Phoenix二级索引
1. 二级索引配置
修改HRegionserver节点的hbase-site.xml,添加如下配置:
xml
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>需要重启hbase集群和重新连接phoenix shell。
2. 全局索引(global index)
Global Index是默认的索引格式,创建全局索引时,会在HBase中建立一张新表。也就是说索引数据和数据表是存放在不同的表中的,因此全局索引适用于多读少写的业务场景。写数据的时候会消耗大量开销,因为索引表也要更新,而索引表是分布在不同的数据节点上的,跨节点的数据传输带来了较大的性能消耗。
在读数据的时候Phoenix会选择索引表来降低查询消耗的时间。
2.1 创建单个字段的全局索引
sh
## 新建一张表
0: jdbc:phoenix:> create table t_salary(
. . . . . . . .)> id bigint primary key,
. . . . . . . .)> name varchar,
. . . . . . . .)> money bigint,
. . . . . . . .)> address varchar
. . . . . . . .)> );
No rows affected (1.297 seconds)
0: jdbc:phoenix:> create index idx_name on t_salary(name);
No rows affected (6.351 seconds)查看表列表,会发现多了一个idx_name的表: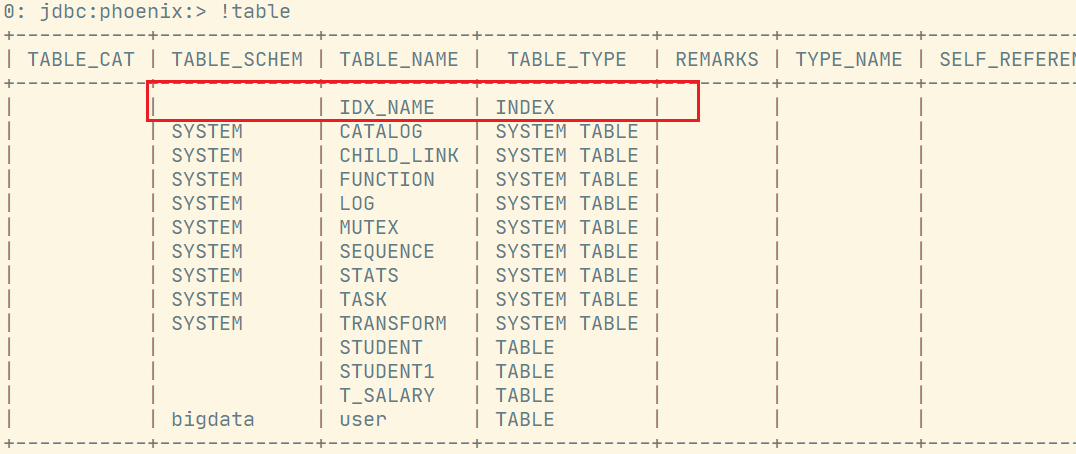
2.2 查看二级索引是否有效
- 插入测试数据:
sh
0: jdbc:phoenix:> upsert into t_salary values(1000,'jack','sichuan',15000);
1 row affected (0.13 seconds)
0: jdbc:phoenix:> upsert into t_salary values(1001,'maomao','suining',8000);
1 row affected (0.037 seconds)
0: jdbc:phoenix:> upsert into t_salary values(1002,'ahuang','双流',7000);
1 row affected (0.03 seconds)
0: jdbc:phoenix:> upsert into t_salary values(1003,'诸葛亮','南阳',27000);
1 row affected (0.039 seconds)
0: jdbc:phoenix:> select * from t_salary;
+------+--------+---------+-------+
| ID | NAME | ADDRESS | MONEY |
+------+--------+---------+-------+
| 1000 | jack | sichuan | 15000 |
| 1001 | maomao | suining | 8000 |
| 1002 | ahuang | 双流 | 7000 |
| 1003 | 诸葛亮 | 南阳 | 27000 |
+------+--------+---------+-------+
4 rows selected (0.05 seconds)- 使用explainPlan执行计划查看有二级索引之后会变成范围扫描
sh
0: jdbc:phoenix:> explain select id,name from t_salary where name='jack';
+-----------------------------------------------------------------------------+----------------+---------------+-------------+
| PLAN | EST_BYTES_READ | EST_ROWS_READ | EST_INFO_TS |
+-----------------------------------------------------------------------------+----------------+---------------+-------------+
| CLIENT 1-CHUNK PARALLEL 1-WAY ROUND ROBIN RANGE SCAN OVER IDX_NAME ['jack'] | null | null | null |
| SERVER FILTER BY FIRST KEY ONLY | null | null | null |
+-----------------------------------------------------------------------------+----------------+---------------+-------------+
2 rows selected (0.032 seconds)警告
如果查询的字段除了索引字段还有其他字段,索引表不会被使用,也就是说不会带来查询速度的提升。  若想解决上述问题,可采用如下方案:
若想解决上述问题,可采用如下方案:
- 使用包含索引
- 使用本地索引
3. 包含索引(covered index)
创建携带其他字段的全局索引(本质还是全局索引), 可以认为是全局索引的补充。
3.1 删除旧索引
先删除之前的索引表idx_name,避免phoeinx维护2张索引表
sh
0: jdbc:phoenix:> drop index idx_name on t_salary;
No rows affected (1.726 seconds)3.2 创建包含索引
sh
0: jdbc:phoenix:> create index idx_name on t_salary(name) include (money);
8 rows affected (6.276 seconds)3.3 查看二级索引是否有效
sh
0: jdbc:phoenix:> explain select id,name,money from t_salary where name='诸葛亮';
+----------------------------------------------------------------------------+----------------+---------------+-------------+
| PLAN | EST_BYTES_READ | EST_ROWS_READ | EST_INFO_TS |
+----------------------------------------------------------------------------+----------------+---------------+-------------+
| CLIENT 1-CHUNK PARALLEL 1-WAY ROUND ROBIN RANGE SCAN OVER IDX_NAME ['诸葛亮'] | null | null | null |
+----------------------------------------------------------------------------+----------------+---------------+-------------+
1 row selected (0.021 seconds)4. 本地索引(local index)
Local Index适用于写操作频繁的场景, 索引数据和数据表的数据是存放在同一张表中(且是同一个Region),避免了在写操作的时候往不同服务器的索引表中写索引带来的额外开销。
本地索引会将所有的信息存在一个影子列族中,虽然读取的时候也是范围扫描,但是没有全局索引快,优点在于不用写多个表了。
4.1 删除之前的索引
sh
0: jdbc:phoenix:> drop index idx_name on t_salary;
No rows affected (1.32 seconds)4.2 创建本地索引
索引列可以添加多个
sh
0: jdbc:phoenix:> create local index idx_name on t_salary(name, money, address);
8 rows affected (11.284 seconds)从4.8.0开始,本地索引数据存储在同一个数据表中单独的影子列族中。在使用本地索引进行读取时,因为不能预先确定索引数据确切的region位置,因此必须检查每个region的数据。这会给读取时带来一些额外开销。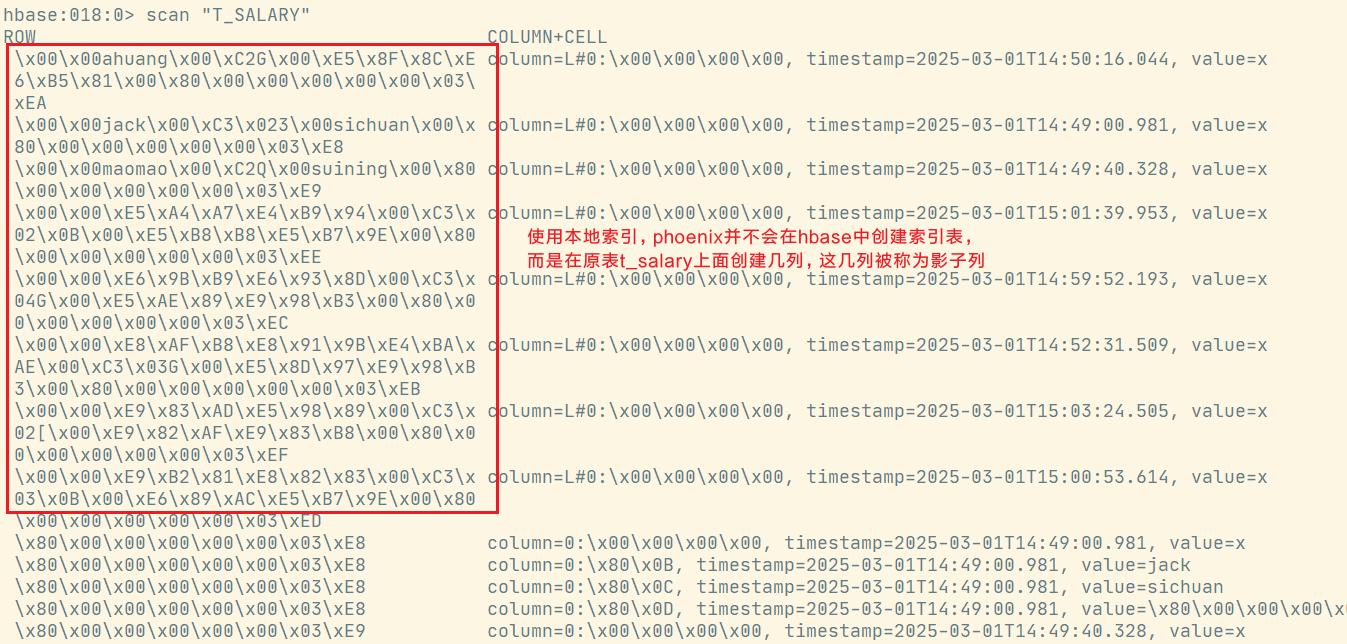
4.3 查看二级索引是否有效
sh
0: jdbc:phoenix:> explain select id,name,money,address from t_salary where name='大乔';
+---------------------------------------------------------------------------------------+----------------+---------------+-------------+
| PLAN | EST_BYTES_READ | EST_ROWS_READ | EST_INFO_TS |
+---------------------------------------------------------------------------------------+----------------+---------------+-------------+
| CLIENT 1-CHUNK PARALLEL 1-WAY ROUND ROBIN RANGE SCAN OVER IDX_NAME(T_SALARY) [1,'大乔'] | null | null | null |
| SERVER FILTER BY FIRST KEY ONLY | null | null | null |
+---------------------------------------------------------------------------------------+----------------+---------------+-------------+
2 rows selected (0.03 seconds)5. 覆盖索引
覆盖索引的特点是我们可以把关心的列打包存储在索引表中,一旦在索引表中能够找到索引条目就不需要返回主表,直接拿到查询结果。
sql
-- 建立覆盖索引
CREATE INDEX IDX_COVER_PARENTID on TMP_STAFF(parentid) include(departmentid);
-- 使用覆盖索引
SELECT departmentid FROM TMP_STAFF WHERE parentid = 1782 ;