API操作HBase
1. 环境准备
- 新建maven项目hbase-demo,引入依赖:
<dependencies>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.6.1-hadoop3</version>
</dependency>
</dependencies>- 在resources目录下面创建log4j.properties文件
log4j.rootLogger=INFO, stdout, D
# Console Appender
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern= %d{hh:mm:ss,SSS} [%t] %-5p %c %x - %m%n
# Custom tweaks
log4j.logger.org.apache=ERROR
log4j.logger.org.apache.spark=ERROR
log4j.logger.org.sparkproject.jetty=ERROR
# log file
log4j.appender.D = org.apache.log4j.DailyRollingFileAppender
log4j.appender.D.File = log/log.log
log4j.appender.D.Append = true
log4j.appender.D.Threshold = ERROR
log4j.appender.D.layout = org.apache.log4j.PatternLayout
log4j.appender.D.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n2. 创建连接
根据官方API介绍,HBase的客户端连接由类来创建,用户使用完成ConnectionFactory之后需要手动关闭连接。同时连接是一个重量级的,推荐一个进程使用一个连接,对HBase的命令通过连接中的两个属性Admin和Table来实现。
2.1 单线程连接
public class App {
public static void main( String[] args ) throws IOException {
// 1. 创建连接配置对象
Configuration conf = new Configuration();
// 2. 添加配置参数
conf.set("hbase.zookeeper.quorum", "hadoop102,hadoop103,hadoop104");
// 3. 创建连接
// 默认创建的同步连接
Connection connection = ConnectionFactory.createConnection(conf);
// 不建议使用异步连接
CompletableFuture<AsyncConnection> asyncConn = ConnectionFactory.createAsyncConnection(conf);
// 4. 使用连接
System.out.println(connection);
// 5. 关闭连接
connection.close();
}
}2.2 多线程连接
从服务器上面下载hbase-site.xml文件,放到工程resource目录下,配置如下:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop102,hadoop103,hadoop104</value>
</property>
</configuration>由于hbase的连接是一个比较重的对象,hbase官方不建议每次操作hbase都去创建连接,hbase的连接对象是线程安全的,可以在多线程环境中共同使用。
public class HBaseConnection {
static Connection connection = null;
static {
try {
connection = ConnectionFactory.createConnection();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
// 主进程退出时调用
private static void closeConn() throws IOException {
if(connection!=null){
connection.close();
}
}
}为何不再使用Configuration对象进行创建连接对象了呢?查询源码发现:
在createConnection()方法里面会调用create()方法 
点击进入create()方法: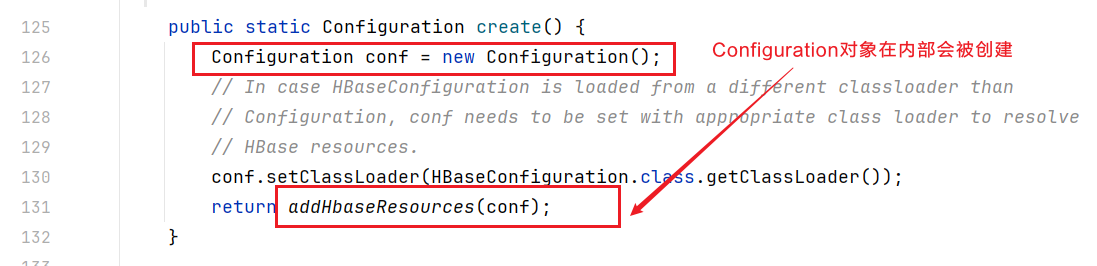 点击进入addHbaseResources()方法,发现会读取hbase-site.xml配置文件,所以只需要在resource目录下创建名为hbase-site.xml的配置文件,就会被hbase客户端自动读取。
点击进入addHbaseResources()方法,发现会读取hbase-site.xml配置文件,所以只需要在resource目录下创建名为hbase-site.xml的配置文件,就会被hbase客户端自动读取。
3. 创建命令空间
public class HBaseDML {
static Logger logger = LoggerFactory.getLogger(HBaseDML.class);
static Connection conn = HBaseConnection.connection;
public static void createNamespace(String nameSpace) throws IOException {
// 获取Admin对象, Admin对象不是线程安全的,不能放入缓存或者池化
// Admin对象主要用来管理命令空间、表
Admin admin = conn.getAdmin();
try {
admin.createNamespace(NamespaceDescriptor.create(nameSpace).build());
}catch (Exception e){
logger.error("创建命名空间报错", e);
}
admin.close();
}
public static void main(String[] args) throws IOException {
createNamespace("bigdata");
HBaseConnection.closeConn();
}
}登录服务器验证查看命名空间:
hbase:003:0> list_namespace
NAMESPACE
bigdata
default
hbase
ns1
4 row(s)
Took 0.1040 seconds4. 判断表是否存在
package org.example
import org.apache.hadoop.hbase.TableName
import org.slf4j.LoggerFactory
object HBaseDML2{
val logger = LoggerFactory.getLogger(HBaseDML2.getClass)
val connection = HBaseConnection.connection
private def isExistTable(tableName:String, nameSpace:String):Boolean={
val admin = connection.getAdmin
val flag = admin.tableExists(TableName.valueOf(nameSpace, tableName))
admin.close()
flag
}
def main(args: Array[String]): Unit = {
var flag: Boolean = false
try {
flag = isExistTable("ns1", "person")
}catch {
case e : Exception=>
logger.error("存在判断报错", e)
}
println(flag)
HBaseConnection.closeConn();
}
}4. 创建表
package org.example
import org.apache.hadoop.hbase.TableName
import org.apache.hadoop.hbase.client.{ColumnFamilyDescriptorBuilder, TableDescriptorBuilder}
import org.apache.hadoop.hbase.util.Bytes
import org.slf4j.LoggerFactory
object HBaseDML3{
val logger = LoggerFactory.getLogger(HBaseDML3.getClass)
val connection = HBaseConnection.connection
private def isExistTable(nameSpace:String, tableName:String):Boolean={
val admin = connection.getAdmin
val flag = admin.tableExists(TableName.valueOf(nameSpace, tableName))
admin.close()
flag
}
def main(args: Array[String]): Unit = {
try {
if(isExistTable("bigdata", "user")){
println("已存在表")
}else{
// 表不存在,创建表
val result = createTable("bigdata", "user", 5, "info", "msg")
println(result)
}
}catch {
case e : Exception=>
logger.error("存在判断报错", e)
}
HBaseConnection.closeConn();
}
private def createTable(namespace: String, tableName: String, maxVersion: Int, columnNameArray:String*) = {
if(columnNameArray.isEmpty){
"表字段缺失"
}else{
val tableBuilder = TableDescriptorBuilder.newBuilder(TableName.valueOf(namespace, tableName))
// 遍历创建列族
for (columnName <- columnNameArray) {
// 创建列族描述
val familyDescriptor = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(columnName)).setMaxVersions(maxVersion).build()
tableBuilder.setColumnFamily(familyDescriptor)
}
val admin = connection.getAdmin
admin.createTable(tableBuilder.build())
admin.close()
"创建成功"
}
}
}查看结果: 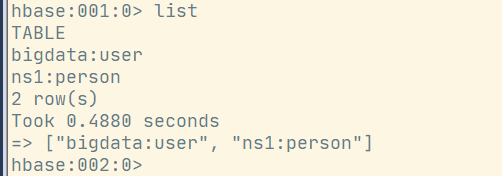
5. 修改表
object HBaseDML4 {
val logger = LoggerFactory.getLogger(HBaseDML4.getClass)
val connection = HBaseConnection.connection
private def isExistTable(nameSpace: String, tableName: String): Boolean = {
val admin = connection.getAdmin
val flag = admin.tableExists(TableName.valueOf(nameSpace, tableName))
admin.close()
flag
}
def main(args: Array[String]): Unit = {
try {
if (isExistTable("bigdata", "user")) {
// 表存在
val result = modifyTableVersion("bigdata", "user", "info", 6)
println(result)
} else {
println("不存在表")
}
} catch {
case e: Exception =>
logger.error("存在判断报错", e)
}
HBaseConnection.closeConn();
}
private def modifyTableVersion(namespace: String, tableName: String, columnNameFamily: String, version: Int) = {
if (version < 1) {
"版本不能小于1"
} else {
val admin = connection.getAdmin
// 修改表不能再通过newBuilder(tableName)方法,它会创建一个新的表格构建器,没有hbase对应表中的信息
// val tableBuilder = TableDescriptorBuilder.newBuilder(TableName.valueOf(namespace, tableName))
// 获取表的描述
val tableDescriptor = admin.getDescriptor(TableName.valueOf(namespace, tableName))
val tableBuilder = TableDescriptorBuilder.newBuilder(tableDescriptor)
// newBuilder(byte)会创建一个新的列族描述
// val familyDescriptor = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(columnNameFamily))
// 应该用从hbase读取过来的现有的列族描述
val familyDescriptor = tableDescriptor.getColumnFamily(Bytes.toBytes(columnNameFamily))
val newFamilyDescriptor = ColumnFamilyDescriptorBuilder.newBuilder(familyDescriptor)
.setMaxVersions(version)
.build()
// tableBuilder.setColumnFamily()会将表格描述中所有的列族描述覆盖
tableBuilder.modifyColumnFamily(newFamilyDescriptor)
admin.modifyTable(tableBuilder.build())
// 关闭admin
admin.close()
"创建成功"
}
}
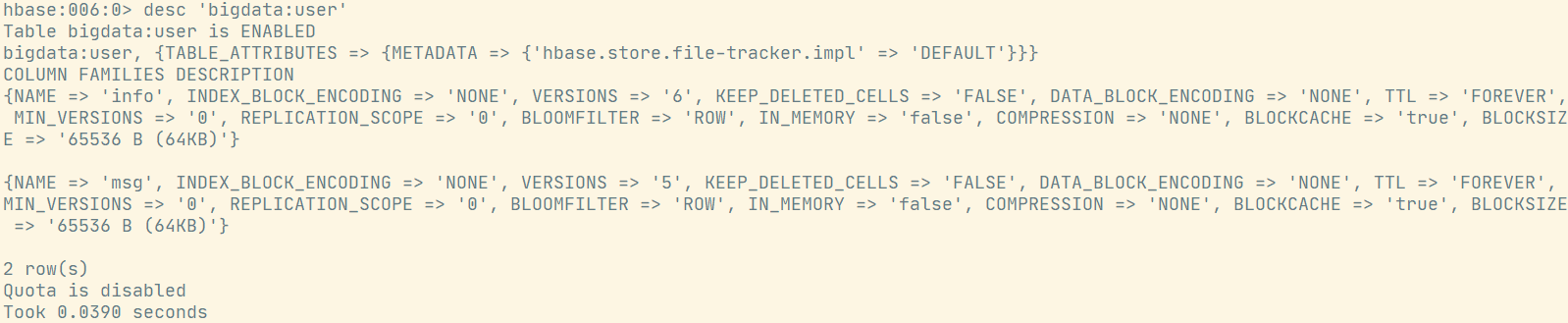
}
6. 删除表
原生API删除表格是需要两步,下面代码封装后只需要执行一步,但是实际工作中一般不会封装删除表的方法,只是演示,在大数据场景中,误删除表格会造成很大的数据损失。
import org.apache.hadoop.hbase.TableName
import org.slf4j.LoggerFactory
object HBaseDML5 {
val logger = LoggerFactory.getLogger(HBaseDML5.getClass)
val connection = HBaseConnection.connection
private def isExistTable(nameSpace: String, tableName: String): Boolean = {
val admin = connection.getAdmin
val flag = admin.tableExists(TableName.valueOf(nameSpace, tableName))
admin.close()
flag
}
def main(args: Array[String]): Unit = {
try {
if (isExistTable("bigdata", "user")) {
// 表存在
val result = deleteTable("bigdata", "user")
println(result)
} else {
println("不存在表")
}
} catch {
case e: Exception =>
logger.error("存在判断报错", e)
}
HBaseConnection.closeConn();
}
private def deleteTable(namespace: String, tableName: String) = {
val admin = connection.getAdmin
val table = TableName.valueOf(namespace, tableName)
// 删除表格之前需要标记表不可用
admin.disableTable(table)
admin.deleteTable(table)
// 关闭admin
admin.close()
"删除成功"
}
}7. 写入数据
object HBaseDDL1 {
val logger = LoggerFactory.getLogger(HBaseDML5.getClass)
val connection = HBaseConnection.connection
private def isExistTable(nameSpace: String, tableName: String): Boolean = {
val admin = connection.getAdmin
val flag = admin.tableExists(TableName.valueOf(nameSpace, tableName))
admin.close()
flag
}
def main(args: Array[String]): Unit = {
try {
if (isExistTable("bigdata", "user")) {
// 表存在
putCell("bigdata", "user","1001", "info", "name", "张三")
putCell("bigdata", "user","1001", "info", "age", "28")
println("插入完成")
} else {
println("不存在表")
}
} catch {
case e: Exception =>
logger.error("存在判断报错", e)
}
HBaseConnection.closeConn();
}
/**
* @param namespace 命名空间
* @param tableName 表名称
* @param rowKey 主键
* @param columFamily 列族
* @param columnName 字段名称
* @param data 字段值
*/
private def putCell(namespace: String, tableName: String, rowKey: String, columFamily: String, columnName: String, data:String) = {
val table = connection.getTable(TableName.valueOf(namespace, tableName))
// 创建put对象
val put = new client.Put(Bytes.toBytes(rowKey))
// 给put添加数据
put.addColumn(Bytes.toBytes(columFamily), Bytes.toBytes(columnName), Bytes.toBytes(data))
// 将数据写入
table.put(put)
table.close()
}
}执行完毕后查看:
8. 读取数据
8.1 读取单列数据
object HBaseDDL2 {
val logger = LoggerFactory.getLogger(HBaseDML5.getClass)
val connection = HBaseConnection.connection
private def isExistTable(nameSpace: String, tableName: String): Boolean = {
val admin = connection.getAdmin
val flag = admin.tableExists(TableName.valueOf(nameSpace, tableName))
admin.close()
flag
}
def main(args: Array[String]): Unit = {
try {
if (isExistTable("bigdata", "user")) {
// 表存在
getCells("bigdata", "user","1001", "info", "name")
println("读取完成")
} else {
println("不存在表")
}
} catch {
case e: Exception =>
logger.error("存在判断报错", e)
}
HBaseConnection.closeConn();
}
/**
* @param namespace 命名空间
* @param tableName 表名称
* @param rowKey 主键
* @param columFamily 列族
* @param columnName 字段名称
*/
private def getCells(namespace: String, tableName: String, rowKey: String, columFamily: String, columnName: String) = {
val table = connection.getTable(TableName.valueOf(namespace, tableName))
// 创建get对象
val get = new Get(Bytes.toBytes(rowKey))
// 给put添加数据, addColumn读取某一列数据
get.addColumn(Bytes.toBytes(columFamily), Bytes.toBytes(columnName))
// 读取所有版本
get.readAllVersions()
// 获取数据
val result = table.get(get)
val cells = result.rawCells()
// 如果是实际开发,需要在业务方法中处理数据
for(cell <- cells){
println(new String(CellUtil.cloneValue(cell)))
}
table.close()
}
}执行结果: 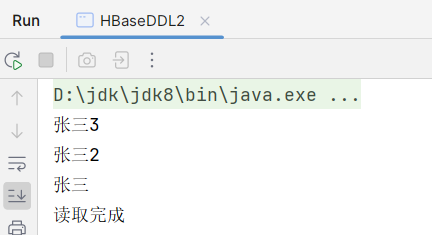
8.2 扫描数据
前面的方法一次只能读取一行数据,如果需要读取多行数据需要使用scan的api:
object HBaseDDL3 {
val logger = LoggerFactory.getLogger(HBaseDML5.getClass)
val connection = HBaseConnection.connection
private def isExistTable(nameSpace: String, tableName: String): Boolean = {
val admin = connection.getAdmin
val flag = admin.tableExists(TableName.valueOf(nameSpace, tableName))
admin.close()
flag
}
def main(args: Array[String]): Unit = {
try {
if (isExistTable("bigdata", "user")) {
// 表存在
scanRows("bigdata", "user","1001", "1004")
println("读取完成")
} else {
println("不存在表")
}
} catch {
case e: Exception =>
logger.error("存在判断报错", e)
}
HBaseConnection.closeConn();
}
/**
* @param namespace 命名空间
* @param tableName 表名称
* @param startRow 主键开始
* @param endRow 主键结束
*/
private def scanRows(namespace: String, tableName: String, startRow: String, endRow: String) = {
val table = connection.getTable(TableName.valueOf(namespace, tableName))
// 创建scan对象, 默认查询所有,一般要限制行数
val scan = new Scan()
// 设置起止行,左闭右开
scan.withStartRow(Bytes.toBytes(startRow))
scan.withStopRow(Bytes.toBytes(endRow))
// 获得scanner
val scanner = table.getScanner(scan)
scanner.forEach(result=>{
val cells = result.rawCells()
for(cell <- cells){
val rowStr = new String(CellUtil.cloneRow(cell))+"\t"+
new String(CellUtil.cloneFamily(cell))+"\t"+
new String(CellUtil.cloneQualifier(cell))+"\t"+
new String(CellUtil.cloneValue(cell))
println(rowStr)
}
})
table.close()
}
}执行结果: 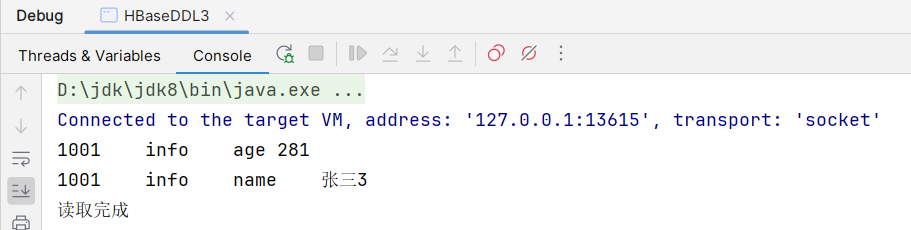
8.3 带过滤扫描
过滤器有两种,第一种过滤后只保留当前列数据, 第二种过滤后保留当前行数据。
object HBaseDDL4 {
val logger = LoggerFactory.getLogger(HBaseDML5.getClass)
val connection = HBaseConnection.connection
private def isExistTable(nameSpace: String, tableName: String): Boolean = {
val admin = connection.getAdmin
val flag = admin.tableExists(TableName.valueOf(nameSpace, tableName))
admin.close()
flag
}
def main(args: Array[String]): Unit = {
try {
if (isExistTable("bigdata", "user")) {
// 表存在
filterScanRows("bigdata", "user","1001","1004", "info", "name", "张三2")
println("读取完成")
} else {
println("不存在表")
}
} catch {
case e: Exception =>
logger.error("存在判断报错", e)
}
HBaseConnection.closeConn();
}
/**
* @param namespace 命名空间
* @param tableName 表名称
* @param startRow 主键
* @param endRow 列族
*/
private def filterScanRows(namespace: String, tableName: String, startRow: String, endRow: String, columnFamily:String, columnName:String, value:String) = {
val table = connection.getTable(TableName.valueOf(namespace, tableName))
// 创建scan对象, 默认查询所有,一般要限制行数
val scan = new Scan()
// 设置起止行,左闭右开
scan.withStartRow(Bytes.toBytes(startRow))
scan.withStopRow(Bytes.toBytes(endRow))
val filter = new ColumnValueFilter(
// 列族名称
Bytes.toBytes(columnFamily),
// 列名称
Bytes.toBytes(columnName),
// 比较关系
CompareOperator.EQUAL,
Bytes.toBytes(value),
)
scan.setFilter(filter)
// 获得scanner
val scanner = table.getScanner(scan)
scanner.forEach(result=>{
val cells = result.rawCells()
for(cell <- cells){
val rowStr = new String(CellUtil.cloneRow(cell))+"\t"+
new String(CellUtil.cloneFamily(cell))+"\t"+
new String(CellUtil.cloneQualifier(cell))+"\t"+
new String(CellUtil.cloneValue(cell))
println(rowStr)
}
})
table.close()
}
}执行结果: 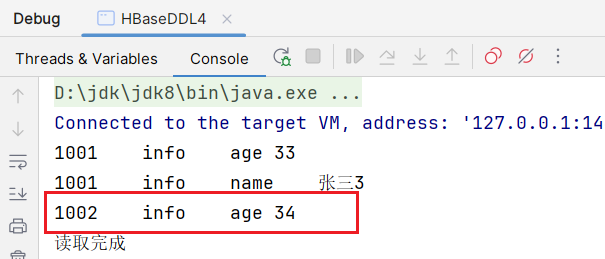 发现里面rowkey为1002也被读了出来,查看user所有数据:
发现里面rowkey为1002也被读了出来,查看user所有数据: 发现这条数据并没有column叫name的,原因在于hbase查询过滤的时候,如果指定字段的值没有也会被查询出来。可以在自己的代码中进行二次过滤。
发现这条数据并没有column叫name的,原因在于hbase查询过滤的时候,如果指定字段的值没有也会被查询出来。可以在自己的代码中进行二次过滤。
9. 删除数据
删除数据只能按照rowKey和列进行删除
import org.apache.hadoop.hbase.client.{Delete}
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.hbase.{TableName}
import org.slf4j.LoggerFactory
object HBaseDDL6 {
val logger = LoggerFactory.getLogger(HBaseDML5.getClass)
val connection = HBaseConnection.connection
private def isExistTable(nameSpace: String, tableName: String): Boolean = {
val admin = connection.getAdmin
val flag = admin.tableExists(TableName.valueOf(nameSpace, tableName))
admin.close()
flag
}
def main(args: Array[String]): Unit = {
try {
if (isExistTable("bigdata", "user")) {
// 表存在
HBaseDDL2.getCells("bigdata", "user","1002", "info", "age")
deleteColumn("bigdata", "user","1002", "info", "age")
println("读取完成")
} else {
println("不存在表")
}
} catch {
case e: Exception =>
logger.error("存在判断报错", e)
}
HBaseConnection.closeConn();
}
/**
* @param namespace 命名空间
* @param tableName 表名称
* @param rowKey 主键
* @param columnFamily 列族
* @param columnName 列名
*/
private def deleteColumn(namespace: String, tableName: String, rowKey:String, columnFamily:String, columnName:String) = {
val table = connection.getTable(TableName.valueOf(namespace, tableName))
val delete = new Delete(Bytes.toBytes(rowKey))
// 只删除最新版本的数据
// delete.addColumn(Bytes.toBytes(columnFamily),Bytes.toBytes(columnName))
// 相当于命令行deleteall, 删除所有key对应的版本数据
delete.addColumns(Bytes.toBytes(columnFamily),Bytes.toBytes(columnName))
table.delete(delete)
table.close()
}
}提示
在开发中,实际很少会接触底层API, 会有人将底层封装好提供jar给我们进行业务开发