HBase读写流程
1. 读流程
1.1 HFile结构
HFile是存储在HDFS上面每一个store文件夹下实际存储数据的文件。里面存储多种内容。包括数据本身(keyValue 键值对)、元数据记录、文件信息、数据索引、元数据索引和一个固定长度的尾部信息(记录文件的修改情况)。键值对按照块大小(默认64K)保存在文件中,数据索引按照块创建,块越多,索引越大。每一个HFile还会维护一个布隆过滤器(就像是一个很大的地图,文件中每有一种key,就在对应的位置标记,读取时可以大致判断要get的key是否存在HFile中)。KeyValue内容如下:
rowlength -----------→ key的长度
row -----------------→ key的值
columnfamilylength --→ 列族长度
columnfamily --------→ 列族
columnqualifier -----→ 列名
timestamp -----------→ 时间戳(默认系统时间)
keytype -------------→ Put
由于HFile存储经过序列化,所以无法直接查看。可以通过HBase提供的命令来查看存储在HDFS上面的HFile元数据内容。
[jack@hadoop102 hbase]$ bin/hbase hfile -m -f /hbase/data/命名空间/表名/regionID/列族/HFile 名
[jack@hadoop102 hbase-2.6.1]$ bin/hbase hfile -m -f /HBase/data/bigdata/user/23e1ff3d6a440e5cd5903903e1a1d9a2/info/4658458601c74f21889a4214e6b4b051
Block index size as per heapsize: 376
reader=/HBase/data/bigdata/user/23e1ff3d6a440e5cd5903903e1a1d9a2/info/4658458601c74f21889a4214e6b4b051,
## 没有压缩
compression=none,
## 因为还没有去读取过该数据,所以缓存里面没有,都是false
cacheConf=cacheDataOnRead=false,
cacheDataOnWrite=false,
cacheIndexesOnWrite=false,
cacheBloomsOnWrite=false,
cacheEvictOnClose=false,
cacheDataCompressed=false,
prefetchOnOpen=false,
firstKey=Optional[1001/info:age/1732768745586/Put/seqid=0],
lastKey=Optional[1001/info:name/1732767868703/Put/seqid=0],
avgKeyLen=23,
avgValueLen=5,
entries=5,
length=5140
Trailer:
fileinfoOffset=374,
loadOnOpenDataOffset=264,
dataIndexCount=1,
metaIndexCount=0,
totalUncomressedBytes=5047,
entryCount=5,
compressionCodec=NONE,
uncompressedDataIndexSize=36,
numDataIndexLevels=1,
firstDataBlockOffset=0,
lastDataBlockOffset=0,
comparatorClassName=org.apache.hadoop.hbase.InnerStoreCellComparator,
encryptionKey=NONE,
## 记录版本,如果版本没变,直接可以尝试读取缓存
majorVersion=3,
minorVersion=3
Fileinfo:
BLOOM_FILTER_TYPE = ROW
COMPACTION_EVENT_KEY = PBUF
DELETE_FAMILY_COUNT = 0
EARLIEST_PUT_TS = 1732767868703
HISTORICAL = false
KEY_VALUE_VERSION = 1
LAST_BLOOM_KEY = 1001
MAJOR_COMPACTION_KEY = false
MAX_MEMSTORE_TS_KEY = 8
MAX_SEQ_ID_KEY = 9
TIMERANGE = 1732767868703....1732768745586
hfile.AVG_KEY_LEN = 23
hfile.AVG_VALUE_LEN = 5
hfile.CREATE_TIME_TS = 1732771600467
hfile.KEY_OF_BIGGEST_CELL = \x00\x041001\x04infoname\x00\x00\x01\x93q\x10\xC8Z\x04
hfile.LASTKEY = 1001/info:name/1732767868703/Put/vlen=0/mvcc=0
hfile.LEN_OF_BIGGEST_CELL = \x00\x00\x00\x00\x00\x00\x00+
Mid-key: Optional[1001/info:age/1732768745586/Put/seqid=0]
## 布隆过滤器的信息
Bloom filter:
BloomSize: 2
No of Keys in bloom: 1
Max Keys for bloom: 1
Percentage filled: 100%
Number of chunks: 1
Comparator: ByteArrayComparator
Delete Family Bloom filter:
Not present1.2 读流程
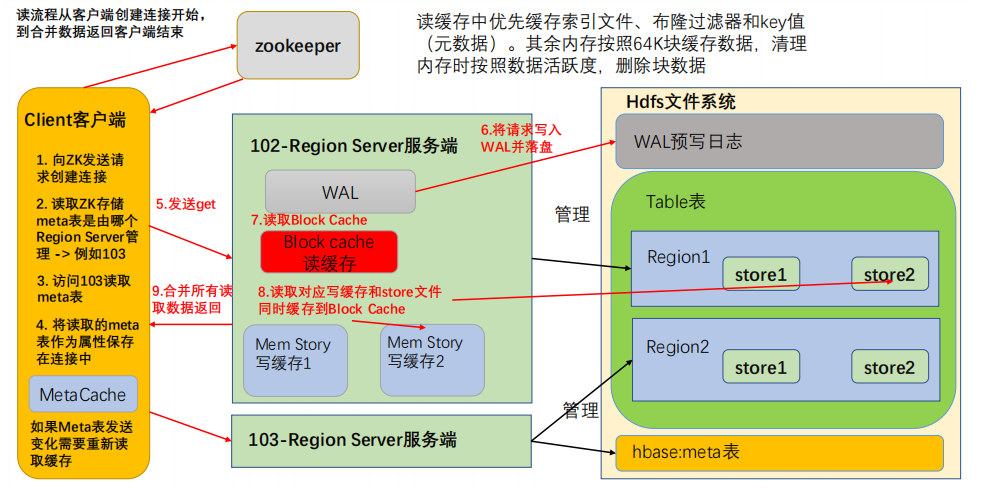
- 创建连接同写流程。
- 创建Table对象发送get请求。
- 优先访问Block Cache,查找是否之前读取过,并且可以读取HFile的索引信息和布隆过滤器。
- 不管读缓存中是否已经有数据了(可能已经过期了),都需要再次读取写缓存和store中的文件(防止数据刚刚写入就开始读取)。
- 最终将所有读取到的数据合并版本(高版本的数据覆盖低版本的),按照get的要求返回即可。
1.3 合并读取数据优化
每次读取数据都需要读取三个位置(block cache\写缓存\hfile),最后进行版本的合并。效率会非常低,所有系统需要对此优化。
- HFile带有索引文件,读取对应RowKey数据会比较快。
- Block Cache会缓存之前读取的内容和元数据信息,如果HFile没有发生变化(记录在HFile尾信息中),则不需要再次读取。
- 不管读缓存中是否已经有数据了(可能已经过期了),都需要再次读取写缓存和store中的文件。
- 最终将所有读取到的数据合并版本,按照get的要求返回即可。
2. 写流程
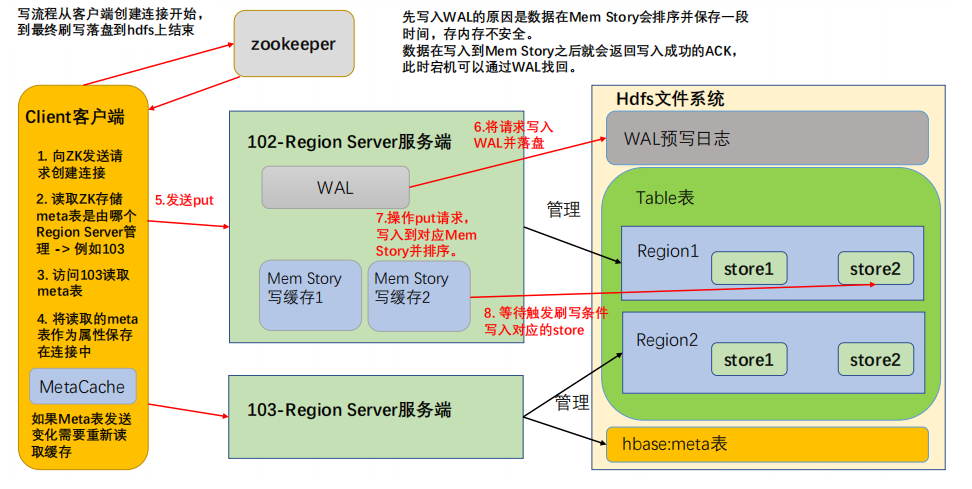
- 写流程顺序正如API编写顺序,首先创建HBase的重量级连接。
- 首先访问zookeeper,获取hbase:meta表位于哪个Region Server;
- 访问对应的Region Server,获取hbase:meta表,将其缓存到连接中,作为连接属性MetaCache,由于Meta表格具有一定的数据量,导致了创建连接比较慢;
- 之后使用创建的连接获取Table,这是一个轻量级的连接,只有在第一次创建的时候会检查表格是否存在访问RegionServer,之后在获取Table时不会访问RegionServer;
- 将数据顺序写入(追加)到 WAL,此处写入是直接落盘的,并设置专门的线程控制WAL预写日志的滚动(类似 Flume);
- 根据写入命令的RowKey和ColumnFamily查看具体写入到哪个MemStore,并且在MemStore中排序;
- 向客户端发送ack;
- 等达到MemStore的刷写时机后,将数据刷写到对应的store中。
3. MemStore Flush
3.1 刷写机制
MemStore刷写由多个线程控制,条件互相独立;主要的刷写规则是控制刷写文件的大小,在每一个刷写线程中都会进行监控。
- 当某个memstroe的大小达到了
hbase.hregion.memstore.flush.size(默认值128M,和HDFS的块大小一致),其所在region的所有memstore都会刷写。当memstore的大小达到:hbase.hregion.memstore.flush.size(默认值128M) *hbase.hregion.memstore.block.multiplier(默认值4)时,会刷写同时阻止继续往该memstore写数据(由于线程监控是周期性的,所有有可能面对数据洪峰,尽管可能性比较小)。 - 由HRegionServer中的属性MemStoreFlusher内部线程FlushHandler控制。标准为LOWER_MARK(低水位线)和HIGH_MARK(高水位线),意义在于避免写缓存使用过多的内存造成OOM。当region server中memstore的总大小达到低水位线:
java_heapsize*hbase.regionserver.global.memstore.size(默认值0.4) *hbase.regionserver.global.memstore.size.lower.limit(默认值0.95)
region会按照其所有memstore的大小顺序(由大到小)依次进行刷写。直到region server中所有memstore的总大小减小到上述值以下。
当region server中memstore的总大小达到高水位线hbase.regionserver.global.memstore.size(默认值0.4),会同时阻止继续往所有的memstore写数据。 - 为了避免数据过长时间处于内存之中,到达自动刷写的时间,也会触发memstore flush。由HRegionServer的属性PeriodicMemStoreFlusher控制进行,由于重要性比较低,5min才会执行一次。自动刷新的时间间隔由该属性进行配置
hbase.regionserver.optionalcacheflushinterval(默认1小时) - 当WAL文件的数量超过
hbase.regionserver.max.logs,region会按照时间顺序依次进行刷写,直到WAL文件数量减小到hbase.regionserver.max.log以下(该属性名已经废弃,现无需手动设置,最大值为32)。可以理解为wal文件在数据最终写入到table里面时就会被删除,基本上不会累积达到这个配置阈值,除非写入table很慢(那机器的性能很慢),导致wal文件堆积。
3.2 查看源码
打开org.apache.hadoop.hbase.regionserver.MemStoreFlusher类: 进入FlushHandler类,它是一个线程类:
进入FlushHandler类,它是一个线程类:
private class FlushHandler extends Thread {
public void run() {
// ReginServer只要启动,这里就是一直满足条件不断循环
while (!server.isStopped() && running.get()) {
FlushQueueEntry fqe = null;
try {
wakeupPending.set(false); // allow someone to wake us up again
fqe = flushQueue.poll(threadWakeFrequency, TimeUnit.MILLISECONDS);
if (fqe == null || fqe == WAKEUPFLUSH_INSTANCE) {
// 判断低水位线
FlushType type = isAboveLowWaterMark();
// 类型有高水位线,低水位线和NORMAL
if (type != FlushType.NORMAL) {
if (!flushOneForGlobalPressure(type)) {
Thread.sleep(1000);
wakeUpIfBlocking();
}
// 唤醒刷写线程
wakeupFlushThread();
}
continue;
}
FlushRegionEntry fre = (FlushRegionEntry) fqe;
// 如果刷完就break,退出while循环
if (!flushRegion(fre)) {
break;
}
} catch (InterruptedException ex) {
//......异常处理
}
if (server.isStopped()) {
synchronized (regionsInQueue) {
regionsInQueue.clear();
flushQueue.clear();
}
wakeUpIfBlocking();
}
LOG.info(getName() + " exiting");
}
......
}另外ReginServer会周期的执行reclaimMemStoreMemory()方法: