自定义函数
Hive自带了一些函数,比如:max/min等,但是数量有限,当Hive提供的内置函数无法满足你的业务处理需要时, 自己可以通过自定义UDF来方便的扩展。官方文档地址
根据用户自定义函数类别分为以下三种:
- UDF(User-Defined-Function)
一进一出。 - UDAF(User-Defined Aggregation Function)
用户自定义聚合函数,多进一出。
类似于:count/max/min - UDTF(User-Defined Table-Generating Functions)
用户自定义表生成函数,一进多出。
如lateral view explode()
1. 自定义函数步骤
- 继承Hive提供的类
org.apache.hadoop.hive.ql.udf.generic.GenericUDF或者org.apache.hadoop.hive.ql.exec.UDF
org.apache.hadoop.hive.ql.udf.generic.GenericUDTF - 实现类中的抽象方法
- 在hive的命令行窗口创建函数
- 添加jar
- 创建function
- 在hive的命令行窗口删除函数
2. 自定义UDF函数
- 需求: 自定义一个UDF实现计算给定基本数据类型的长度。
- 创建一个Maven工程hive-myfunction
- 导入依赖
xml
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>4.0.0</version>
</dependency>- 创建MyLen类
java
public class MyLen extends GenericUDF {
// ObjectInspector翻译为对象检查器,也就是说initialize可以用来做参数的类型、大小等检查
@Override
public ObjectInspector initialize(ObjectInspector[] objectInspectors) throws UDFArgumentException {
// objectInspectors作为传入的参数类型数组
if(objectInspectors.length!=1){
throw new UDFArgumentException("参数个数只能是1个");
}
if(ObjectInspector.Category.PRIMITIVE!=objectInspectors[0].getCategory()){
throw new UDFArgumentException("参数只支持字符串类型!");
}
PrimitiveObjectInspector primitiveObjectInspector = (PrimitiveObjectInspector) objectInspectors[0];
if(PrimitiveObjectInspector.PrimitiveCategory.STRING != primitiveObjectInspector.getPrimitiveCategory()){
throw new UDFArgumentException("参数只支持字符串类型!");
}
// 校验通过
// 告诉Hive,自定义函数的返回值类型
return PrimitiveObjectInspectorFactory.javaIntObjectInspector;
}
// 函数功能在该方法中实现, 通过前面的校验才会后续执行该方法
@Override
public Object evaluate(DeferredObject[] deferredObjects) throws HiveException {
// deferredObjects一定长度为1并且为字符串类型
// DeferredObject里面有懒加载特性,需要调用get()才能获取真正的值
Object o = deferredObjects[0].get();
if(o == null){
return 0; // 如果值为空
}else{
return o.toString().length();
}
}
// // 用于获取解释的字符串,比如在执行计划时显示信息
@Override
public String getDisplayString(String[] strings) {
return "用于求长度";
}
}- 打成jar包,上传到Hive所在的服务器
sh
[jack@hadoop102 examples]$ pwd
/opt/module/hive-4.0.0/examples
[jack@hadoop102 examples]$ ll
总用量 24
drwxrwxr-x. 3 jack jack 12288 5月 28 22:25 files
-rw-r--r--. 1 jack jack 2935 6月 21 01:08 hive-myfunction-1.0.jar
drwxrwxr-x. 2 jack jack 4096 5月 28 22:25 queries3. 创建临时函数
也就是说创建的临时函数只在Hive的会话里面有效,断开session将失效
- 将jar包添加到hive的classpath
sql
add jar /opt/module/hive-4.0.0/examples/hive-myfunction-1.0.jar;- 创建临时函数与开发好的java类关联
sql
create temporary function my_len
as "com.rocket.MyLen";- 检查自定义函数是否存在
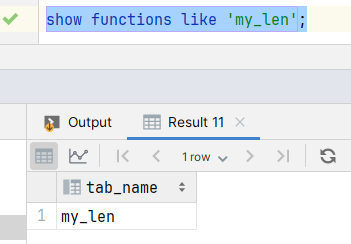
- 使用my_len函数
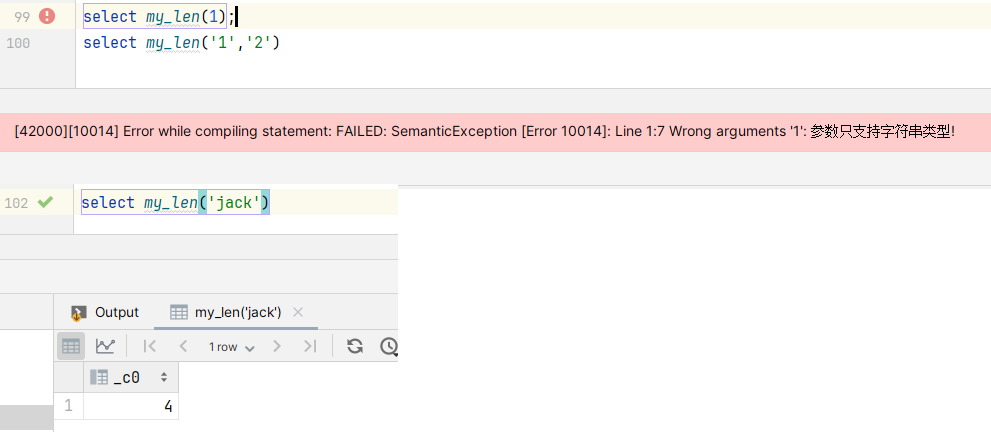
提示
临时函数一般用来测试,测试无误后创建成永久函数
4. 创建永久函数
因为add jar本身命令也是临时生效,所以在创建永久函数的时候,需要重新制定路径,并且因为元数据的原因,这个路径还得是HDFS上的路径
- 上传hive-myfunction-1.0.jar到hdfs上面
sh
[jack@hadoop102 examples]$ hadoop fs -mkdir /udf/
[jack@hadoop102 examples]$ hadoop fs -put /opt/module/hive-4.0.0/examples/hive-myfunction-1.0.jar /udf/- 断开之前的客户端连接,执行下面命令
sql
create function my_len
as "com.rocket.MyLen"
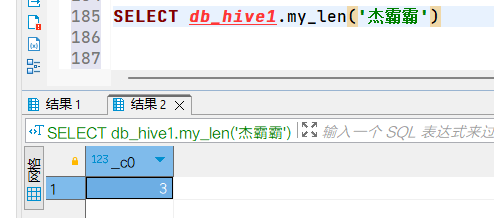
using jar "hdfs://hadoop102:8020/udf/hive-myfunction-1.0.jar";- 检查自定义函数是否存在,发现函数不存在,模糊匹配发现函数名多了数据库名,也不难理解,既然是永久存在肯定会将函数找个地方存起来。
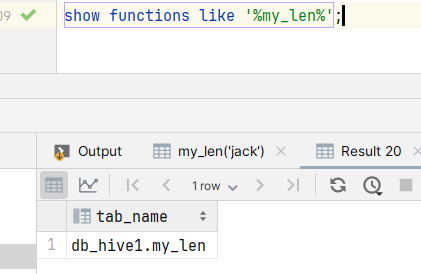
- 使用my_len函数
- 换一个客户端连上hive,执行相同命令发现依然有效