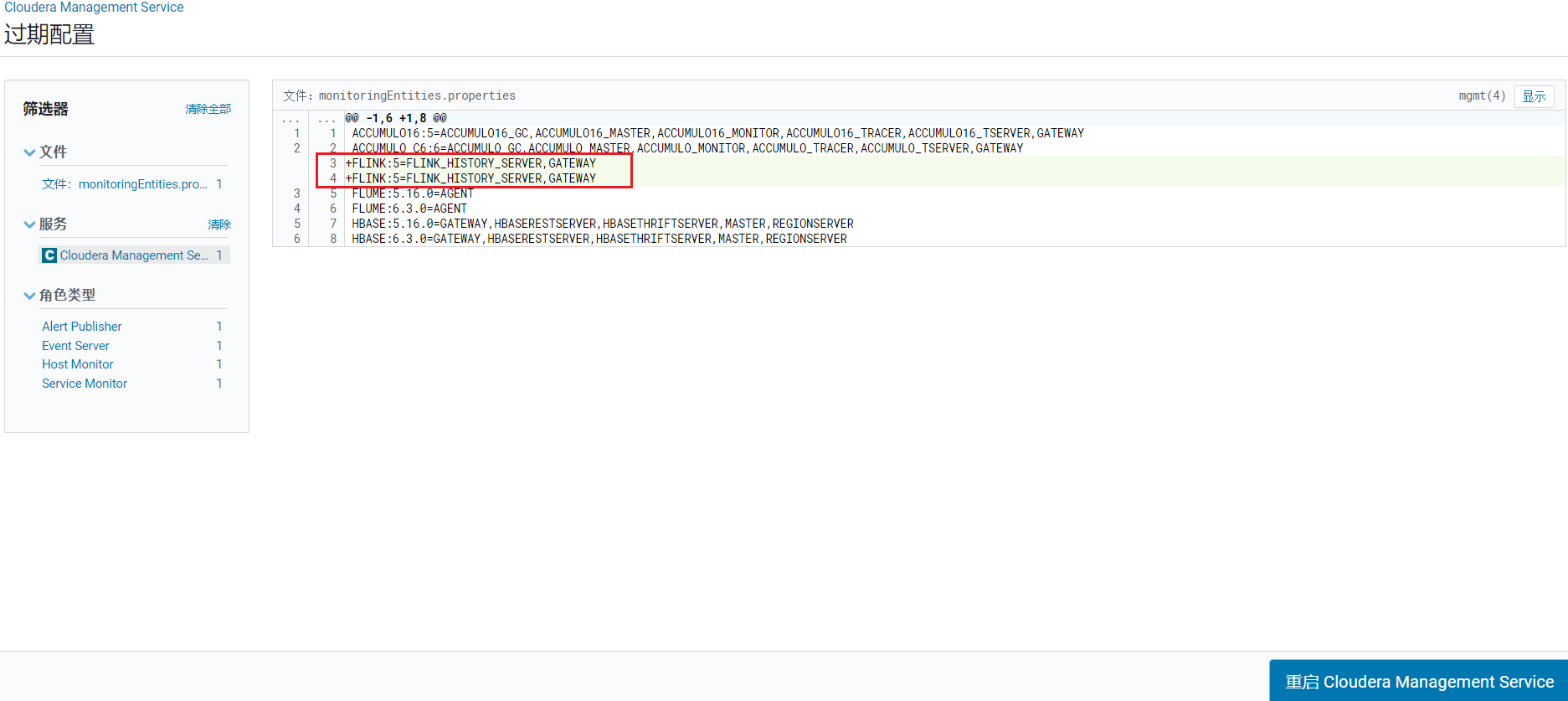 点击重启CM Server按钮:
点击重启CM Server按钮: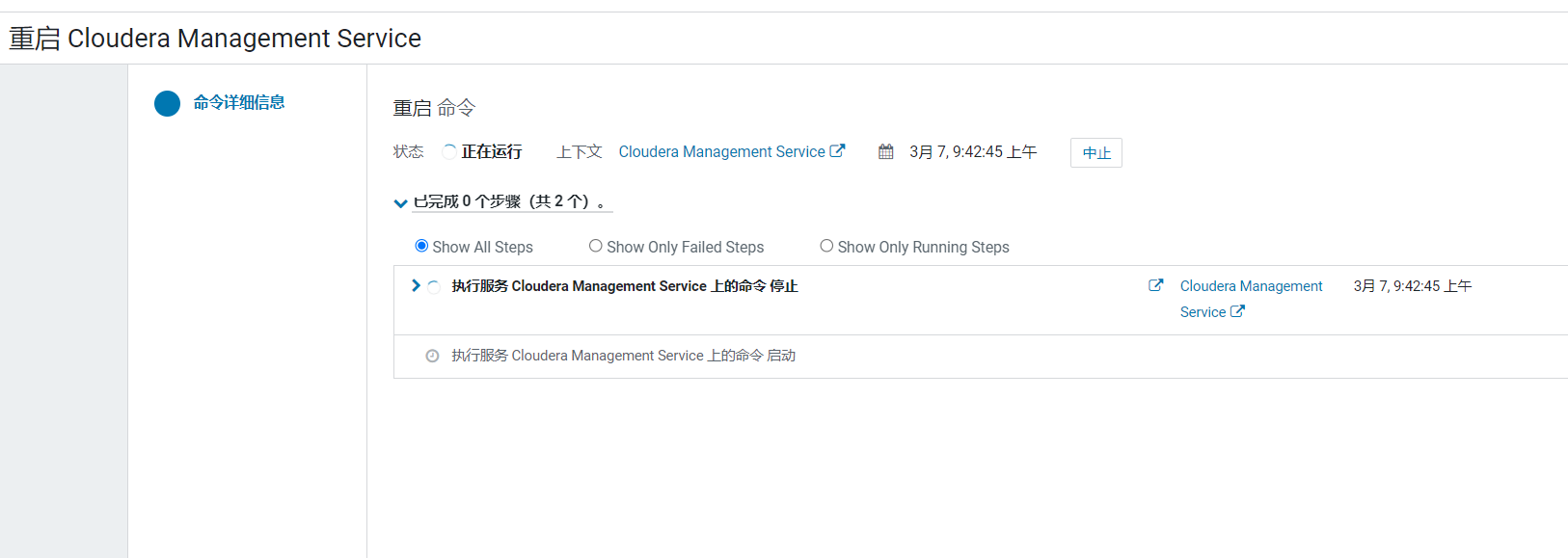
重启完成后,点击完成: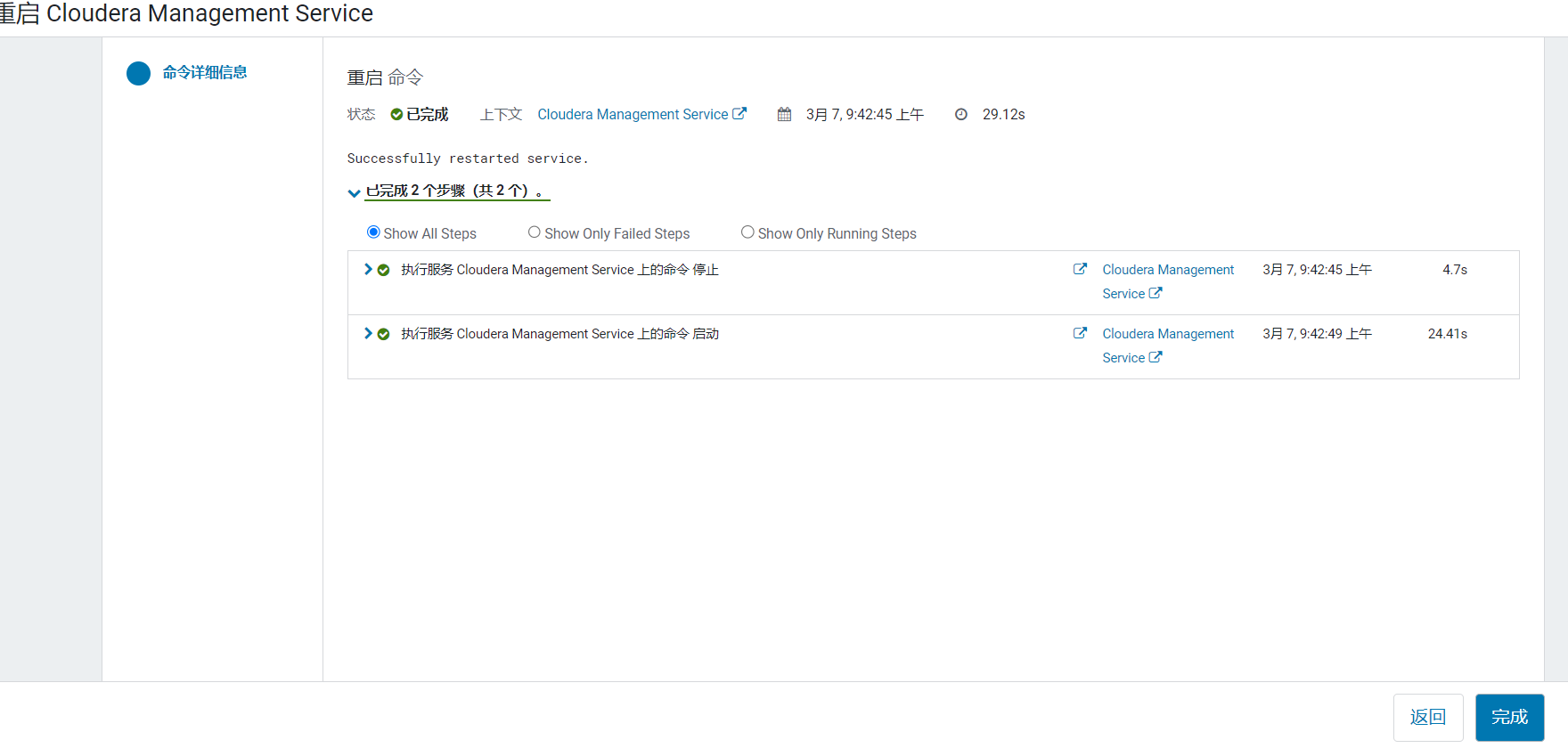 可以看到这时,Flink服务就被监控了:
可以看到这时,Flink服务就被监控了: 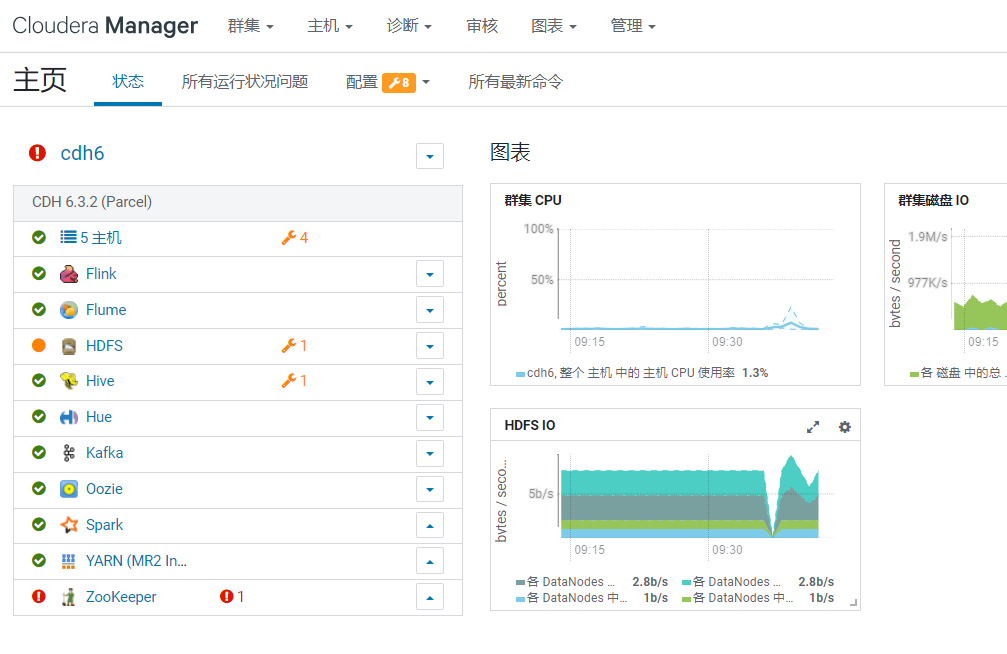
8. 验证Flink功能
8.1 使用yarn-per-job模式跑wordcount测试
[root@hadoop101 flink-1.14.6-cdh6.3.2]# chmod 777 /opt/cloudera/parcels/FLINK/bin/flink
[root@hadoop101 flink-1.14.6-cdh6.3.2]# sudo -u hdfs /opt/cloudera/parcels/FLINK/bin/flink run -t yarn-per-job /opt/cloudera/parcels/FLINK/lib/flink/examples/batch/WordCount.jar在CM页面找到YARN,点击进入YARN组件页面,选择WEBUI菜单: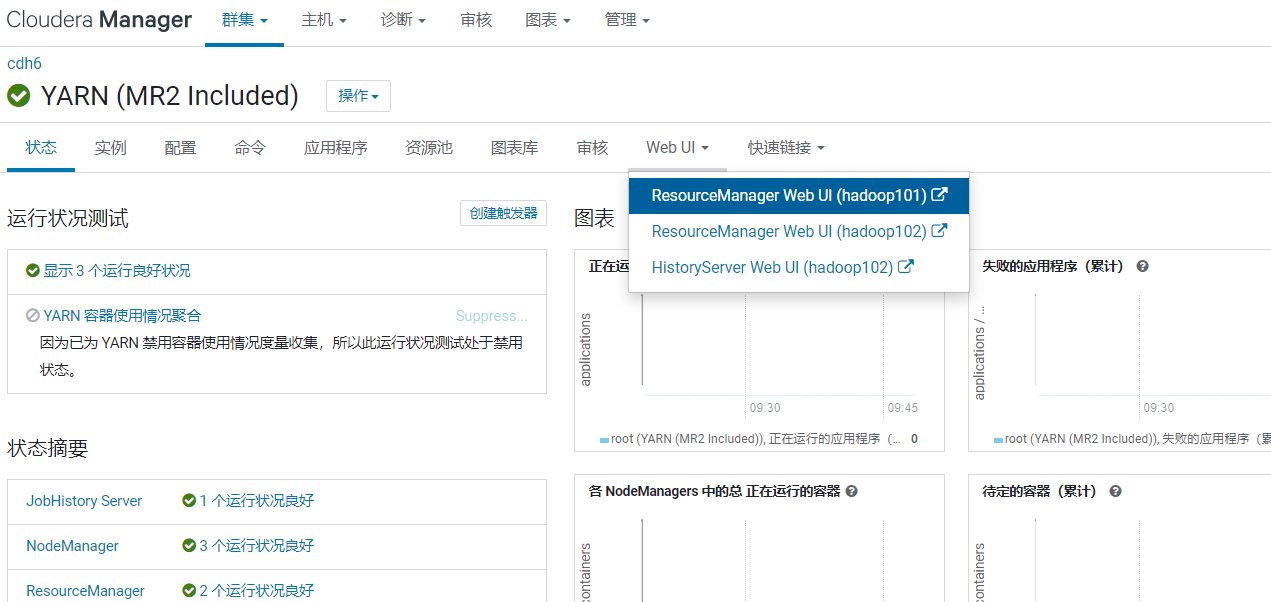 点击进入ResouceManager页面:
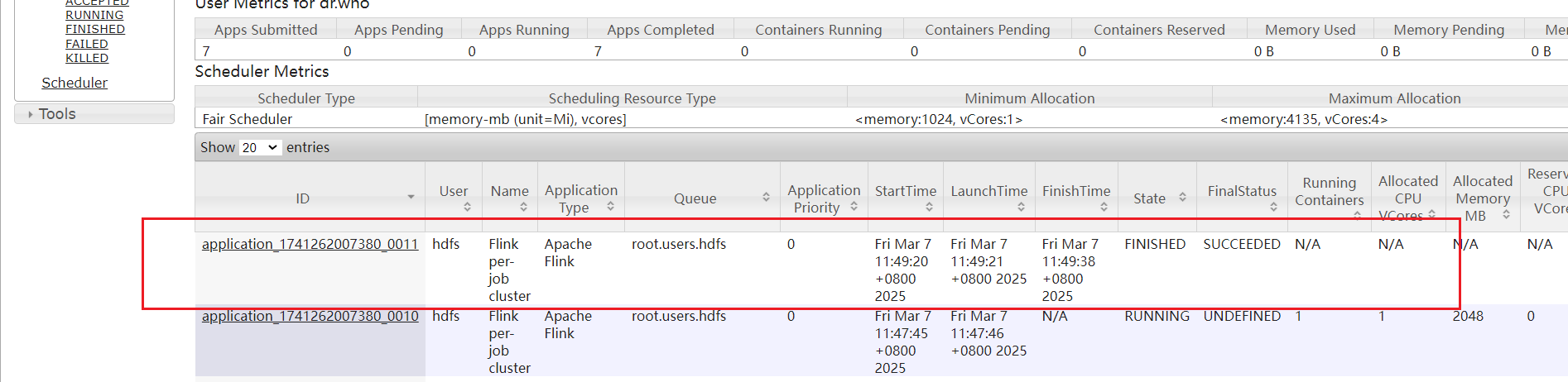
点击进入ResouceManager页面: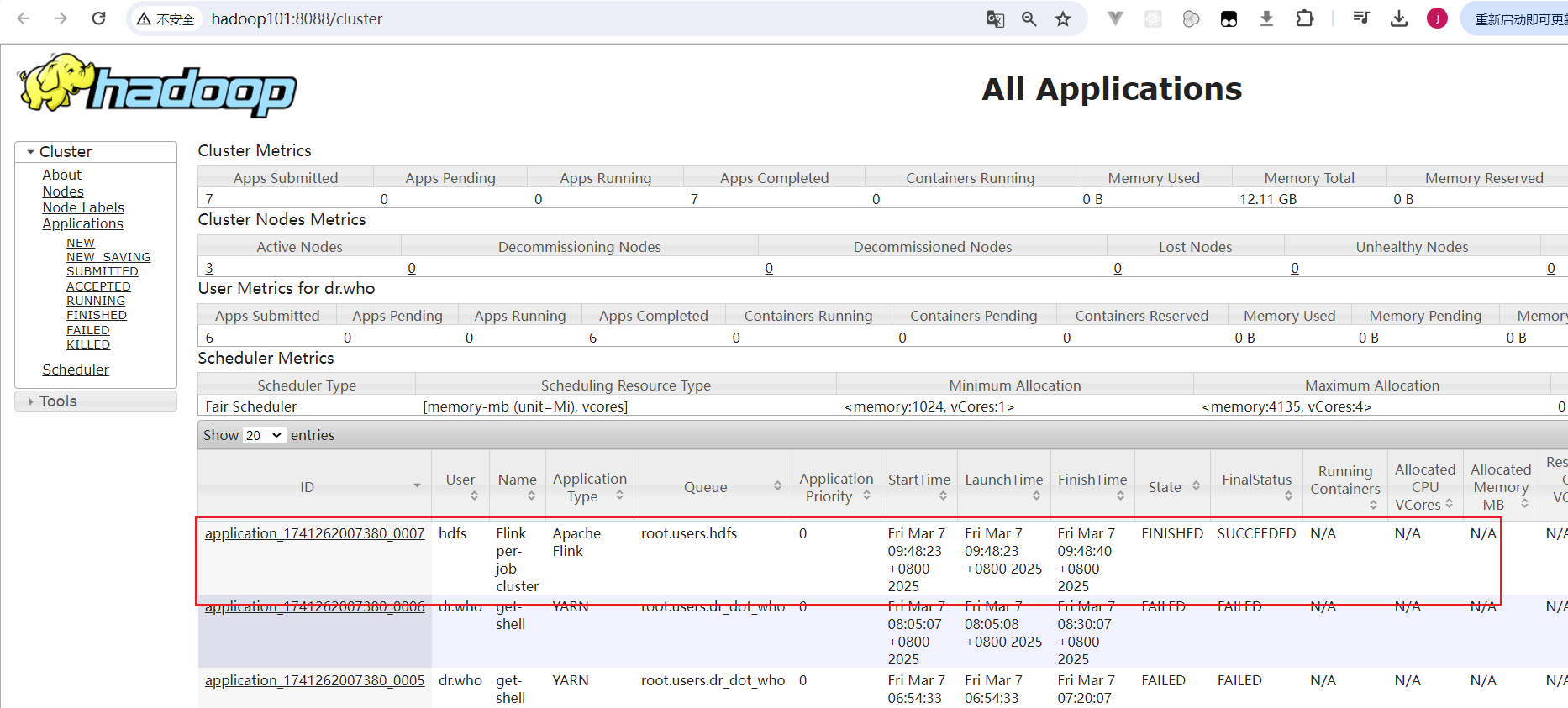 可以看到当前运行成功了Flink作业。
可以看到当前运行成功了Flink作业。
8.2 验证Hive_FlinkSQL
在hdfs上面上传hive-site.xml文件
## 需要hdfs用户具有管理权限操作
[root@hadoop101 ~]# vim /etc/passwd
## 将hdfs用户设置为可以登录: /sbin/nologin改为/bin/bash
hdfs:x:992:989:Hadoop HDFS:/var/lib/hadoop-hdfs:/bin/bash
[root@hadoop101 ~]# su - hdfs
[hdfs@hadoop101 ~]$ hadoop fs -mkdir /hiveconf/
[hdfs@hadoop101 ~]$ hadoop fs -put /etc/hive/conf.cloudera.hive/hive-site.xml /hiveconf/在hue中创建表t_user: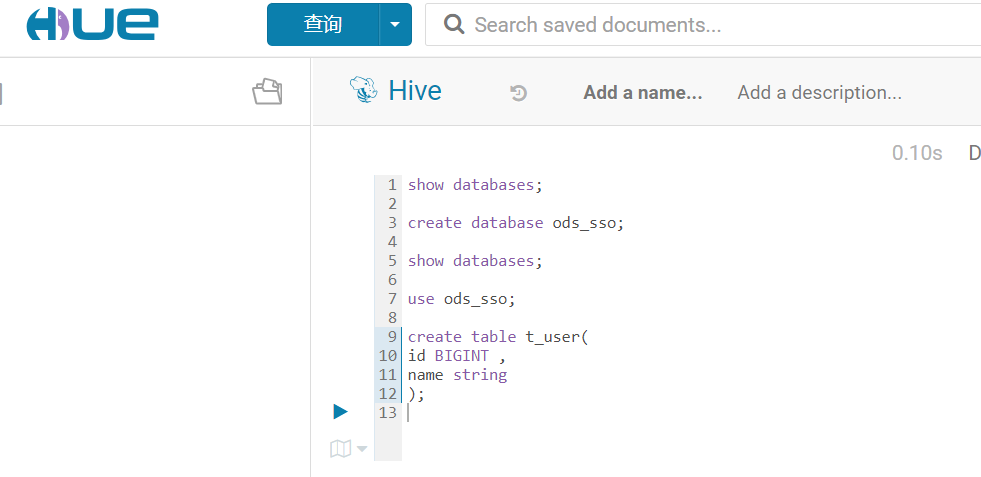 继续使用hdfs用户执行flink-sql-client命令行:
继续使用hdfs用户执行flink-sql-client命令行:
[root@hadoop101 ~]$ /opt/cloudera/parcels/FLINK/bin/flink-sql-client -s yarn-session 在交互命令窗口中进行操作:
在交互命令窗口中进行操作:
Flink SQL> CREATE CATALOG myhive WITH (
> 'type' = 'hive',
> 'hive-version'='2.1.1',
> 'default-database' = 'default',
> 'hive-conf-dir' = 'hdfs://hadoop101:8020/hiveconf/'
> );
[INFO] Execute statement succeed.
Flink SQL> show catalogs;
+-----------------+
| catalog name |
+-----------------+
| default_catalog |
| myhive |
+-----------------+
2 rows in set
Flink SQL> USE CATALOG myhive;
[INFO] Execute statement succeed.
Flink SQL> show tables;
+------------+
| table name |
+------------+
| t_user |
+------------+
1 row in set
Flink SQL> insert into t_user values(1001, 'jack');
[INFO] Submitting SQL update statement to the cluster...
2025-03-07 11:47:43,694 WARN org.apache.flink.yarn.configuration.YarnLogConfigUtil [] - The configuration directory ('/etc/flink/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
2025-03-07 11:47:43,835 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2025-03-07 11:47:43,892 INFO org.apache.hadoop.conf.Configuration [] - resource-types.xml not found
2025-03-07 11:47:43,892 INFO org.apache.hadoop.yarn.util.resource.ResourceUtils [] - Unable to find 'resource-types.xml'.
2025-03-07 11:47:43,921 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Cluster specification: ClusterSpecification{masterMemoryMB=2048, taskManagerMemoryMB=2048, slotsPerTaskManager=1}
2025-03-07 11:47:45,879 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Submitting application master application_1741262007380_0010
2025-03-07 11:47:46,109 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl [] - Submitted application application_1741262007380_0010
2025-03-07 11:47:46,109 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Waiting for the cluster to be allocated
2025-03-07 11:47:46,110 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Deploying cluster, current state ACCEPTED
2025-03-07 11:47:51,641 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - YARN application has been deployed successfully.
2025-03-07 11:47:51,642 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface hadoop103:8080 of application 'application_1741262007380_0010'.
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: 77f07cc61645af7f38ffddc8419021f1
Flink SQL> SET sql-client.execution.result-mode=tableau;
[INFO] Session property has been set.
Flink SQL> select * from t_user;
2025-03-07 11:49:18,997 INFO org.apache.hadoop.mapred.FileInputFormat [] - Total input files to process : 1
2025-03-07 11:49:19,146 WARN org.apache.flink.yarn.configuration.YarnLogConfigUtil [] - The configuration directory ('/etc/flink/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
2025-03-07 11:49:19,162 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2025-03-07 11:49:19,167 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Cluster specification: ClusterSpecification{masterMemoryMB=2048, taskManagerMemoryMB=2048, slotsPerTaskManager=1}
2025-03-07 11:49:20,848 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Submitting application master application_1741262007380_0011
2025-03-07 11:49:21,054 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl [] - Submitted application application_1741262007380_0011
2025-03-07 11:49:21,054 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Waiting for the cluster to be allocated
2025-03-07 11:49:21,055 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Deploying cluster, current state ACCEPTED
2025-03-07 11:49:26,079 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - YARN application has been deployed successfully.
2025-03-07 11:49:26,079 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface hadoop103:8081 of application 'application_1741262007380_0011'.
+----+----------------------+--------------------------------+
| op | id | name |
+----+----------------------+--------------------------------+
| +I | 1001 | jack |
+----+----------------------+--------------------------------+
Received a total of 1 row访问http://hadoop101:8088,可以看到刚才执行了一个flink任务: