Hive运维
1. Hive服务启动脚本(版本1)
之前启动hiveserver2和metastore都是分别启动的,不太方便,而且也不便于查看日志。
- 创建hive_helper文件
[jack@hadoop102 ~]$ vi ~/bin/hive_helper
#!/bin/bash
HIVE_LOG_DIR=$HIVE_HOME/logs
if [ ! -d $HIVE_LOG_DIR ]
then
mkdir -p $HIVE_LOG_DIR
fi
#检查进程是否运行正常,参数1为进程名,参数2为进程端口
function check_process()
{
pid=$(ps -ef 2>/dev/null | grep -v grep | grep -i $1 | awk '{print $2}')
ppid=$(netstat -nltp 2>/dev/null | grep $2 | awk '{print $7}' | cut -d '/' -f 1)
echo $pid
[[ "$pid" =~ "$ppid" ]] && [ "$ppid" ] && return 0 || return 1
}
function hive_start()
{
metapid=$(check_process HiveMetastore 9083)
cmd="nohup hive --service metastore >$HIVE_LOG_DIR/metastore.log 2>&1 &"
[ -z "$metapid" ] && eval $cmd || echo "Metastroe服务已启动"
server2pid=$(check_process HiveServer2 10000)
cmd="nohup hive --service hiveserver2 >$HIVE_LOG_DIR/hiveServer2.log 2>&1 &"
[ -z "$server2pid" ] && eval $cmd || echo "HiveServer2服务已启动"
}
function hive_stop()
{
metapid=$(check_process HiveMetastore 9083)
[ "$metapid" ] && kill $metapid || echo "Metastore服务未启动"
server2pid=$(check_process HiveServer2 10000)
[ "$server2pid" ] && kill $server2pid || echo "HiveServer2服务未启动"
}
case $1 in
"start")
hive_start
;;
"stop")
hive_stop
;;
"restart")
hive_stop
sleep 2
hive_start
;;
"status")
check_process HiveMetastore 9083 >/dev/null && echo "Metastore服务运行正常" || echo "Metastore服务运行异常"
check_process HiveServer2 10000 >/dev/null && echo "HiveServer2服务运行正常" || echo "HiveServer2服务运行异常"
;;
*)
echo Invalid Args!
echo 'Usage: '$(basename $0)' start|stop|restart|status'
;;
esac后台启动命令说明
nohup:放在命令开头,表示不挂起,也就是关闭终端进程也继续保持运行状态。/dev/null:是Linux文件系统中的一个文件,被称为黑洞,所有写入该文件的内容都会被自动丢弃。0 1 2: 数字0表示标准输入,1表示标准输出, 2表示错误输出。2>&1:表示将错误重定向到标准输出上。&:放在命令结尾,表示后台运行。
命令组合使用:nohup [xxx命令操作] > xxx.log 2>&1 &,表示将xxx命令运行的结果输出到xxx.log中,并保持命令启动的进程在后台运行。
- 添加执行权限
[jack@hadoop102 ~]$ chmod +x ~/bin/hive_helper
[jack@hadoop102 ~]$ ll ~/bin/hive_helper
-rwxrwxr-x. 1 jack jack 1648 5月 30 22:53 /home/jack/bin/hive_helper- 查看HiveMetastore和HiveServer2服务状态
[jack@hadoop102 ~]$ hive_helper status
Metastore服务运行正常
HiveServer2服务运行正常2. Hive服务启动脚本(版本2)
hive一键启动脚本包含启动、停止和beeline功能。
2.1 安装except
yum install -y expect2.2 编写Hive登录脚本
创建beeline.exp,expect脚本用于启动beeline,并登入hive:
#!/bin/expect
spawn beeline
set timeout 5
expect "beeline>"
send "!connect jdbc:hive2://node02:10000\r"
expect "Enter username for jdbc:hive2://node02:10000:"
send "hive\r"
expect "Enter password for jdbc:hive2://node02:10000:"
send "******\r"
interact2.3 编写Hive启停脚本
在/home/hive/bin下创建hive_helper脚本:
#!/bin/bash
# 判断参数个数
if [ $# -lt 1 ]
then
echo "need one param, but given $# ..."
exit;
fi
# 日志文件的存储位置
hiveserver_log_path='/opt/module/hive-4.1.0/logs/hiveserver.log'
metastore_log_path='/opt/module/hive-4.1.0/logs/metastore.log'
case $1 in
"start")
echo ' ---------- start metastore ---------- '
nohup /opt/module/hive-4.1.0/bin/hive --service metastore >> $metastore_log_path 2>&1 &
echo ' ---------- start hiveserver2 ---------- '
nohup /opt/module/hive-4.1.0/bin/hive --service hiveserver2 >> $hiveserver_log_path 2>&1 &
;;
"stop")
echo ' ---------- stop hiveserver2 ---------- '
kill -9 $(jps -m | grep 'HiveServer2' | awk 'NR==1{print $1}')
echo ' ---------- stop metastore ---------- '
kill -9 $(jps -m | grep 'HiveMetaStore' | awk 'NR==1{print $1}')
;;
"beeline")
echo ' ---------- enter beeline ---------- '
expect /home/hive/beeline.exp
;;
*)
echo "Input Params Error ..."
;;
esac2.4 测试脚本
[hive@Node02 opt]$ hive_helper beeline
---------- enter beeline ----------
spawn beeline
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/hive-4.1.0/lib/log4j-slf4j-impl-2.24.3.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/tez-0.10.5/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.4.1/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
!connect jdbc:hive2://node02:10000
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/hive-4.1.0/lib/log4j-slf4j-impl-2.24.3.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/tez-0.10.5/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.4.1/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
2025-08-31T03:41:12.259953268Z main WARN The use of package scanning to locate Log4j plugins is deprecated.
Please remove the `packages` attribute from your configuration file.
See https://logging.apache.org/log4j/2.x/faq.html#package-scanning for details.
2025-08-31T03:41:12.473517080Z main INFO Starting configuration org.apache.logging.log4j.core.config.properties.PropertiesConfiguration@7b205dbd...
2025-08-31T03:41:12.474717752Z main INFO Start watching for changes to jar:file:/opt/module/hive-4.1.0/lib/hive-beeline-4.1.0.jar!/beeline-log4j2.properties every 0 seconds
2025-08-31T03:41:12.475744764Z main INFO Configuration org.apache.logging.log4j.core.config.properties.PropertiesConfiguration@7b205dbd started.
2025-08-31T03:41:12.480884189Z main INFO Stopping configuration org.apache.logging.log4j.core.config.DefaultConfiguration@2ea41516...
2025-08-31T03:41:12.482415907Z main INFO Configuration org.apache.logging.log4j.core.config.DefaultConfiguration@2ea41516 stopped.
Beeline version 4.1.0 by Apache Hive
beeline> !connect jdbc:hive2://node02:10000
Connecting to jdbc:hive2://node02:10000
Enter username for jdbc:hive2://node02:10000: hive
Enter password for jdbc:hive2://node02:10000: ******
Connected to: Apache Hive (version 4.1.0)
Driver: Hive JDBC (version 4.1.0)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://node02:10000>3. Hive常用交互命令
[jack@hadoop102 ~]$ beeline --help
Usage: java org.apache.hive.cli.beeline.BeeLine
-u <database url> the JDBC URL to connect to
-c <named url> the named JDBC URL to connect to,
which should be present in beeline-site.xml
as the value of beeline.hs2.jdbc.url.<namedUrl>
-r reconnect to last saved connect url (in conjunction with !save)
-n <username> the username to connect as
-p <password> the password to connect as
-d <driver class> the driver class to use
-i <init file> script file for initialization
-e <query> query that should be executed
-f <exec file> script file that should be executed
-w (or) --password-file <password file> the password file to read password from
--hiveconf property=value Use value for given property
--hivevar name=value hive variable name and value
This is Hive specific settings in which variables
can be set at session level and referenced in Hive
commands or queries.
--property-file=<property-file> the file to read connection properties (url, driver, user, password) from
--color=[true/false] control whether color is used for display
--showHeader=[true/false] show column names in query results
--escapeCRLF=[true/false] show carriage return and line feeds in query results as escaped \r and \n
--headerInterval=ROWS; the interval between which heades are displayed
--fastConnect=[true/false] skip building table/column list for tab-completion
--autoCommit=[true/false] enable/disable automatic transaction commit
--verbose=[true/false] show verbose error messages and debug info
--showWarnings=[true/false] display connection warnings
--showDbInPrompt=[true/false] display the current database name in the prompt
--showNestedErrs=[true/false] display nested errors
--numberFormat=[pattern] format numbers using DecimalFormat pattern
--force=[true/false] continue running script even after errors
--maxWidth=MAXWIDTH the maximum width of the terminal
--maxColumnWidth=MAXCOLWIDTH the maximum width to use when displaying columns
--silent=[true/false] be more silent
--report=[true/false] show number of rows and execution time after query execution
--autosave=[true/false] automatically save preferences
--outputformat=[table/vertical/csv2/tsv2/dsv/csv/tsv/json/jsonfile] format mode for result display
Note that csv, and tsv are deprecated - use csv2, tsv2 instead
--incremental=[true/false] Defaults to false. When set to false, the entire result set
is fetched and buffered before being displayed, yielding optimal
display column sizing. When set to true, result rows are displayed
immediately as they are fetched, yielding lower latency and
memory usage at the price of extra display column padding.
Setting --incremental=true is recommended if you encounter an OutOfMemory
on the client side (due to the fetched result set size being large).
Only applicable if --outputformat=table.
--incrementalBufferRows=NUMROWS the number of rows to buffer when printing rows on stdout,
defaults to 1000; only applicable if --incremental=true
and --outputformat=table
--truncateTable=[true/false] truncate table column when it exceeds length
--delimiterForDSV=DELIMITER specify the delimiter for delimiter-separated values output format (default: |)
--isolation=LEVEL set the transaction isolation level
--nullemptystring=[true/false] set to true to get historic behavior of printing null as empty string
--maxHistoryRows=MAXHISTORYROWS The maximum number of rows to store beeline history.
--delimiter=DELIMITER set the query delimiter; multi-char delimiters are allowed, but quotation
marks, slashes, and -- are not allowed; defaults to ;
--convertBinaryArrayToString=[true/false] display binary column data as string or as byte array
--getUrlsFromBeelineSite Print all urls from beeline-site.xml, if it is present in the classpath
--help display this message
Example:
1. Connect using simple authentication to HiveServer2 on localhost:10000
$ beeline -u "jdbc:hive2://localhost:10000" username password
2. Connect using simple authentication to HiveServer2 on hs.local:10000 using -n for username and -p for password
$ beeline -n username -p password -u "jdbc:hive2://hs2.local:10000"
3. Connect using Kerberos authentication with hive/localhost@mydomain.com as HiveServer2 principal
$ beeline -u "jdbc:hive2://hs2.local:10013/default;principal=hive/localhost@mydomain.com"
4. Connect using SSL connection to HiveServer2 on localhost at 10000
$ beeline "jdbc:hive2://localhost:10000/default;ssl=true;sslTrustStore=/usr/local/truststore;trustStorePassword=mytruststorepassword"
5. Connect using LDAP authentication
$ beeline -n ldap-username -p ldap-password -u "jdbc:hive2://localhost:10000/default"2.1 连接hive命令
- 使用beeline直接连接,利用连接脚本beeline
[jack@hadoop102 bin]$ beeline -u jdbc:hive2://hadoop102:10000 -n jack
Connecting to jdbc:hive2://hadoop102:10000
Connected to: Apache Hive (version 4.0.0)
Driver: Hive JDBC (version 4.0.0)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 4.0.0 by Apache Hive
0: jdbc:hive2://hadoop102:10000>- 使用hive命令间接连接
[jack@hadoop102 hive-4.0.0]$ sh bin/hive
Beeline version 4.0.0 by Apache Hive
beeline> !connect jdbc:hive2://hadoop102:10000
Connecting to jdbc:hive2://hadoop102:10000
Enter username for jdbc:hive2://hadoop102:10000: jack
Enter password for jdbc:hive2://hadoop102:10000: ****
Connected to: Apache Hive (version 4.0.0)
Driver: Hive JDBC (version 4.0.0)
Transaction isolation: TRANSACTION_REPEATABLE_READ2.2 "-e"不进入hive交互窗口执行hql语句
其中hql语句指的是hive sql语句
[jack@hadoop102 bin]$ beeline -u jdbc:hive2://hadoop102:10000 -n jack -e "select * from default.stu;"
Connecting to jdbc:hive2://hadoop102:10000
Connected to: Apache Hive (version 4.0.0)
Driver: Hive JDBC (version 4.0.0)
Transaction isolation: TRANSACTION_REPEATABLE_READ
INFO : Compiling command(queryId=jack_20240531071928_2c79fac0-4ce7-40d3-8a5f-e5dbfe3c0ae1): select * from default.stu
INFO : Semantic Analysis Completed (retrial = false)
INFO : Created Hive schema: Schema(fieldSchemas:[FieldSchema(name:stu.id, type:int, comment:null), FieldSchema(name:stu.name, type:string, comment:null)], properties:null)
INFO : Completed compiling command(queryId=jack_20240531071928_2c79fac0-4ce7-40d3-8a5f-e5dbfe3c0ae1); Time taken: 0.332 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=jack_20240531071928_2c79fac0-4ce7-40d3-8a5f-e5dbfe3c0ae1): select * from default.stu
INFO : Completed executing command(queryId=jack_20240531071928_2c79fac0-4ce7-40d3-8a5f-e5dbfe3c0ae1); Time taken: 0.0 seconds
+---------+-----------+
| stu.id | stu.name |
+---------+-----------+
| 1 | 阿茂 |
| 2 | 杰霸霸 |
| 3 | 圆圆 |
+---------+-----------+
3 rows selected (0.649 seconds)
Beeline version 4.0.0 by Apache Hive
Closing: 0: jdbc:hive2://hadoop102:100002.3 "-f"不进入hive交互窗口执行hql脚本
- 在/opt/module/hive4.0.0/下创建datas目录并在datas目录下创建data1.sql文件
[jack@hadoop102 hive-4.0.0]$ mkdir datas
[jack@hadoop102 hive-4.0.0]$ vi datas/data1.sql- 文件中写入正确的hql语句,结尾要加分号
[jack@hadoop102 hive-4.0.0]$ cat datas/data1.sql
insert into default.stu values('4', '团子');- 执行文件中的hql语句
[jack@hadoop102 hive-4.0.0]$ beeline -u jdbc:hive2://hadoop102:10000 -n jack -f datas/data1.sql
Connecting to jdbc:hive2://hadoop102:10000
Connected to: Apache Hive (version 4.0.0)
Driver: Hive JDBC (version 4.0.0)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://hadoop102:10000> insert into default.stu values('4', '团子');
INFO : Compiling command(queryId=jack_20240531073053_347e4d46-c1bc-46cc-9241-a121c4fb8544): insert into default.stu values('4', '团子')
INFO : Semantic Analysis Completed (retrial = false)
INFO : Created Hive schema: Schema(fieldSchemas:[FieldSchema(name:_col0, type:int, comment:null), FieldSchema(name:_col1, type:string, comment:null)], properties:null)
INFO : Completed compiling command(queryId=jack_20240531073053_347e4d46-c1bc-46cc-9241-a121c4fb8544); Time taken: 0.406 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=jack_20240531073053_347e4d46-c1bc-46cc-9241-a121c4fb8544): insert into default.stu values('4', '团子')
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. tez) or using Hive 1.X releases.
INFO : Query ID = jack_20240531073053_347e4d46-c1bc-46cc-9241-a121c4fb8544
INFO : Total jobs = 3
INFO : Launching Job 1 out of 3
INFO : Starting task [Stage-1:MAPRED] in serial mode
INFO : Number of reduce tasks determined at compile time: 1
INFO : In order to change the average load for a reducer (in bytes):
INFO : set hive.exec.reducers.bytes.per.reducer=<number>
INFO : In order to limit the maximum number of reducers:
INFO : set hive.exec.reducers.max=<number>
INFO : In order to set a constant number of reducers:
INFO : set mapreduce.job.reduces=<number>
INFO : number of splits:1
INFO : Submitting tokens for job: job_1717109202684_0001
INFO : Executing with tokens: []
INFO : The url to track the job: http://hadoop103:8088/proxy/application_1717109202684_0001/
INFO : Starting Job = job_1717109202684_0001, Tracking URL = http://hadoop103:8088/proxy/application_1717109202684_0001/
INFO : Kill Command = /opt/module/hadoop-3.3.6/bin/mapred job -kill job_1717109202684_0001
INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
INFO : 2024-05-31 07:31:19,226 Stage-1 map = 0%, reduce = 0%
INFO : 2024-05-31 07:31:26,759 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 5.81 sec
INFO : 2024-05-31 07:31:27,821 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 6.38 sec
INFO : MapReduce Total cumulative CPU time: 6 seconds 380 msec
INFO : Ended Job = job_1717109202684_0001
INFO : Starting task [Stage-7:CONDITIONAL] in serial mode
INFO : Stage-4 is selected by condition resolver.
INFO : Stage-3 is filtered out by condition resolver.
INFO : Stage-5 is filtered out by condition resolver.
INFO : Starting task [Stage-4:MOVE] in serial mode
INFO : Moving data to directory hdfs://hadoop102:8020/user/hive/warehouse/stu/.hive-staging_hive_2024-05-31_07-30-53_792_1938175852226376053-5/-ext-10000 from hdfs://hadoop102:8020/user/hive/warehouse/stu/.hive-staging_hive_2024-05-31_07-30-53_792_1938175852226376053-5/-ext-10002
INFO : Starting task [Stage-0:MOVE] in serial mode
INFO : Loading data to table default.stu from hdfs://hadoop102:8020/user/hive/warehouse/stu/.hive-staging_hive_2024-05-31_07-30-53_792_1938175852226376053-5/-ext-10000
INFO : Starting task [Stage-2:STATS] in serial mode
INFO : Executing stats task
INFO : Table default.stu stats: [numFiles=4, numRows=4, totalSize=35, rawDataSize=31, numFilesErasureCoded=0]
INFO : MapReduce Jobs Launched:
INFO : Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 6.38 sec HDFS Read: 31587 HDFS Write: 1063596 HDFS EC Read: 0 SUCCESS
INFO : Total MapReduce CPU Time Spent: 6 seconds 380 msec
INFO : Completed executing command(queryId=jack_20240531073053_347e4d46-c1bc-46cc-9241-a121c4fb8544); Time taken: 35.503 seconds
1 row affected (35.957 seconds)3. Hive参数配置方式
3.1 查看当前所有的配置信息
信息很多,以下对命令执行结果省略大部分内容。
0: jdbc:hive2://hadoop102:10000> set;
+----------------------------------------------------+
| set |
+----------------------------------------------------+
| _hive.hdfs.session.path=/tmp/hive/jack/1e299d67-1423-4c30-9ef2-58d155050f02 |
| _hive.local.session.path=/tmp/jack/1e299d67-1423-4c30-9ef2-58d155050f02 |
| _hive.ss.authz.settings.applied.marker=true |
| _hive.tmp_table_space=/tmp/hive/jack/1e299d67-1423-4c30-9ef2-58d155050f02/_tmp_space.db |
| datanode.https.port=50475 |
| datanucleus.cache.level2=false |
| datanucleus.cache.level2.type=none |
| datanucleus.connectionPool.maxPoolSize=10 |
| datanucleus.connectionPoolingType=HikariCP |
| datanucleus.identifierFactory=datanucleus1 |
| datanucleus.plugin.pluginRegistryBundleCheck=LOG |
| datanucleus.rdbms.initializeColumnInfo=NONE |
| datanucleus.rdbms.useLegacyNativeValueStrategy=true |
| datanucleus.schema.autoCreateAll=false |
| datanucleus.schema.validateColumns=false |
| datanucleus.schema.validateConstraints=false |
| datanucleus.schema.validateTables=false |
| datanucleus.storeManagerType=rdbms |
| datanucleus.transactionIsolation=read-committed |
| dfs.balancer.address=0.0.0.0:0 |
| dfs.balancer.block-move.timeout=0 |
| dfs.balancer.dispatcherThreads=200 |
| dfs.balancer.getBlocks.min-block-size=10485760 |
| dfs.balancer.getBlocks.size=2147483648 |
| dfs.balancer.keytab.enabled=false |
| dfs.balancer.max-iteration-time=1200000 |
| dfs.balancer.max-no-move-interval=60000 |
| dfs.balancer.max-size-to-move=10737418240 |
| dfs.balancer.movedWinWidth=5400000 |
| dfs.balancer.moverThreads=1000 |
| dfs.balancer.service.interval=5m |
| dfs.balancer.service.retries.on.exception=5 |
| dfs.batched.ls.limit=100 |
| dfs.block.access.key.update.interval=600 |
| dfs.block.access.token.enable=false |
| dfs.block.access.token.lifetime=600 |
| dfs.block.access.token.protobuf.enable=false |
| dfs.block.invalidate.limit=1000 |
| dfs.block.misreplication.processing.limit=10000 |
| dfs.block.placement.ec.classname=org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicyRackFaultTolerant |
| dfs.block.replicator.classname=org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicyDefault |
| dfs.block.scanner.skip.recent.accessed=false |
| dfs.block.scanner.volume.bytes.per.second=1048576 |
| dfs.block.scanner.volume.join.timeout.ms=5000 |
| dfs.blockreport.incremental.intervalMsec=0 |
| dfs.blockreport.initialDelay=0 |
| dfs.blockreport.intervalMsec=21600000 |
| dfs.blockreport.split.threshold=1000000 |
| dfs.blocksize=134217728 |
| dfs.bytes-per-checksum=512 |
| dfs.cachereport.intervalMsec=10000 |
| dfs.checksum.combine.mode=MD5MD5CRC |
| dfs.checksum.ec.socket-timeout=3000 |
| dfs.checksum.type=CRC32C |
| dfs.client-write-packet-size=65536 |
| dfs.client.block.reader.remote.buffer.size=512 |
| dfs.client.block.write.locateFollowingBlock.initial.delay.ms=400 |
| dfs.client.block.write.locateFollowingBlock.max.delay.ms=60000 |
| dfs.client.block.write.locateFollowingBlock.retries=5 |
| dfs.client.block.write.replace-datanode-on-failure.best-effort=false |
| dfs.client.block.write.replace-datanode-on-failure.enable=true |
| dfs.client.block.write.replace-datanode-on-failure.min-replication=0 |
| dfs.client.block.write.replace-datanode-on-failure.policy=DEFAULT |
| dfs.client.block.write.retries=3 |
| dfs.client.cached.conn.retry=3 |
| dfs.client.context=default |
| dfs.client.datanode-restart.timeout=30 |
| dfs.client.deadnode.detection.enabled=false |
| dfs.client.deadnode.detection.idle.sleep.ms=10000 |
| dfs.client.deadnode.detection.probe.connection.timeout.ms=20000 |
| dfs.client.deadnode.detection.probe.deadnode.interval.ms=60000 |
| dfs.client.deadnode.detection.probe.deadnode.threads=10 |
| dfs.client.deadnode.detection.probe.suspectnode.interval.ms=300 |
| dfs.client.deadnode.detection.probe.suspectnode.threads=10 |
| dfs.client.deadnode.detection.rpc.threads=20 |
| dfs.client.domain.socket.data.traffic=false |
| dfs.client.failover.connection.retries=0 |
| dfs.client.failover.connection.retries.on.timeouts=0 |
| dfs.client.failover.max.attempts=15 |
| dfs.client.failover.random.order=false |
| dfs.client.failover.resolve-needed=false |
| dfs.client.failover.resolver.impl=org.apache.hadoop.net.DNSDomainNameResolver |
| dfs.client.failover.resolver.useFQDN=true |
| dfs.client.failover.sleep.base.millis=500 |
| dfs.client.failover.sleep.max.millis=15000 |
| dfs.client.fsck.connect.timeout=60000ms |
| dfs.client.fsck.read.timeout=60000ms |
| dfs.client.hedged.read.threadpool.size=0 |
| dfs.client.hedged.read.threshold.millis=500 |
| dfs.client.https.keystore.resource=ssl-client.xml |
| dfs.client.https.need-auth=false |
| dfs.client.key.provider.cache.expiry=864000000 |
| dfs.client.max.block.acquire.failures=3 |
| dfs.client.mmap.cache.size=256 |
| dfs.client.mmap.cache.timeout.ms=3600000 |
| dfs.client.mmap.enabled=true |
| dfs.client.mmap.retry.timeout.ms=300000 |
| dfs.client.read.short.circuit.replica.stale.threshold.ms=1800000 |
| dfs.client.read.shortcircuit=false |
| dfs.client.read.shortcircuit.buffer.size=1048576 |
+----------------------------------------------------+
......
+----------------------------------------------------+
| set |
+----------------------------------------------------+
| system:java.runtime.version=1.8.0_391-b13 |
| system:java.specification.maintenance.version=5 |
| system:java.specification.name=Java Platform API Specification |
| system:java.specification.vendor=Oracle Corporation |
| system:java.specification.version=1.8 |
| system:java.util.logging.config.file=/opt/module/hive-4.0.0/conf/parquet-logging.properties |
| system:java.vendor=Oracle Corporation |
| system:java.vendor.url=http://java.oracle.com/ |
| system:java.vendor.url.bug=http://bugreport.sun.com/bugreport/ |
| system:java.version=1.8.0_391 |
| system:java.vm.info=mixed mode |
| system:java.vm.name=Java HotSpot(TM) 64-Bit Server VM |
| system:java.vm.specification.name=Java Virtual Machine Specification |
| system:java.vm.specification.vendor=Oracle Corporation |
| system:java.vm.specification.version=1.8 |
| system:java.vm.vendor=Oracle Corporation |
| system:java.vm.version=25.391-b13 |
| system:jetty.git.hash=4a0c91c0be53805e3fcffdcdcc9587d5301863db |
| system:jline.terminal=jline.UnsupportedTerminal |
| system:line.separator= |
| |
| system:log4j.configurationFile=hive-log4j2.properties |
| system:log4j2.formatMsgNoLookups=true |
| system:os.arch=amd64 |
| system:os.name=Linux |
| system:os.version=3.10.0-1160.105.1.el7.x86_64 |
| system:path.separator=: |
| system:proc_hiveserver2= |
| system:proc_jar= |
| system:sun.arch.data.model=64 |
| system:sun.boot.class.path=/opt/module/jdk1.8.0_391/jre/lib/resources.jar:/opt/module/jdk1.8.0_391/jre/lib/rt.jar:/opt/module/jdk1.8.0_391/jre/lib/jsse.jar:/opt/module/jdk1.8.0_391/jre/lib/jce.jar:/opt/module/jdk1.8.0_391/jre/lib/charsets.jar:/opt/module/jdk1.8.0_391/jre/lib/jfr.jar:/opt/module/jdk1.8.0_391/jre/classes |
| system:sun.boot.library.path=/opt/module/jdk1.8.0_391/jre/lib/amd64 |
| system:sun.cpu.endian=little |
| system:sun.cpu.isalist= |
| system:sun.io.unicode.encoding=UnicodeLittle |
| system:sun.java.command=org.apache.hadoop.util.RunJar /opt/module/hive-4.0.0/lib/hive-service-4.0.0.jar org.apache.hive.service.server.HiveServer2 |
| system:sun.java.launcher=SUN_STANDARD |
| system:sun.jnu.encoding=UTF-8 |
| system:sun.management.compiler=HotSpot 64-Bit Tiered Compilers |
| system:sun.os.patch.level=unknown |
| system:user.country=CN |
| system:user.dir=/home/jack |
| system:user.home=/home/jack |
| system:user.language=zh |
| system:user.name=jack |
| system:user.timezone=Asia/Shanghai |
| system:yarn.home.dir=/opt/module/hadoop-3.3.6 |
| system:yarn.log.dir=/opt/module/hadoop-3.3.6/logs |
| system:yarn.log.file=hadoop.log |
| system:yarn.root.logger=INFO,console |
+----------------------------------------------------+3.2 参数的配置三种方式
- 通过配置文件方式
其中默认配置文件:hive-default.xml
用户自定义配置文件:hive-site.xml
用户自定义配置会覆盖默认配置。另外,Hive也会读入Hadoop的配置,因为Hive是作为Hadoop的客户端启动的,Hive的配置会覆盖Hadoop的配置。配置文件的设定对本机启动的所有Hive进程都有效。 - 命令行参数方式 启动Hive连接时,可以在命令行添加
--hiveconf param=value来设定参数。
[jack@hadoop102 hive-4.0.0]$ beeline -u jdbc:hive2://hadoop102:10000 -n jack --hiveconf mapreduce.job.reduces=10
Connecting to jdbc:hive2://hadoop102:10000
Connected to: Apache Hive (version 4.0.0)
Driver: Hive JDBC (version 4.0.0)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 4.0.0 by Apache Hive
0: jdbc:hive2://hadoop102:10000> set mapreduce.job.reduces;
+---------------------------+
| set |
+---------------------------+
| mapreduce.job.reduces=10 |
+---------------------------+
1 row selected (0.124 seconds)注意:命令行参数设置仅对本次Hive启动有效。
3. 参数声明方式
可以在HQL中使用SET关键字设定参数,例如:
0: jdbc:hive2://hadoop102:10000> set mapreduce.job.reduces=11;
No rows affected (0.016 seconds)
0: jdbc:hive2://hadoop102:10000> set mapreduce.job.reduces;
+---------------------------+
| set |
+---------------------------+
| mapreduce.job.reduces=11 |
+---------------------------+
1 row selected (0.014 seconds)注意:命令行参数设置仅对本次Hive启动有效。 上述三种设定方式的优先级依次递增。即配置文件 < 命令行参数 < 参数声明。注意某些系统级的参数,例如log4j相关的设定,必须用前两种方式设定,因为那些参数的读取在会话建立以前已经完成了。
4. Hive常见属性配置
4.1 Hive客户端显示当前库和表头
默认显示表头,显示库需要修改命令行脚本hive,修改$HIVE_HOME/bin/hive文件中修改加入参数--showDbInPrompt=true:
## 在382行开始覆盖如下内容
RUN_ARGS="$@"
if [ "$SERVICE" = beeline ] ; then
RUN_ARGS="$RUN_ARGS --showDbInPrompt=true"
fi
export JVM_PID="$$"
if [ "$TORUN" = "" ] ; then
echo "Service $SERVICE not found"
echo "Available Services: $SERVICE_LIST"
exit 7
else
set -- "${SERVICE_ARGS[@]}"
$TORUN $RUN_ARGS
fihive客户端在运行时可以显示当前使用的库和表头信息的执行效果:
beeline> jack[jack@hadoop102 bin]$ hive
Beeline version 4.0.0 by Apache Hive
beeline> !connect jdbc:hive2://hadoop102:10000
Connecting to jdbc:hive2://hadoop102:10000
Enter username for jdbc:hive2://hadoop102:10000: jack
Enter password for jdbc:hive2://hadoop102:10000:
Connected to: Apache Hive (version 4.0.0)
Driver: Hive JDBC (version 4.0.0)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://hadoop102:10000 (default)> select * from stu;
INFO : Compiling command(queryId=jack_20240604072939_db4e1973-95c4-4f01-bd61-5ea75b784aa8): select * from stu
INFO : Semantic Analysis Completed (retrial = false)
INFO : Created Hive schema: Schema(fieldSchemas:[FieldSchema(name:stu.id, type:int, comment:null), FieldSchema(name:stu.name, type:string, comment:null)], properties:null)
INFO : Completed compiling command(queryId=jack_20240604072939_db4e1973-95c4-4f01-bd61-5ea75b784aa8); Time taken: 0.258 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=jack_20240604072939_db4e1973-95c4-4f01-bd61-5ea75b784aa8): select * from stu
INFO : Completed executing command(queryId=jack_20240604072939_db4e1973-95c4-4f01-bd61-5ea75b784aa8); Time taken: 0.0 seconds
+---------+-----------+
| stu.id | stu.name |
+---------+-----------+
| 1 | ss |
| 2 | 杰霸霸 |
| 3 | 圆圆 |
| 4 | 团子 |
+---------+-----------+
4 rows selected (0.419 seconds)
0: jdbc:hive2://hadoop102:10000 (default)> use mydatabase;
INFO : Compiling command(queryId=jack_20240604072858_5e51bc4e-9efd-4705-8815-b1c1a03aa997): use mydatabase
INFO : Semantic Analysis Completed (retrial = false)
INFO : Created Hive schema: Schema(fieldSchemas:null, properties:null)
INFO : Completed compiling command(queryId=jack_20240604072858_5e51bc4e-9efd-4705-8815-b1c1a03aa997); Time taken: 0.035 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=jack_20240604072858_5e51bc4e-9efd-4705-8815-b1c1a03aa997): use mydatabase
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=jack_20240604072858_5e51bc4e-9efd-4705-8815-b1c1a03aa997); Time taken: 0.067 seconds
No rows affected (0.202 seconds)
0: jdbc:hive2://hadoop102:10000 (mydatabase)>4.2 Hive运行日志路径配置
- Hive的log默认存放在/tmp/jack/hive.log目录下(当前用户名下)
[jack@hadoop102 ~]$ cd /tmp/jack
[jack@hadoop102 jack]$ ll
总用量 2900
drwx------. 2 jack jack 6 6月 3 06:57 07003a25-dae4-4423-b14a-86de37ffa2c0
-rw-rw-r--. 1 jack jack 0 6月 3 06:57 07003a25-dae4-4423-b14a-86de37ffa2c02037754920182337464.pipeout
-rw-rw-r--. 1 jack jack 0 6月 3 06:57 07003a25-dae4-4423-b14a-86de37ffa2c0338951335538656993.pipeout
drwx------. 2 jack jack 6 6月 3 06:57 0d27c902-6ba9-4732-b30e-6862757c2e96
drwx------. 2 jack jack 6 6月 3 06:57 fc2be0fc-a737-4409-8237-48f4c790e783
-rw-rw-r--. 1 jack jack 0 6月 3 06:57 fc2be0fc-a737-4409-8237-48f4c790e7833131115738461546315.pipeout
-rw-rw-r--. 1 jack jack 0 6月 3 06:57 fc2be0fc-a737-4409-8237-48f4c790e7833689072413516091661.pipeout
-rw-rw-r--. 1 jack jack 124924 6月 3 06:59 hive.log
-rw-rw-r--. 1 jack jack 1873 5月 28 23:21 hive.log.2024-05-28
-rw-rw-r--. 1 jack jack 803308 5月 30 22:59 hive.log.2024-05-29
-rw-rw-r--. 1 jack jack 800072 5月 31 23:59 hive.log.2024-05-30
-rw-rw-r--. 1 jack jack 461069 6月 1 23:59 hive.log.2024-05-31
-rw-rw-r--. 1 jack jack 543009 6月 2 23:59 hive.log.2024-06-01
-rw-rw-r--. 1 jack jack 151138 6月 3 06:56 hive.log.2024-06-02
drwxrwxr-x. 3 jack jack 50 6月 3 06:57 operation_logs- 修改Hive的log存放日志到/opt/module/hive/logs
## 修改$HIVE_HOME/conf/hive-log4j2.properties.template文件名称为hive-log4j2.properties
[jack@hadoop102 conf]$ mv hive-log4j2.properties.template hive-log4j2.properties
## 在hive-log4j2.properties文件中修改log存放位置
[jack@hadoop102 conf]$ vim hive-log4j2.properties
修改配置如下
property.hive.log.dir=/opt/module/hive-4.0.0/logs4.3 Hive的JVM堆内存设置
新版本的Hive启动的时候,默认申请的JVM堆内存大小为256M,JVM堆内存申请的太小,导致后期开启本地模式,执行复杂的SQL时经常会报错:java.lang.OutOfMemoryError: Java heap space,因此最好提前调整一下HADOOP_HEAPSIZE这个参数。
- 修改$HIVE_HOME/conf下的hive-env.sh.template为hive-env.sh
[jack@hadoop102 conf]$ mv hive-env.sh.template hive-env.sh- 将hive-env.sh其中的参数
export HADOOP_HEAPSIZE修改为2048,重启Hive
# The heap size of the jvm stared by hive shell script can be controlled via:
export HADOOP_HEAPSIZE=20484.4 关闭Hadoop虚拟内存检查
在yarn-site.xml中关闭虚拟内存检查(虚拟内存校验,如果已经关闭了,就不需要配了)。
- 修改前记得先停Hadoop
[jack@hadoop102 hadoop]$ vim yarn-site.xml- 添加如下配置
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>- 修改完后记得分发yarn-site.xml,并重启yarn
4.5 提高Hive客户端计算速度
- 设置参数:
hive.exec.mode.local.auto, 意味着将使用本地资源而不是yarn,yarn属于远程调用,yarn内部需要对计算数据申请资源,产生container等流程,本地调试sql阶段很耗时。
-- 在客户端中设置hive session
SET mapreduce.framework.name=local
SET hive.exec.mode.local.auto=TRUE5. Hive乱码解决
5.1 表注释乱码
如图刚建好的表查看建表信息,注释显示不正常: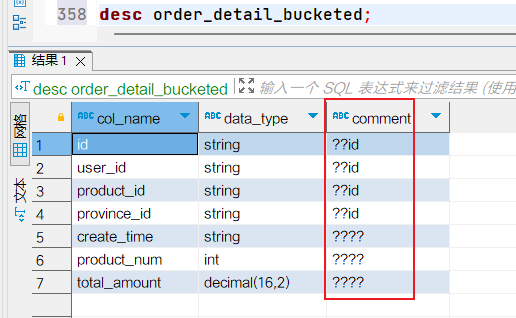
- 调整Hive元数据存储相关表的字符集
-- 修改表字段注解和表注解
alter table COLUMNS_V2 modify column COMMENT varchar(3000) character set utf8;
alter table TABLE_PARAMS modify column PARAM_VALUE varchar(3000) character set utf8;
-- 修改分区字段注解
alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(3000) character set utf8 ;
-- 修改索引注解
alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(3000) character set utf8;- 修改hive-site.xml中连接数据库配置
值得注意的是jdbcUrl中&需要转义成&。
<!-- jdbc连接的URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop105:3306/metastore?useSSL=false&useUnicode=true&characterEncoding=UTF-8</value>
</property>- 设置命令行输出字符
在hive-site.xml文件中设置命令行输出指定字符集编码utf8。
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.encoding</name>
<value>UTF-8</value>
</property>
<property>
<name>hive.charset</name>
<value>utf8</value>
</property>- 重启Hive服务和重建表
可以看到注释已经在图形化客户端和命令行中不再乱码,配置已经生效。