添加大数据组件
1. 添加HDFS\YARN\ZooKeeper
- 集群设置好后自动进入集群设置页面,在页面中选择自定义:
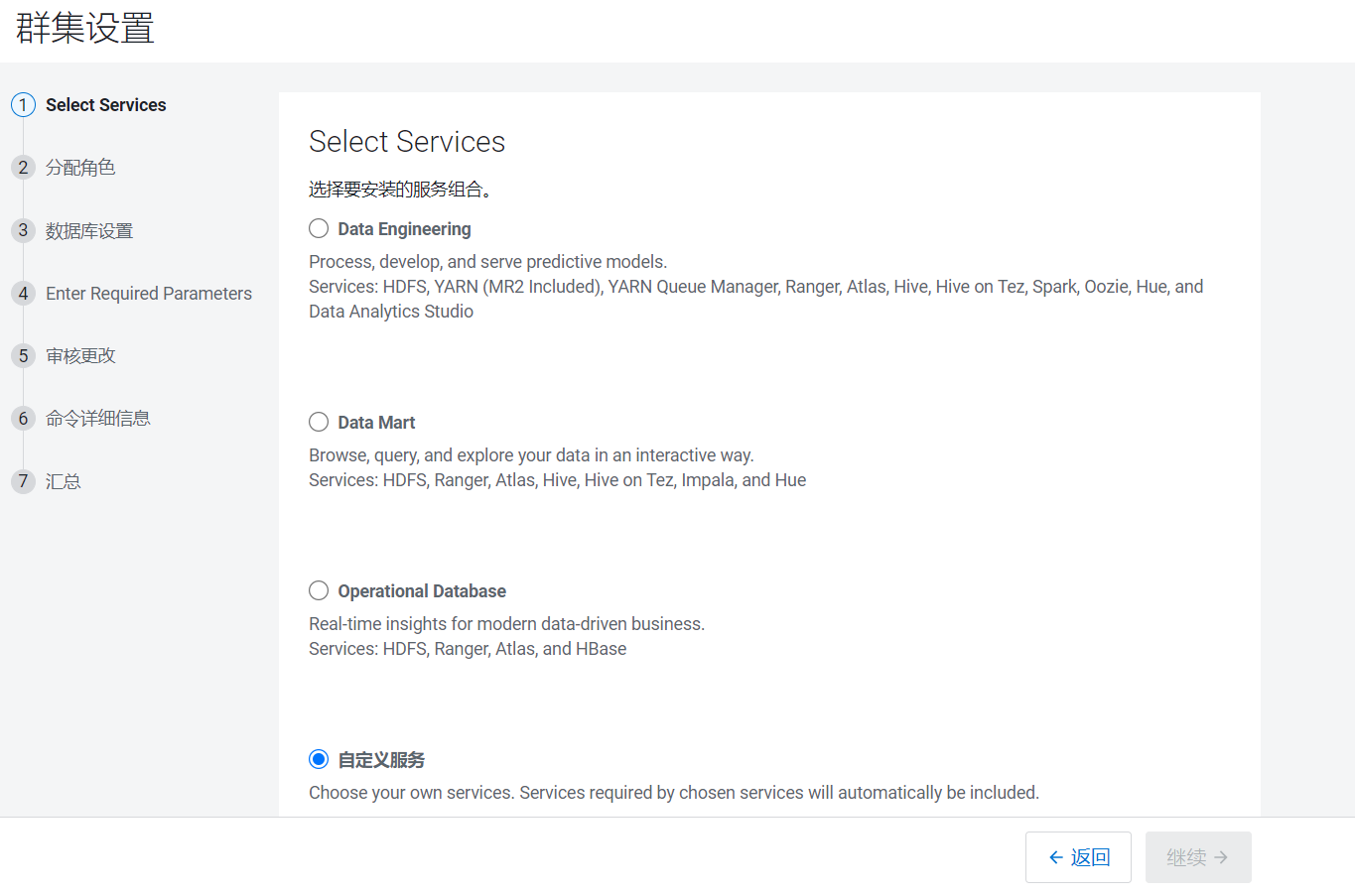
- 选择HDFS\YARN\ZooKeeper组件,点击继续:
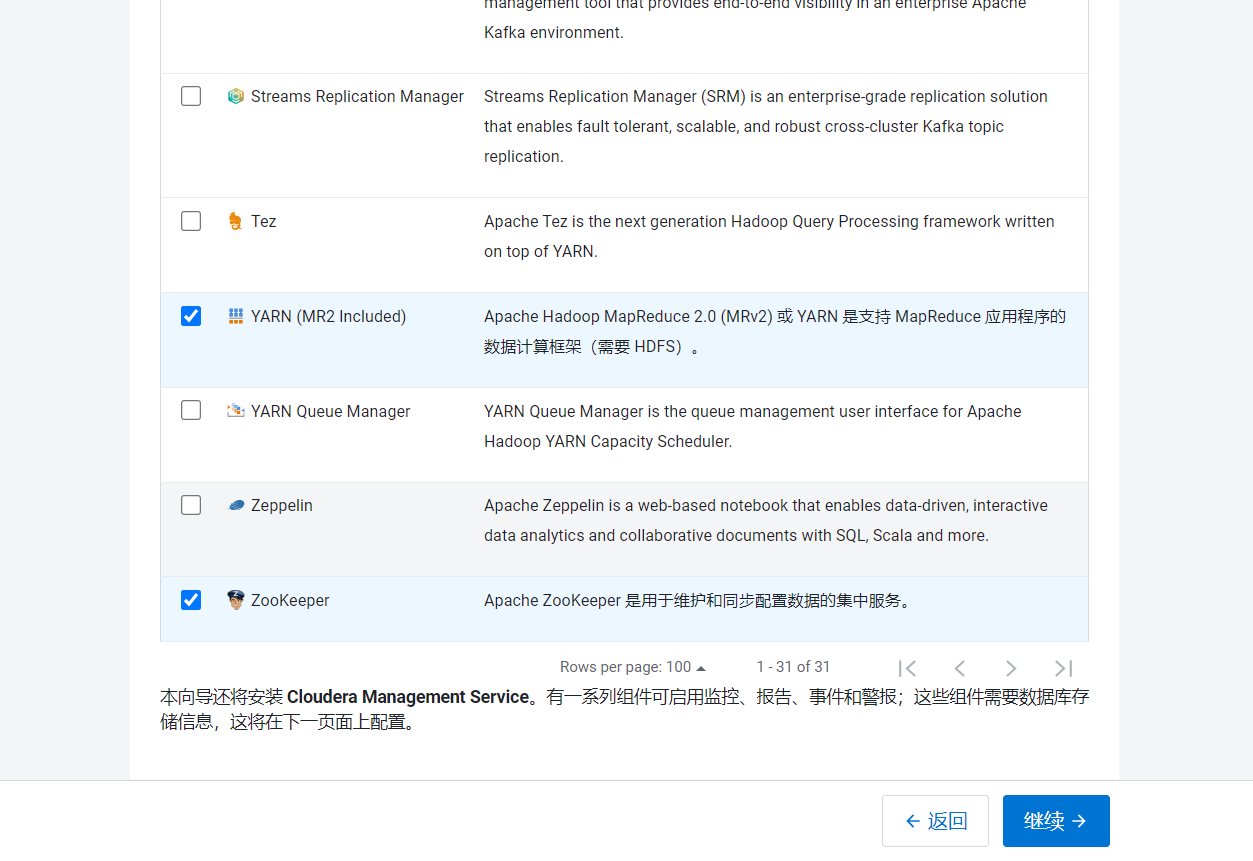
- 进入分配角色页面:
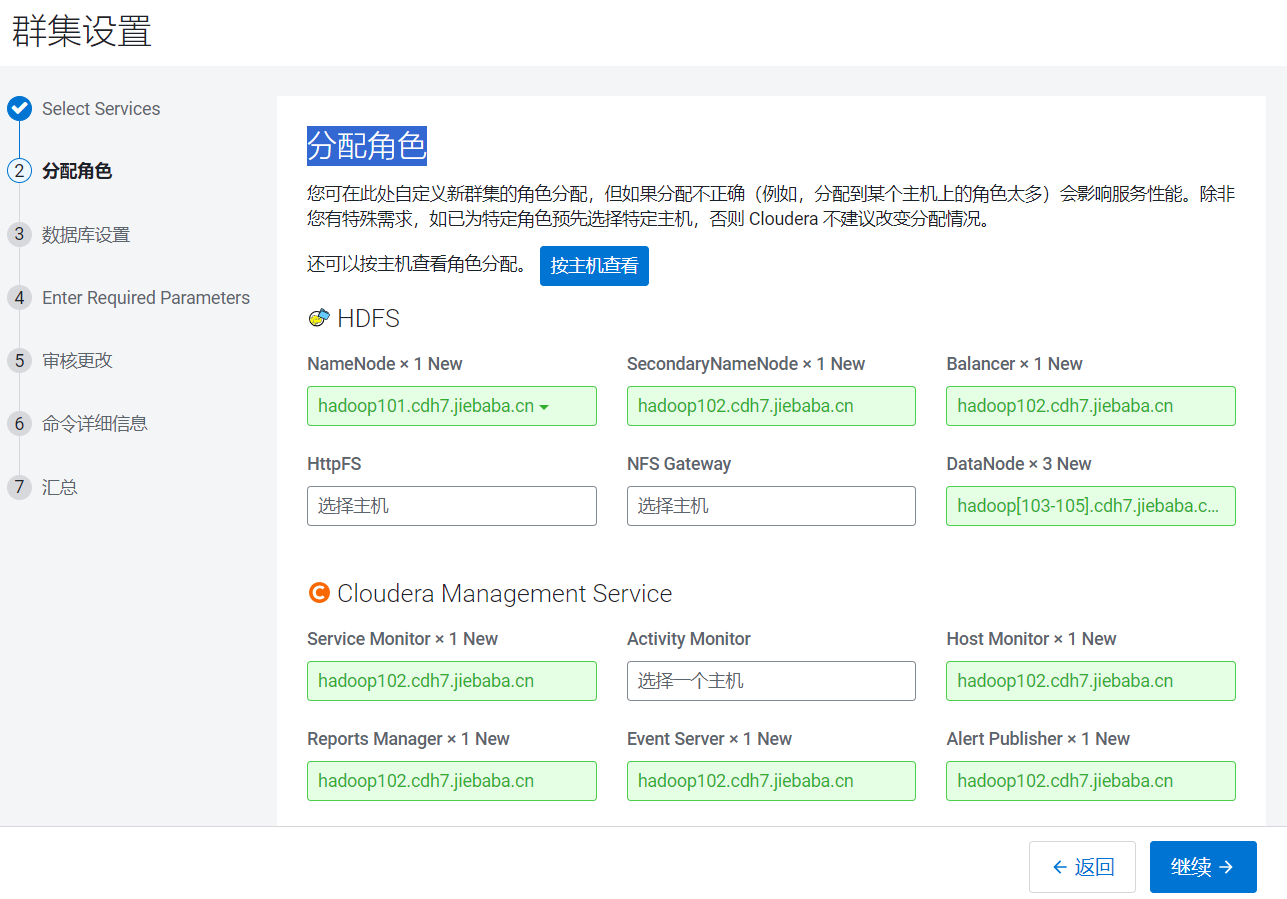
- 分配HDFS组件节点的情况:
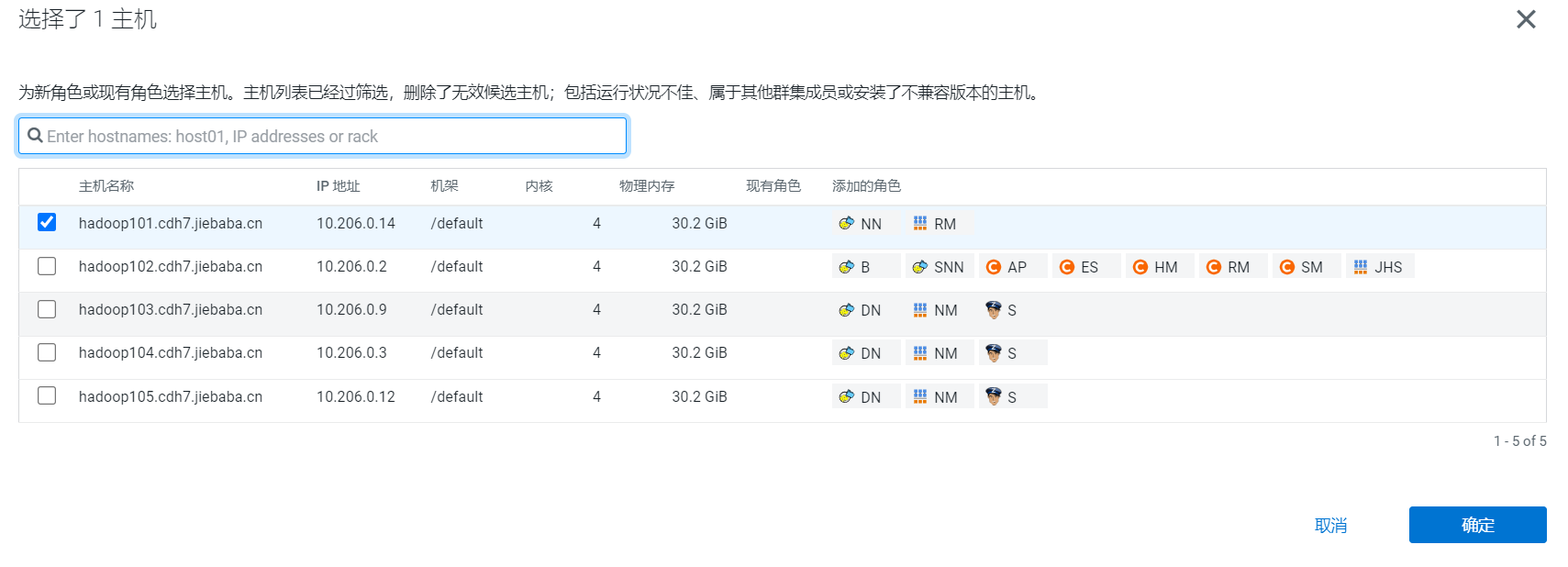
| hadoop101 | hadoop102 | hadoop103 | hadoop104 | hadoop105 |
|---|---|---|---|---|
| namenode | secondnamenode | datanode | datanode | datanode |
- 设置Yarn组件的情况:
| hadoop101 | hadoop102 | hadoop103 | hadoop104 | hadoop105 |
|---|---|---|---|---|
| resourcemanager | historyserver | nodemanager | nodemanager | nodemanager |
- 设置Zookeeper组件的情况:
| hadoop101 | hadoop102 | hadoop103 | hadoop104 | hadoop105 |
|---|---|---|---|---|
| zk | zk | zk |
Cloudera Management Service提供一些监控服务,就都安装在hadoop102上面。点击继续,没什么可以提供配置的,直接点击继续:  参数配置,可以后面修改,点击继续:
参数配置,可以后面修改,点击继续: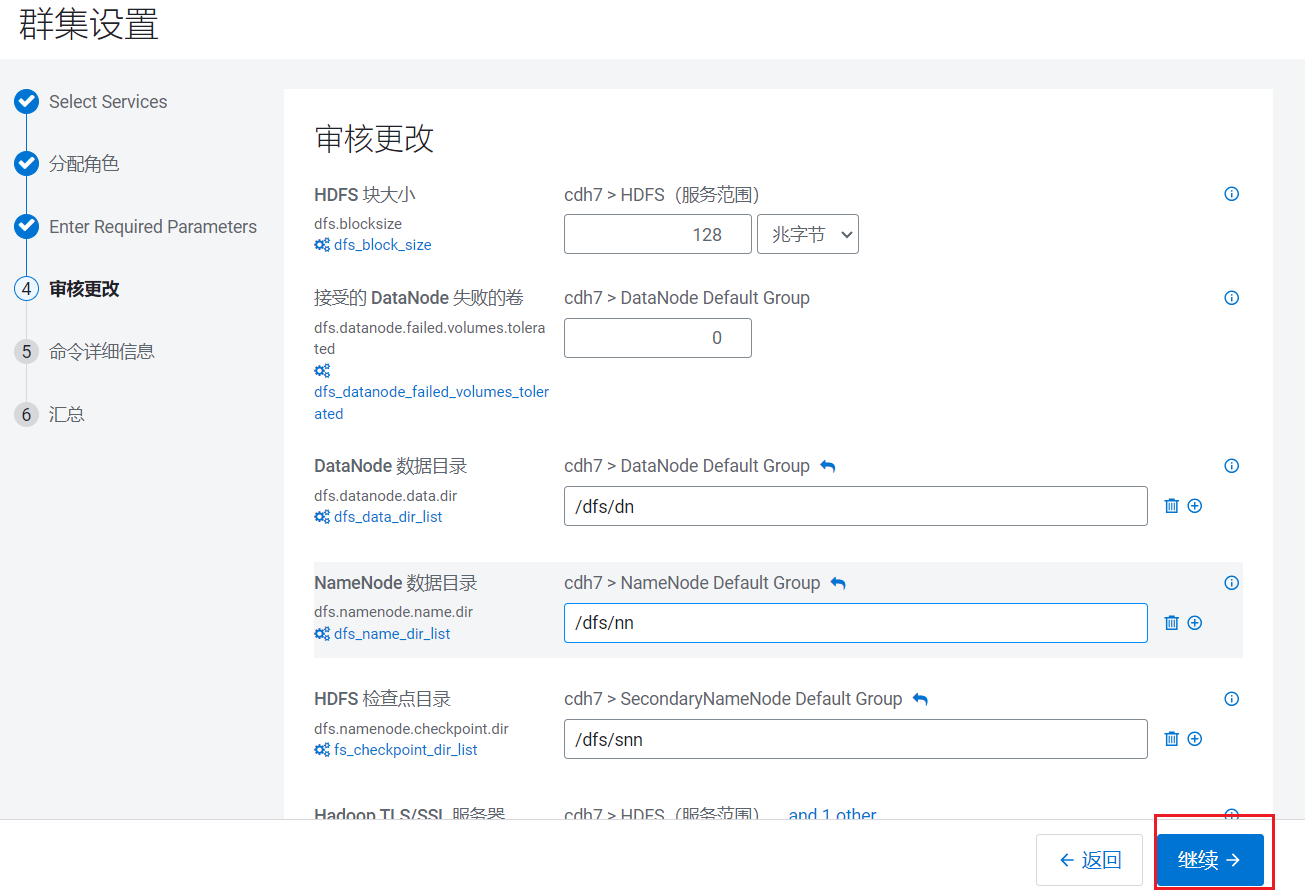 组件就开始了进行安装,CDH底层也是通过封装脚本进行安装的。
组件就开始了进行安装,CDH底层也是通过封装脚本进行安装的。 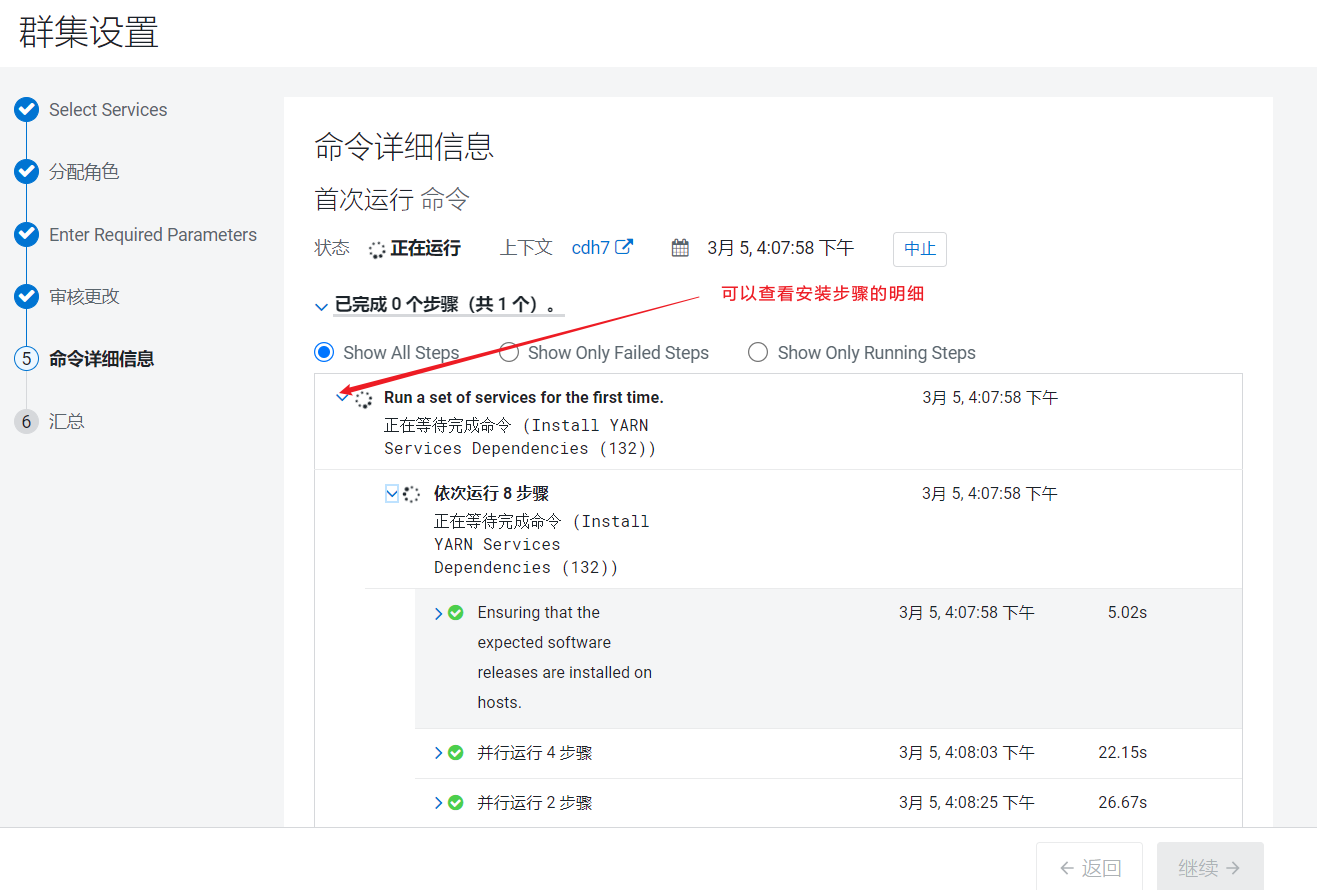 安装完成后会自动启动进程,点击后进入首页:
安装完成后会自动启动进程,点击后进入首页:
2. 处理CDH错误
Cloudera Management Service提醒有两个问题需要处理: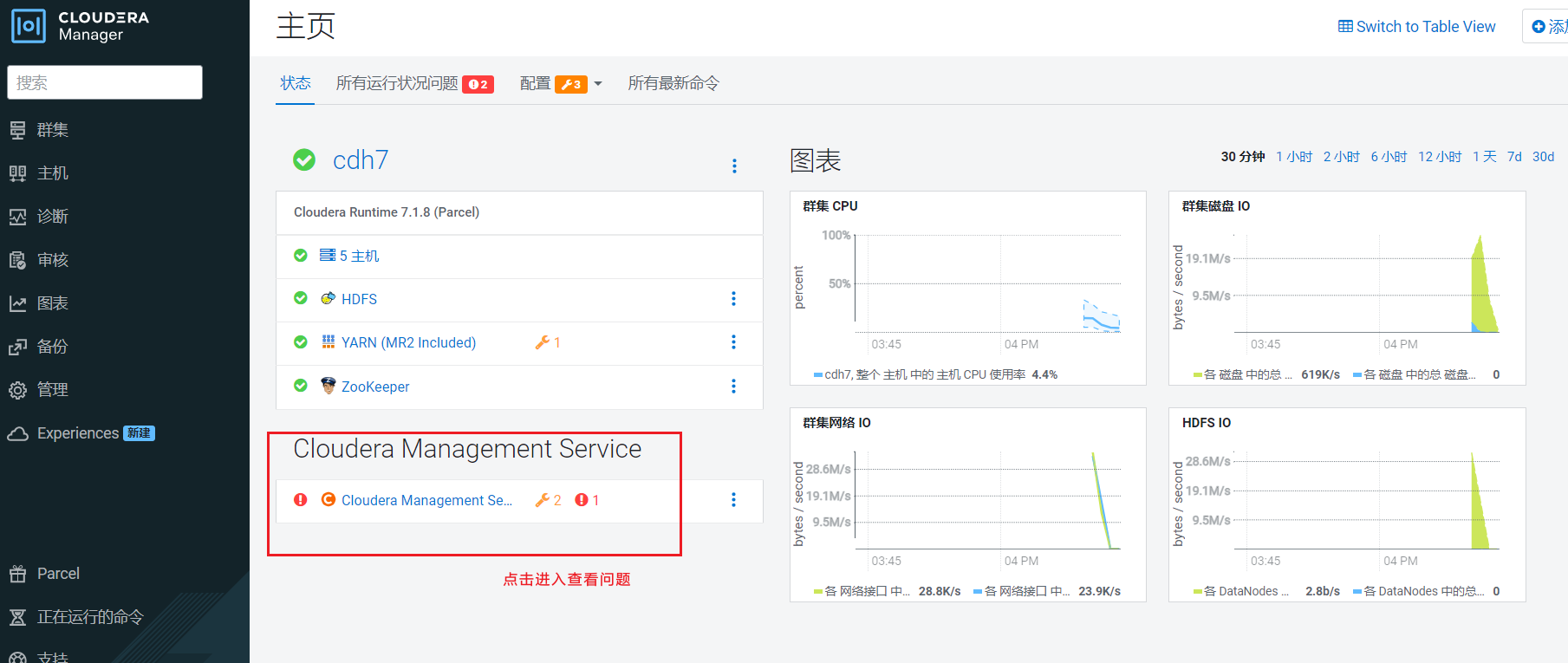 点击问题后弹出框,如果不处理就点击supress表示关闭这类错误提示
点击问题后弹出框,如果不处理就点击supress表示关闭这类错误提示 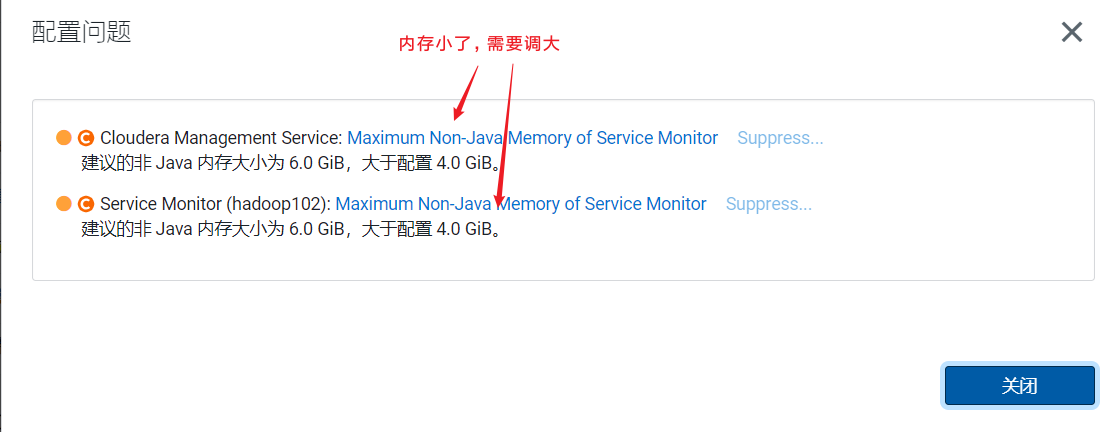 我们点击小扳手图标,进行设置Java内存使用大小:
我们点击小扳手图标,进行设置Java内存使用大小: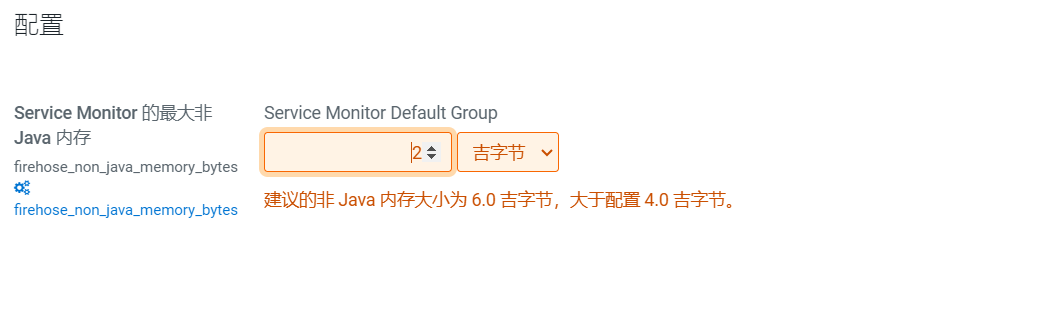 CDH页面很友好,可以直接修改:
CDH页面很友好,可以直接修改: 点击保存更改。首页提示需要重启生效,点击电源图标,进入确定重启页面:
点击保存更改。首页提示需要重启生效,点击电源图标,进入确定重启页面: 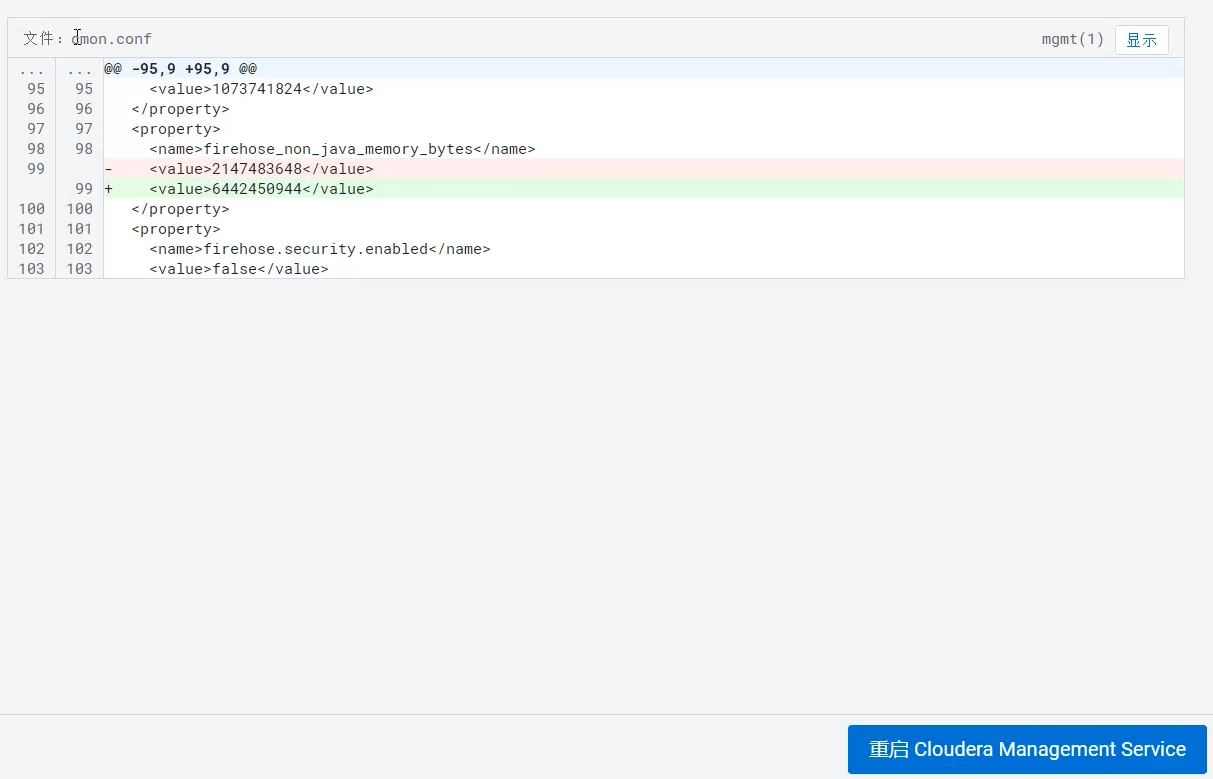
3. 配置NameNode的HA
HDFS是整个大数据框架的数据存储的部分,数据如果丢失不像Yarn资源调度失败了再重新启动点击HDFS简单,需要配置HDFS的高可用,点击HDFS, 进入HDFS组件页面: 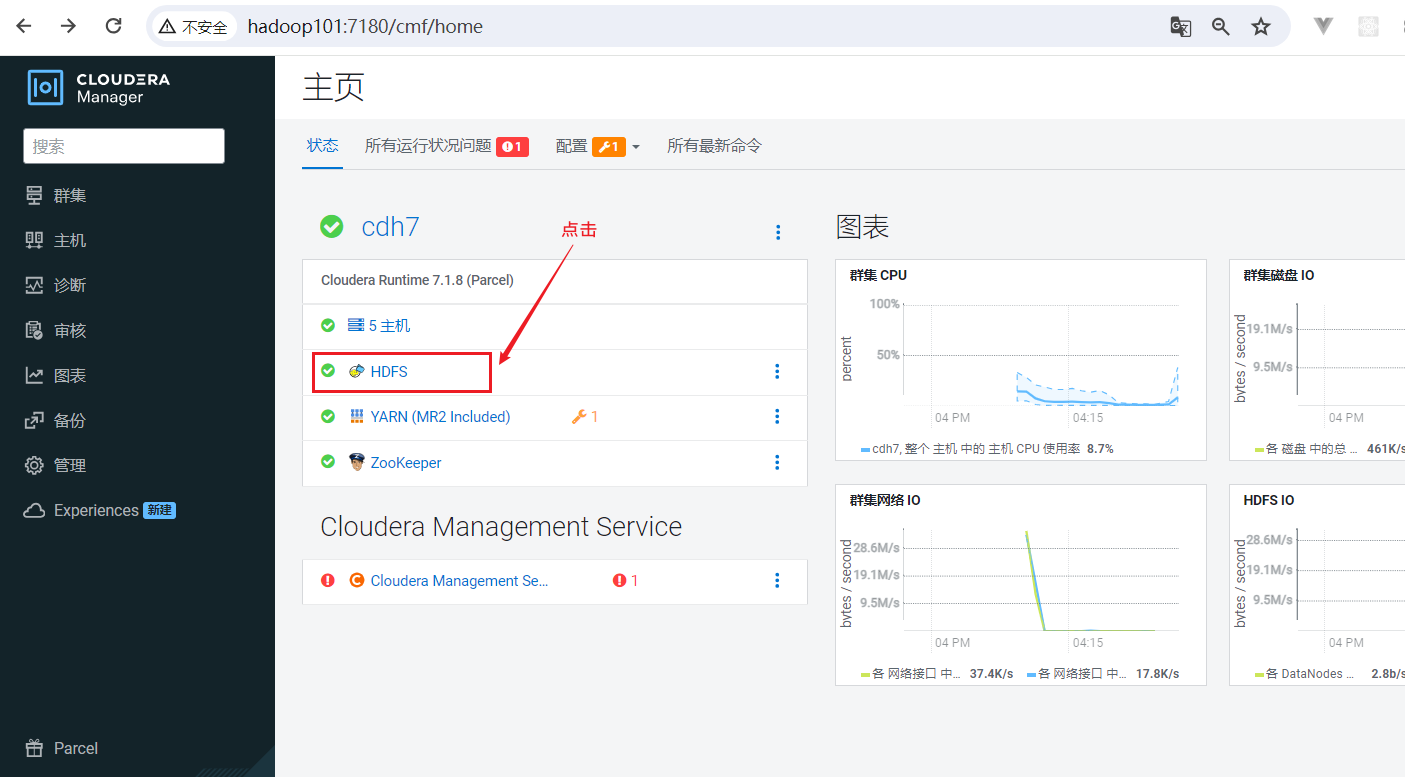 进入HDFS页面点击启用High Availability:
进入HDFS页面点击启用High Availability: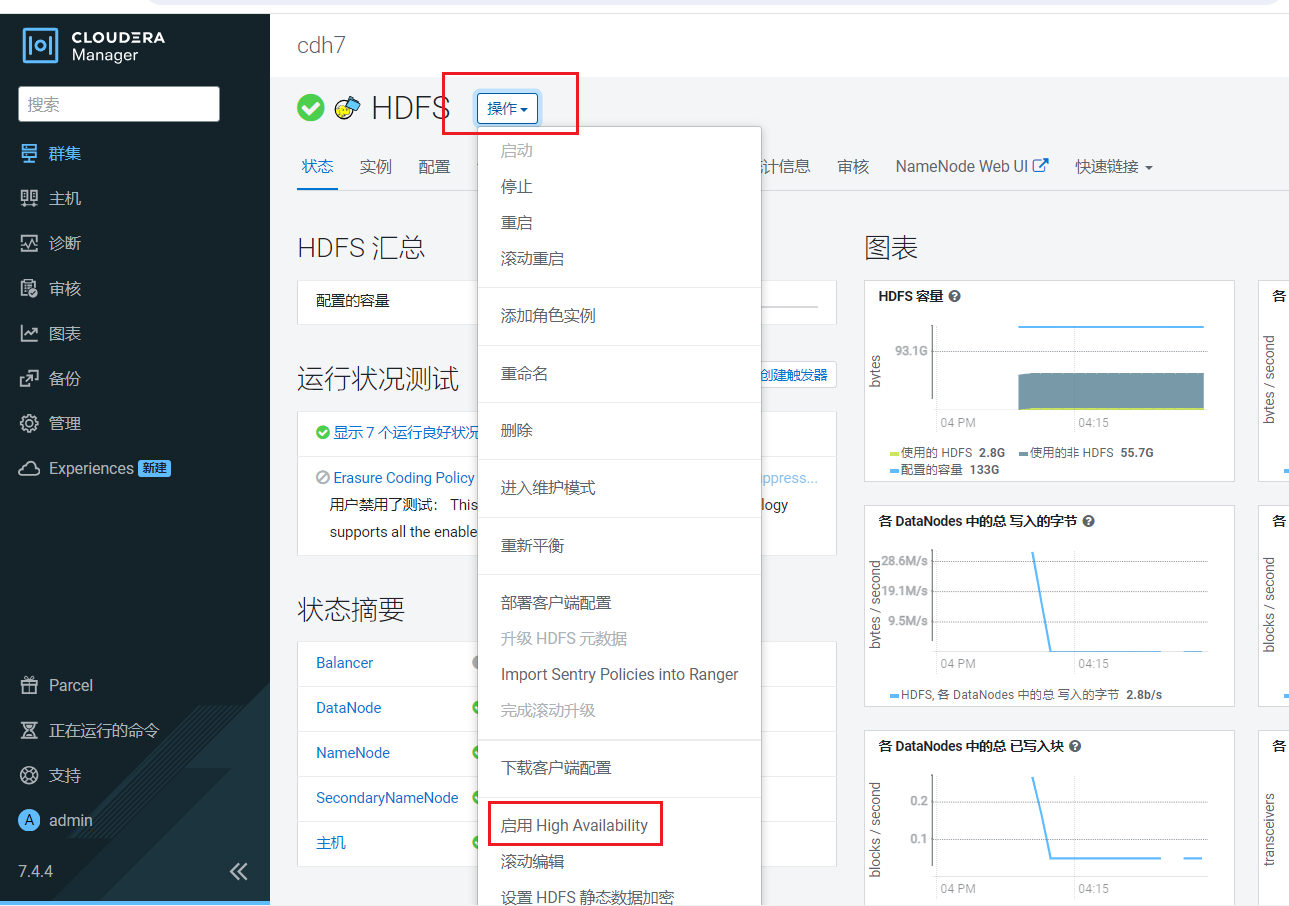 这里需要配置一个命名空间,主要用来区分主NameNode和Standby的NameNode,使用默认,点击继续:
这里需要配置一个命名空间,主要用来区分主NameNode和Standby的NameNode,使用默认,点击继续: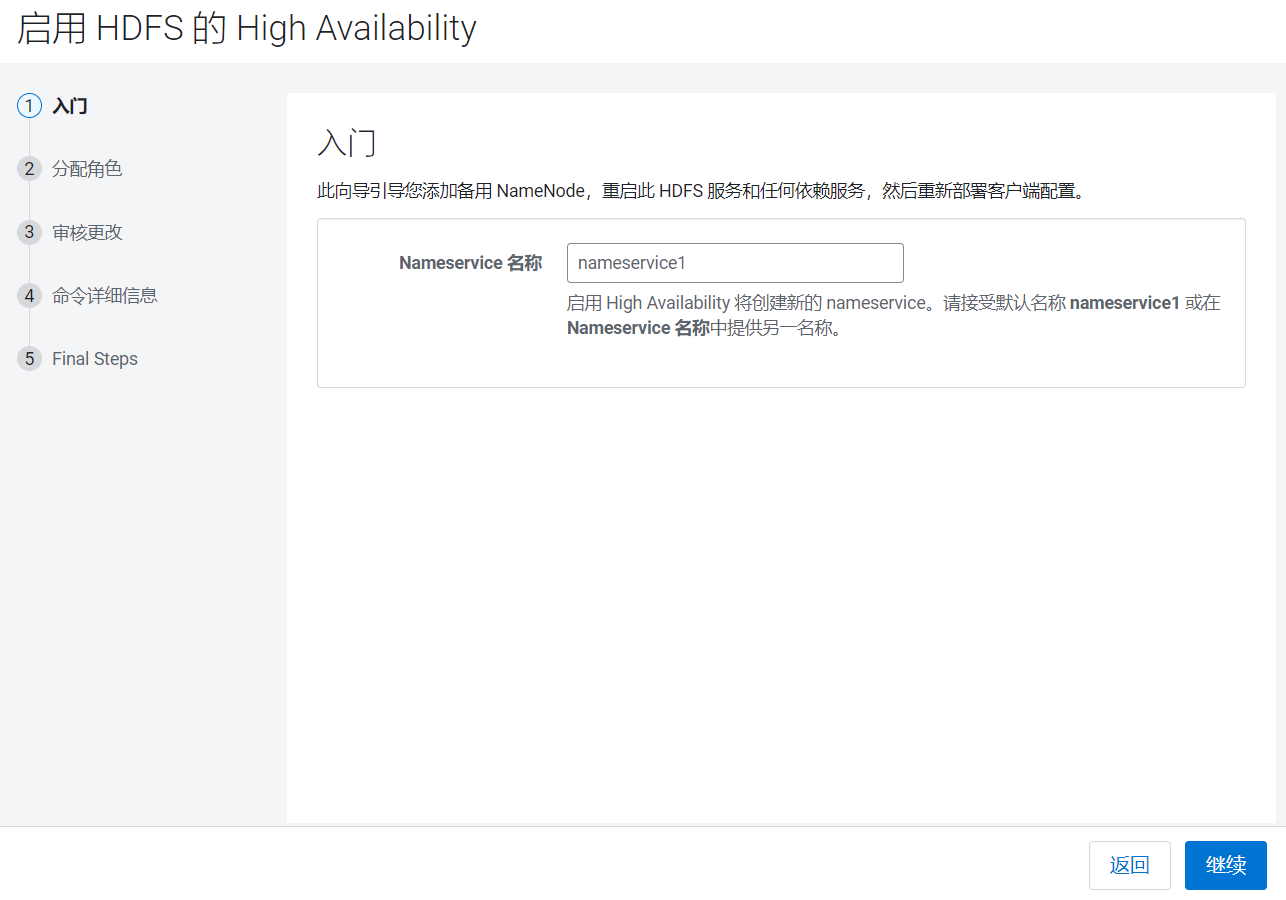 设置Standby的NameNode为hadoop102,JournalNode为hadoop103~105, 点击继续:
设置Standby的NameNode为hadoop102,JournalNode为hadoop103~105, 点击继续: 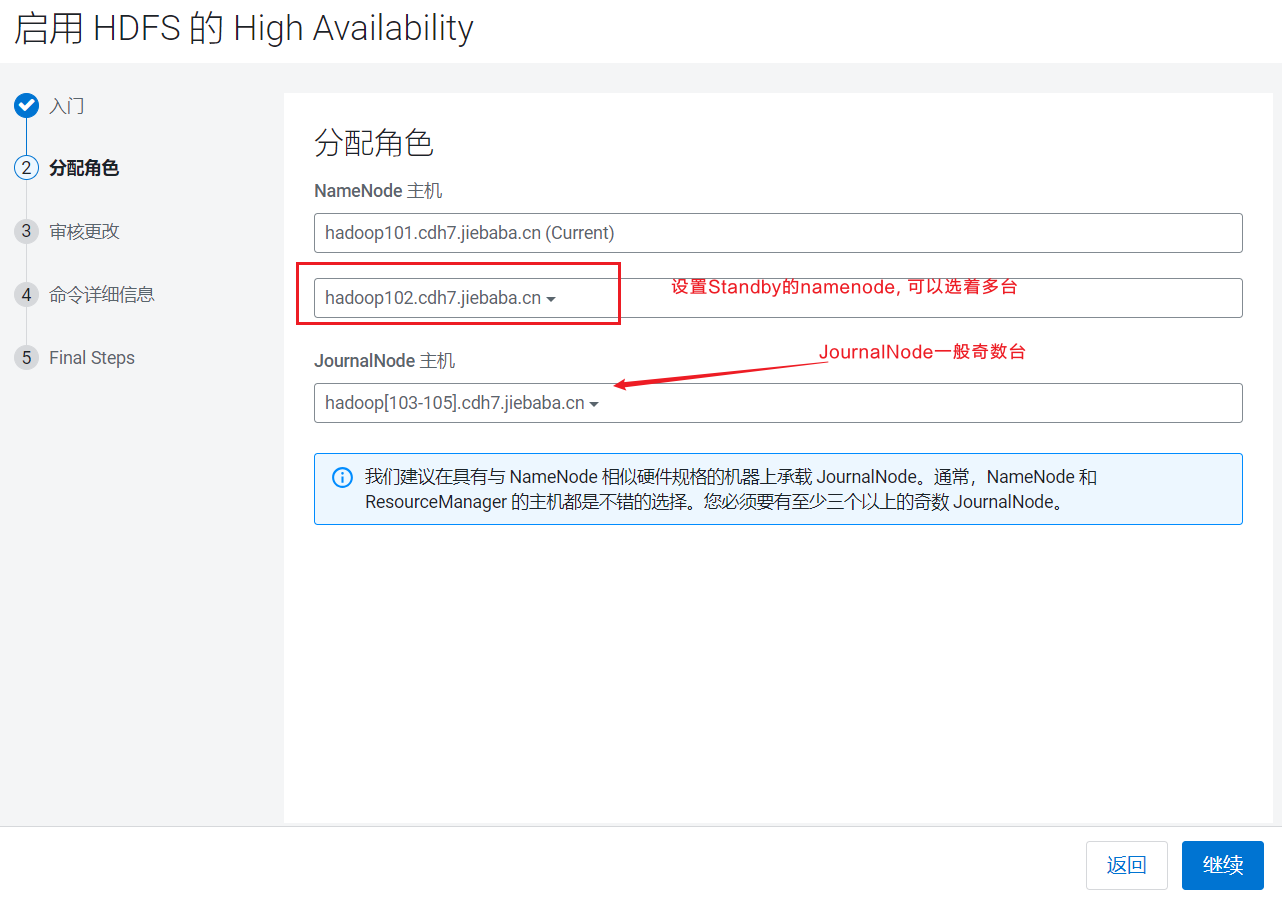 设置JournalNode的读写目录:
设置JournalNode的读写目录: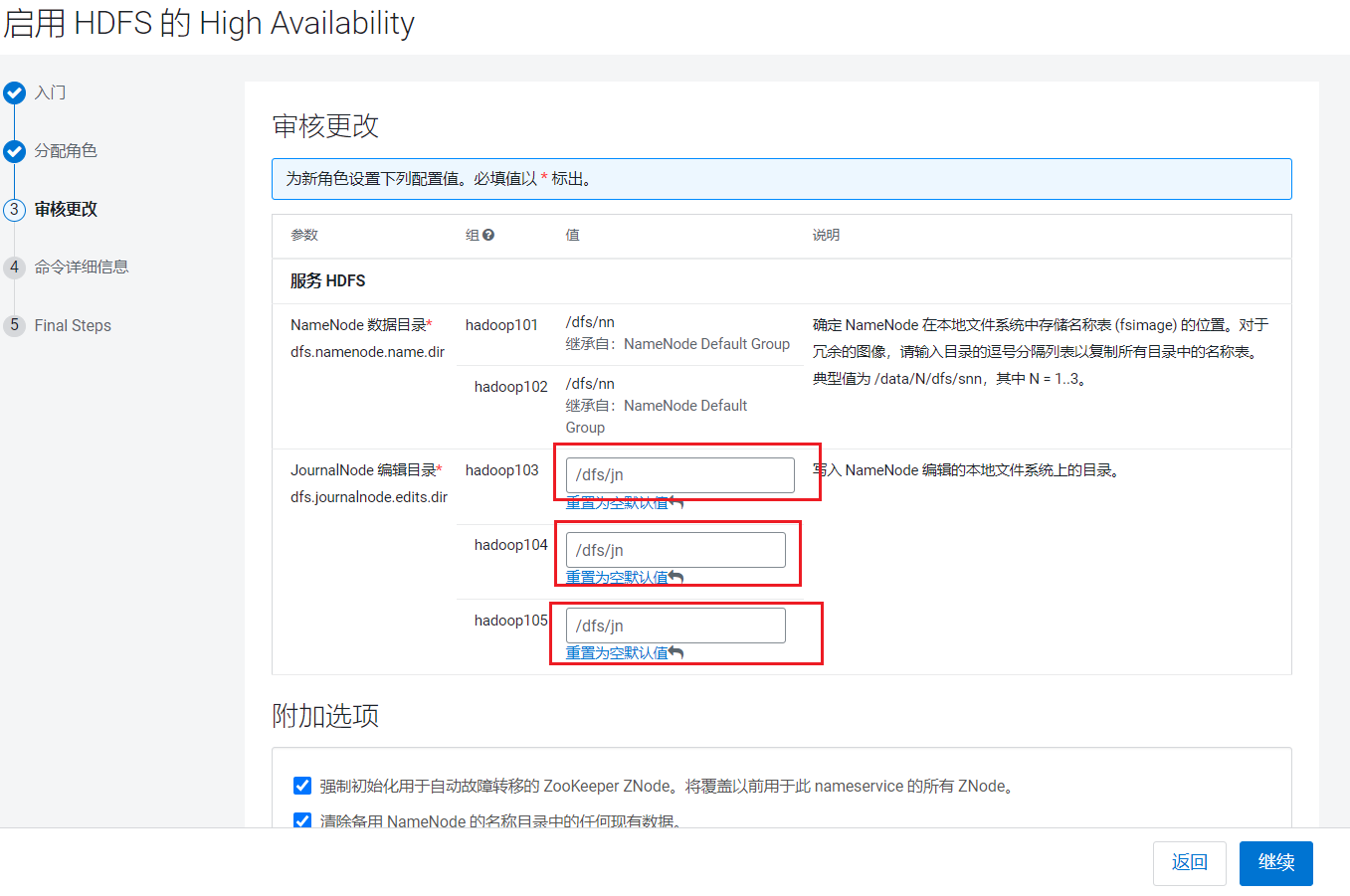 点击继续后,CDH就开始启动Standby的NameNode和JournalNode
点击继续后,CDH就开始启动Standby的NameNode和JournalNode 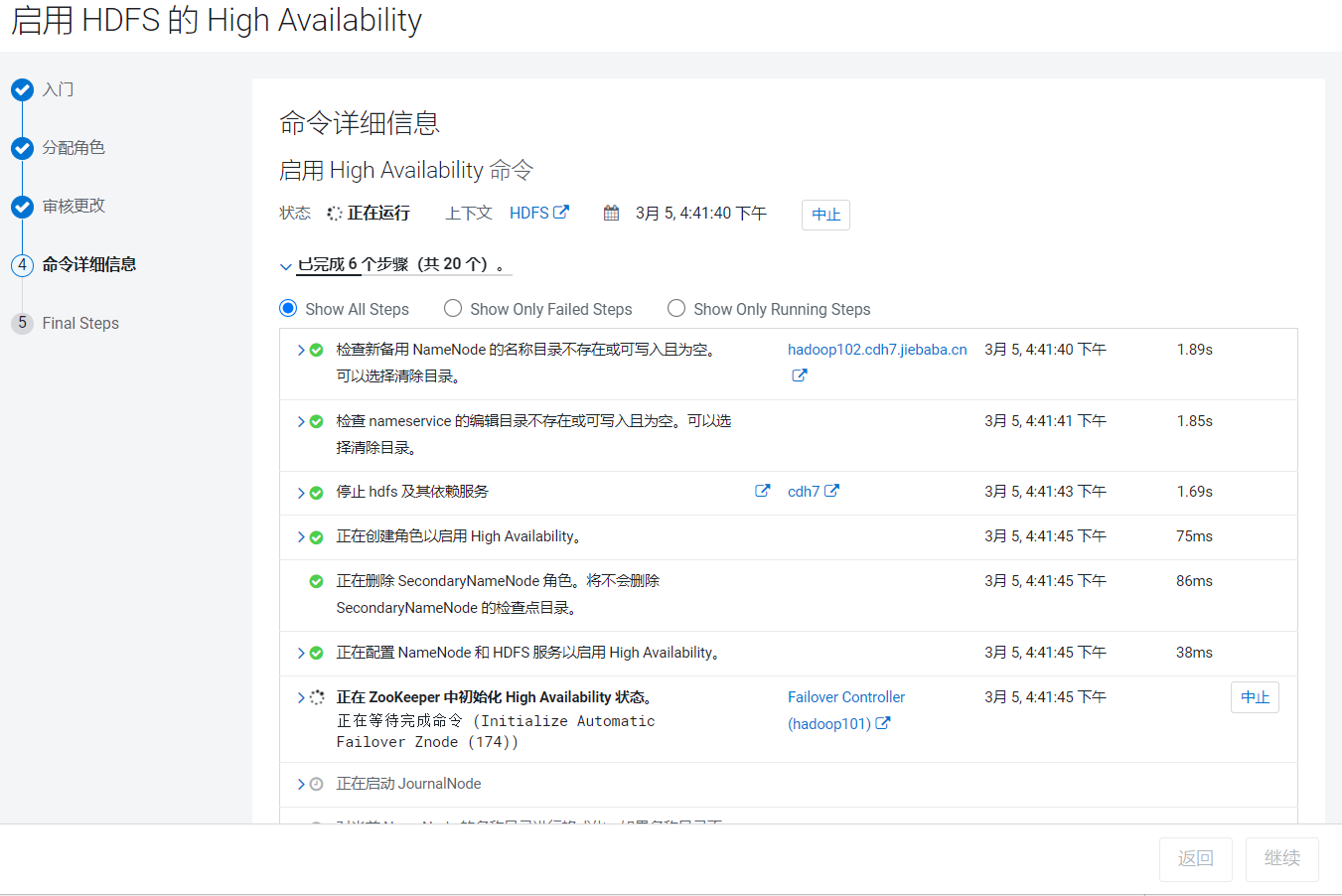 等待一会儿安装完成:
等待一会儿安装完成: 点击HDFS组件页面中的实例页面,可以看到主备的NameNode:
点击HDFS组件页面中的实例页面,可以看到主备的NameNode: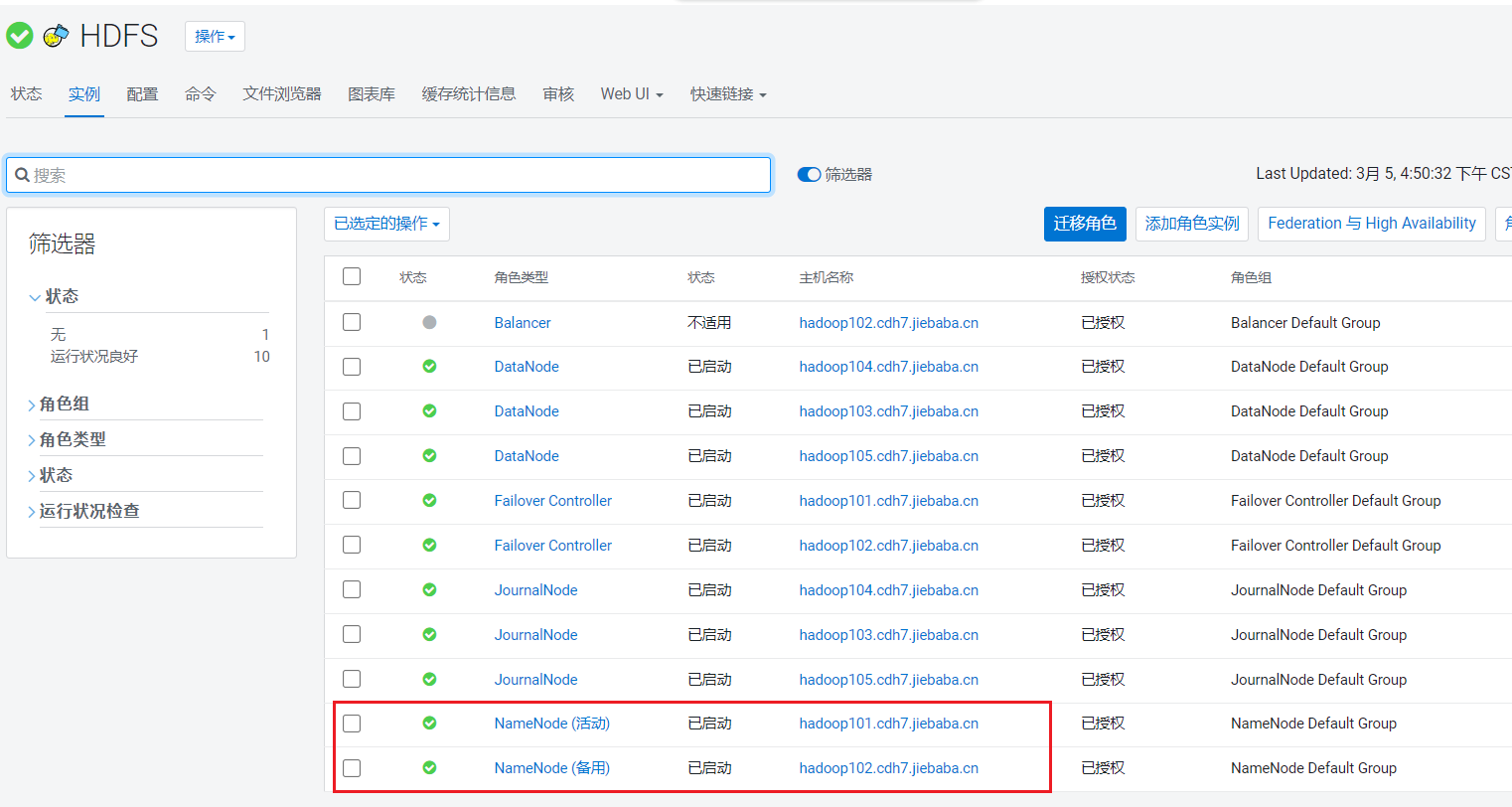 访问http://hadoop101:9870/,即可访问HDFS的webui:
访问http://hadoop101:9870/,即可访问HDFS的webui: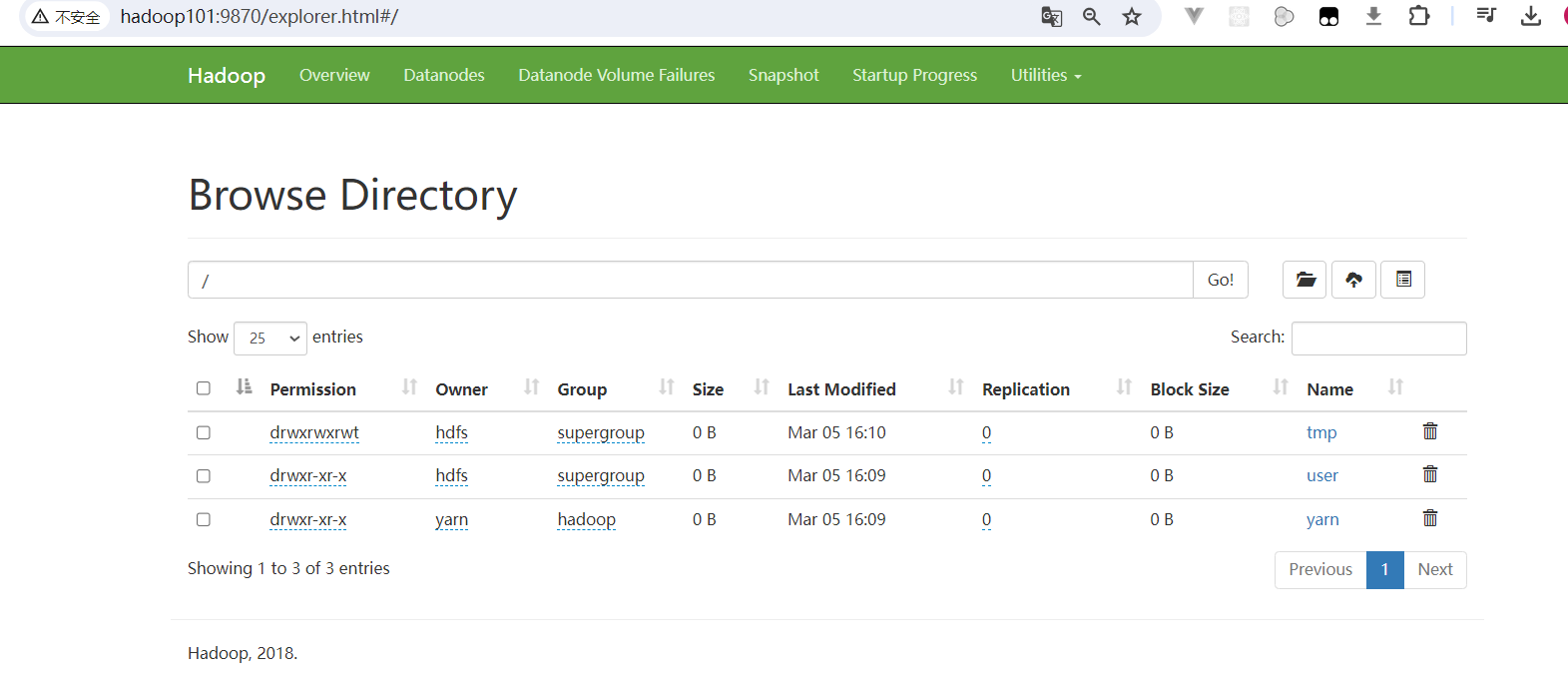
4. 配置Yarn的HA
点击YARN, 进入YARN组件页面, 点击操作: 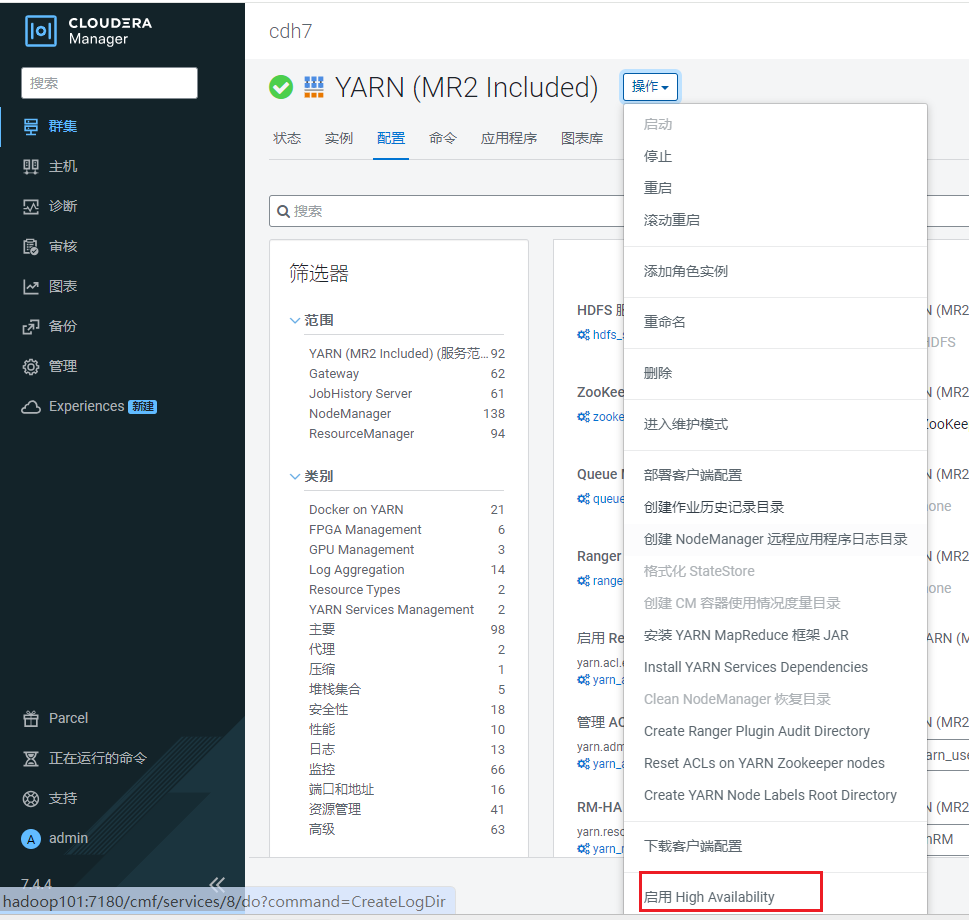 点击启用High Availability:
点击启用High Availability: 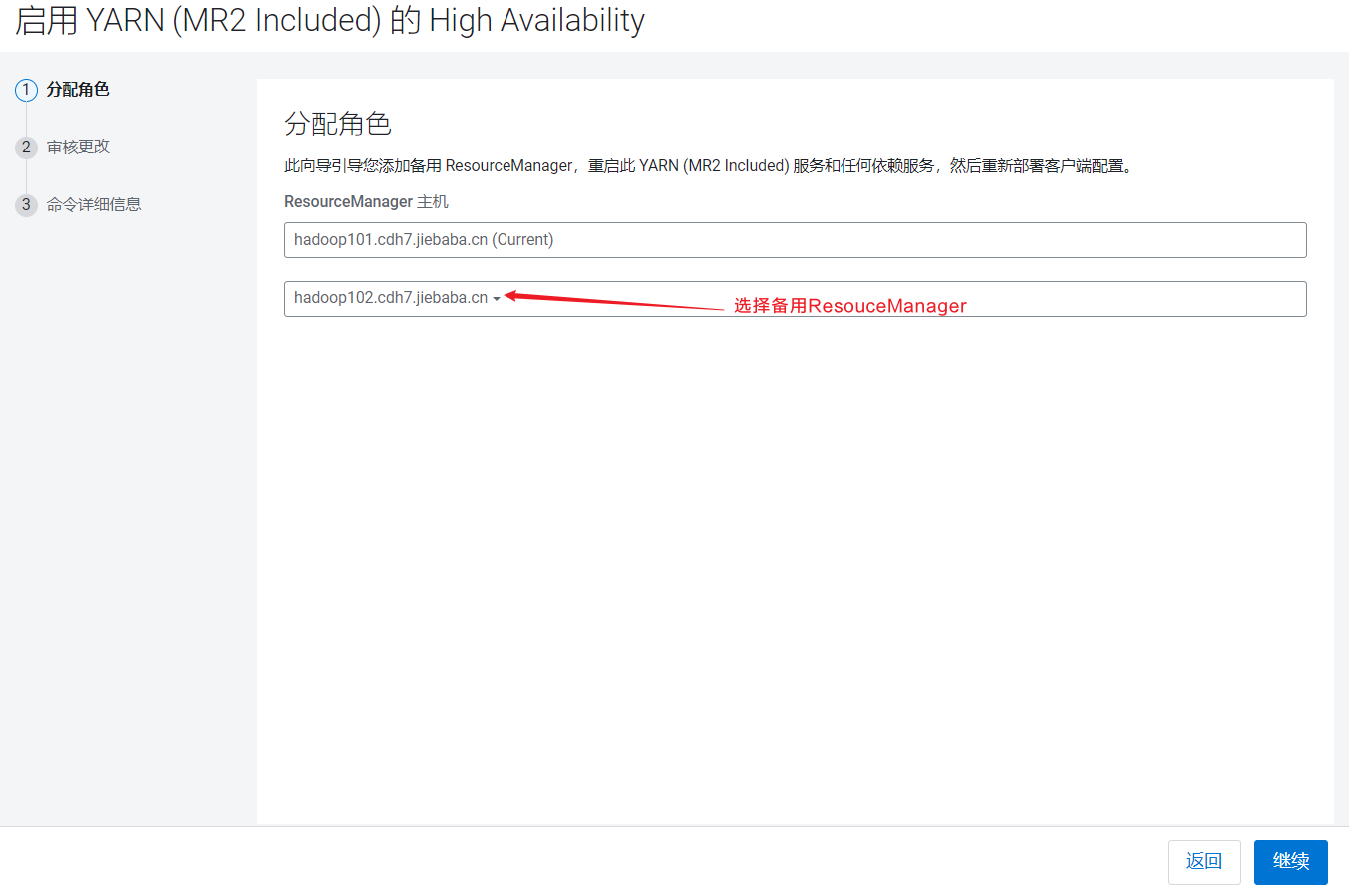 点击继续就开始安装:
点击继续就开始安装: 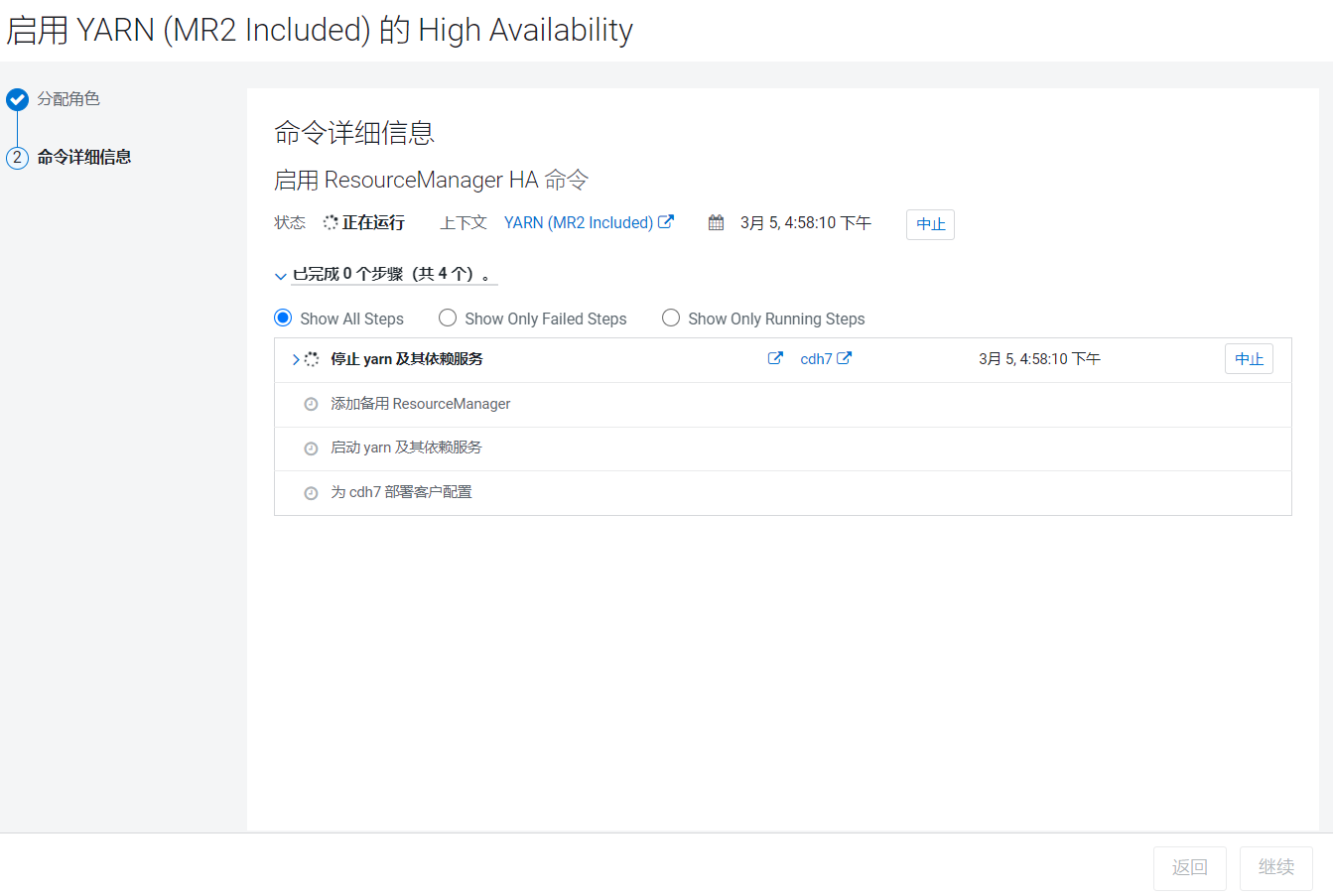 Yarn的高可用是通过多线程实现的,比较轻量级,比较快就安装好了。
Yarn的高可用是通过多线程实现的,比较轻量级,比较快就安装好了。 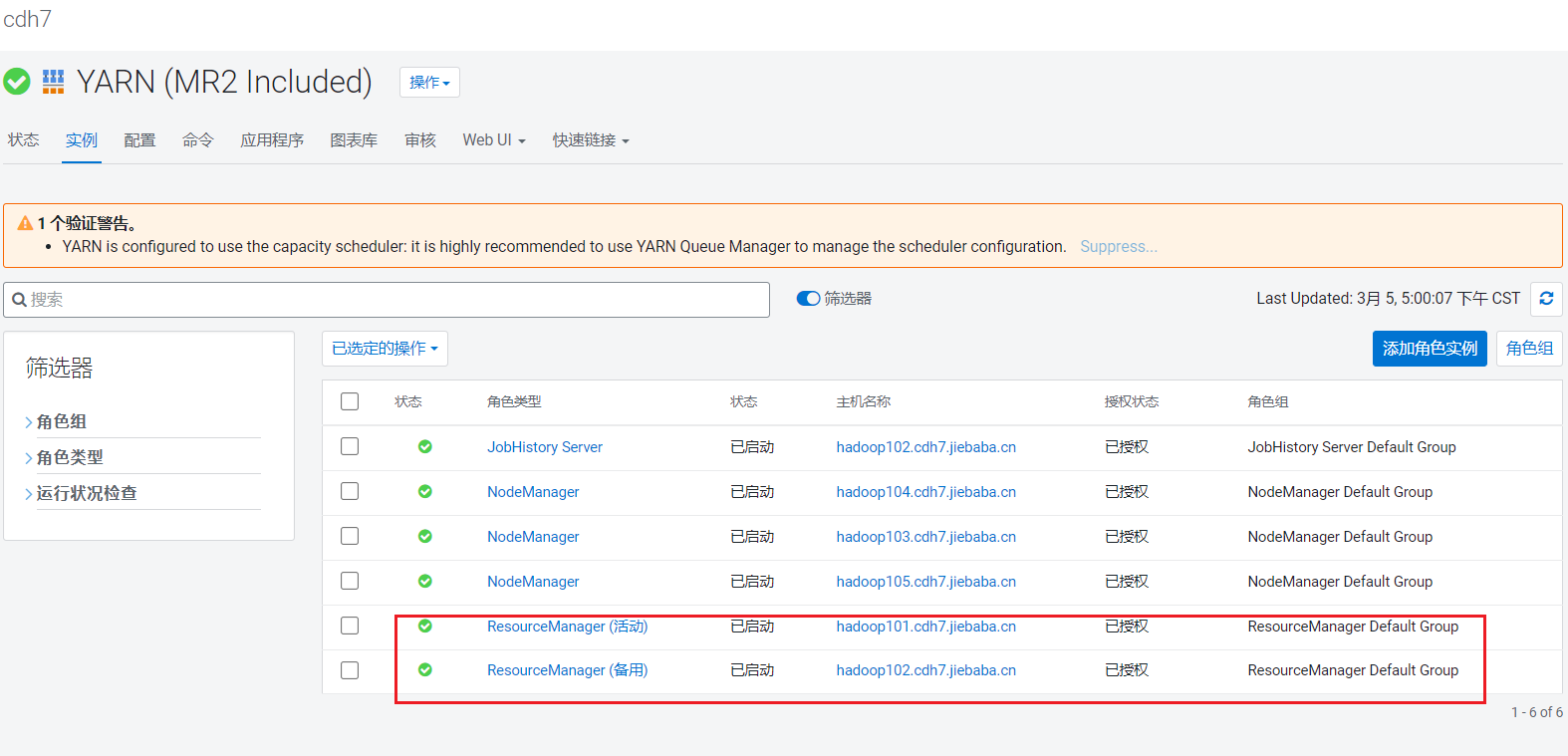
5. Kafka安装
点击首页的操作,点击添加服务: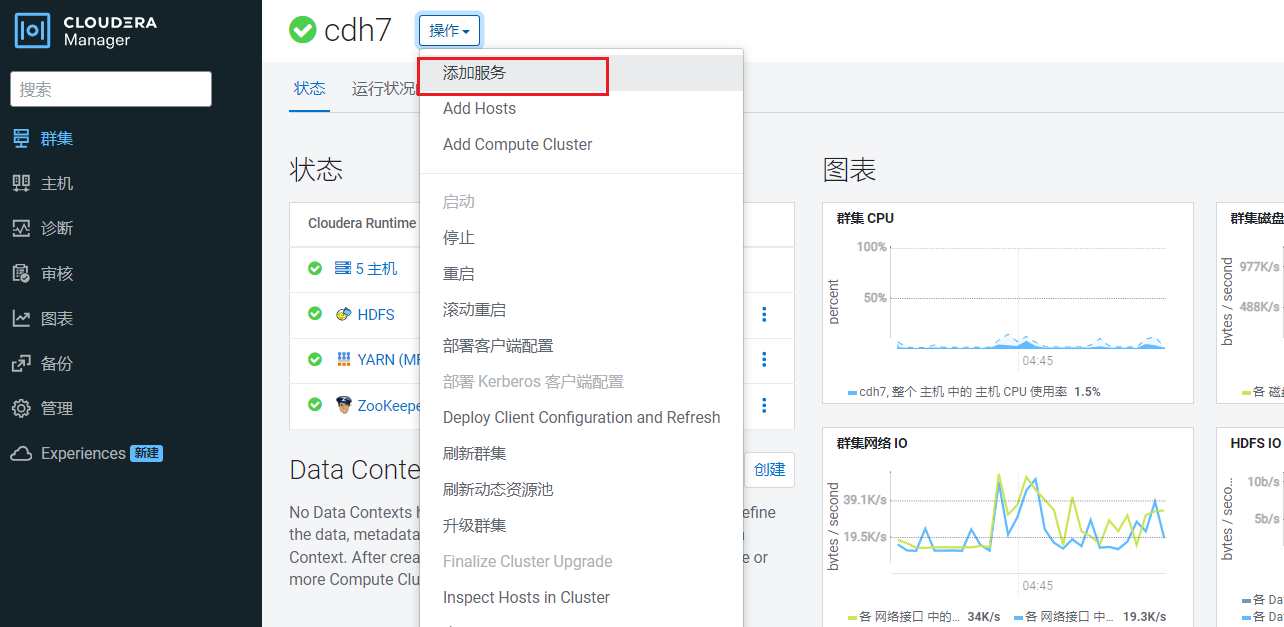 点击添加kafka组件:
点击添加kafka组件: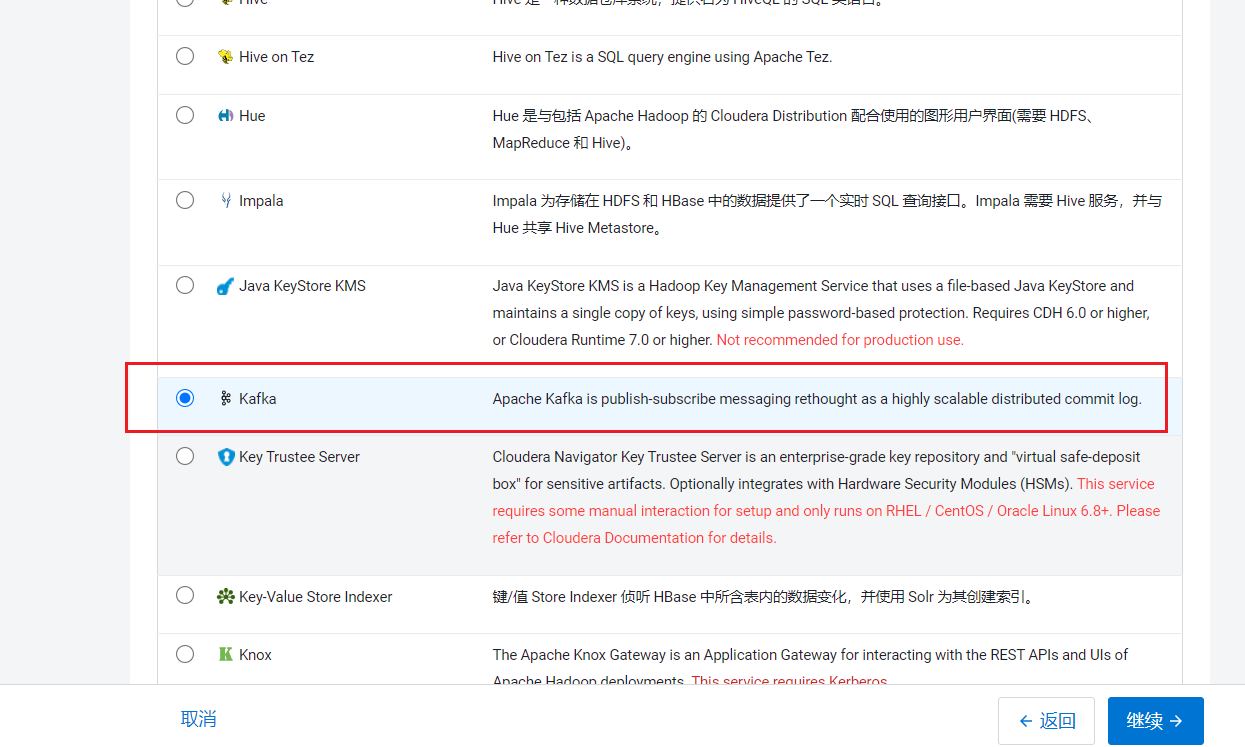 进入选择依赖页面:
进入选择依赖页面: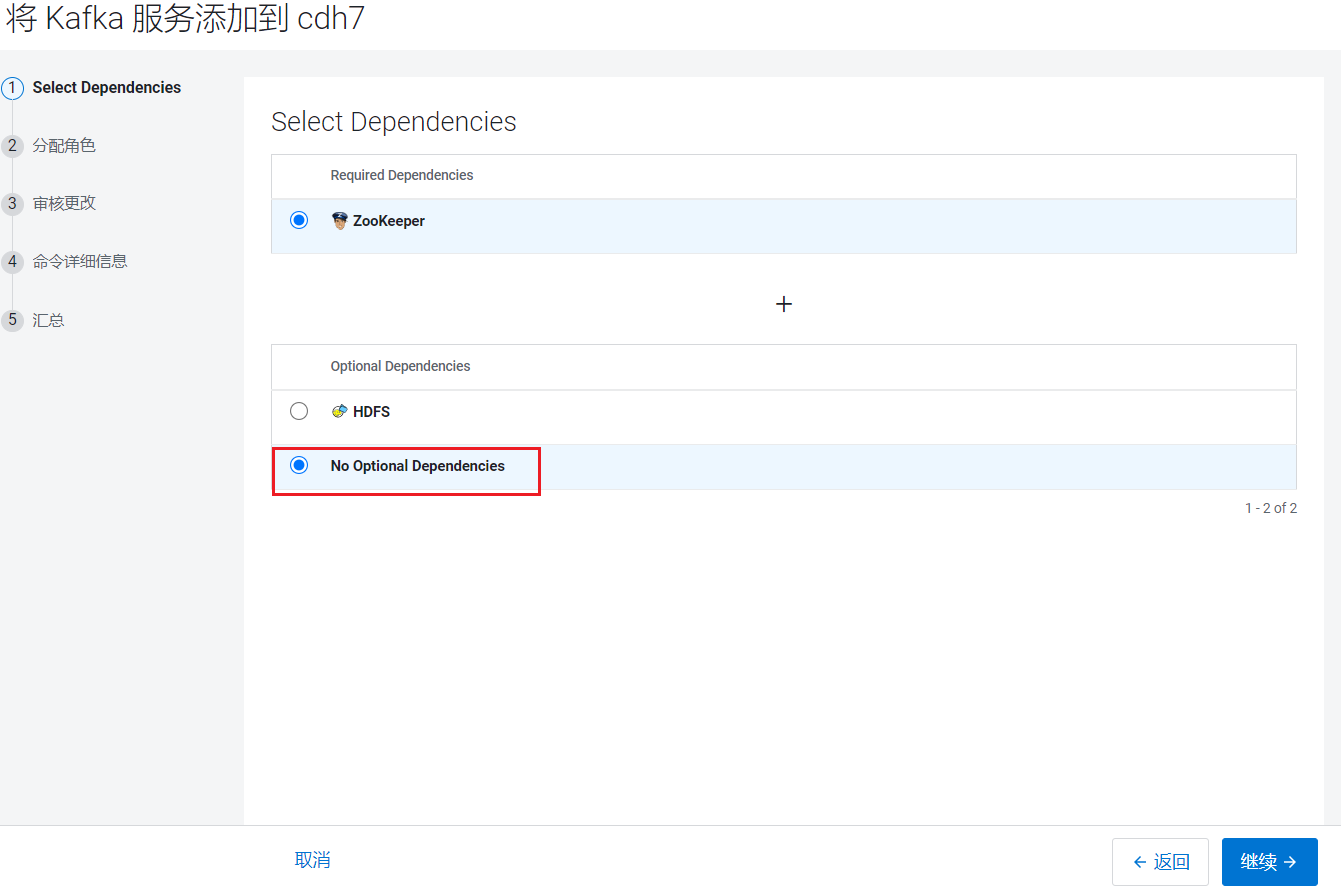 分配节点页面,这里只添加Broker:
分配节点页面,这里只添加Broker: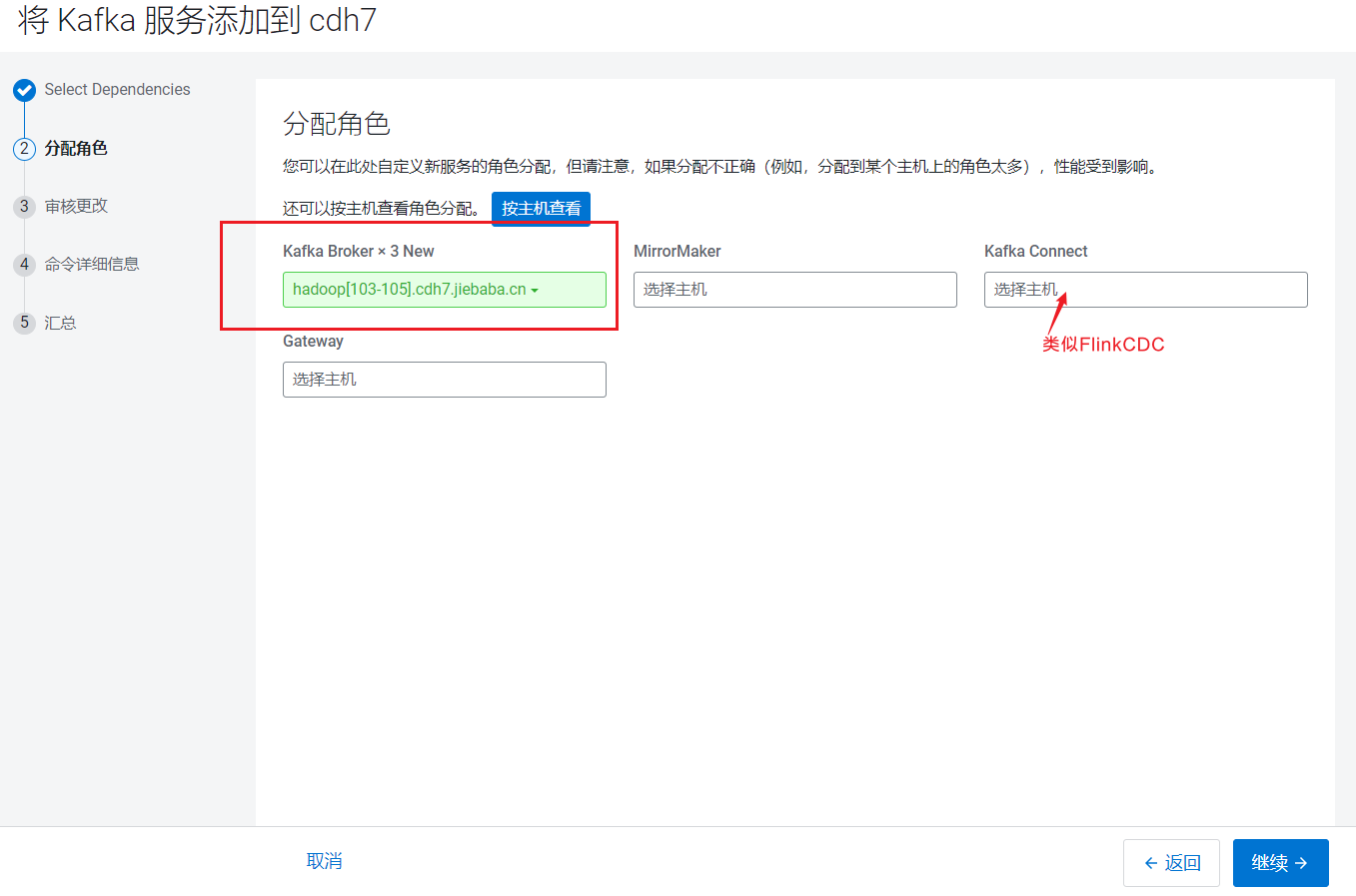 点击继续后,进入参数配置页面:
点击继续后,进入参数配置页面: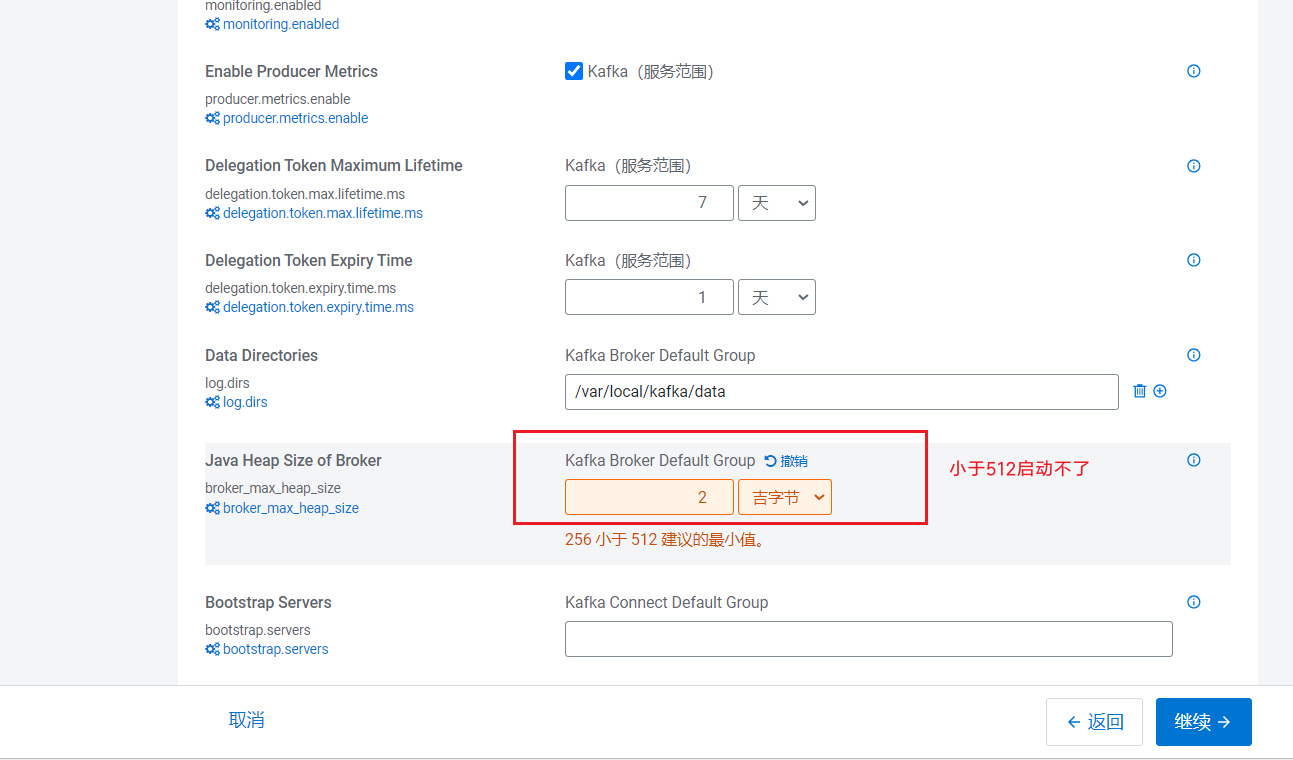 点击继续就开始安装:
点击继续就开始安装: 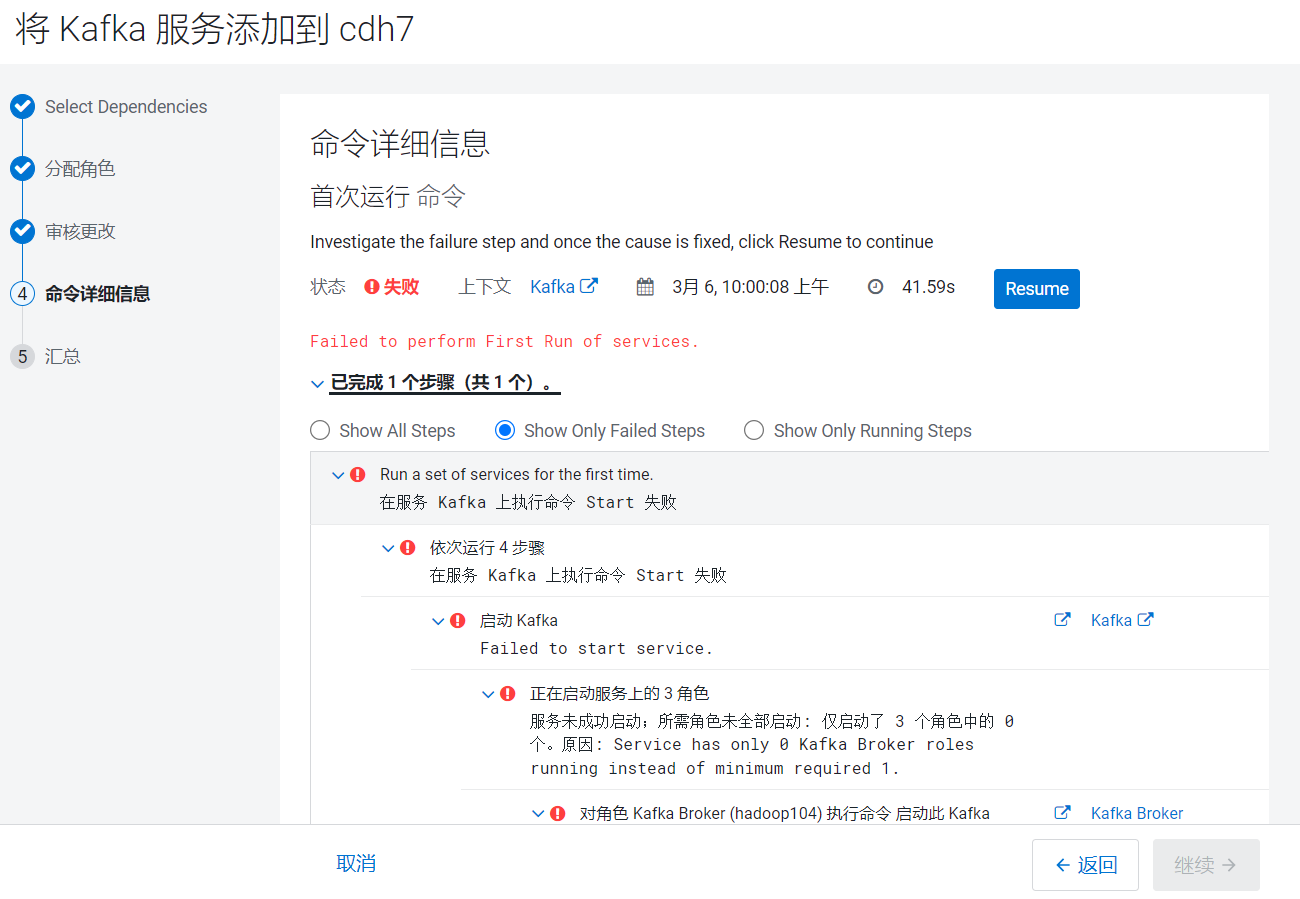 重试了很多次依然报错!!!
重试了很多次依然报错!!!
6. Hive安装
点击首页的操作,点击添加服务: 点击添加Hive组件,点击继续: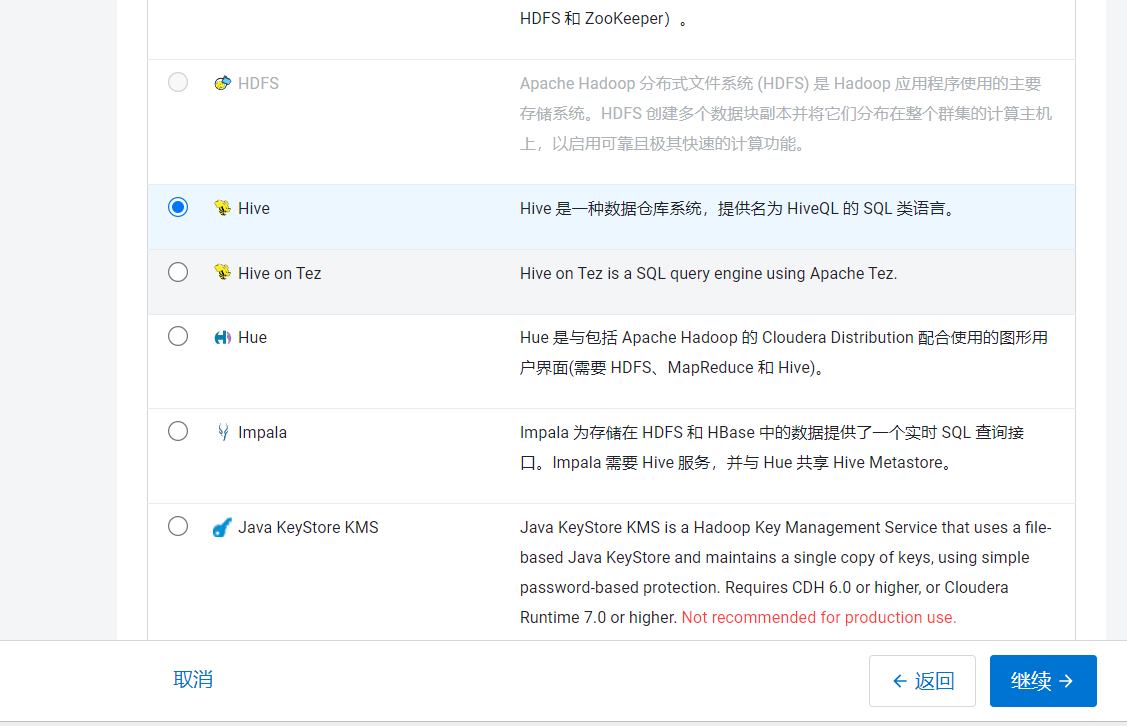 进入选择依赖页面:
进入选择依赖页面: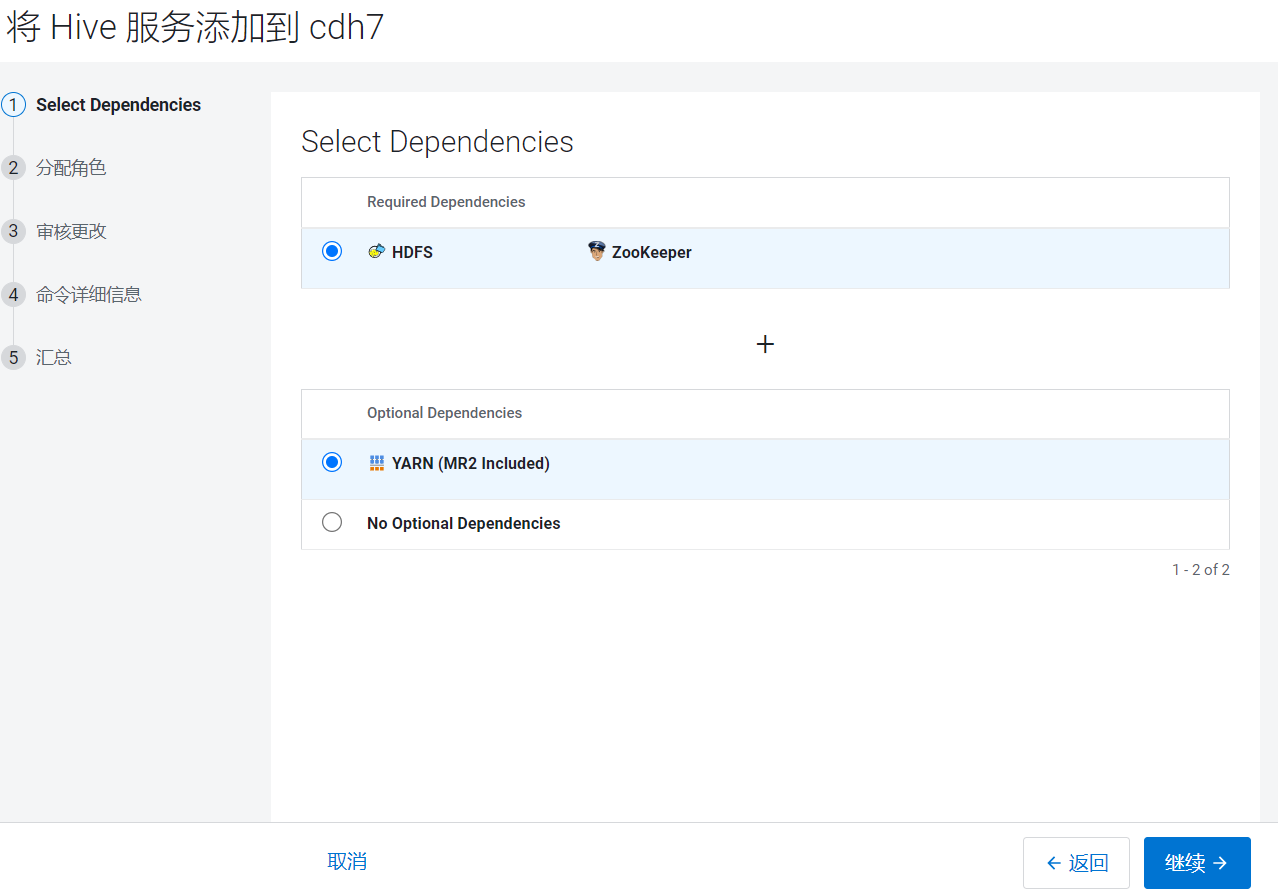 进入分配节点页面,
进入分配节点页面, 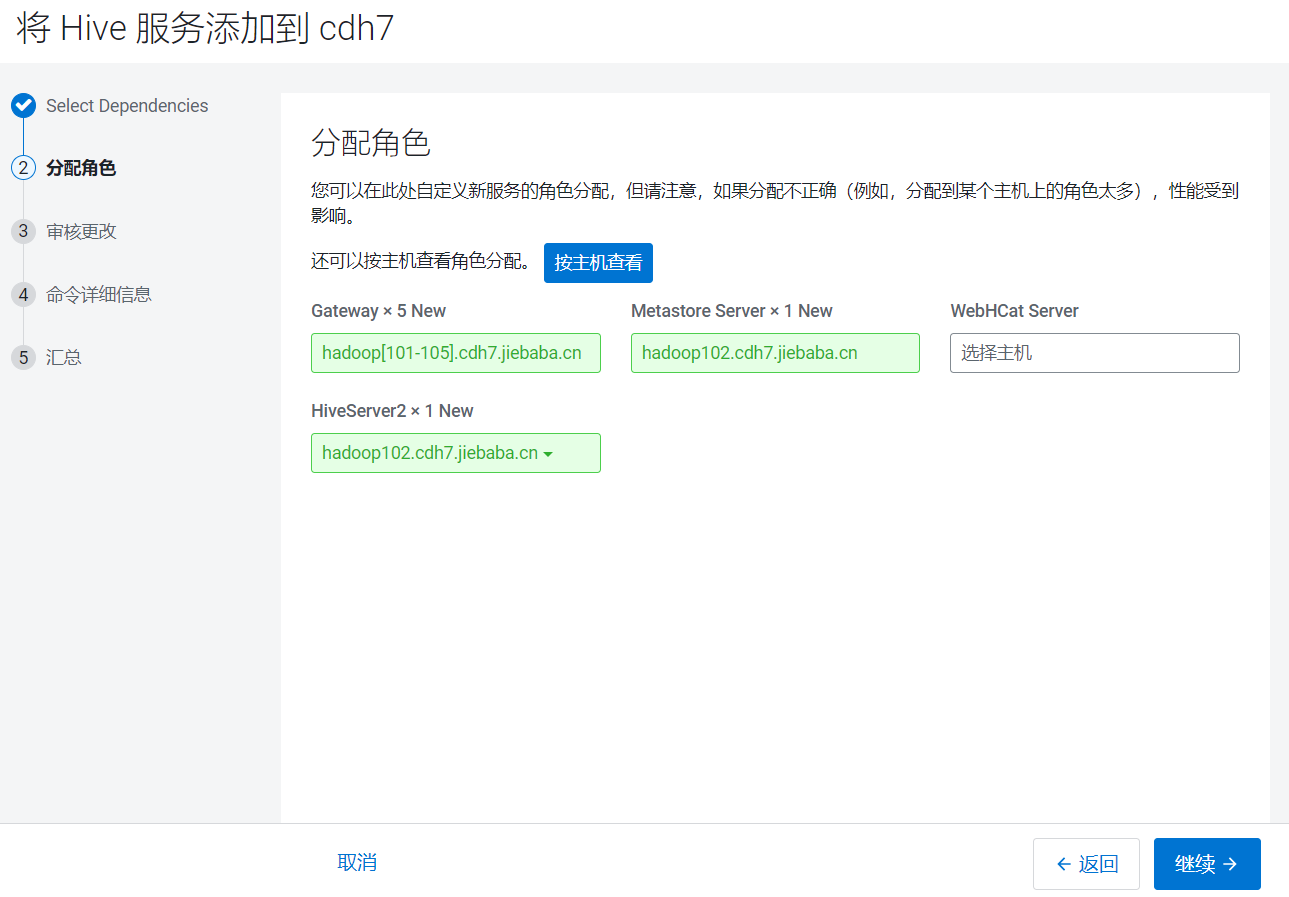
| hadoop101 | hadoop102 | hadoop103 | hadoop104 | hadoop105 |
|---|---|---|---|---|
| Gateway | Gateway Metastore Server HiveServer2 | Gateway | Gateway | Gateway |
点击继续后,进入参数配置页面: 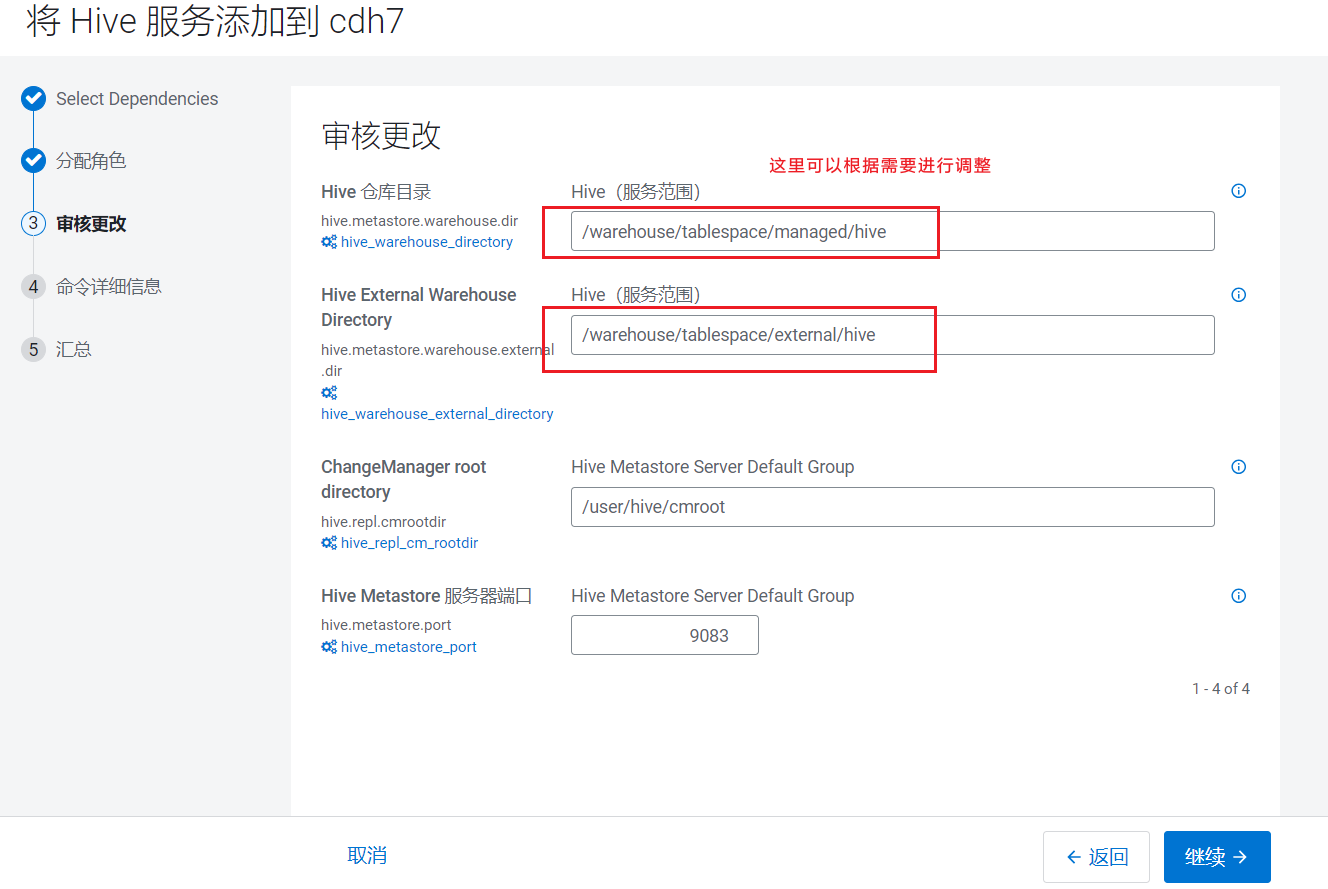 点击继续就开始安装:
点击继续就开始安装: 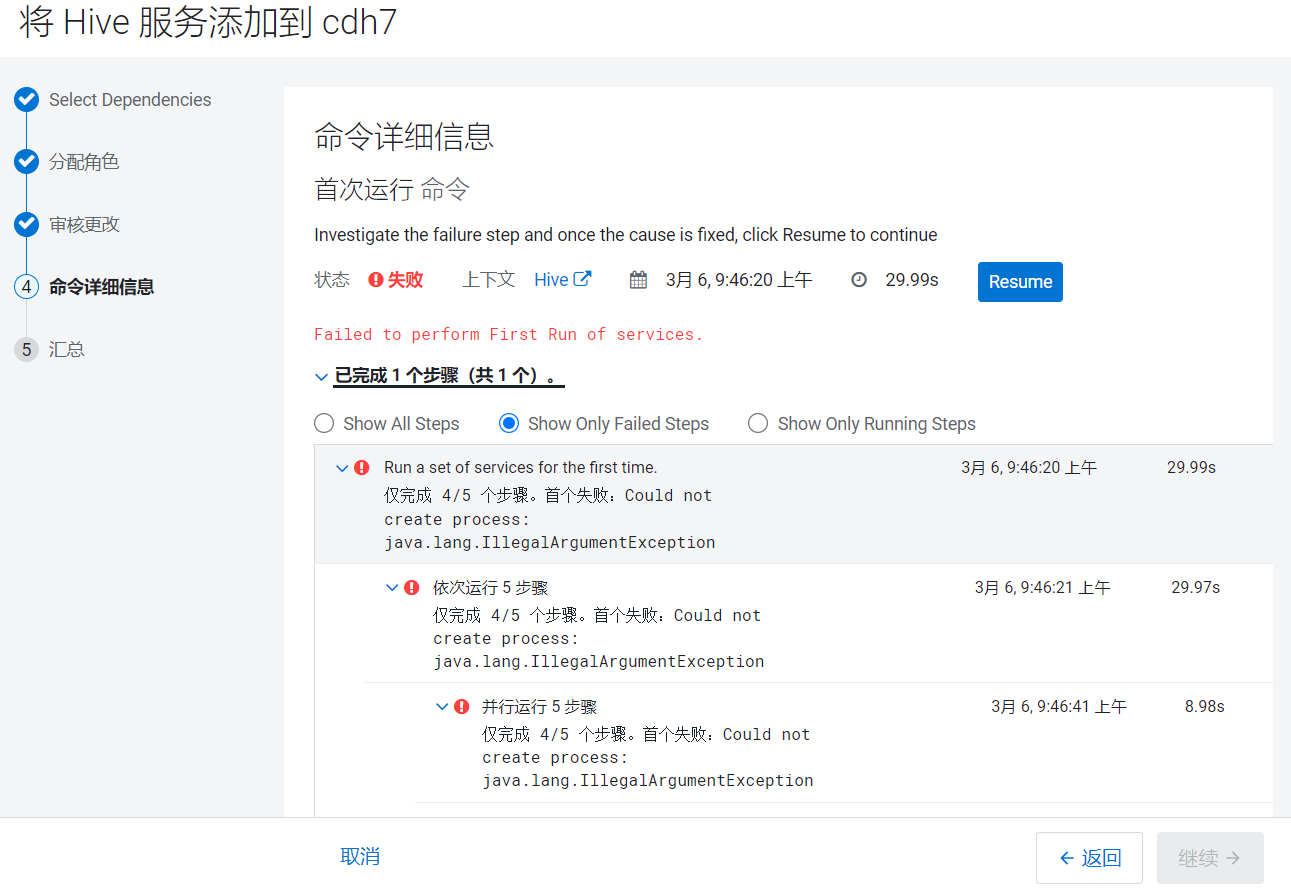 重试了很多次依然报错!!!
重试了很多次依然报错!!!