Redis之布隆过滤器
由一个初值都为零的bit数组和多个哈希函数构成用来快速判断集合中是否存在某个元素 
1. 特性
- 减少内存占用
- 不保存数据信息,只是在内存中做一个是否存在的标记flag
2. 产生背景
它实际上是一个很长的二进制数组(00000000)+一系列随机hash算法映射函数,主要用于判断一个元素是否在集合中。 通常我们会遇到很多要判断一个元素是否在某个集合中的业务场景,一般想到的是将集合中所有元素保存起来,然后通过比较确定。
链表、树、哈希表等等数据结构都是这种思路。但是随着集合中元素的增加,我们需要的存储空间也会呈现线性增长,最终达到瓶颈。同时检索速度也越来越慢,上述三种结构的检索时间复杂度分别为O(n),O(logn),O(1)。这个时候,布隆过滤器(Bloom Filter)就应运而生
3. 原理
一个元素如果判断结果:存在时,元素不一定存在。但是判断结果为不存在时,则一定不存在
布隆过滤器可以添加元素,但是不能删除元素。
布隆过滤器(Bloom Filter) 是一种专门用来解决去重问题的高级数据结构。实质就是一个大型位数组和几个不同的无偏hash函数(无偏表示分布均匀)。由一个初值都为零的bit数组和多个个哈希函数构成,用来快速判断某个数据是否存在。但是跟HyperLogLog一样,它也一样有那么一点点不精确,也存在一定的误判概率。
3.1 添加key时
使用多个hash函数对key进行hash运算得到一个整数索引值,对位数组长度进行取模运算得到一个位置,每个hash函数都会得到一个不同的位置,将这几个位置都置1就完成了add操作。当有变量被加入集合时,通过N个映射函数将这个变量映射成位图中的N个点,把它们置为1(假定有两个变量都通过3个映射函数)。 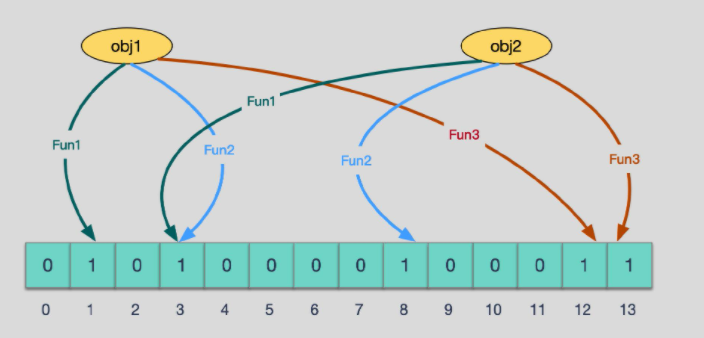
3.2 查询key时
只要有其中一位是零就表示这个key不存在,但如果都是1,则不一定存在对应的key。
正是基于布隆过滤器的快速检测特性,我们可以在把数据写入数据库时,使用布隆过滤器做个标记。当缓存缺失后,应用查询数据库时,可以通过查询布隆过滤器快速判断数据是否存在。如果不存在,就不用再去类据库中查询了。这样一来,即使发生缓存穿透了,大量请求只会查询Redis和布隆过滤器,而不会积压到数据库,也就不会影响数据库的正常运行。布降过滤器可以使用Redis实现,本身就能承担较大的并发访问压力。
4. 使用
redis的setbit/getbit
5. 代码实现
布隆过滤器白名单初始化工具类,一开始就设置一部分数据为白名单所有,
@Component
@Slf4j
public class BloomFilterInit
{
@Resource
private RedisTemplate redisTemplate;
@PostConstruct//初始化白名单数据,故意差异化数据演示效果......
public void init()
{
//白名单客户预加载到布隆过滤器
String uid = "customer:12";
//1 计算hashcode,由于可能有负数,直接取绝对值
int hashValue = Math.abs(uid.hashCode());
//2 通过hashValue和2的32次方取余后,获得对应的下标坑位
long index = (long) (hashValue % Math.pow(2, 32));
log.info(uid+" 对应------坑位index:{}",index);
//3 设置redis里面bitmap对应坑位,该有值设置为1
redisTemplate.opsForValue().setBit("whitelistCustomer", index, true);
}
}编写CheckUtils:
@Component
@Slf4j
public class CheckUtils
{
@Resource
private RedisTemplate redisTemplate;
public boolean checkWithBloomFilter(String checkItem,String key)
{
int hashValue = Math.abs(key.hashCode());
long index = (long) (hashValue % Math.pow(2, 32));
boolean existOK = redisTemplate.opsForValue().getBit(checkItem, index);
log.info("----->key:"+key+"\t对应坑位index:"+index+"\t是否存在:"+existOK);
return existOK;
}
}编写CustomerSerivce:
@Service
@Slf4j
public class CustomerSerivce
{
public static final String CACHE_KEY_CUSTOMER = "customer:";
@Resource
private CustomerMapper customerMapper;
@Resource
private RedisTemplate redisTemplate;
@Resource
private CheckUtils checkUtils;
public void addCustomer(Customer customer){
int i = customerMapper.insertSelective(customer);
if(i > 0)
{
//到数据库里面,重新捞出新数据出来,做缓存
customer=customerMapper.selectByPrimaryKey(customer.getId());
//缓存key
String key=CACHE_KEY_CUSTOMER+customer.getId();
//往mysql里面插入成功随后再从mysql查询出来,再插入redis
redisTemplate.opsForValue().set(key,customer);
}
}
public Customer findCustomerById(Integer customerId){
Customer customer = null;
//缓存key的名称
String key=CACHE_KEY_CUSTOMER+customerId;
//1 查询redis
customer = (Customer) redisTemplate.opsForValue().get(key);
//redis无,进一步查询mysql
if(customer==null)
{
//2 从mysql查出来customer
customer=customerMapper.selectByPrimaryKey(customerId);
// mysql有,redis无
if (customer != null) {
//3 把mysql捞到的数据写入redis,方便下次查询能redis命中。
redisTemplate.opsForValue().set(key,customer);
}
}
return customer;
}
/**
* BloomFilter → redis → mysql
* 白名单:whitelistCustomer
*/
@Resource
private CheckUtils checkUtils;
public Customer findCustomerByIdWithBloomFilter (Integer customerId)
{
Customer customer = null;
//缓存key的名称
String key = CACHE_KEY_CUSTOMER + customerId;
//布隆过滤器check,无是绝对无,有是可能有
//===============================================
if(!checkUtils.checkWithBloomFilter("whitelistCustomer",key))
{
log.info("白名单无此顾客信息:{}",key);
return null;
}
//===============================================
//1 查询redis
customer = (Customer) redisTemplate.opsForValue().get(key);
//redis无,进一步查询mysql
if (customer == null) {
//2 从mysql查出来customer
customer = customerMapper.selectByPrimaryKey(customerId);
// mysql有,redis无
if (customer != null) {
//3 把mysql捞到的数据写入redis,方便下次查询能redis命中。
redisTemplate.opsForValue().set(key, customer);
}
}
return customer;
}
}6. 布隆过滤器优缺点
6.1 优点
高效地插入和查询,内存占用bit空间少
6.2 缺点
不能删除元素。因为删掉元素会导致误判率增加,因为hash冲突同一个位置可能存的东西是多个共有的,你删除一个元素的同时可能也把其它的删除了。