CM6添加组件
集群设置好后自动进入集群组件添加页面
1. 添加HDFS\YARN\ZooKeeper
选择自定义安装: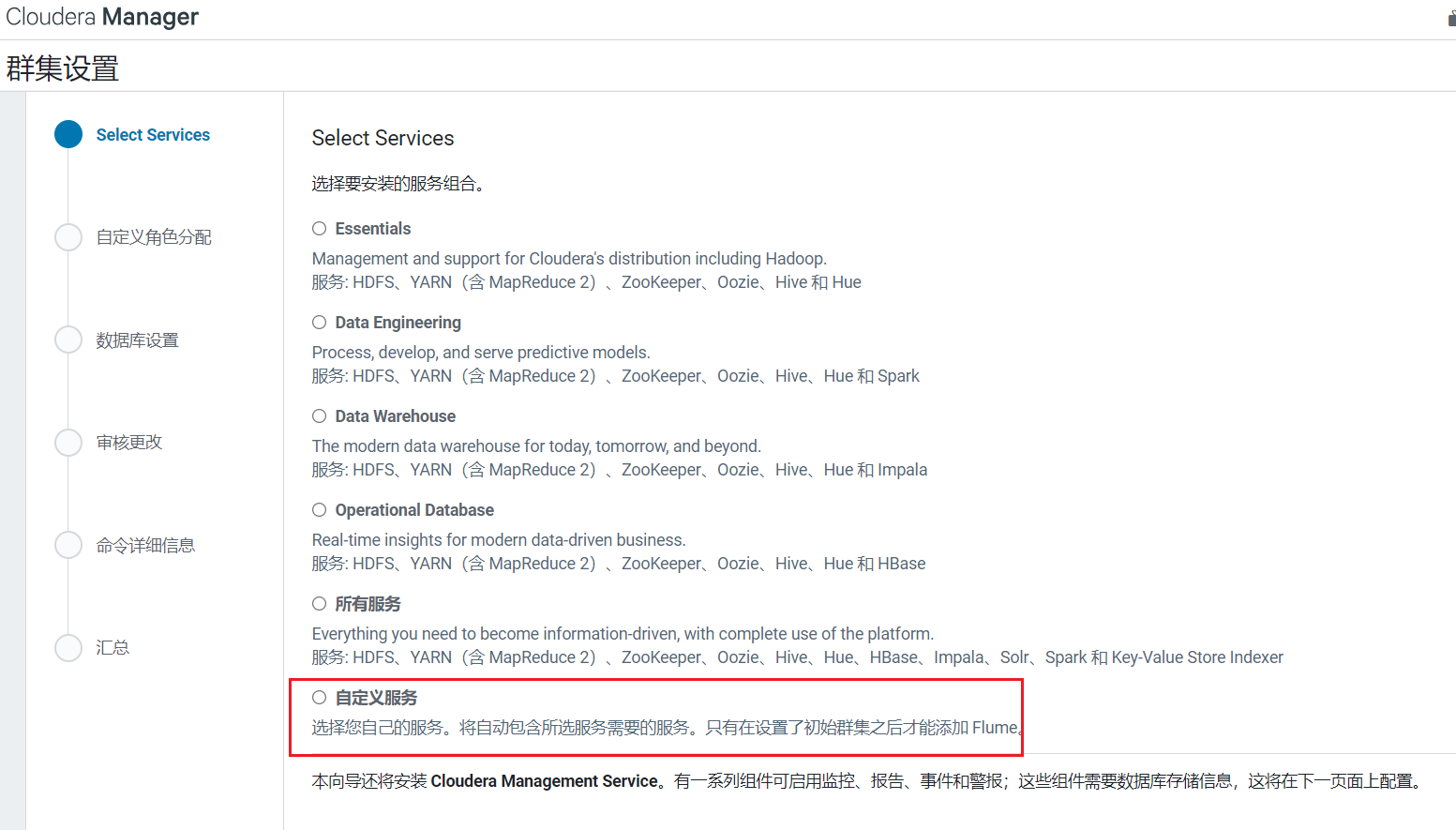 选择安装服务HDFS\YARN\ZooKeeper,点击继续
选择安装服务HDFS\YARN\ZooKeeper,点击继续  进入节点分配页面:
进入节点分配页面: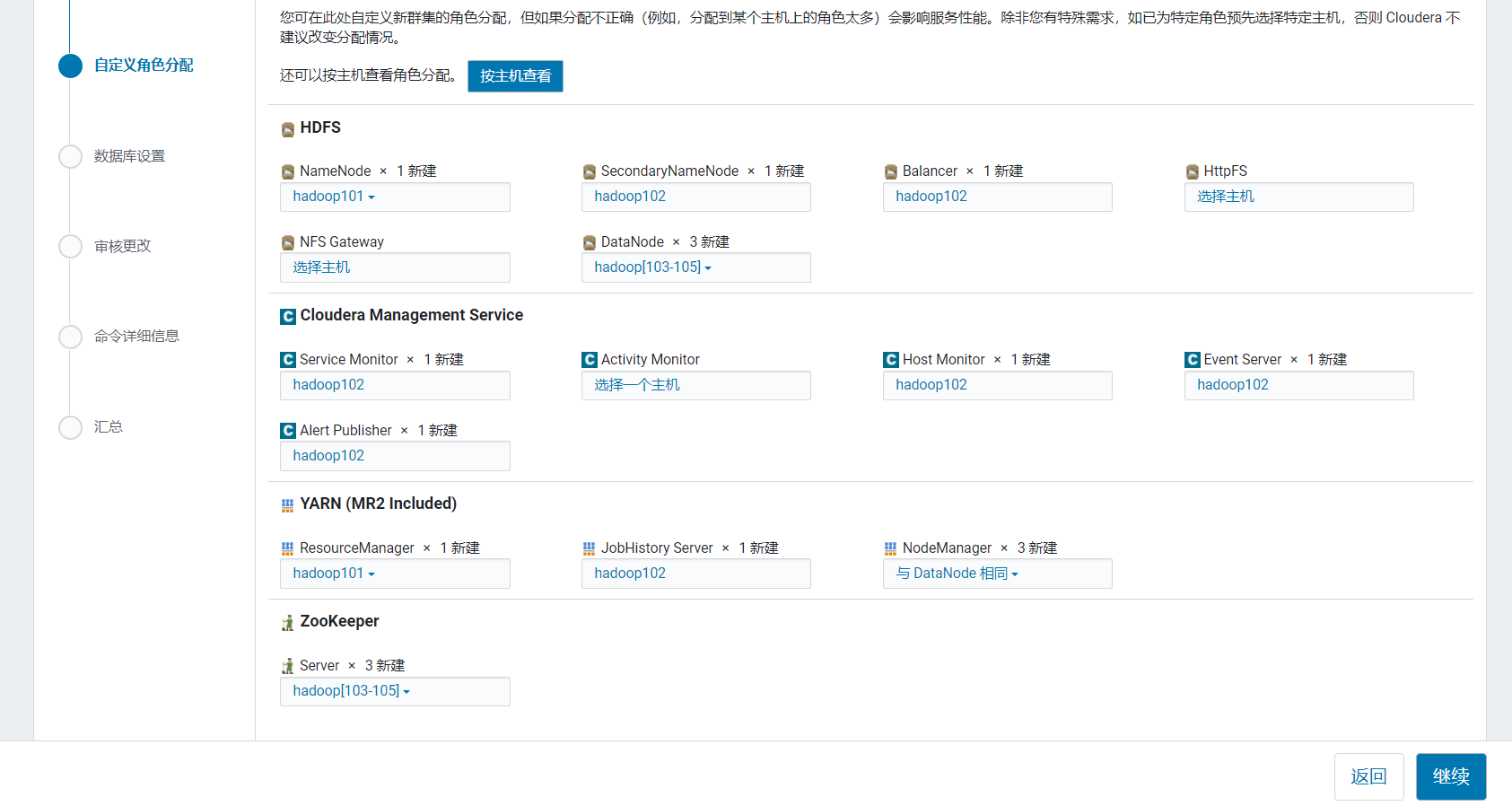
| hadoop101 | hadoop102 | hadoop103 | hadoop104 | hadoop106 | |
|---|---|---|---|---|---|
| HDFS | NN | 2NN | DN | DN | DN |
| YARN | RM | JobHistory | NM | NM | NM |
| ZooKeeper | zk | zk | zk |
点击继续后,进入参数配置页面,一般都不用改: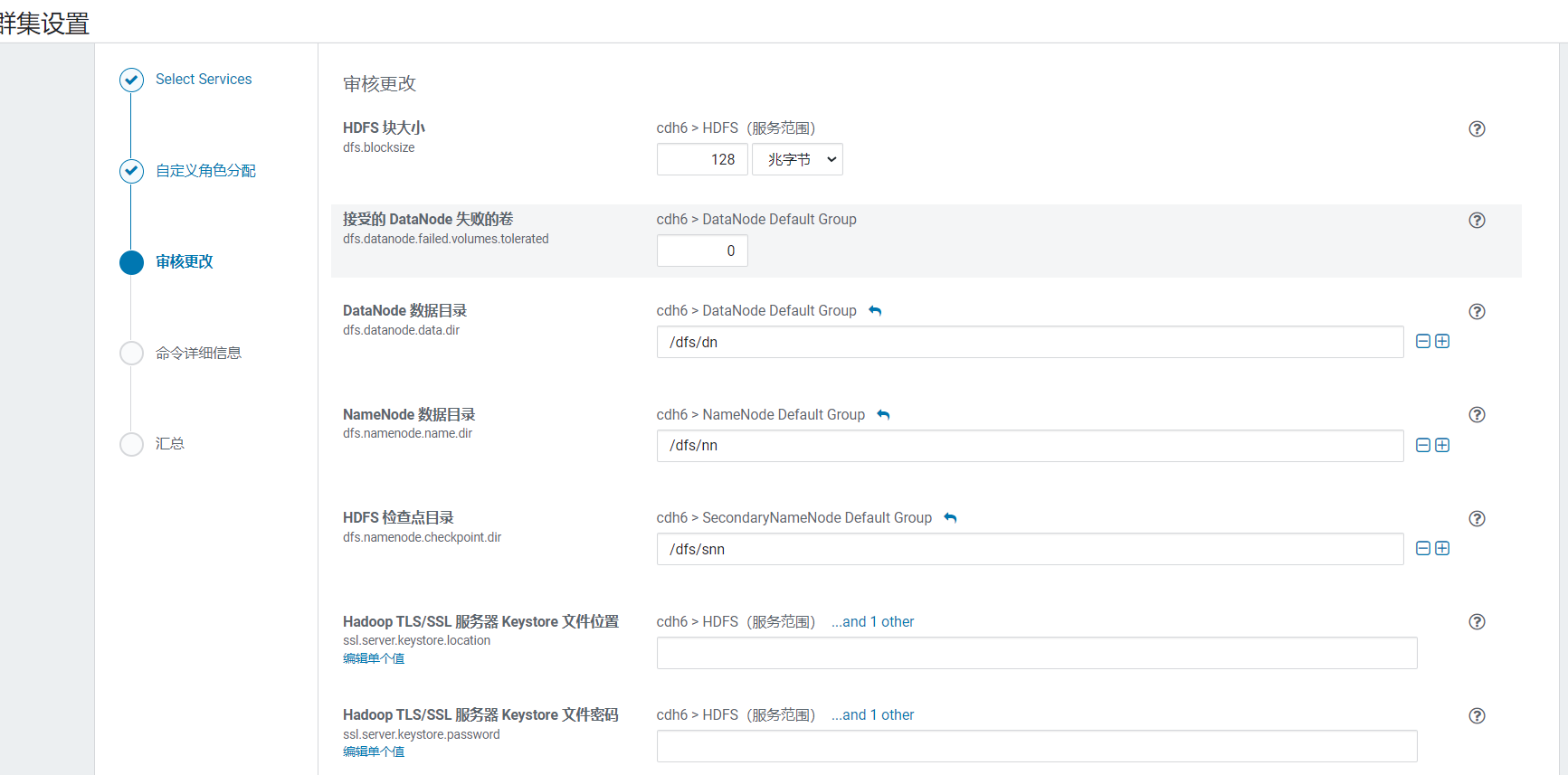 点击继续就开始安装:
点击继续就开始安装: 点击完成:
点击完成: 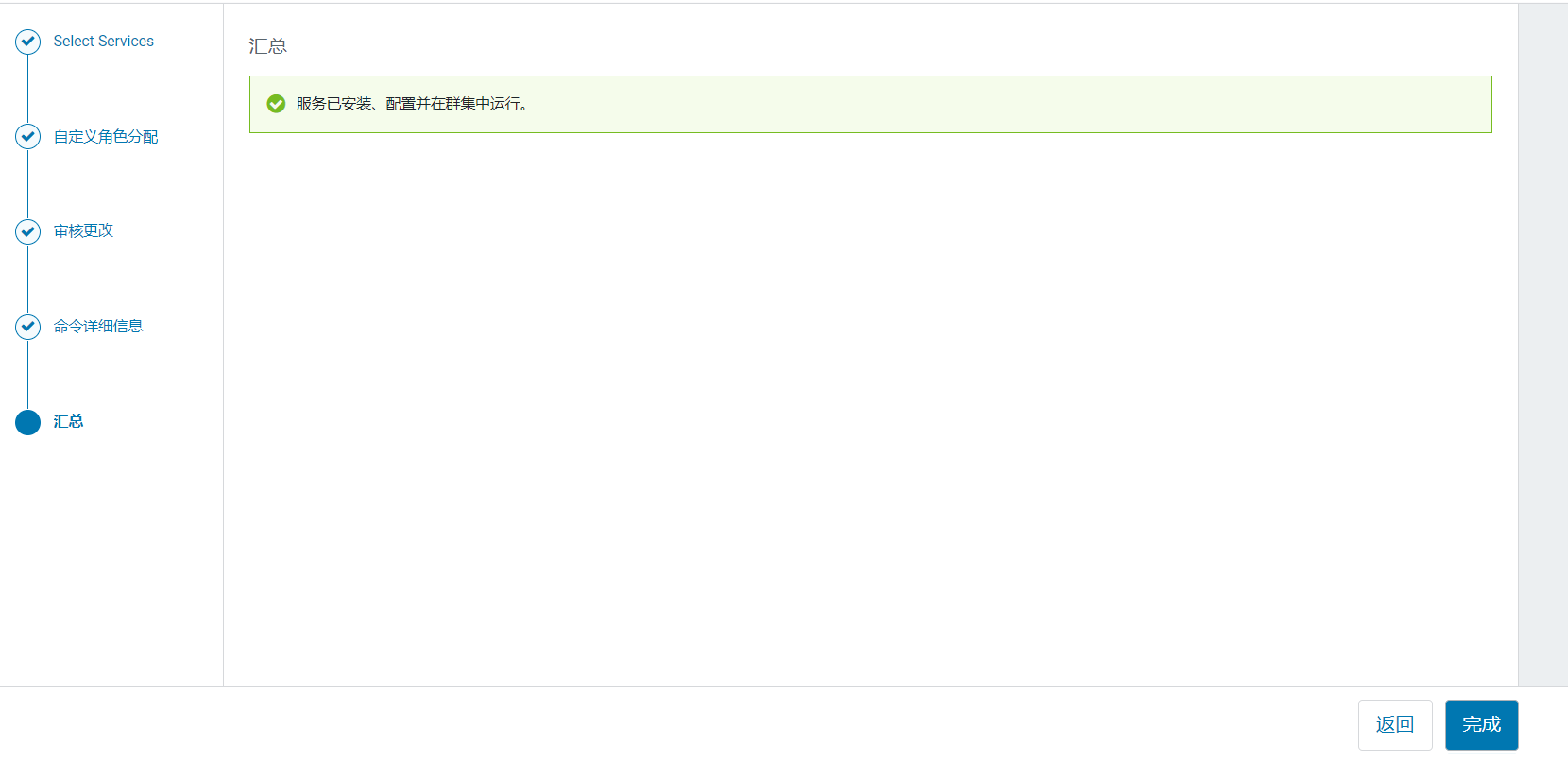 访问http://hadoop101:9870/:
访问http://hadoop101:9870/: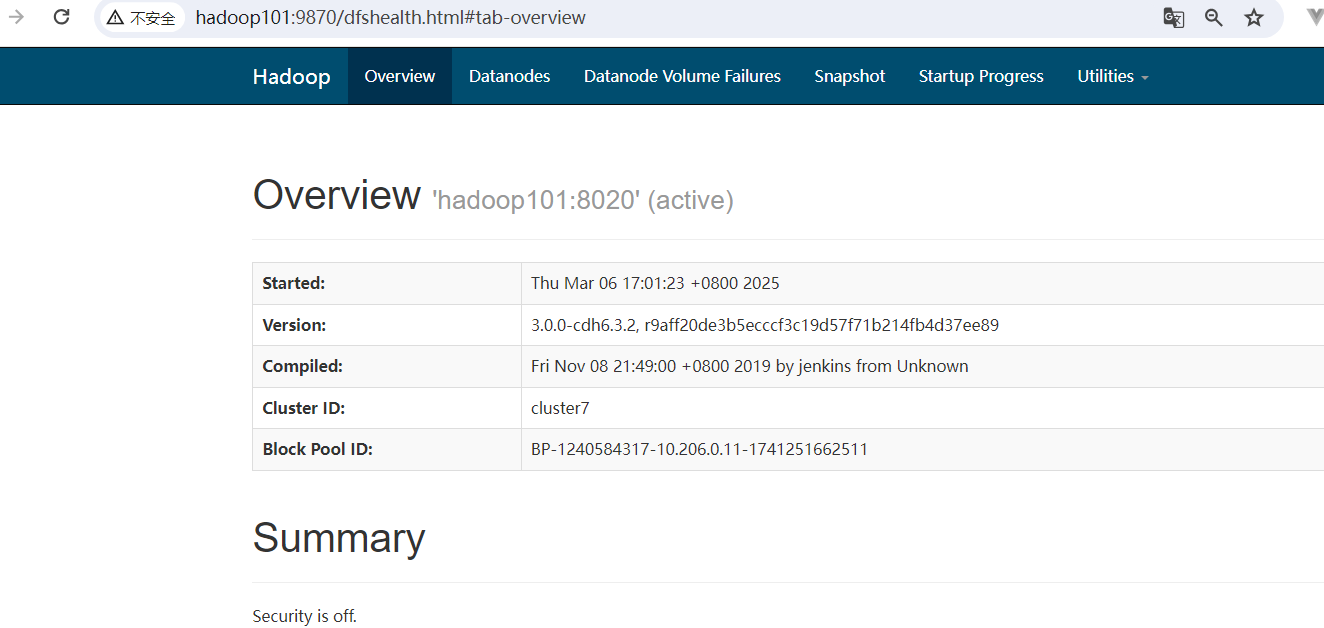
2. 处理平台问题
回到首页后,CDH提示有个配置项需要修改: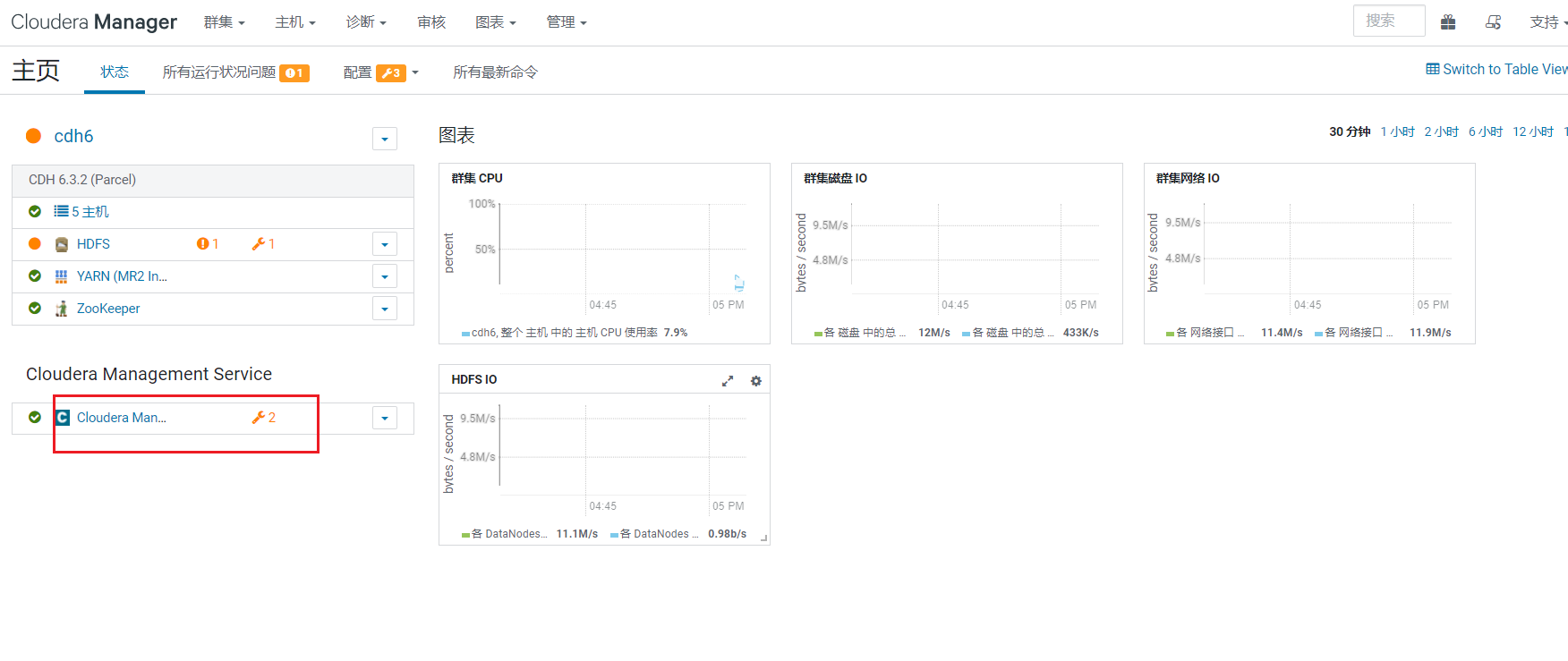 点击问题后弹出框,如果不处理就直接点击supress表示关闭这类错误提示
点击问题后弹出框,如果不处理就直接点击supress表示关闭这类错误提示 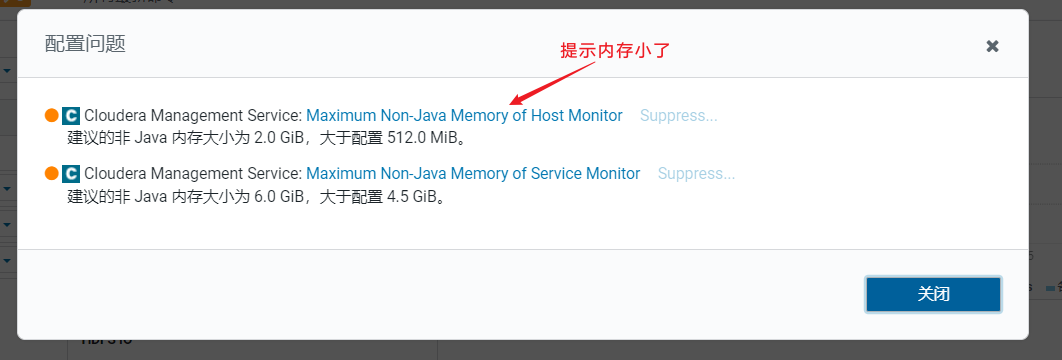 修改后,保存填写理由原因信息方便排查:
修改后,保存填写理由原因信息方便排查: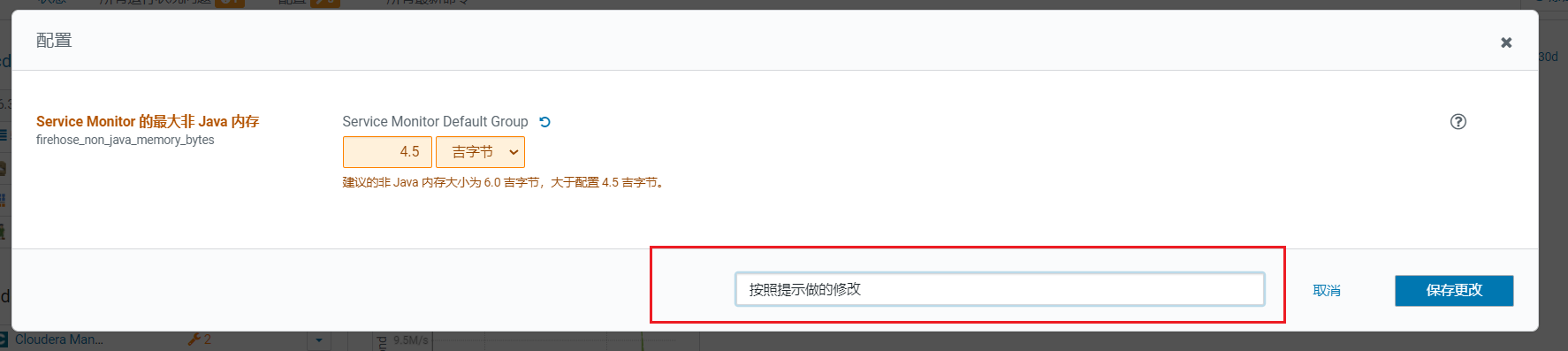
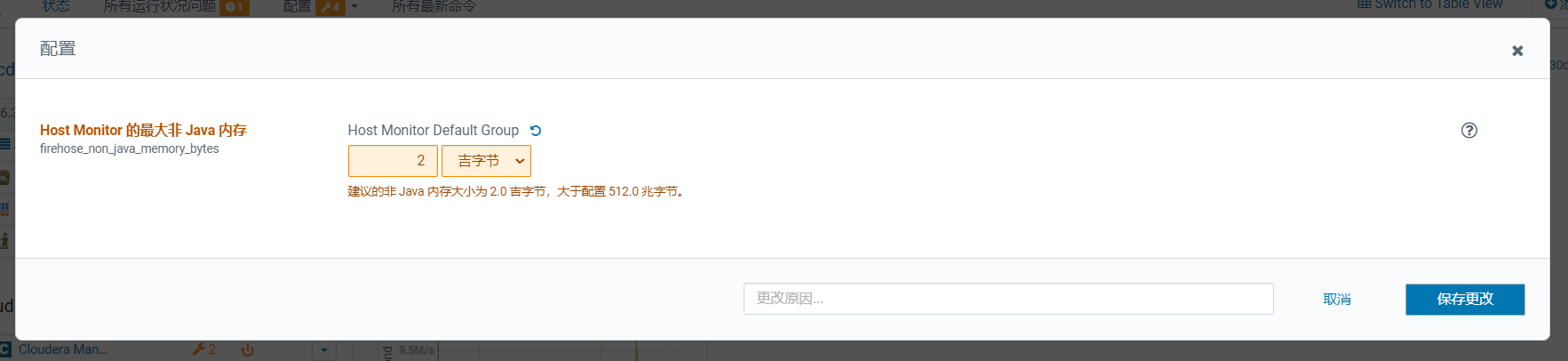 改完出现有电源图标,表示配置需要重启server才能生效:
改完出现有电源图标,表示配置需要重启server才能生效: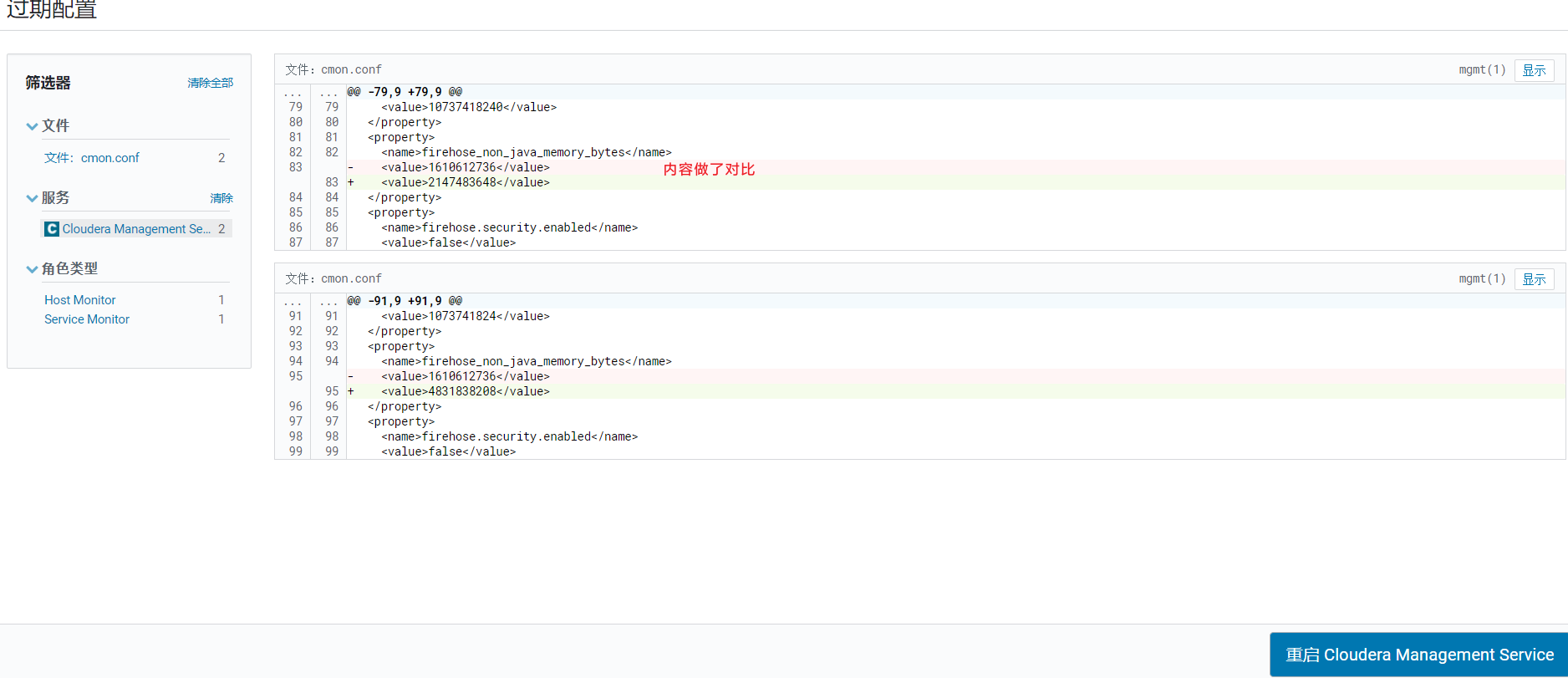 等待重启完成:
等待重启完成: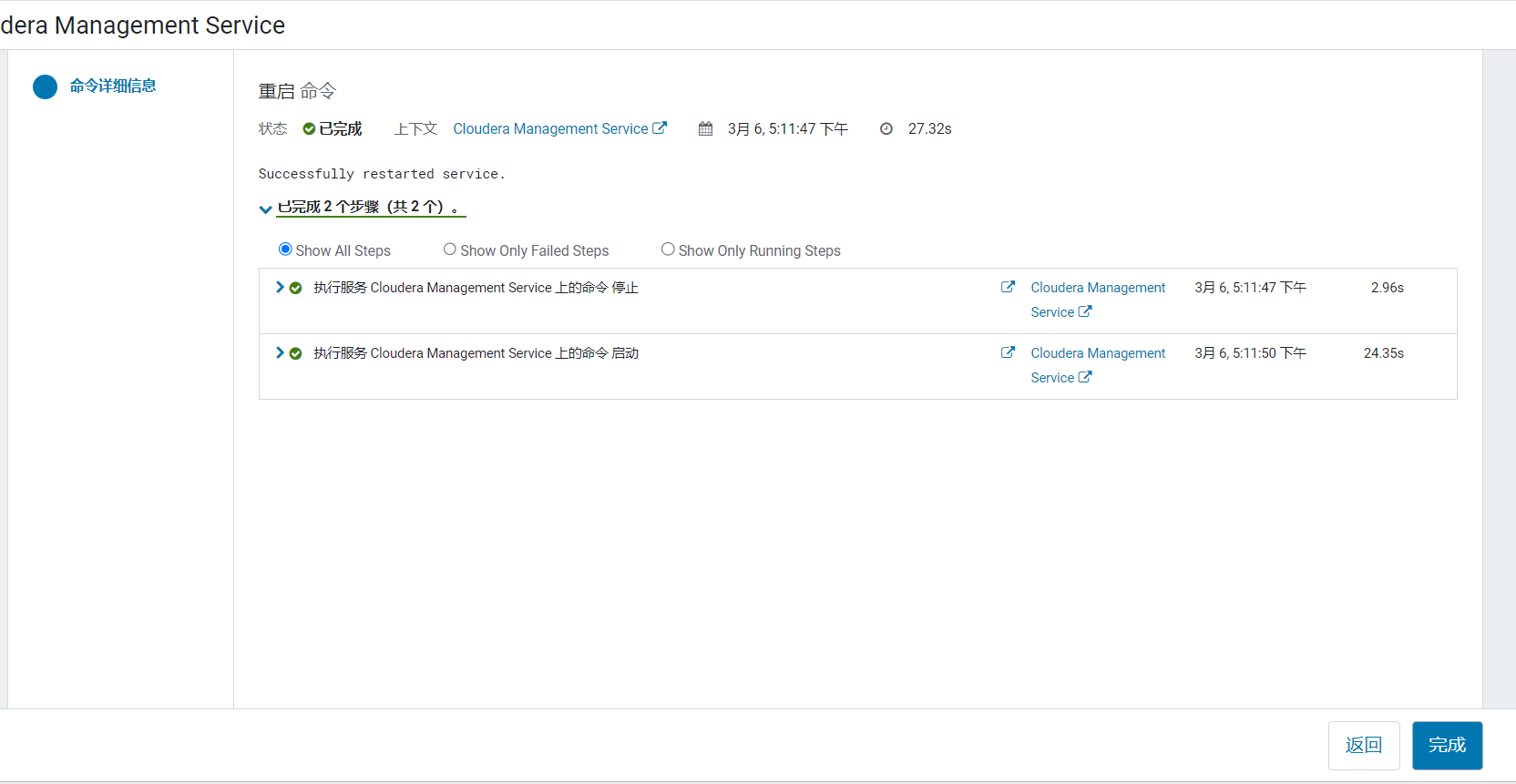 这时HDFS报了一个问题,点击进入:
这时HDFS报了一个问题,点击进入: 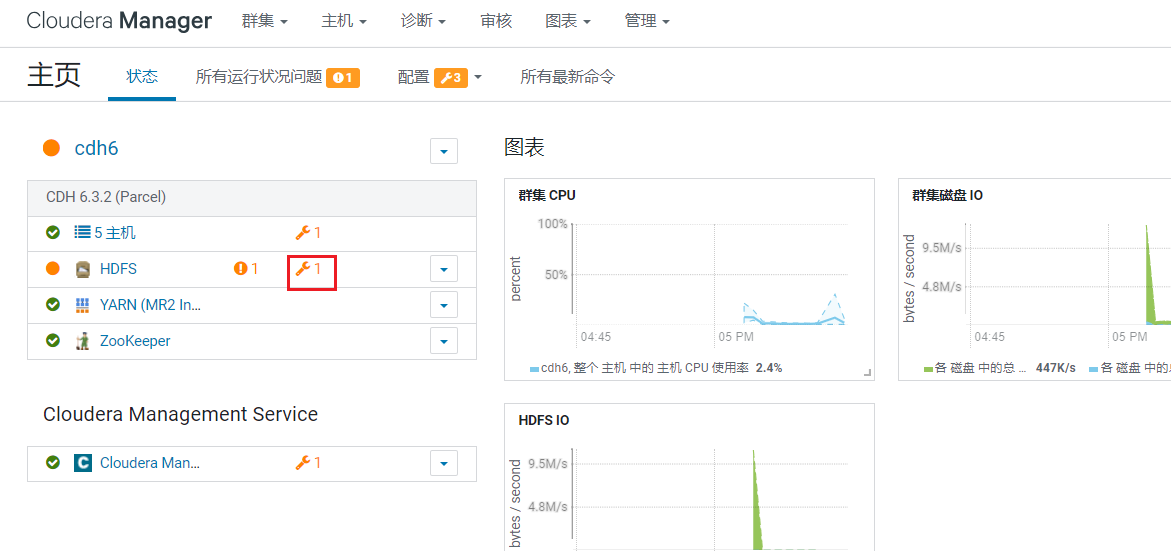 发现是NameNode的内存小了,调大为3G:
发现是NameNode的内存小了,调大为3G: 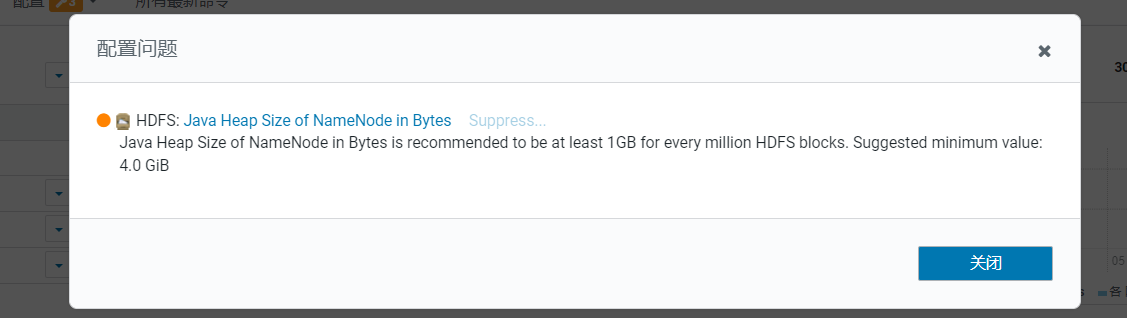 点击保存:
点击保存: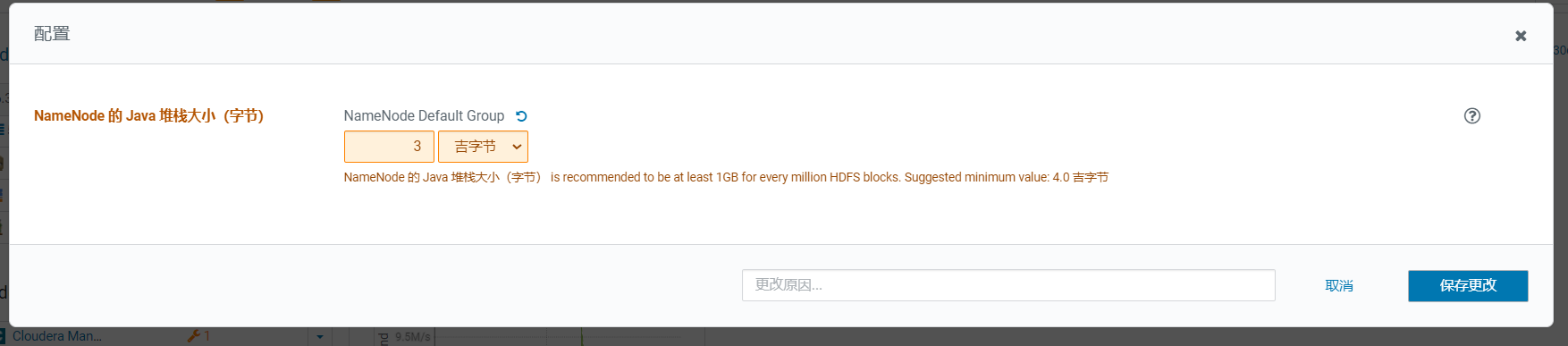 保存后,发现问题变多了,点击重启可能配置生效就解决了:
保存后,发现问题变多了,点击重启可能配置生效就解决了: 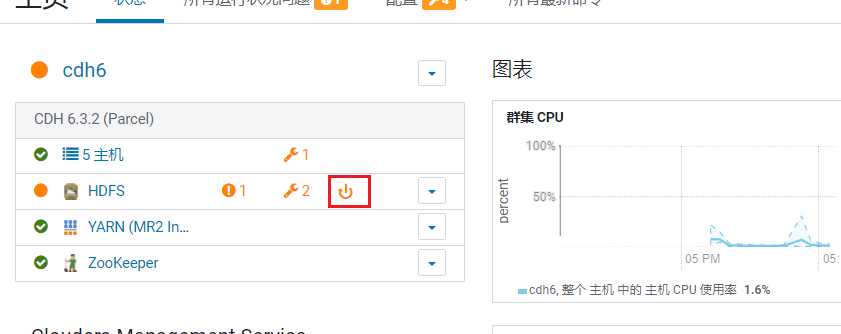 确认更改内容:
确认更改内容: 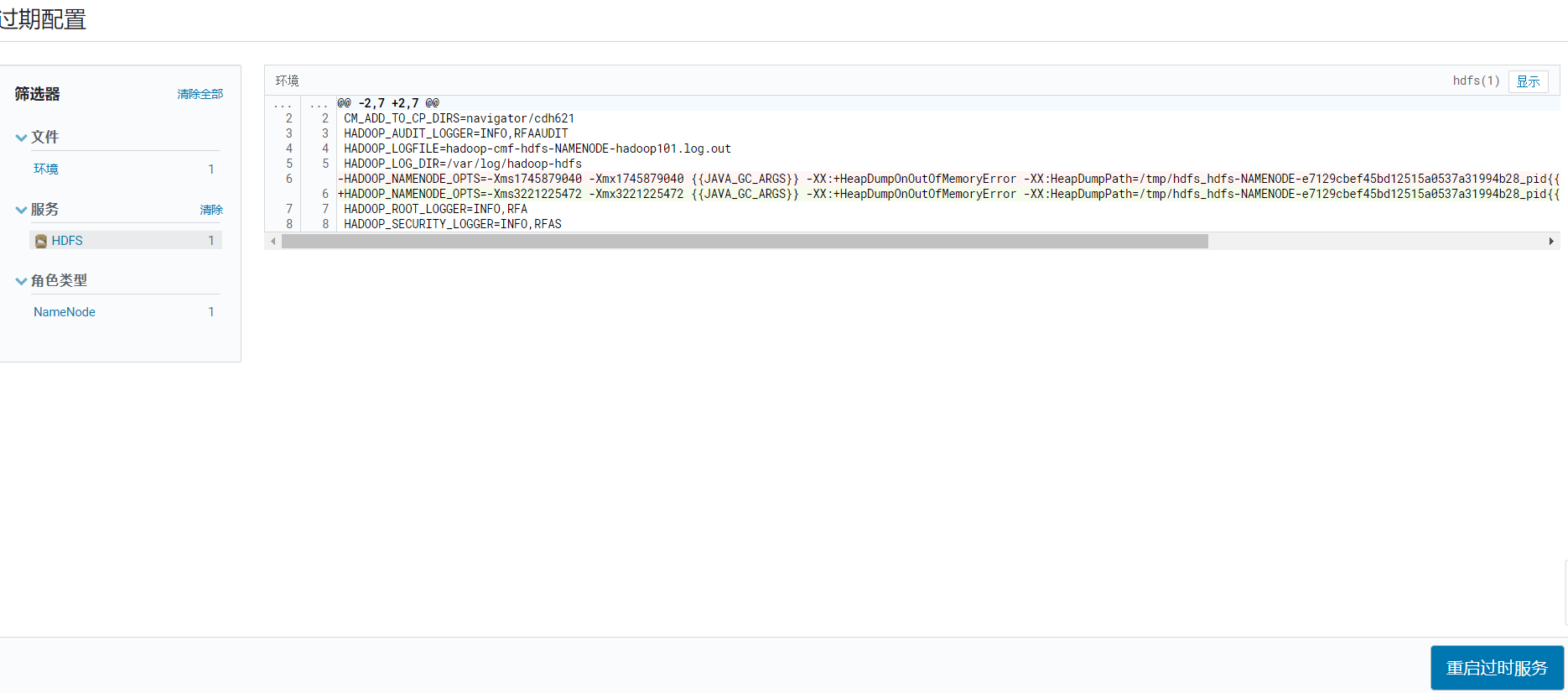 点击重启,搭建初期问题都尽量修改了:
点击重启,搭建初期问题都尽量修改了: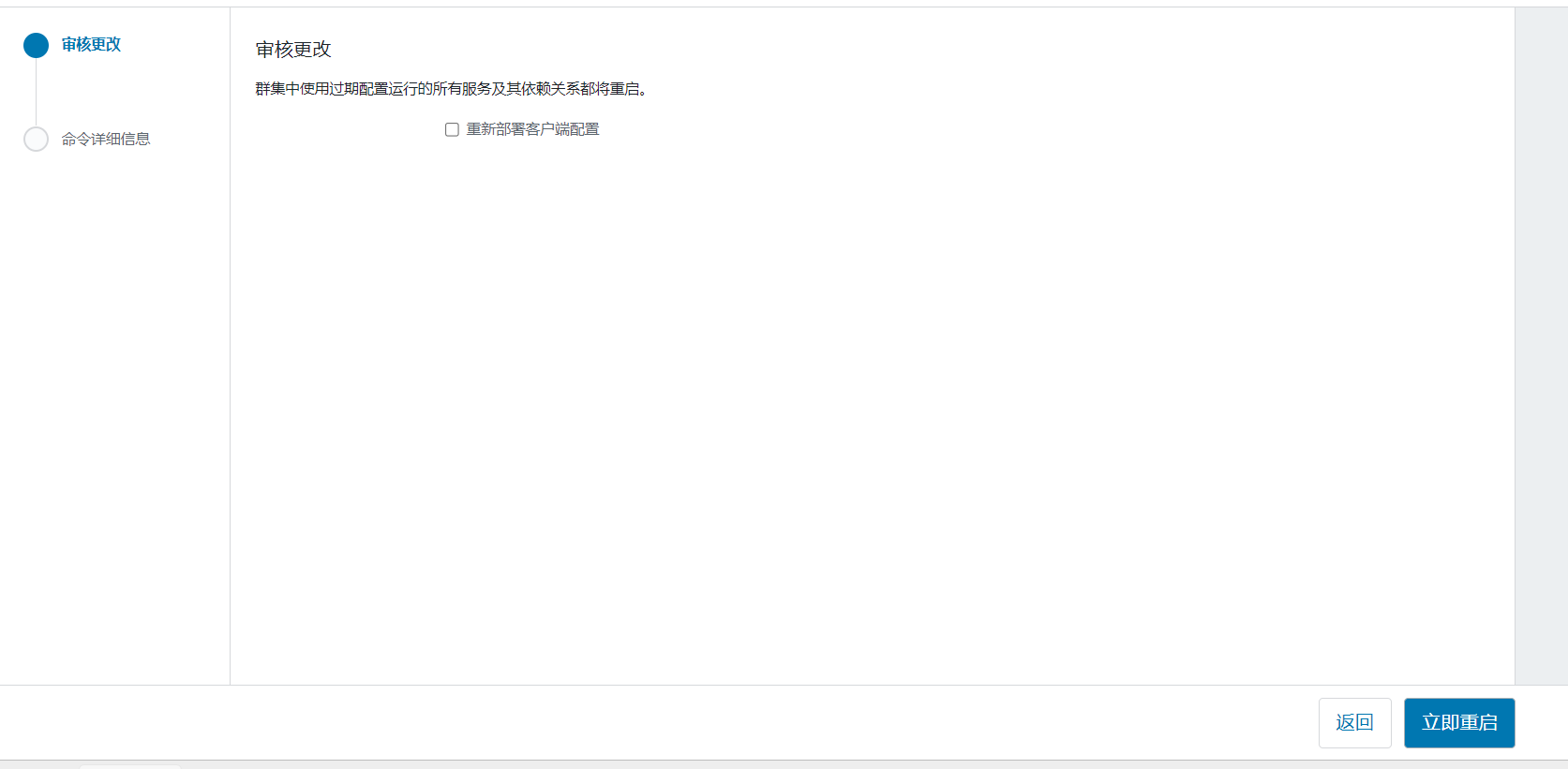 等待重启完成:
等待重启完成: 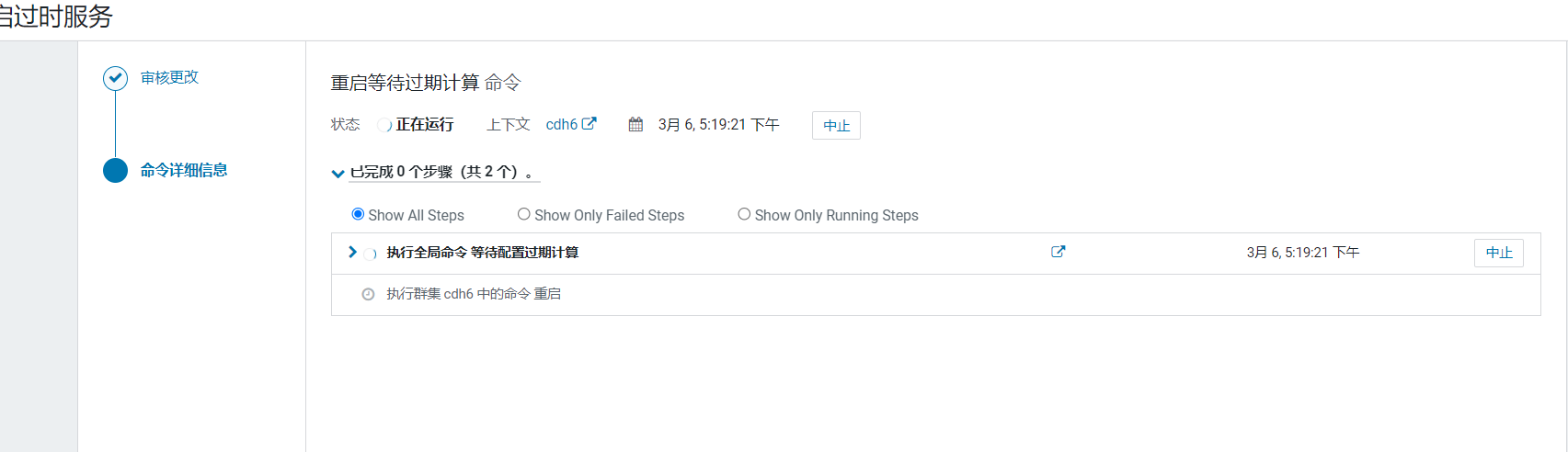
3. 配置HDFS的HA
HDFS是整个大数据框架的数据存储的部分,数据如果丢失不像Yarn资源调度失败了再重新启动点击HDFS简单,需要配置HDFS的高可用,点击HDFS, 进入HDFS组件页面: 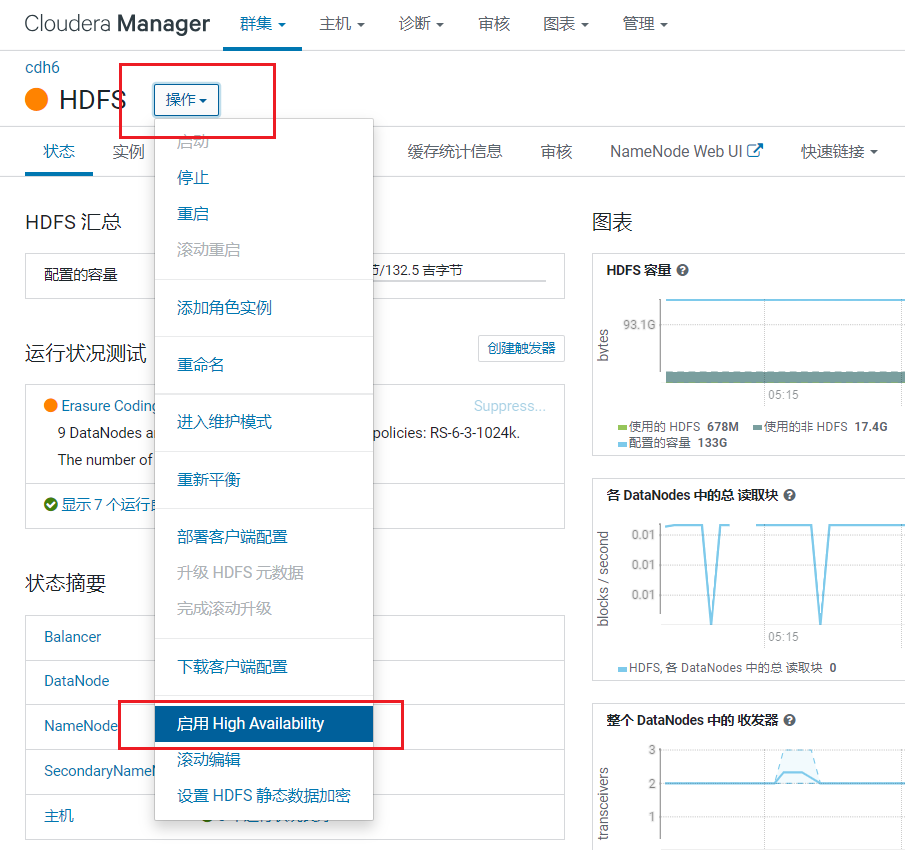 这里需要配置一个命名空间,主要用来ZK中保存区分主NameNode和Standby的NameNode,使用默认点击继续:
这里需要配置一个命名空间,主要用来ZK中保存区分主NameNode和Standby的NameNode,使用默认点击继续: 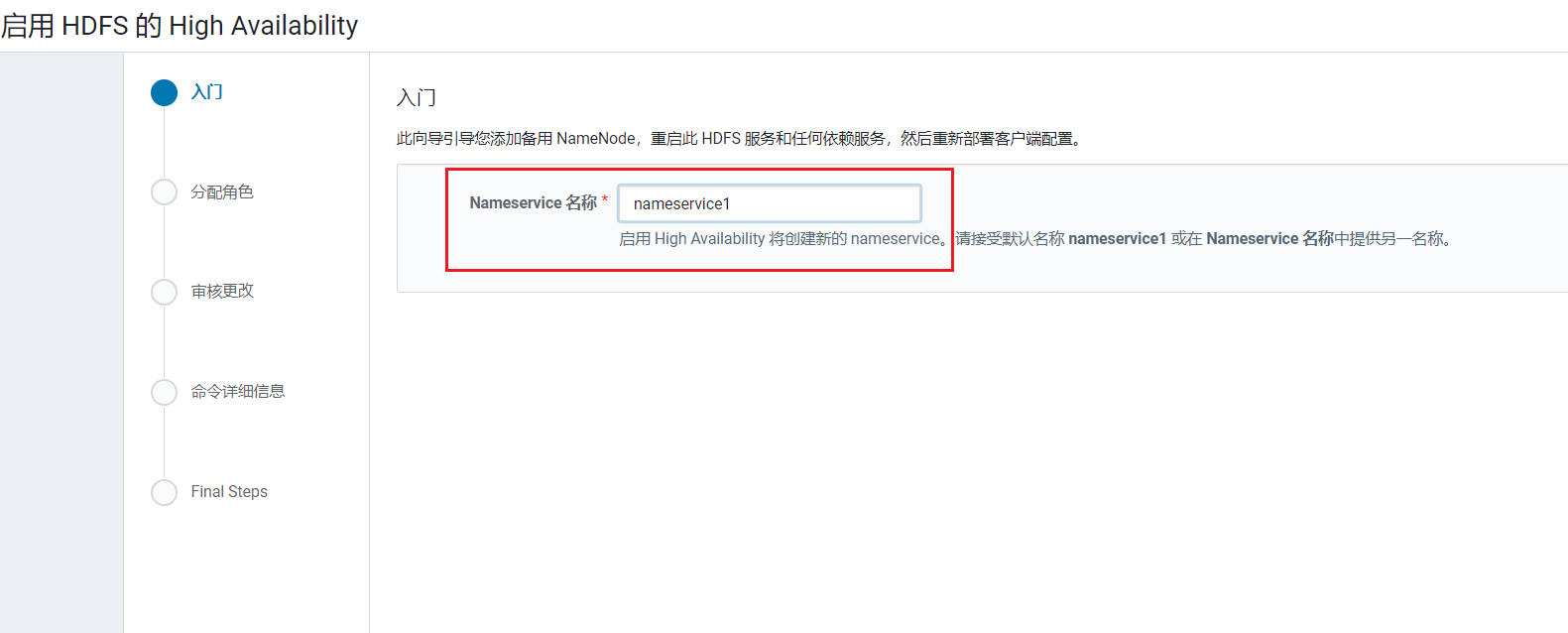 配置节点:
配置节点: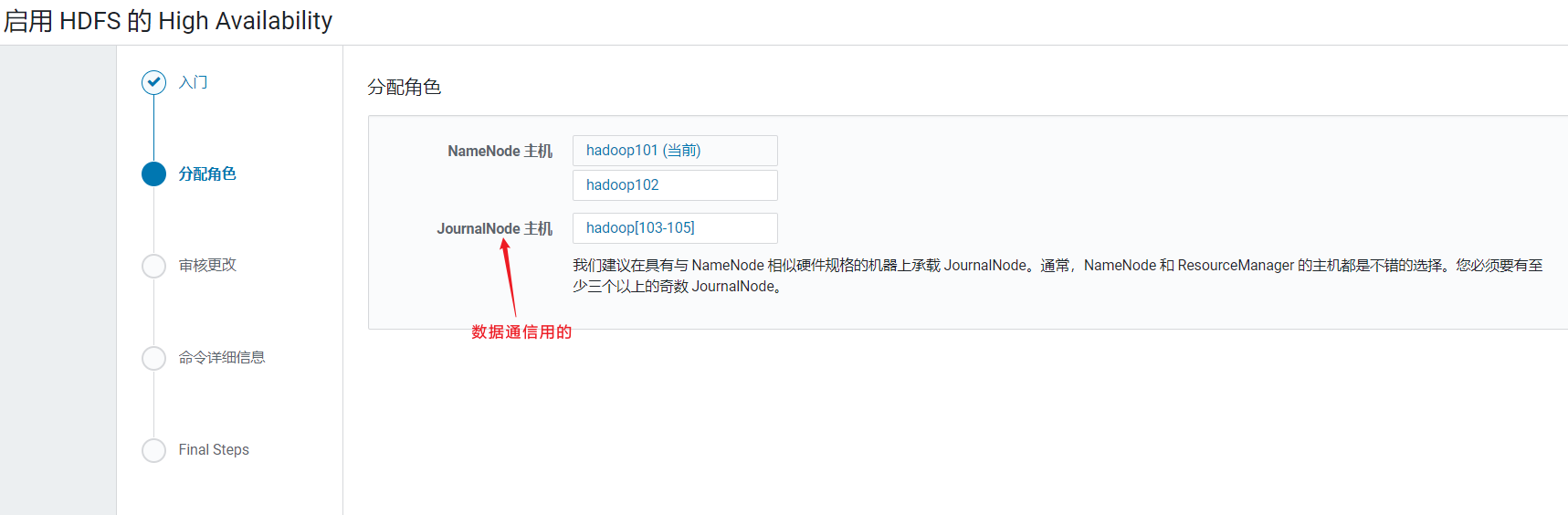 审核更改页面,设置读写目录:
审核更改页面,设置读写目录: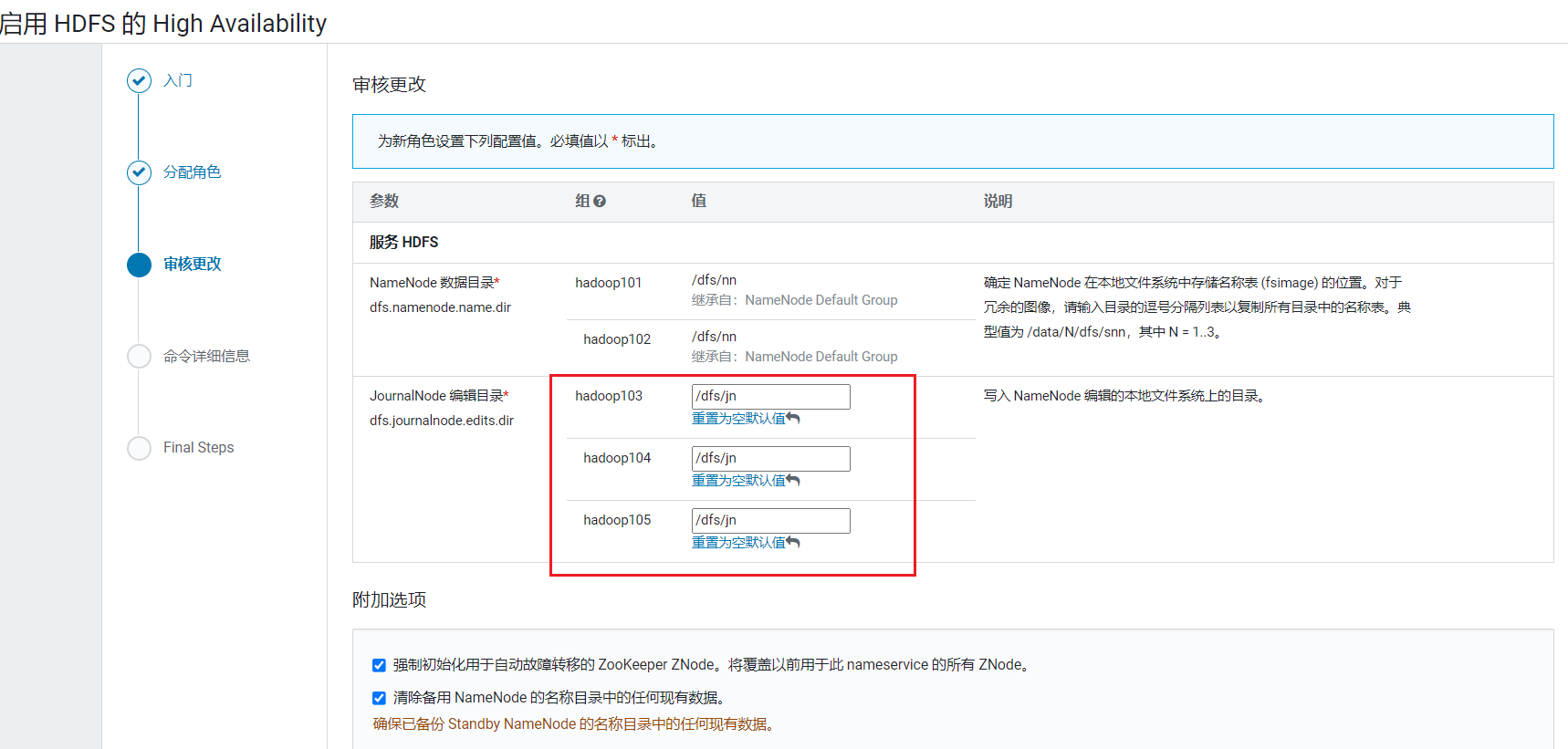 等待完成,启动服务, 点击继续
等待完成,启动服务, 点击继续 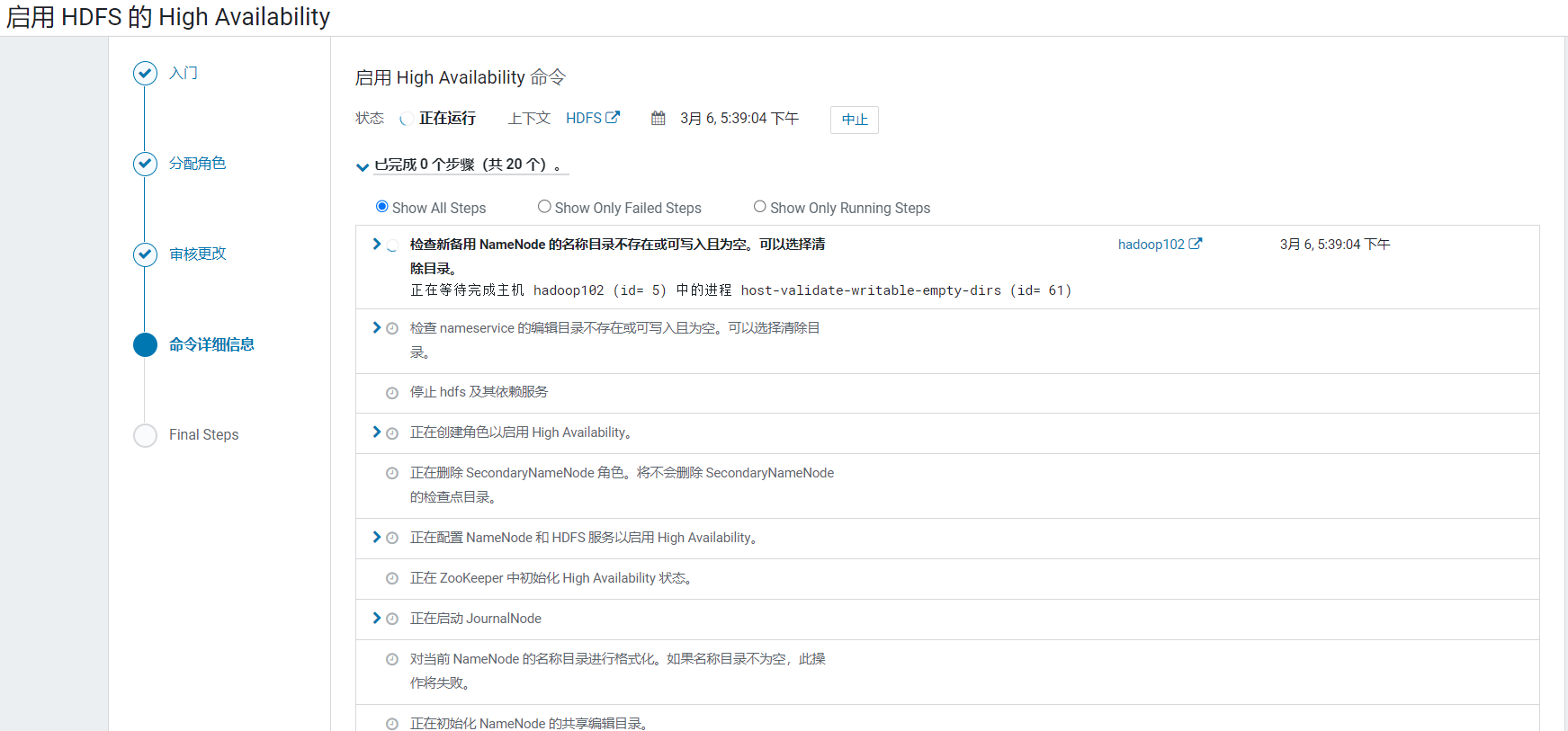 点击完成:
点击完成: 回到HDFS页面后,点击实例:
回到HDFS页面后,点击实例:  可以看到主备NameNode已经启用了:
可以看到主备NameNode已经启用了: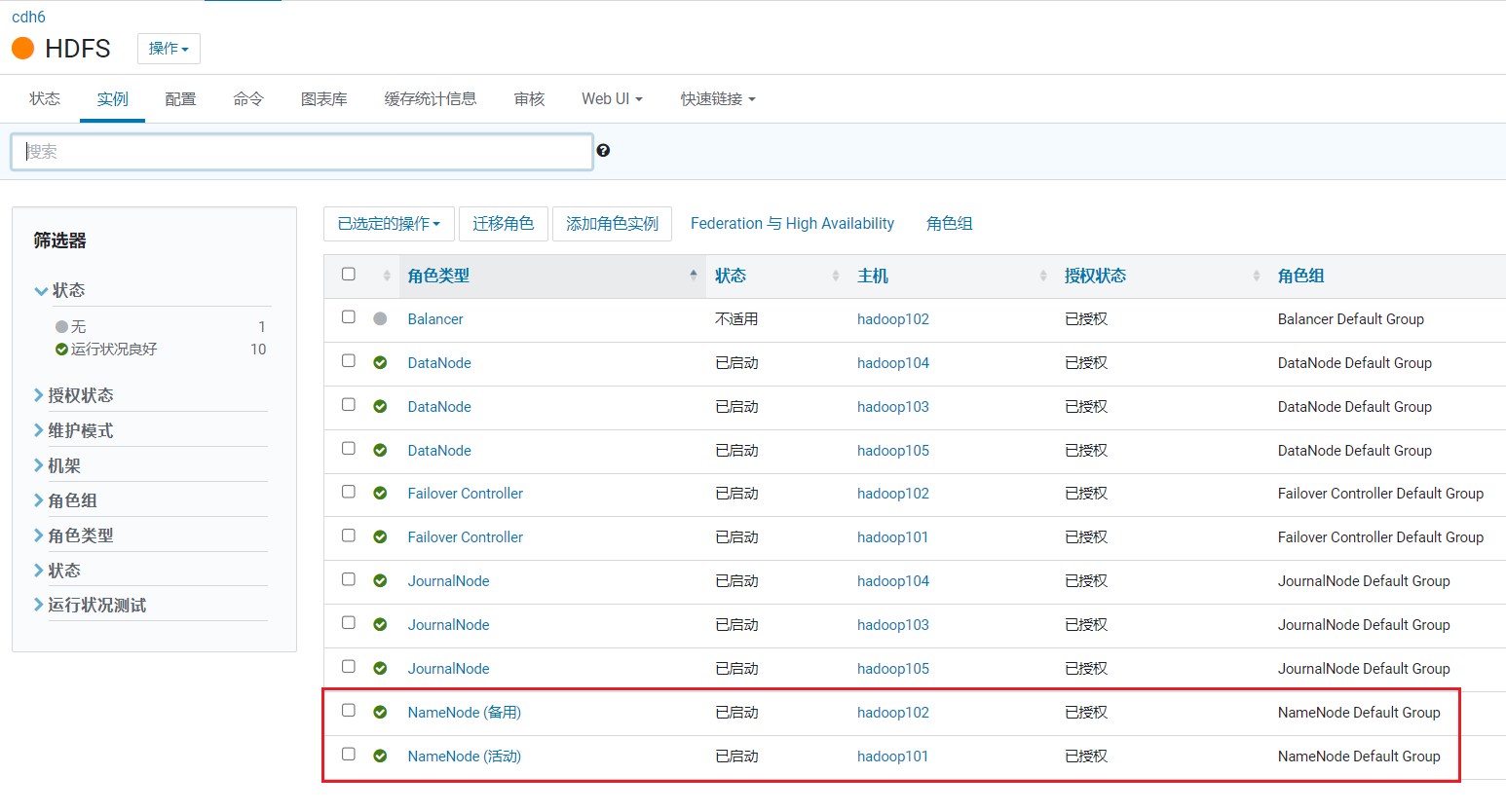
4. 配置Yarn的HA
在首页点击YARN, 进入YARN的页面,点击操作选择启用HA: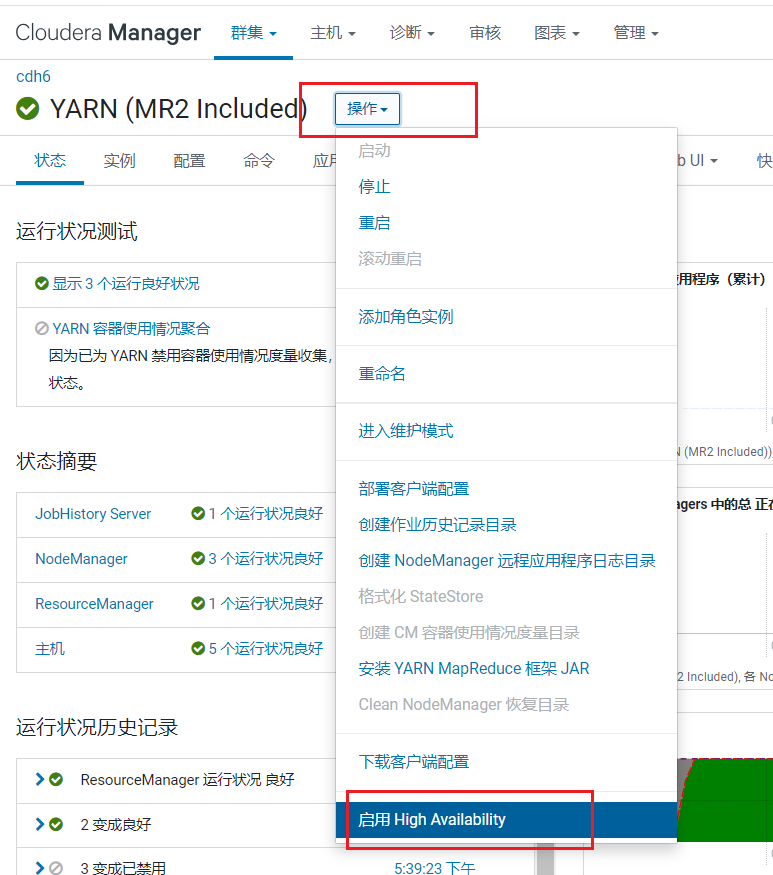 配置节点为hadoop102,点击继续:
配置节点为hadoop102,点击继续: 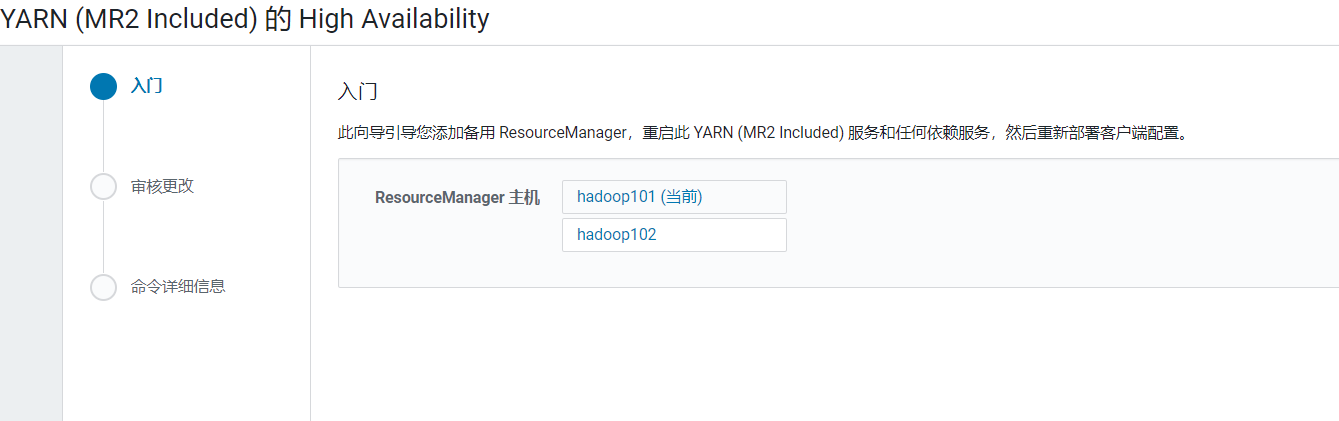 开始进行自动服务:
开始进行自动服务: 完成后,在YARN页面点击实例,可以看到Yarnd的主备已经启用:
完成后,在YARN页面点击实例,可以看到Yarnd的主备已经启用: 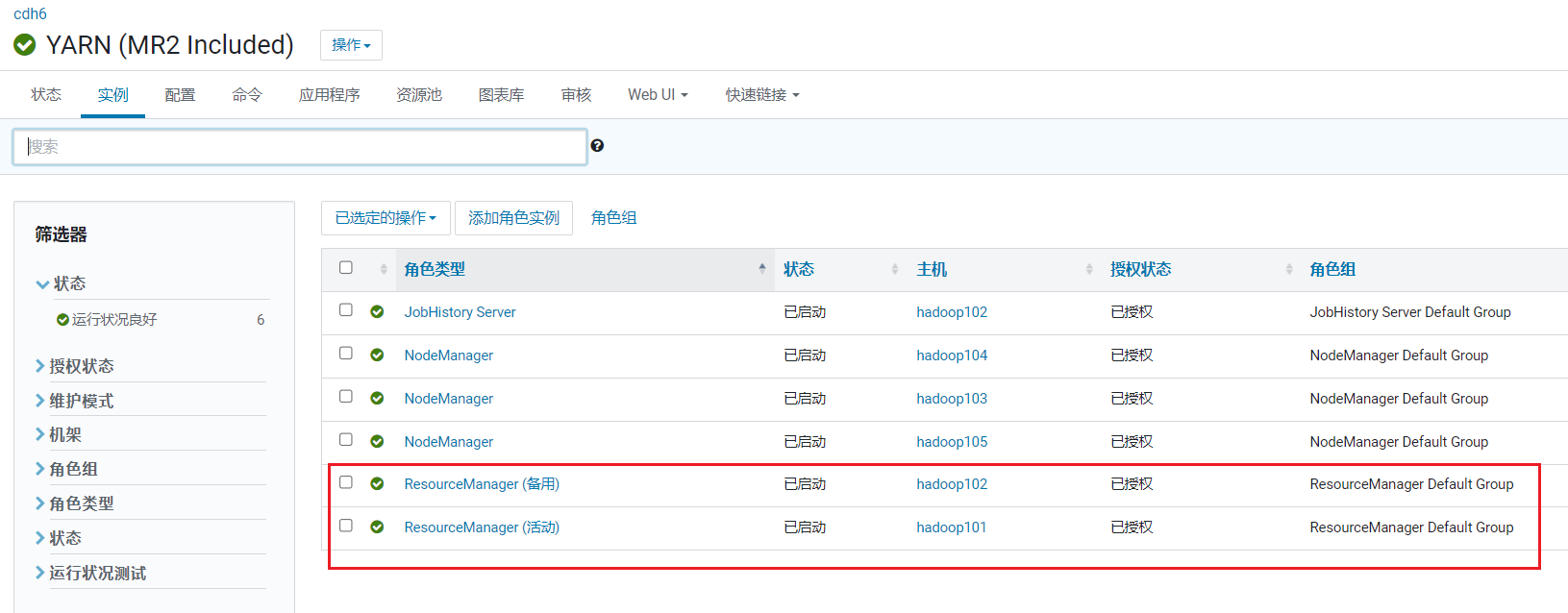
5. 安装Kafka
在首页点击添加服务: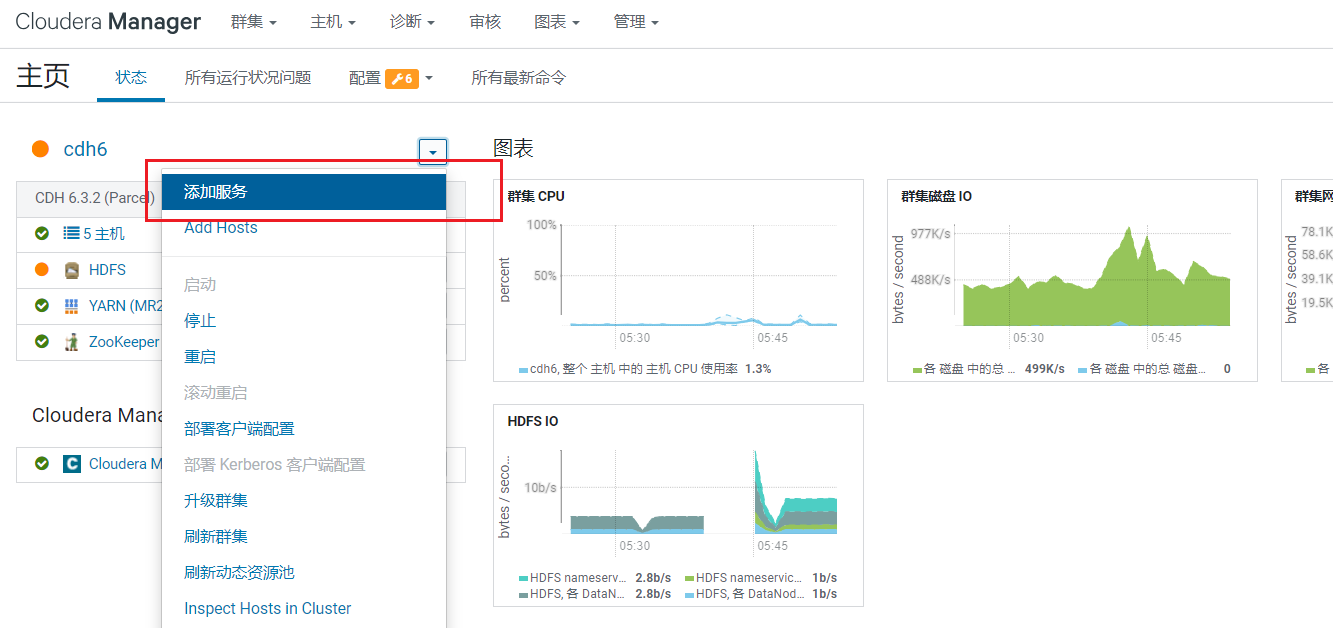 选择服务kafka:
选择服务kafka: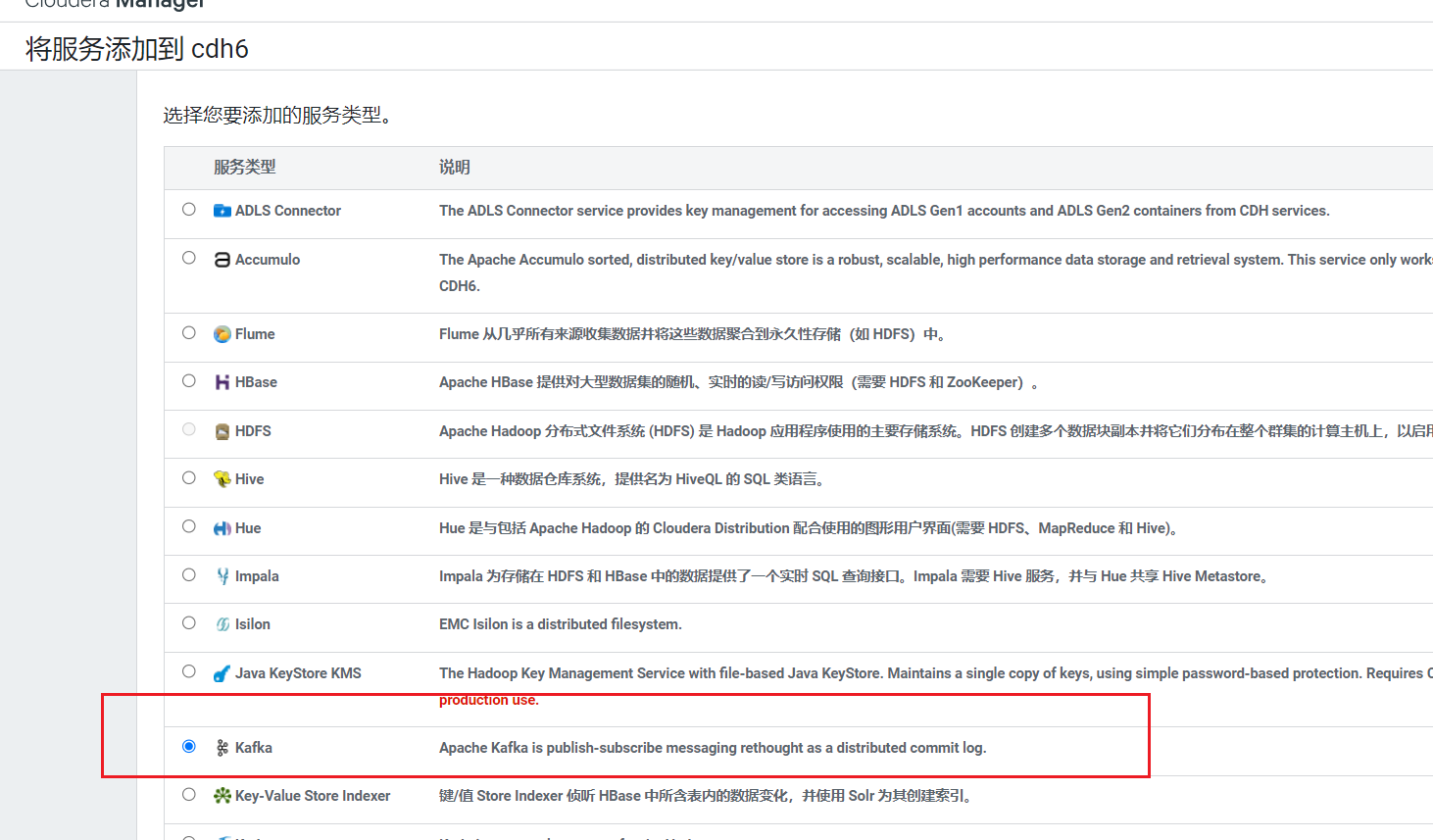 Kafka的Broker选择三台机器, 安装到hadoop103~105上
Kafka的Broker选择三台机器, 安装到hadoop103~105上 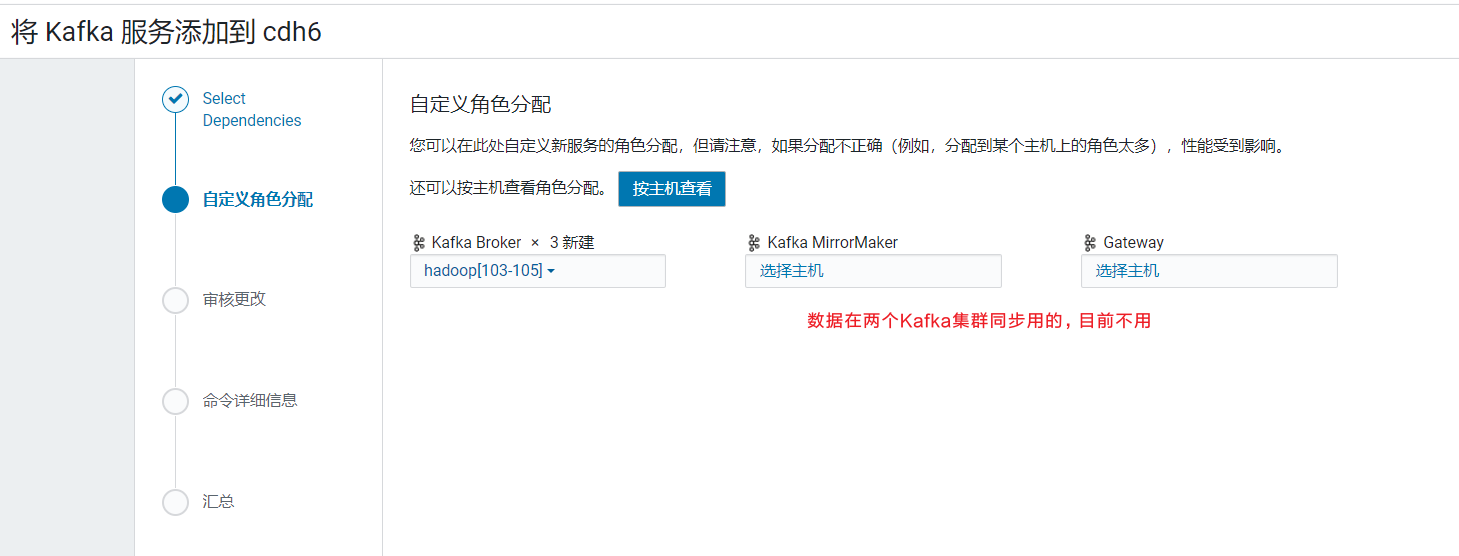 在审核更改页面,修改Kafka的内存大小为1G:
在审核更改页面,修改Kafka的内存大小为1G: 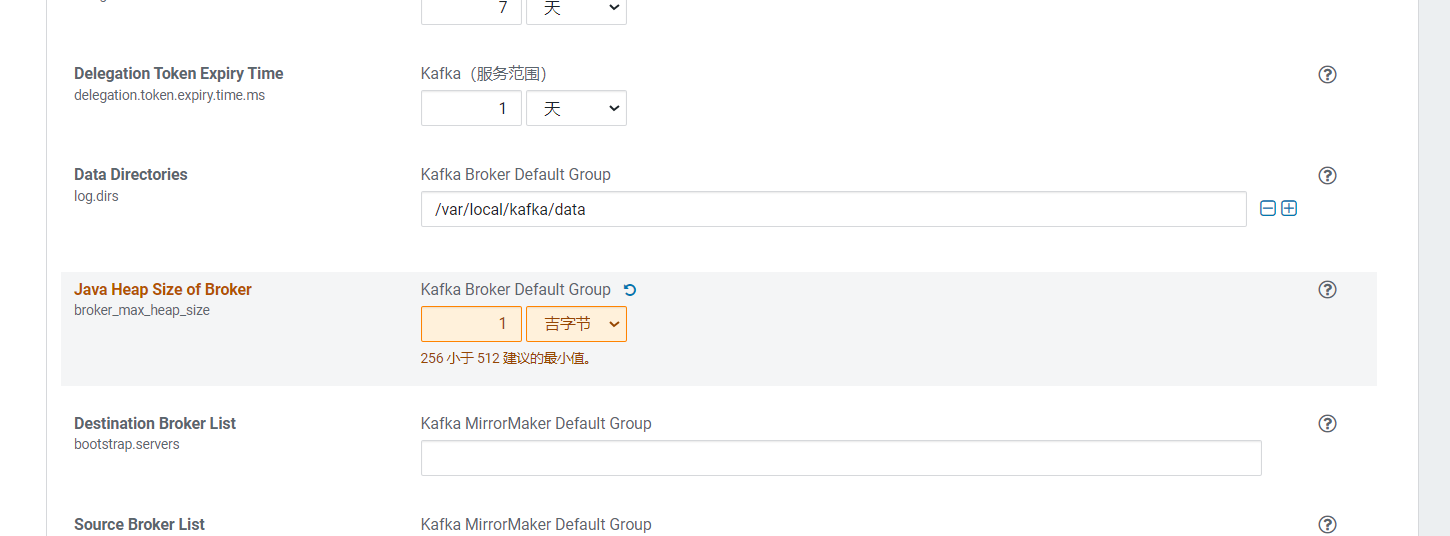 点击继续后,Kafka就开始安装:
点击继续后,Kafka就开始安装: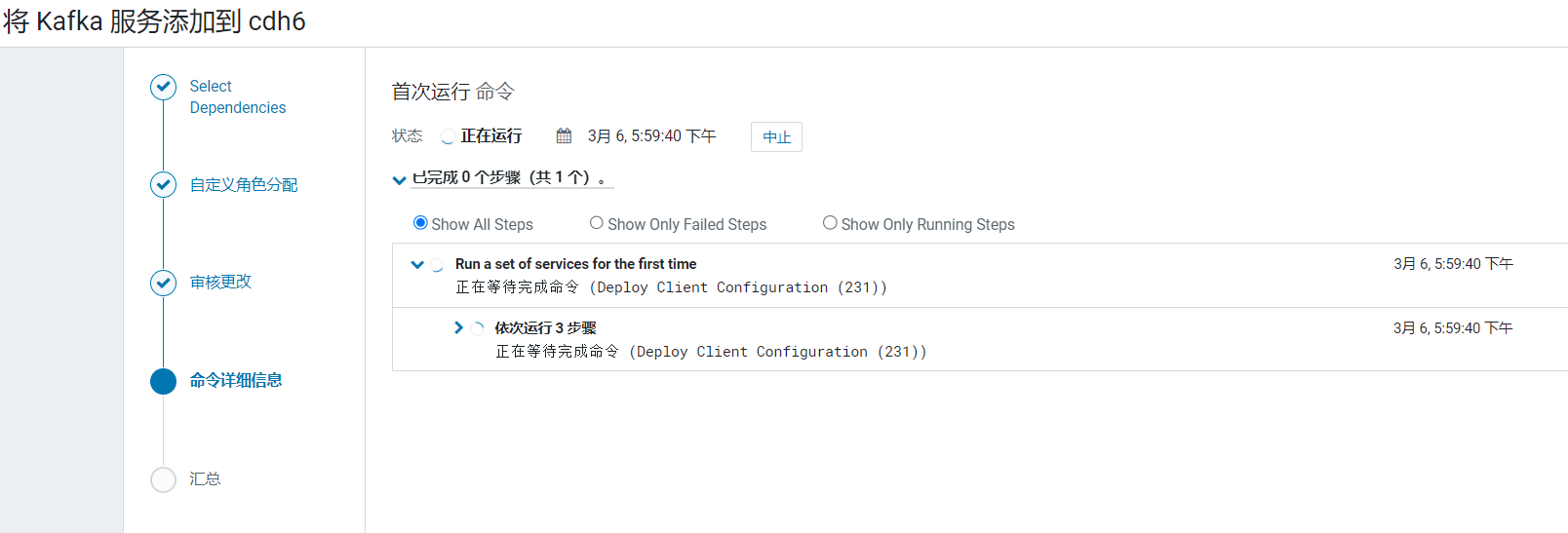 安装完成
安装完成  在命令行中操作:
在命令行中操作:
[root@hadoop101 ~]# kafka-topics --zookeeper hadoop103:2181 --list
[root@hadoop101 ~]# kafka-topics --bootstrap-server hadoop103:9092,hadoop104:9092,hadoop105:9092 --create --replication-factor 1 --partitions 1 --topic test1
[root@hadoop101 ~]# kafka-topics --zookeeper hadoop103:2181 --list
test1使用idea去消费topic:test1 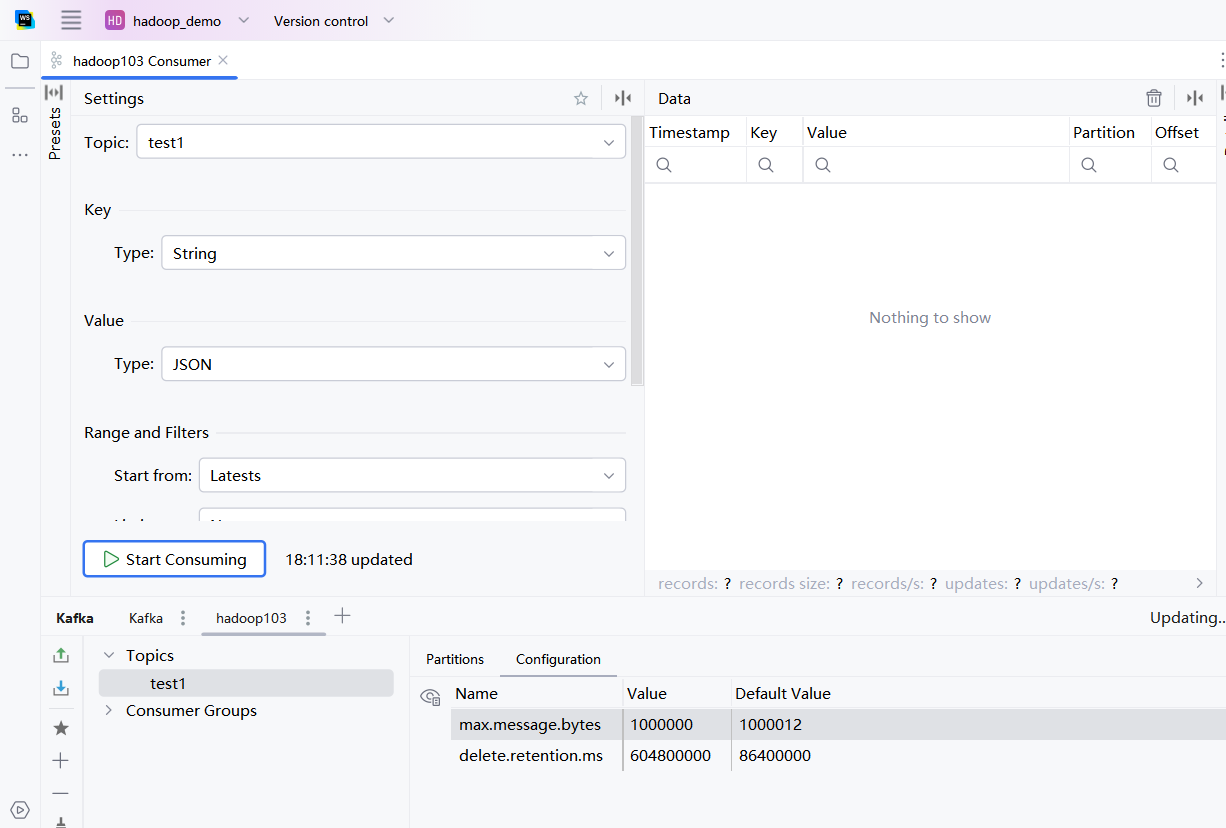
6. Flume安装
在首页点击添加服务: 选择服务Flume: 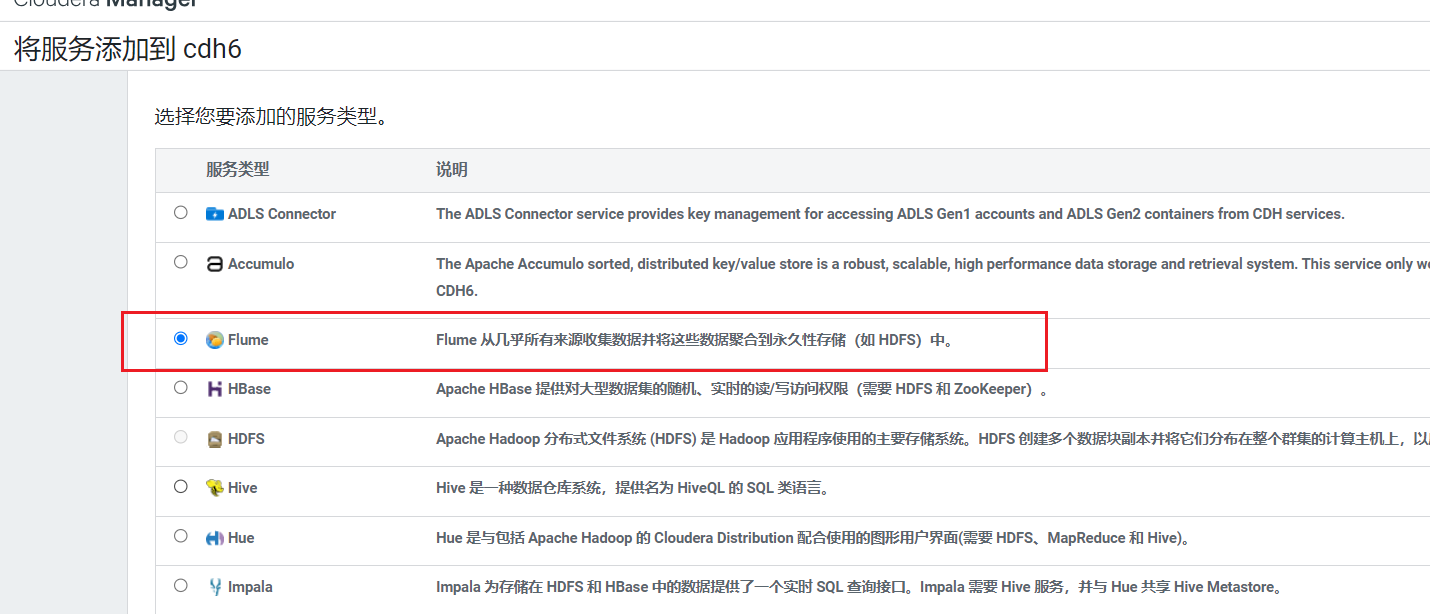
由于已经安装了kafka, flume可以直接整合不用单独配置kafka信息: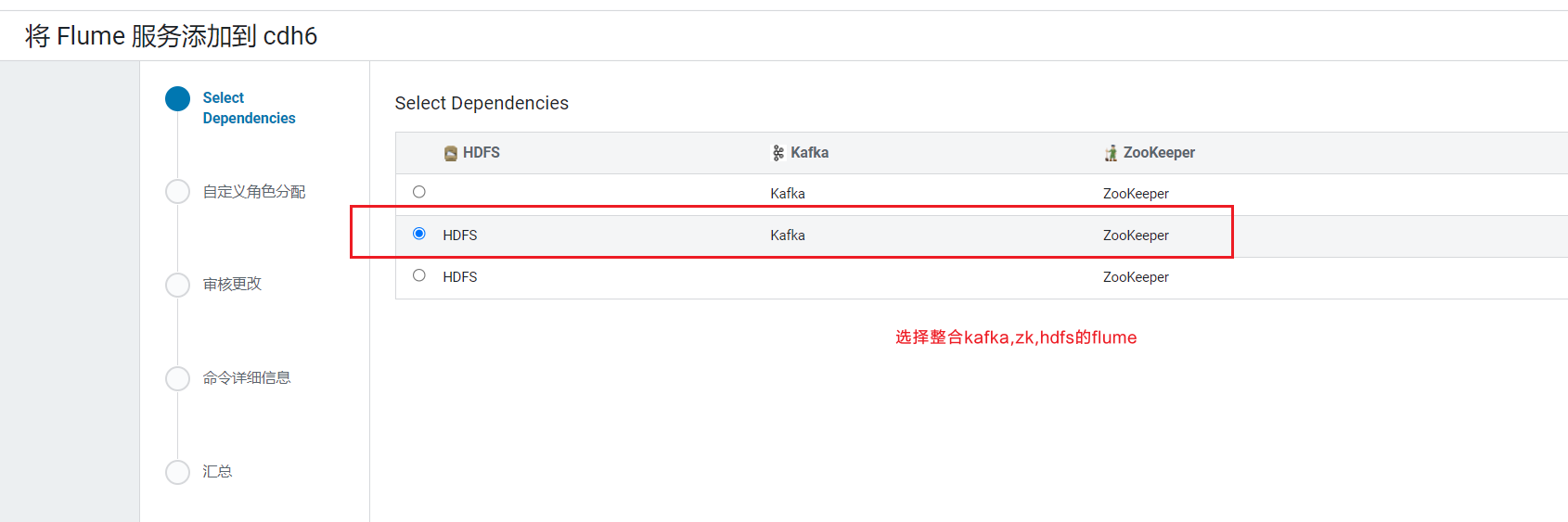 Flume选择三台机器, 安装到hadoop103~105上
Flume选择三台机器, 安装到hadoop103~105上  点击完成,flume的agent安装好了并没有启动
点击完成,flume的agent安装好了并没有启动  点击完成,回到首页,点击启动flume:
点击完成,回到首页,点击启动flume: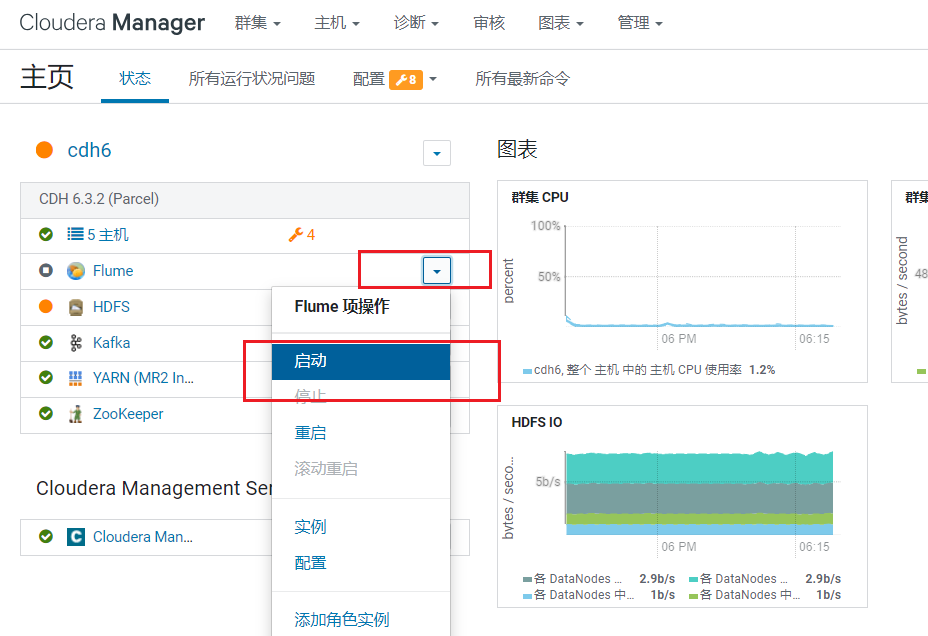 弹出启动信息框,启动完成后点击关闭:
弹出启动信息框,启动完成后点击关闭: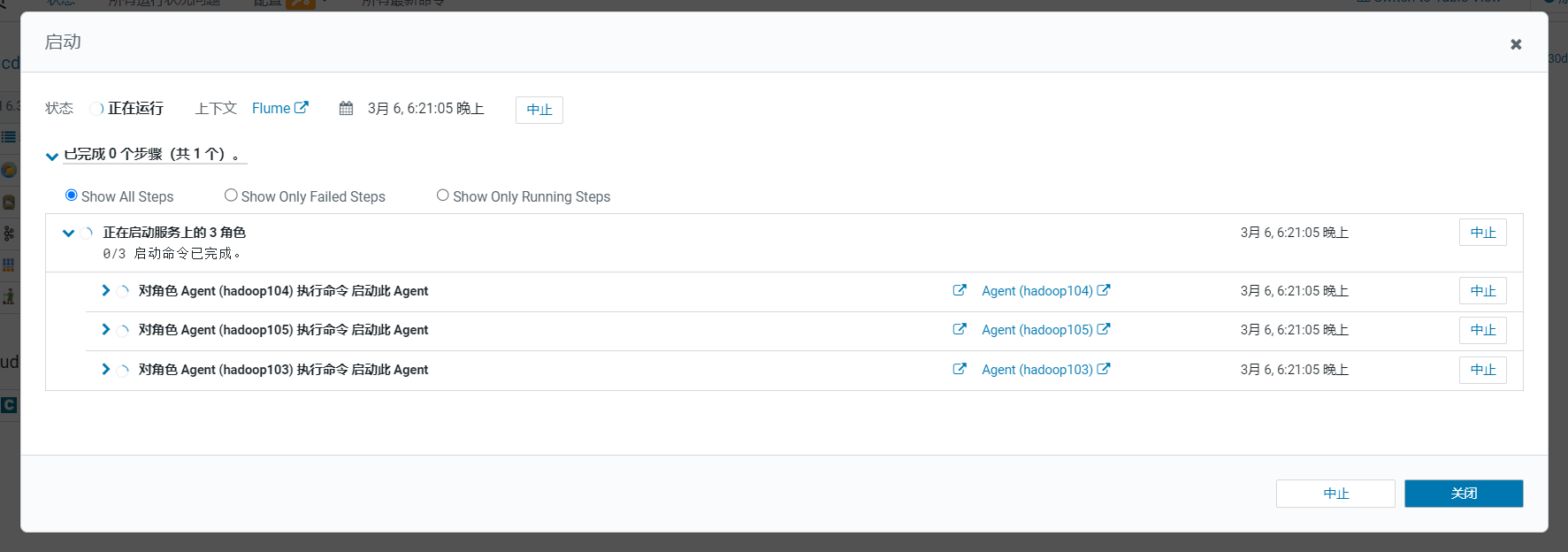 在首页可以看到flume目前是启动状态:
在首页可以看到flume目前是启动状态: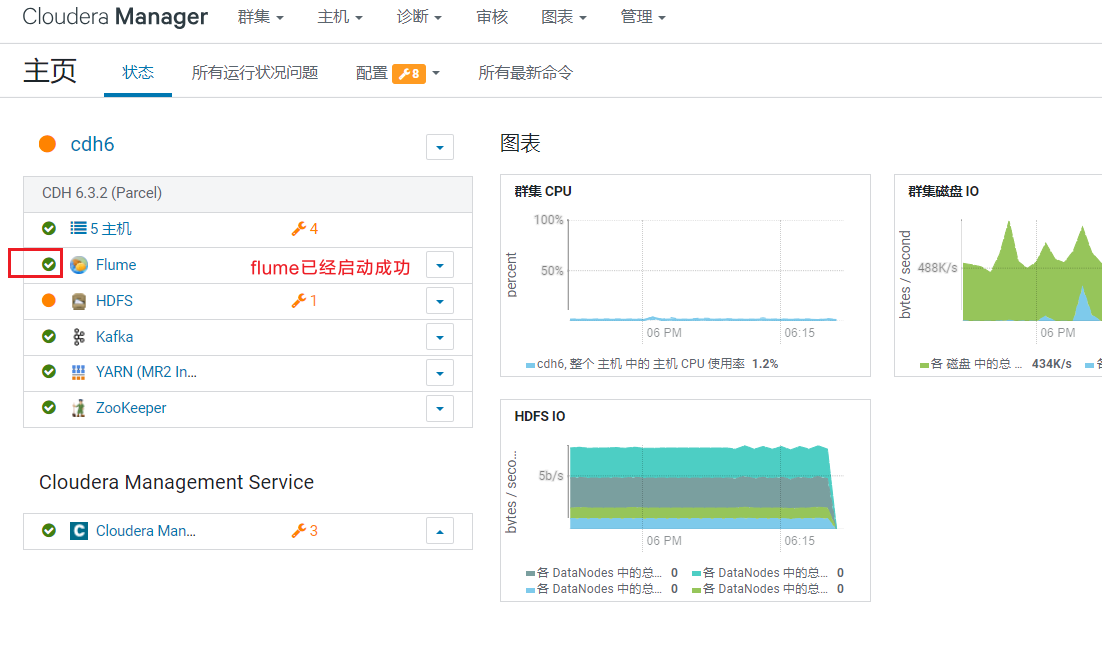
7. Hive安装
在首页点击添加服务: 选择服务Hive: 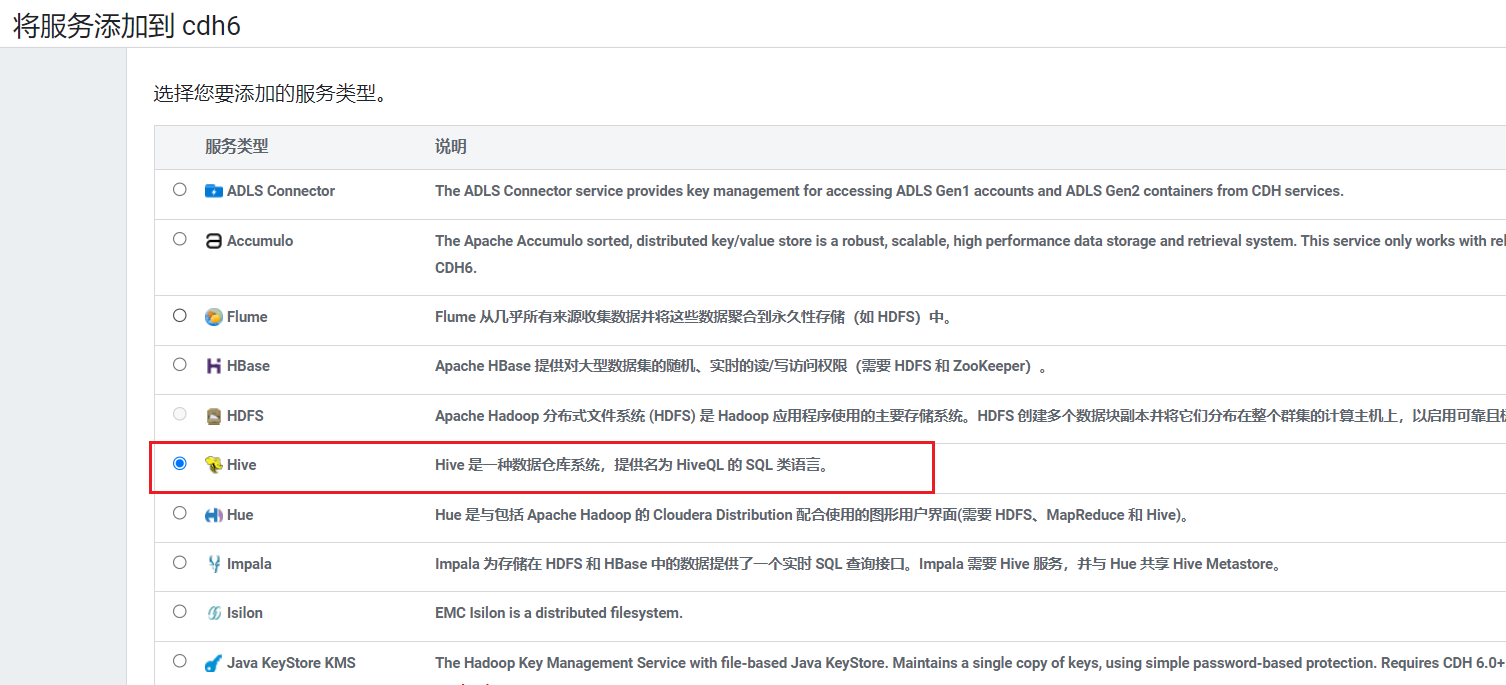 选择节点,gateway在5台机器都安装,hadoop102安装metastore和hiveserver2:
选择节点,gateway在5台机器都安装,hadoop102安装metastore和hiveserver2: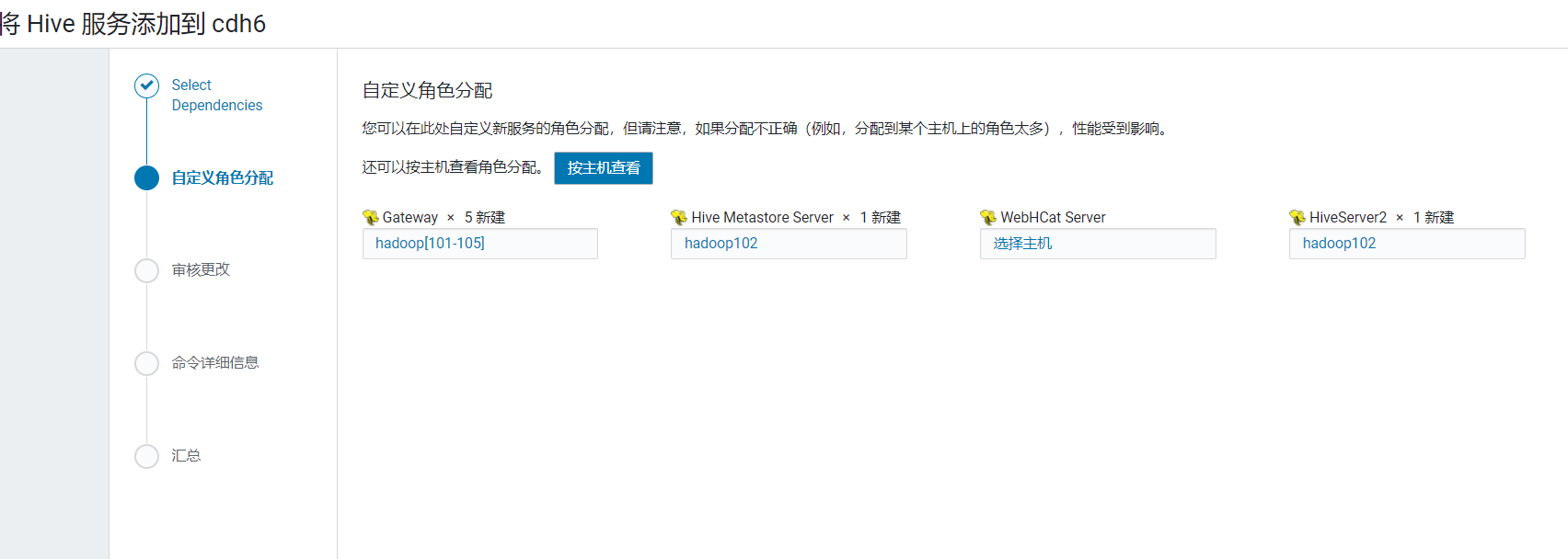 配置配置hive元数据,使用之前创建hive数据库,测试通过后继续:
配置配置hive元数据,使用之前创建hive数据库,测试通过后继续: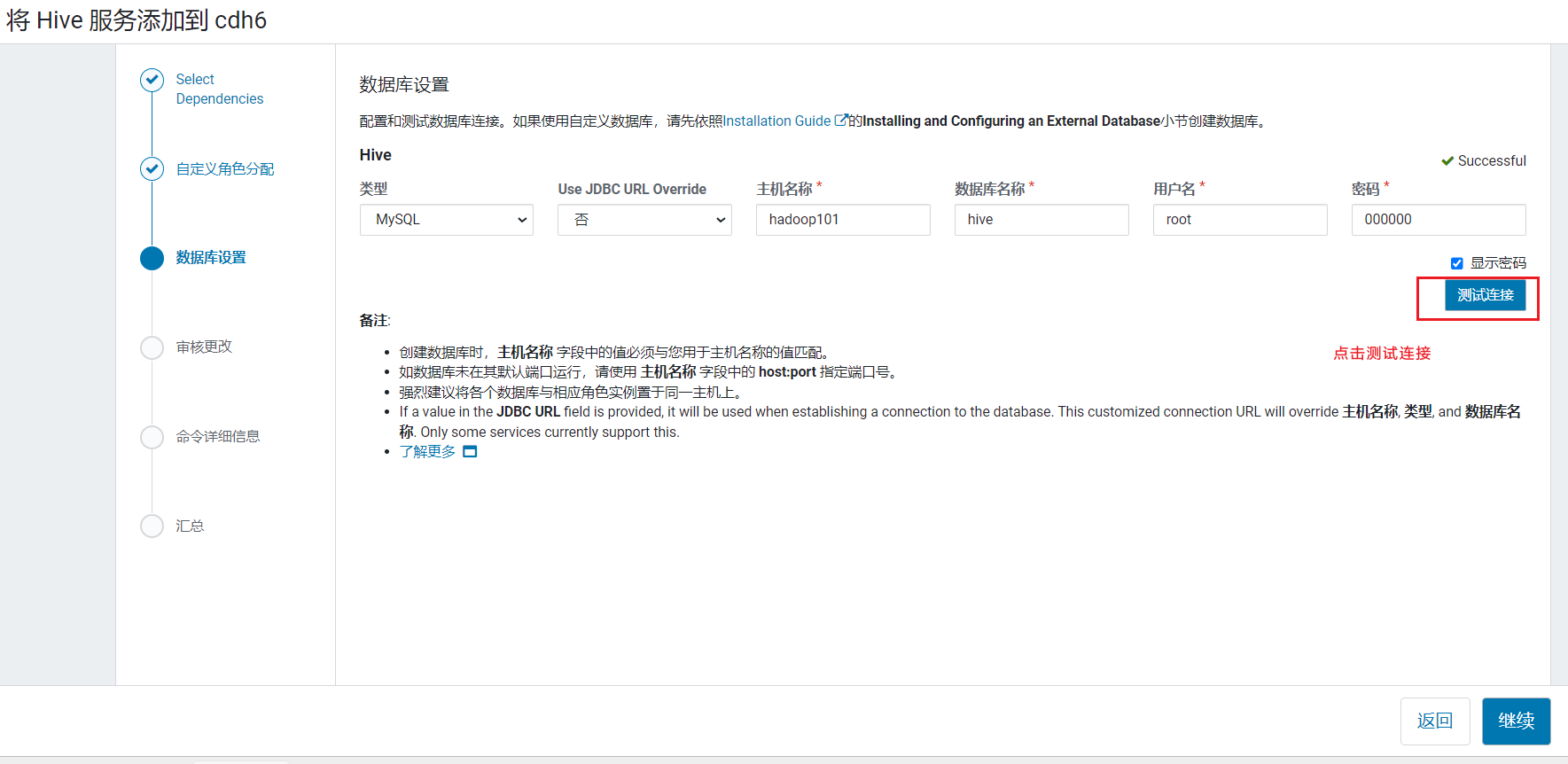 进入hive的仓库地址配置,默认直接点击继续:
进入hive的仓库地址配置,默认直接点击继续: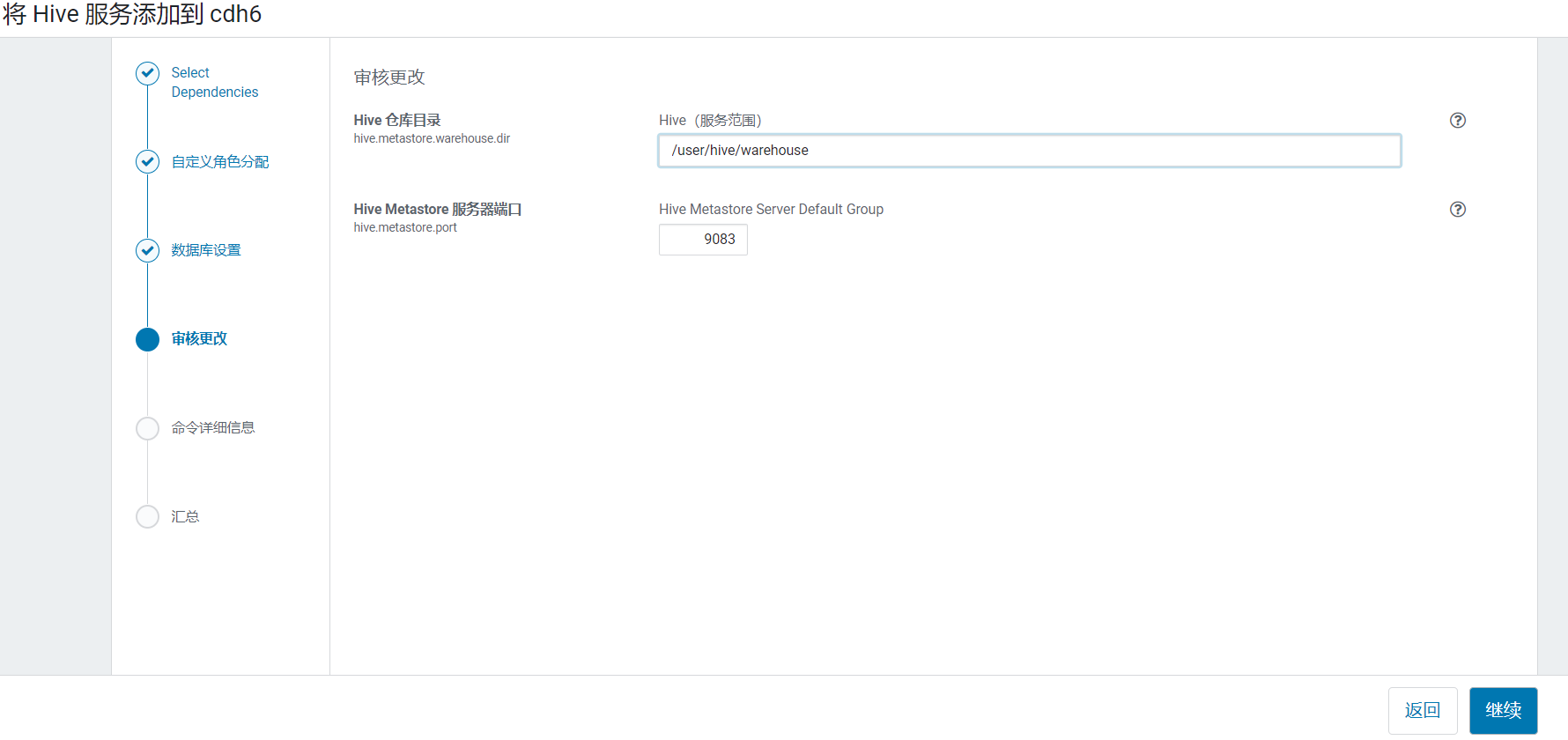 点击继续开始安装,启动Hive进程:
点击继续开始安装,启动Hive进程: 点击完成:
点击完成:
8. 安装spark
在首页点击添加服务: 选择服务Spark:  进入节点分配页面,将HistoryServer安装在hadoop103上:
进入节点分配页面,将HistoryServer安装在hadoop103上: 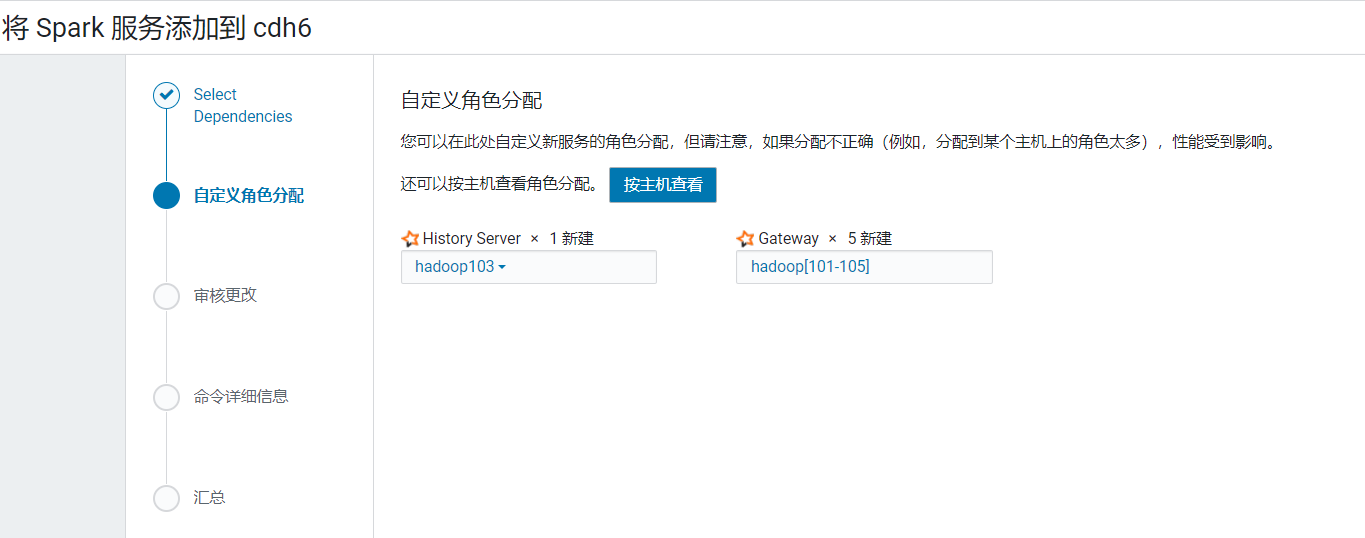 默认即可,点击继续:
默认即可,点击继续: 点击继续开始安装:
点击继续开始安装: 点击完成:
点击完成: 自动回到首页,点击spark旁边的按钮,重启生效配置:
自动回到首页,点击spark旁边的按钮,重启生效配置: 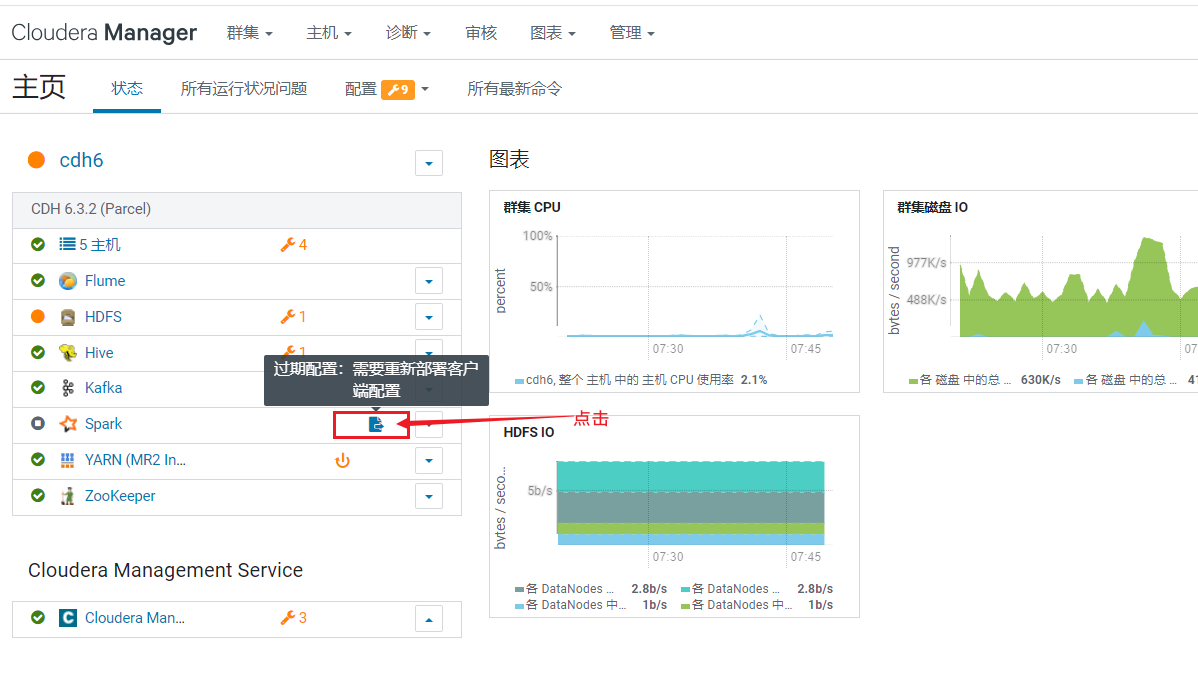 点击重启过时服务:
点击重启过时服务: 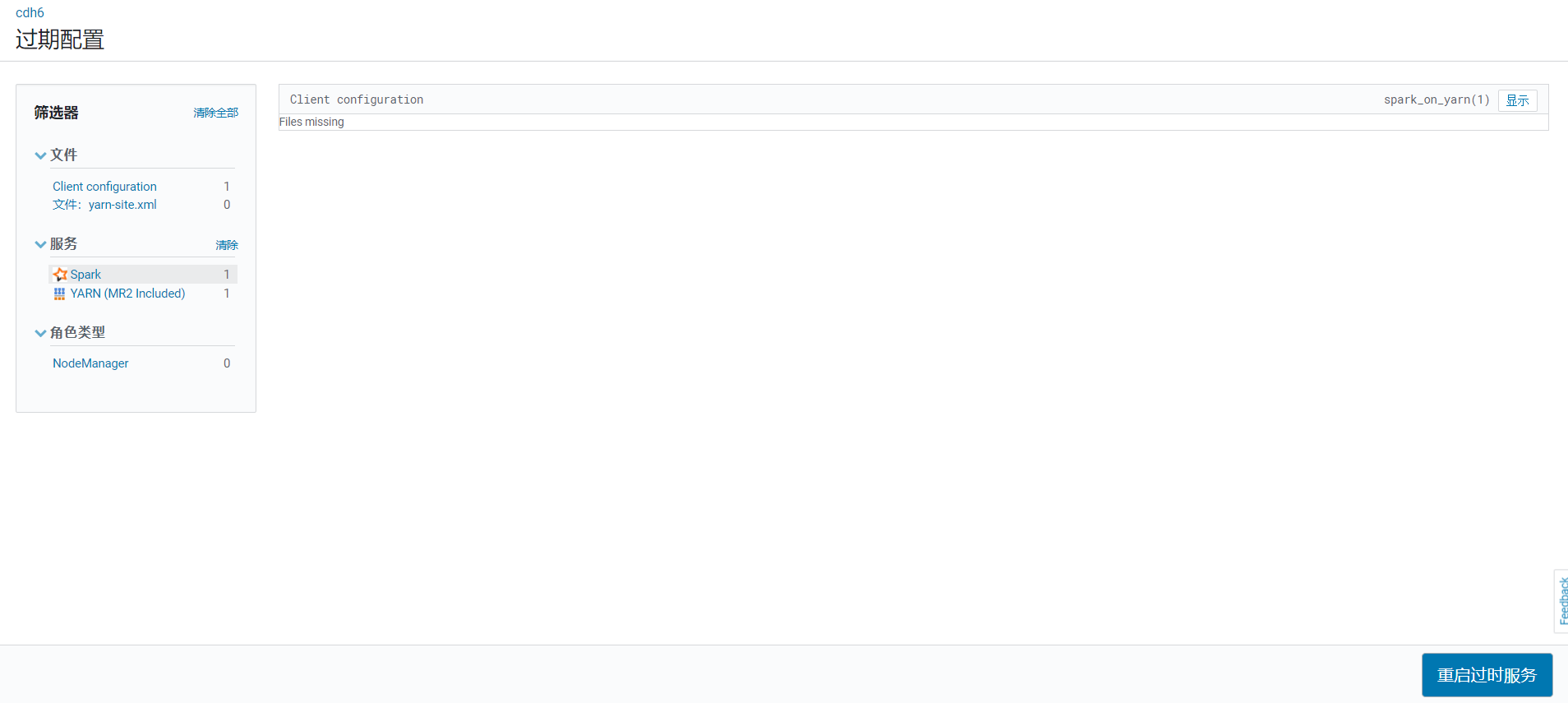 点击立即重启:
点击立即重启: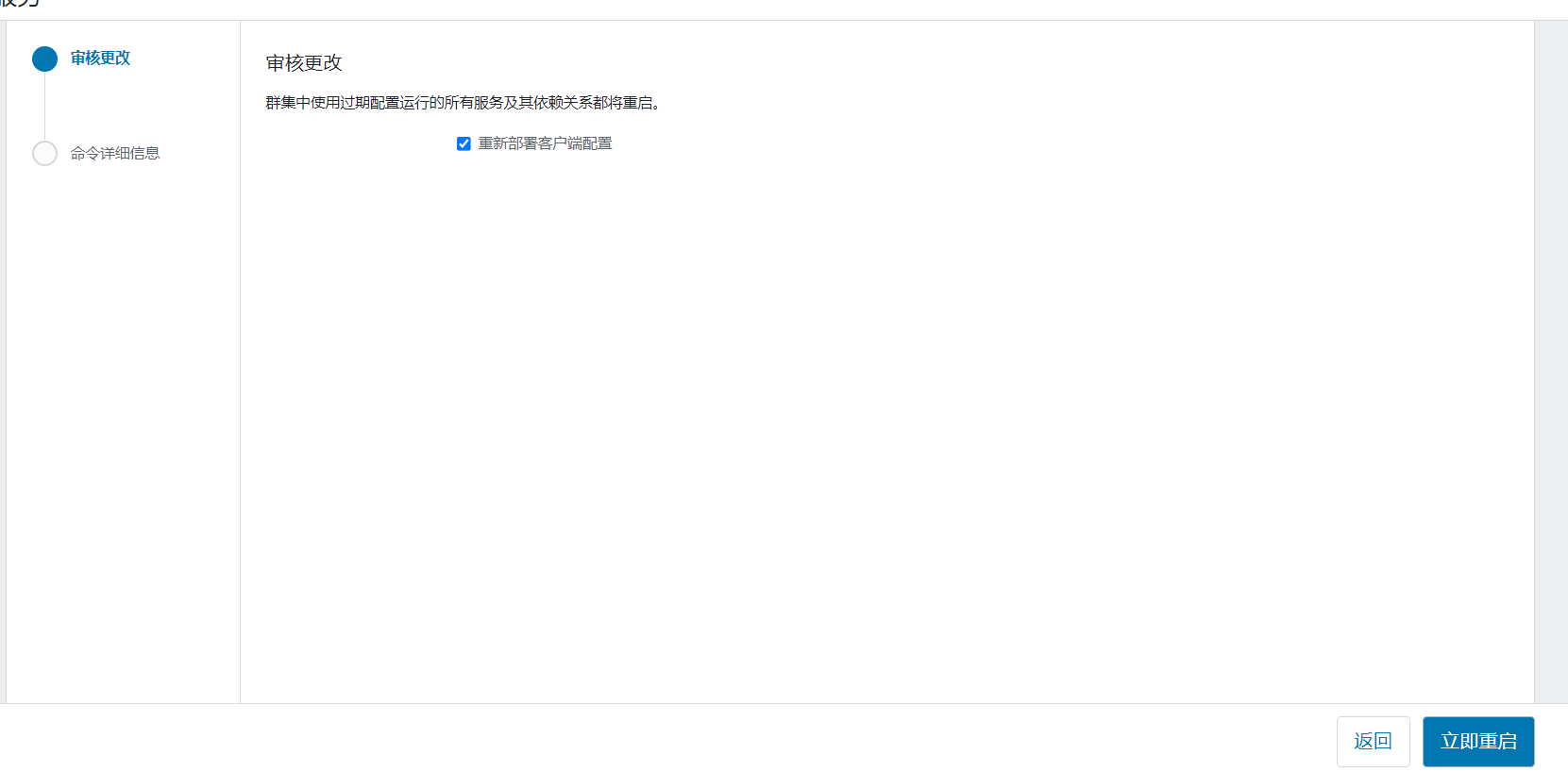 开始重启:
开始重启: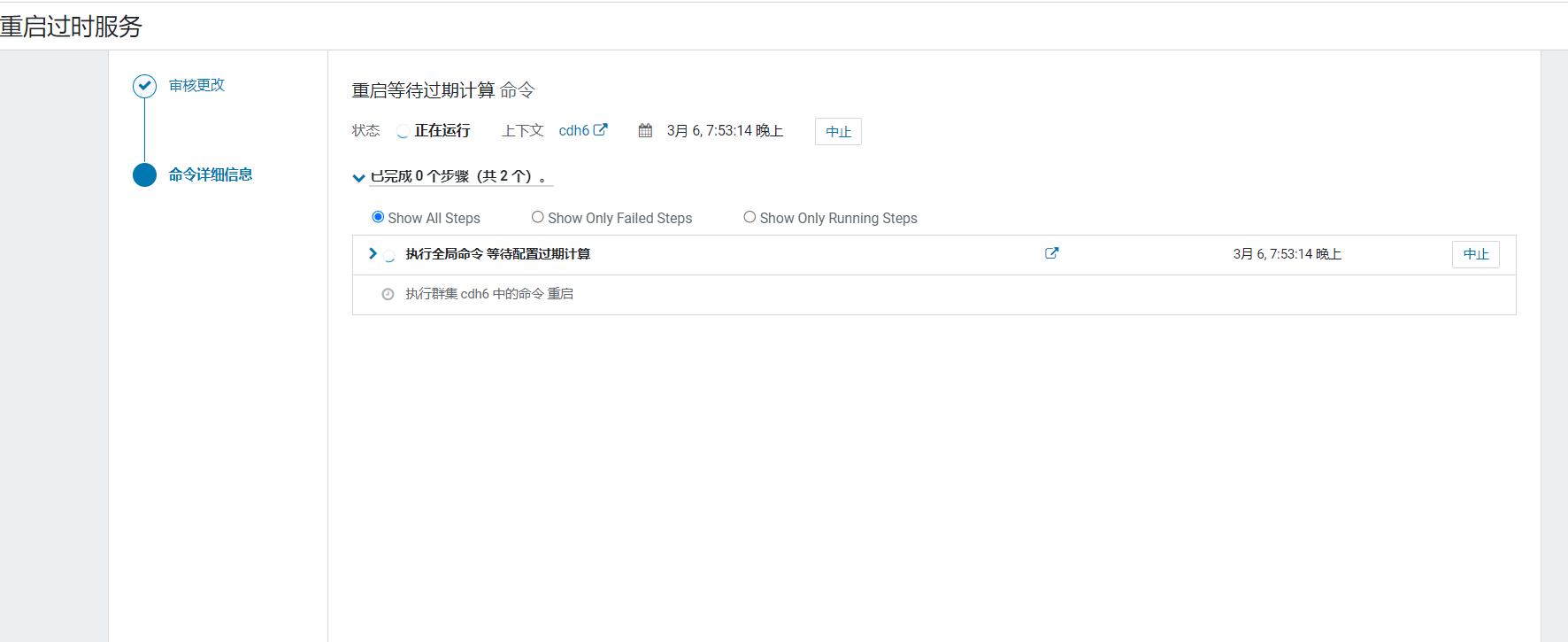 重启后回到首页,Spark状态就正常了:
重启后回到首页,Spark状态就正常了: 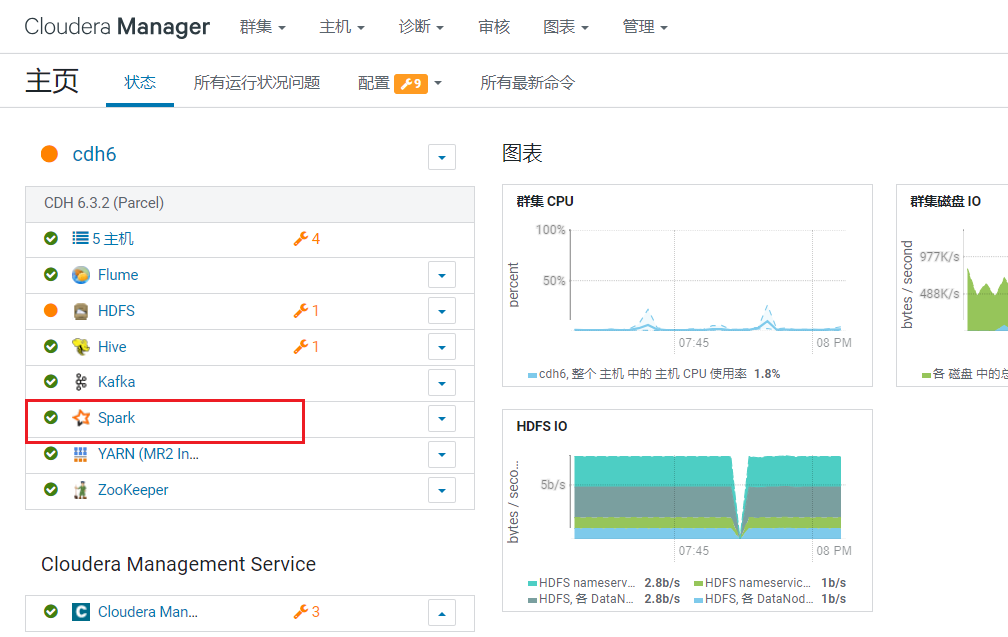
9. 安装Oozie
首页添加服务,选择服务Oozie: 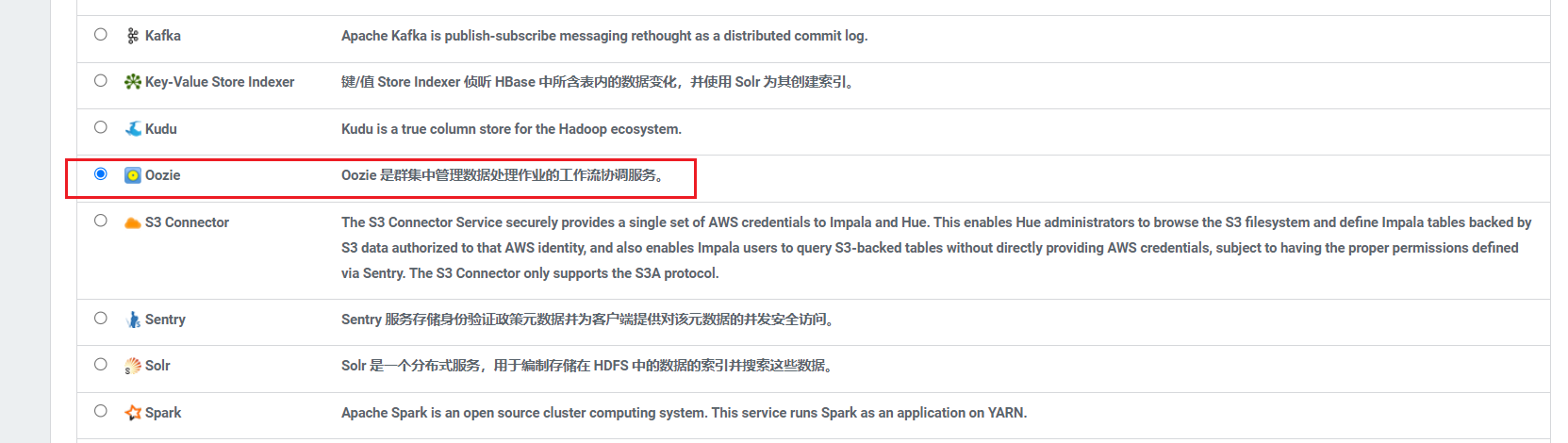 选择集成对多的服务那一栏:
选择集成对多的服务那一栏: 将Oozie部署在hadoop101:
将Oozie部署在hadoop101: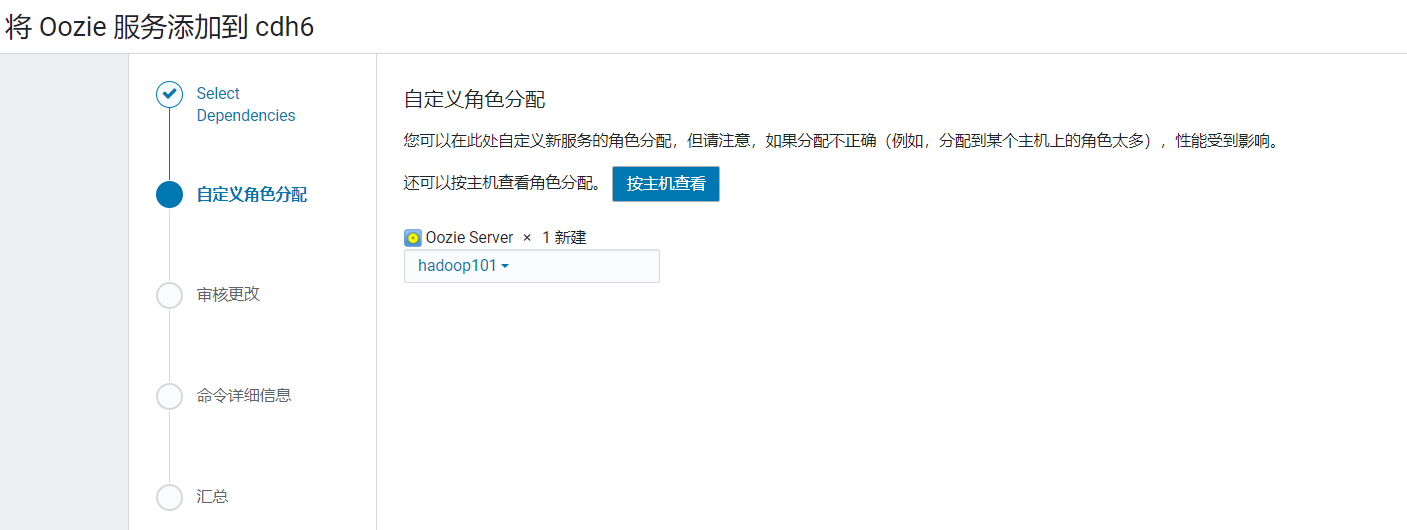 配置使用之前创建的oozie数据库:
配置使用之前创建的oozie数据库: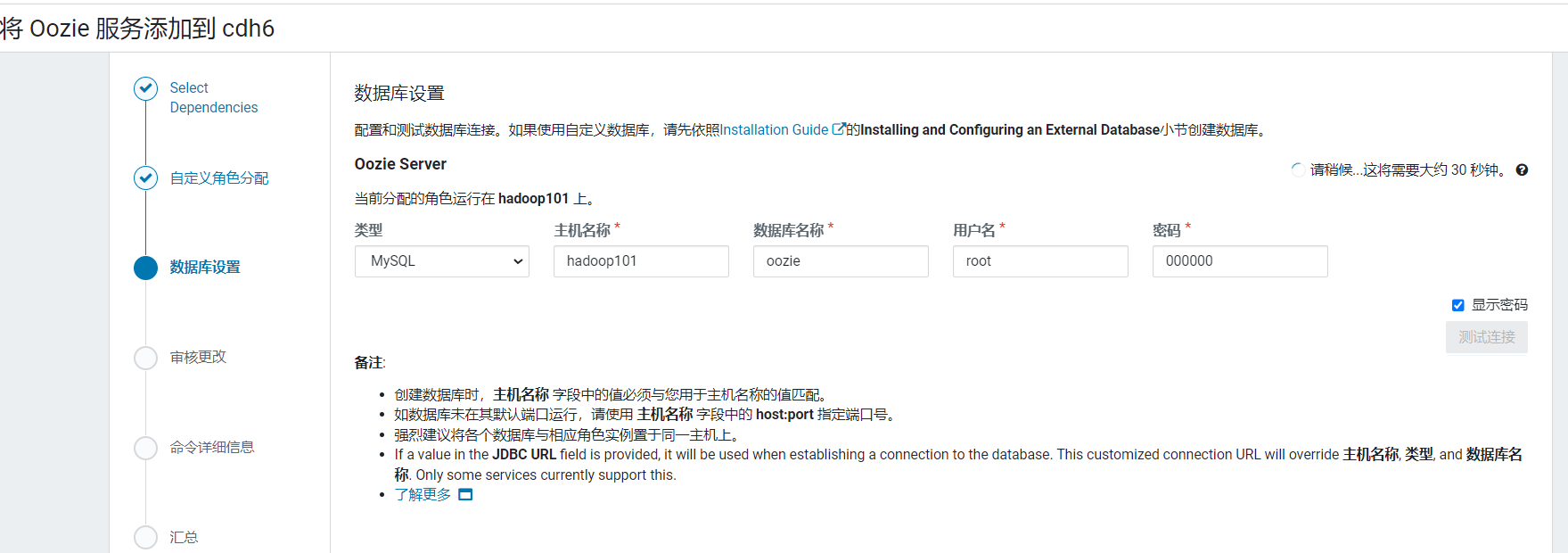 默认配置不用更改:
默认配置不用更改: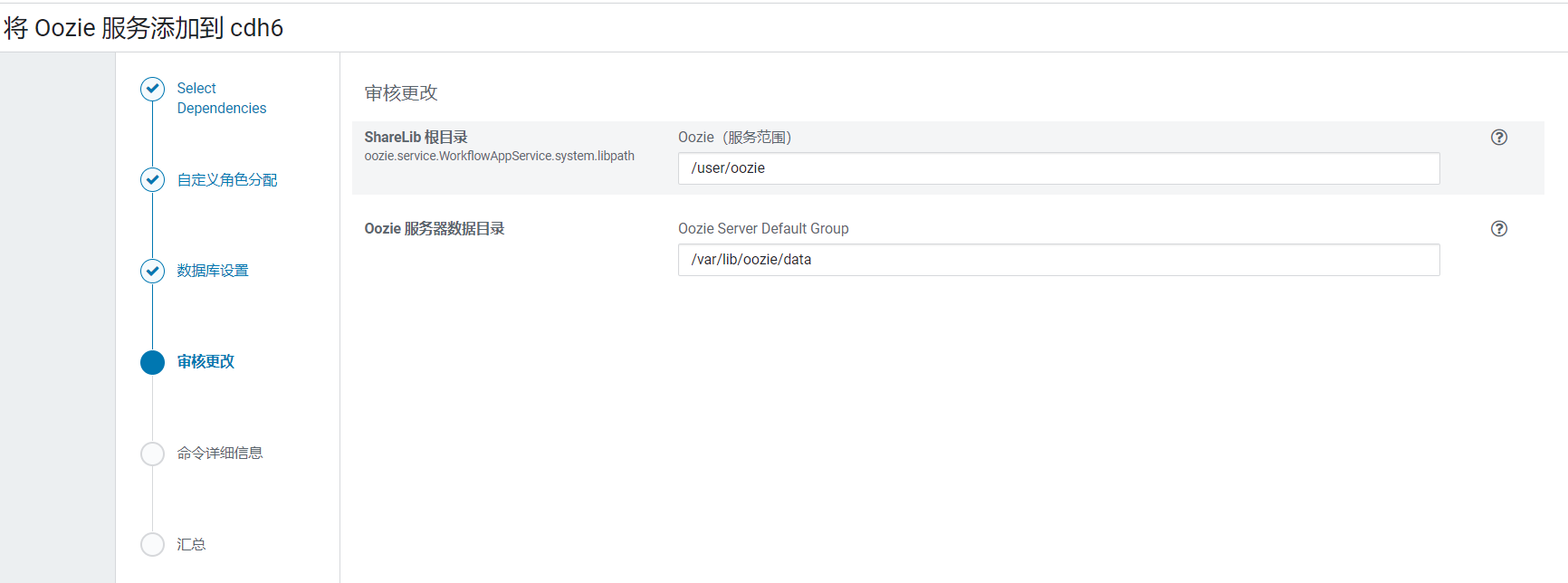 开始安装Oozie:
开始安装Oozie: 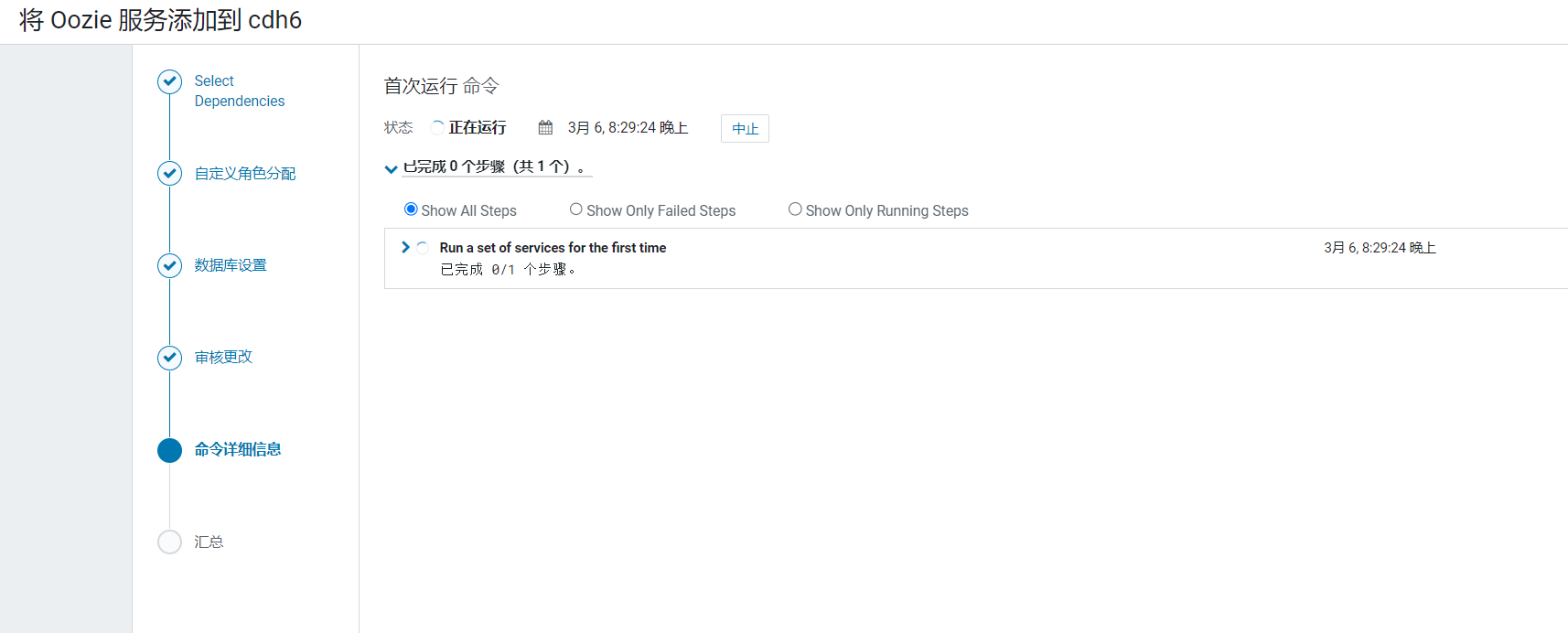 安装完成后,点击完成按钮:
安装完成后,点击完成按钮: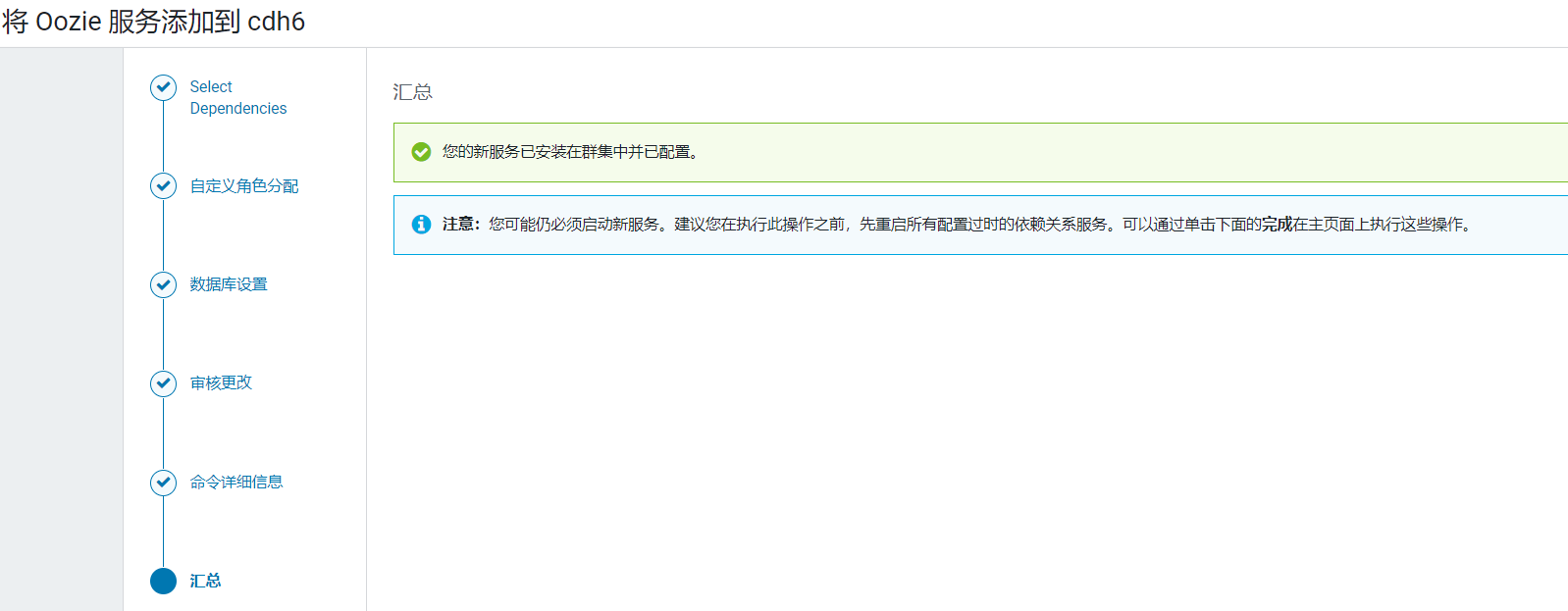
10. 安装HUE
首页添加服务,选择服务Hue:  选择依赖最多的,点击继续:
选择依赖最多的,点击继续: 节点分配配置页面,选择hue安装在hadoop104上:
节点分配配置页面,选择hue安装在hadoop104上: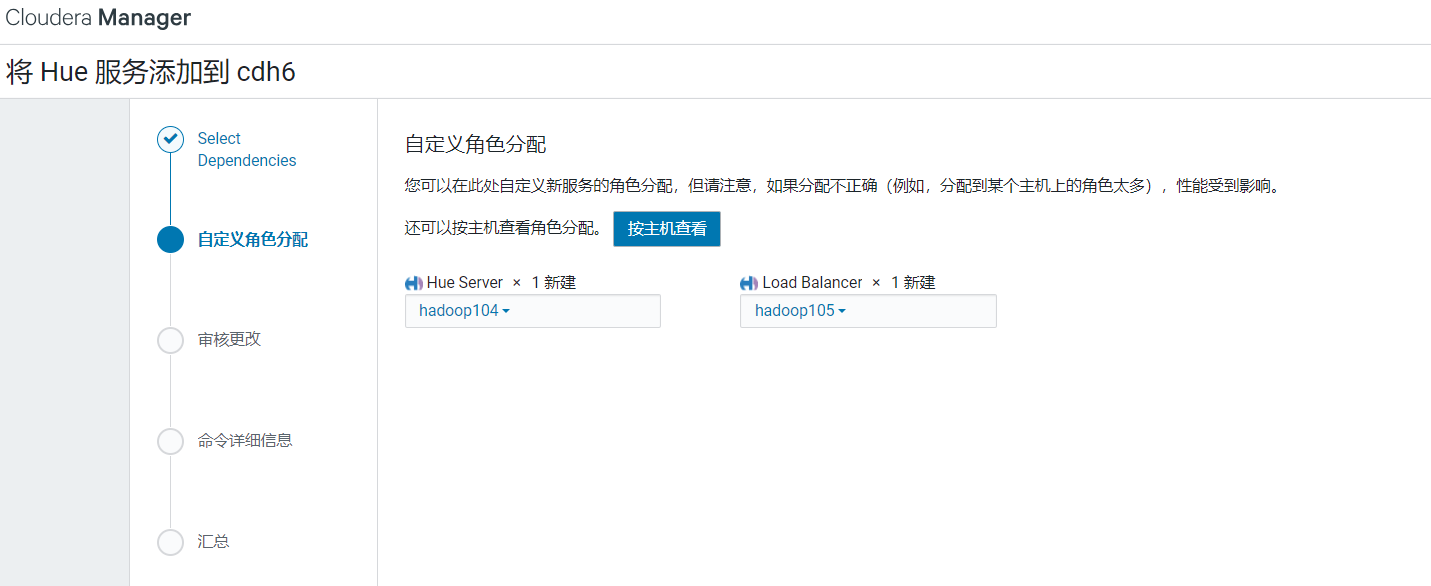 配置hue元数据:
配置hue元数据: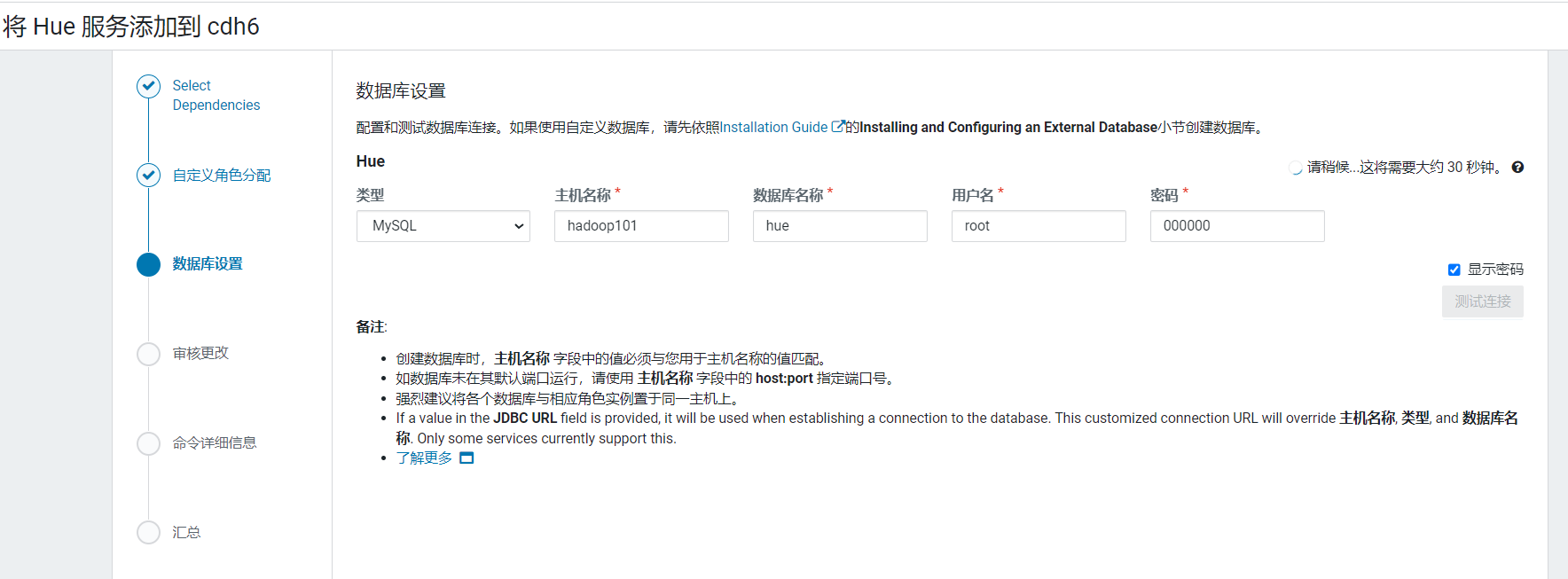 开始进行安装:
开始进行安装: 安装完成后,点击完成按钮:
安装完成后,点击完成按钮: 回到首页后,点击Hue进入Hue页面:
回到首页后,点击Hue进入Hue页面: 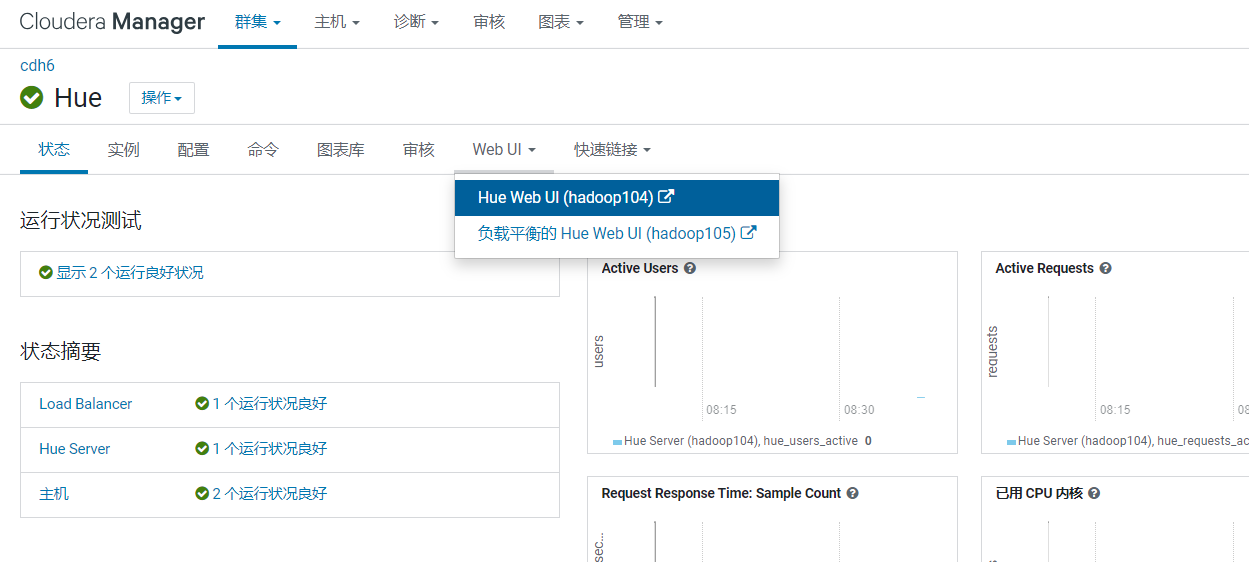 点击webui菜单项,选择Hue Web UI:
点击webui菜单项,选择Hue Web UI: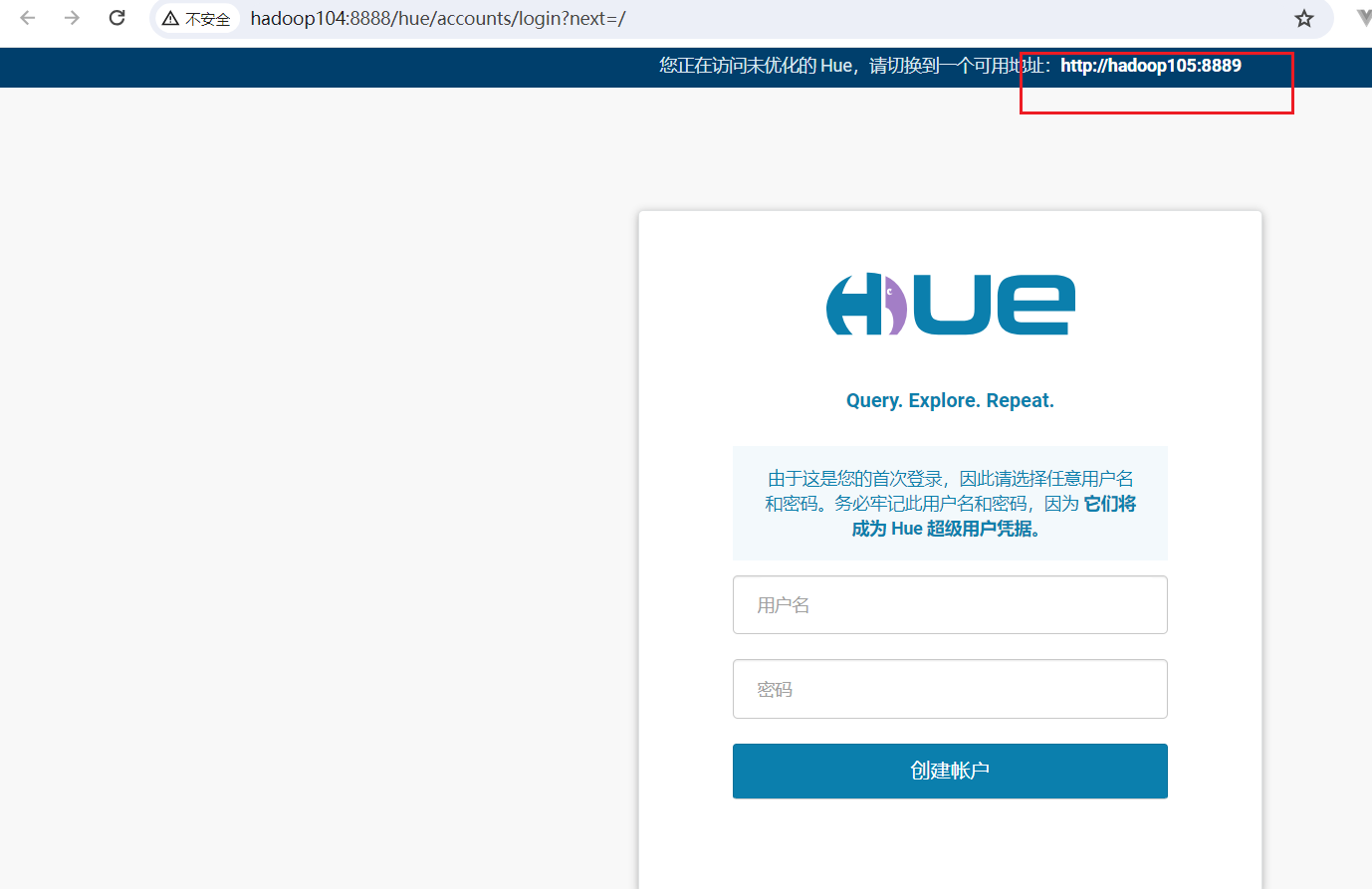 提示我们没有走负载均衡,重新访问http://hadoop105:8889/
提示我们没有走负载均衡,重新访问http://hadoop105:8889/ 首次登陆hue需要登陆hue的账号密码, 最好这里使用hdfs用户(比如hive)。因为hdfs用户可以操作hdfs中的文件,如果使用其他用户只能在当前用户的目录下创建文件。
首次登陆hue需要登陆hue的账号密码, 最好这里使用hdfs用户(比如hive)。因为hdfs用户可以操作hdfs中的文件,如果使用其他用户只能在当前用户的目录下创建文件。