数仓开发之DIM层
1. DIM层设计要点
- DIM层的设计依据是维度建模理论,该层存储维度模型的维度表。
- DIM层的数据存储在HBase表中。
DIM层表是用于维度关联的,要通过主键去获取相关维度信息,这种场景下K-V类型数据库的效率较高。常见的K-V类型数据库有Redis、HBase,而Redis的数据常驻内存,会给内存造成较大压力,因而选用HBase存储维度数据。 - DIM层表名的命名规范为dim_表名
2. 新建远端dev分支
在Gitee的gmall2023-realtime仓库下新建分支dev 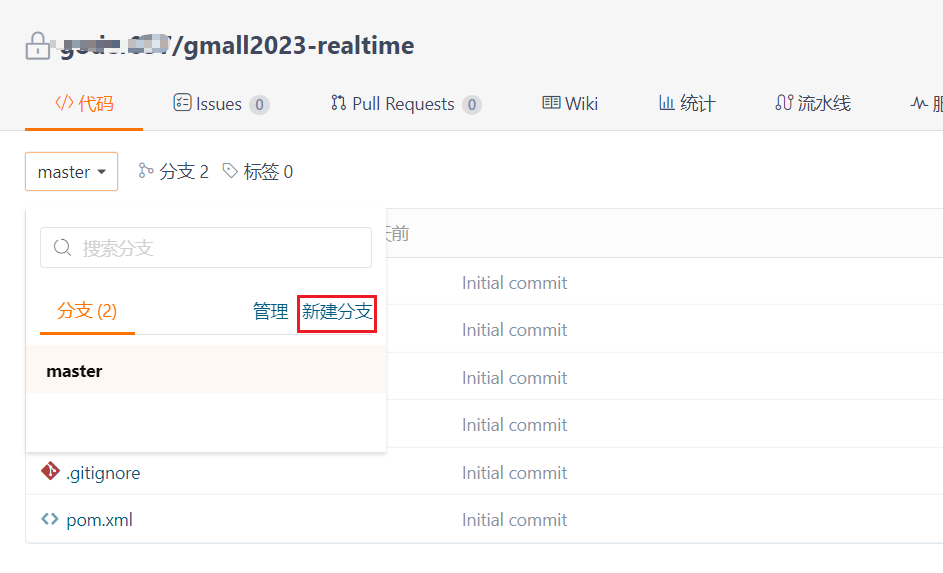 在本地fetch dev分支:
在本地fetch dev分支: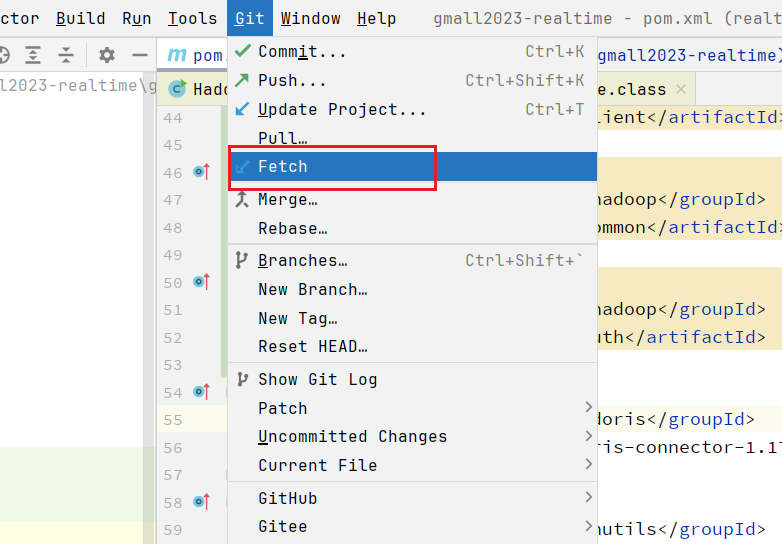
3. App基类设计
Flink Job的处理流程大致可以分为以下几步:
(1)初始化流处理环境,配置检查点,从Kafka中读取目标主题数据
(2)执行核心处理逻辑
(3)执行
其中,所有Job的第一步和第三步基本相同,我们可以定义基类,将这两步交给基类完成。定义抽象方法,用于实现核心处理逻辑,子类只需要重写该方法即可实现功能。省去了大量的重复代码,且不必关心整体的处理流程。
因此使用模板方法设计模式 在realtime-common工程中创建BaseApp类:
public abstract class BaseApp {
/**
* 1)port:测试环境下启动本地WebUI的端口DIM层维度分流应用使用10001端口;DWD层应用程序端口从10011开始,自增
* 1;DWS层端口从10021开始,自增1
* 2)parallelism:并行度,本项目统一设置为4。
* 3)ckAndGroupId:消费Kafka主题时的消费者组ID和检查点路径的最后一级目录名称,二者取值相同,为Job主程序类名
* 的下划线命名形式。如DimApp的该参数取值为dim_app。
* 4)topic:消费的Kafka主题名称
*/
public void start(String ckAndGroupId, String topicName) throws Exception {
start01(4, ckAndGroupId, topicName);
}
private void start01(int parallelism, String ckAndGroupId, String topicName) throws Exception {
System.setProperty("HADOOP_USER_NAME", "jack");
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(parallelism);
// 设置状态后端
env.setStateBackend(new HashMapStateBackend());
// 设置checkpoint间隔时间
env.enableCheckpointing(5000);
// 设置精确一次
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointStorage("hdfs://hadoop102:8020/flink/ckps/"+ckAndGroupId);
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(5000);
env.getCheckpointConfig().setCheckpointTimeout(10000);
env.getCheckpointConfig().setExternalizedCheckpointCleanup(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
KafkaSource<String> kafkaSource = KafkaSource.<String>builder()
.setBootstrapServers("hadoop102:9092,hadoop103:9092,hadoop104:9092")
.setTopics(topicName)
.setValueOnlyDeserializer(new SimpleStringSchema())
.setStartingOffsets(OffsetsInitializer.earliest())
.build();
DataStreamSource<String> kafkaStreamSource =
env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "kafka source");
handle(env, kafkaStreamSource);
env.execute();
}
public abstract void handle(StreamExecutionEnvironment env, DataStreamSource<String> kafkaStreamSource);
}4. 创建常量和工具类
创建常量Constant类
项目会用到大量的配置信息,如主题名、Kafka集群地址等,为了减少冗余代码,保证一致性,将这些配置信息统一抽取到常量类中。
public class Constant {
public static final String KAFKA_BROKERS = "hadoop102:9092,hadoop103:9092,hadoop104:9092";
public static final String TOPIC_DB = "topic_db";
public static final String TOPIC_LOG = "topic_log";
public static final String MYSQL_HOST = "hadoop102";
public static final int MYSQL_PORT = 3306;
public static final String MYSQL_USER_NAME = "root";
public static final String MYSQL_PASSWORD = "123456";
public static final String HBASE_NAMESPACE = "gmall";
public static final String MYSQL_DRIVER = "com.mysql.cj.jdbc.Driver";
public static final String MYSQL_URL = "jdbc:mysql://hadoop102:3307?useSSL=false";
public static final String TOPIC_DWD_TRAFFIC_START = "dwd_traffic_start";
public static final String TOPIC_DWD_TRAFFIC_ERR = "dwd_traffic_err";
public static final String TOPIC_DWD_TRAFFIC_PAGE = "dwd_traffic_page";
public static final String TOPIC_DWD_TRAFFIC_ACTION = "dwd_traffic_action";
public static final String TOPIC_DWD_TRAFFIC_DISPLAY = "dwd_traffic_display";
public static final String TOPIC_DWD_INTERACTION_COMMENT_INFO = "dwd_interaction_comment_info";
public static final String TOPIC_DWD_TRADE_CART_ADD = "dwd_trade_cart_add";
public static final String TOPIC_DWD_TRADE_ORDER_DETAIL = "dwd_trade_order_detail";
public static final String TOPIC_DWD_TRADE_ORDER_CANCEL = "dwd_trade_order_cancel";
public static final String TOPIC_DWD_TRADE_ORDER_PAYMENT_SUCCESS = "dwd_trade_order_payment_success";
public static final String TOPIC_DWD_TRADE_ORDER_REFUND = "dwd_trade_order_refund";
public static final String TOPIC_DWD_TRADE_REFUND_PAYMENT_SUCCESS = "dwd_trade_refund_payment_success";
public static final String TOPIC_DWD_USER_REGISTER = "dwd_user_register";
}4.2 编写FlinkSourceUtil工具类
Flink1.16开始,原先用于交互的FlinkKafkaConsumer、FlinkKafkaProducer被标记为过时,不推荐使用。为了提高模板代码的复用性,将KafkaSource的构建封装到FlinkSourceUtil工具类中。
public class FlinkSourceUtil {
public static KafkaSource<String> getKafkaSource(String groupId, String topicName) {
return KafkaSource.<String>builder()
.setBootstrapServers(Constant.KAFKA_BROKERS)
.setGroupId(groupId)
.setTopics(topicName)
.setStartingOffsets(OffsetsInitializer.latest())
.setValueOnlyDeserializer(new SimpleStringSchemaFix() {
}).build();
}
static class SimpleStringSchemaFix extends SimpleStringSchema {
@Override
public String deserialize(byte[] message) {
if (message != null) {
return new String(message, StandardCharsets.UTF_8);
}
return "";
}
}
}4.3 编写JdbcUtil工具类
在realtime-common工程添加pom依赖:
<dependency>
<groupId>commons-dbutils</groupId>
<artifactId>commons-dbutils</artifactId>
<version>1.8.1</version>
</dependency>在util包下面创建JdbcUtil工具类:
public class JdbcUtil {
static Logger logger = LoggerFactory.getLogger(JdbcUtil.class);
public static Connection getConnection(String jdbcUrl, String username, String password) throws SQLException {
// 不需要Class.forName("xxx"), DriverManager多年更新后已经支持自动加载驱动类
// 创建Connection实例
Connection connection = DriverManager.getConnection(jdbcUrl, username, password);
return connection;
}
public static <T> List<T> queryList(Connection conn, String querySql, Class<T> clazz, Object... params) throws SQLException {
// 创建QueryRunner实例
QueryRunner qr = new QueryRunner();
List<T> result = qr.execute(conn, querySql, new BeanHandler<>(clazz), params);
return result;
}
// 查询多行,指定列作为key,返回Map
public static <K, T> Map<K, T> queryBeanMap(Connection conn, String querySql, Class<T> clazz, Object... params) throws SQLException {
// 创建QueryRunner实例
QueryRunner qr = new QueryRunner();
Map<K, T> result = qr.query(conn, querySql, new BeanMapHandler<K, T>(clazz), params);
return result;
}
public static <T> List<Map<String, Object>> queryMapList(Connection conn, String querySql, Object... params) throws SQLException {
// 创建QueryRunner实例
QueryRunner qr = new QueryRunner();
List<Map<String, Object>> result = qr.query(conn, querySql, new MapListHandler(), params);
return result;
}
public static <T> T queryOne(Connection conn, String querySql, Class<T> clazz, Object... params) throws SQLException {
// 创建QueryRunner实例
QueryRunner qr = new QueryRunner();
T result = qr.query(conn, querySql, new BeanHandler<>(clazz), params);
return result;
}
// 查询一行单个字段,如count(*), max(id)等
public static <T> T queryOneSingleColumn(Connection conn, String querySql, int columnIndex, Object... params) throws SQLException {
// 创建QueryRunner实例
QueryRunner qr = new QueryRunner();
T result = qr.query(conn, querySql, new ScalarHandler<T>(columnIndex), params);
return result;
}
// 返回影响行数
public static int execute(Connection conn, String executeSql, Object... params) throws SQLException {
// 创建QueryRunner实例
QueryRunner qr = new QueryRunner();
int rowCount = qr.execute(conn, executeSql, params);
return rowCount;
}
public static void closeConnection(Connection conn) {
try {
if (conn != null && !conn.isClosed()) {
conn.close();
}
} catch (SQLException e) {
logger.error("mysql连接关闭失败", e);
throw new RuntimeException(e);
}
}
}使用的时候需要注意数据库字段是下划线_风格,而java中是使用驼峰命名,需要查询使用别名做字段映射。
5. 配置表
使用配置表实时调整在运行的Flink参数,使用Flink CDC动态捕获配置表变更。
5.1 配置表结构设计
我们将为维度分流准备配置表table_process_dim,为该表设计五个字段如下: (1)source_table:作为数据源的业务数据表名
(2)sink_table:作为数据目的地的HBase表名
(3)sink_family:作为数据目的地的HBase列族
(4)sink_columns:写入HBase的字段
(5)sink_row_key:写入HBase需要指定的row_key
将sink_table作为配置表的主键,可以通过它获取唯一的配置信息,明确维度分流的数据源及目的地等信息。
5.2 Mysql中创建数据库建表并开启Binlog
- 创建数据库gmall2023_config,注意和gmall业务库区分开
CREATE DATABASE gmall2023_config;- 执行建表语句以及数据导入SQL文件如下
DROP TABLE IF EXISTS `table_process_dim`;
CREATE TABLE `table_process_dim` (
`source_table` varchar(200) NOT NULL COMMENT '来源表',
`sink_table` varchar(200) NOT NULL COMMENT '输出表',
`sink_family` varchar(200) COMMENT '当输出类型是 dim 的时候,输出到 hbase 的列族',
`sink_columns` varchar(2000) COMMENT '输出字段',
`sink_row_key` varchar(200) COMMENT '当输出类型是dim时的rowkey',
PRIMARY KEY (`sink_table`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `table_process_dim`(`source_table`, `sink_table`, `sink_family`, `sink_columns`, `sink_row_key`) VALUES ('activity_info', 'dim_activity_info', 'info','id,activity_name,activity_type,activity_desc,start_time,end_time,create_time', 'id');
INSERT INTO `table_process_dim`(`source_table`, `sink_table`, `sink_family`, `sink_columns`, `sink_row_key`) VALUES ('activity_rule', 'dim_activity_rule', 'info','id,activity_id,activity_type,condition_amount,condition_num,benefit_amount,benefit_discount,benefit_level', 'id');
INSERT INTO `table_process_dim`(`source_table`, `sink_table`, `sink_family`, `sink_columns`, `sink_row_key`) VALUES ('activity_sku', 'dim_activity_sku', 'info','id,activity_id,sku_id,create_time', 'id');
INSERT INTO `table_process_dim`(`source_table`, `sink_table`, `sink_family`, `sink_columns`, `sink_row_key`) VALUES ('base_category1', 'dim_base_category1', 'info','id,name', 'id');
INSERT INTO `table_process_dim`(`source_table`, `sink_table`, `sink_family`, `sink_columns`, `sink_row_key`) VALUES ('base_category2', 'dim_base_category2', 'info','id,name,category1_id', 'id');
INSERT INTO `table_process_dim`(`source_table`, `sink_table`, `sink_family`, `sink_columns`, `sink_row_key`) VALUES ('base_category3', 'dim_base_category3', 'info','id,name,category2_id', 'id');
INSERT INTO `table_process_dim`(`source_table`, `sink_table`, `sink_family`, `sink_columns`, `sink_row_key`) VALUES ('base_province', 'dim_base_province', 'info','id,name,region_id,area_code,iso_code,iso_3166_2', 'id');
INSERT INTO `table_process_dim`(`source_table`, `sink_table`, `sink_family`, `sink_columns`, `sink_row_key`) VALUES ('base_region', 'dim_base_region', 'info','id,region_name', 'id');
INSERT INTO `table_process_dim`(`source_table`, `sink_table`, `sink_family`, `sink_columns`, `sink_row_key`) VALUES ('base_trademark', 'dim_base_trademark', 'info','id,tm_name', 'id');
INSERT INTO `table_process_dim`(`source_table`, `sink_table`, `sink_family`, `sink_columns`, `sink_row_key`) VALUES ('coupon_info', 'dim_coupon_info', 'info', 'id,coupon_name,coupon_type,condition_amount,condition_num,activity_id,benefit_amount,benefit_discount,create_time,range_type,limit_num,taken_count,start_time,end_time,operate_time,expire_time,range_desc', 'id');
INSERT INTO `table_process_dim`(`source_table`, `sink_table`, `sink_family`, `sink_columns`, `sink_row_key`) VALUES ('coupon_range', 'dim_coupon_range', 'info','id,coupon_id,range_type,range_id', 'id');
INSERT INTO `table_process_dim`(`source_table`, `sink_table`, `sink_family`, `sink_columns`, `sink_row_key`) VALUES ('financial_sku_cost', 'dim_financial_sku_cost', 'info','id,sku_id,sku_name,busi_date,is_lastest,sku_cost,create_time', 'id');
INSERT INTO `table_process_dim`(`source_table`, `sink_table`, `sink_family`, `sink_columns`, `sink_row_key`) VALUES ('sku_info', 'dim_sku_info', 'info','id,spu_id,price,sku_name,sku_desc,weight,tm_id,category3_id,sku_default_img,is_sale,create_time', 'id');
INSERT INTO `table_process_dim`(`source_table`, `sink_table`, `sink_family`, `sink_columns`, `sink_row_key`) VALUES ('spu_info', 'dim_spu_info', 'info','id,spu_name,description,category3_id,tm_id','id');
INSERT INTO `table_process_dim`(`source_table`, `sink_table`, `sink_family`, `sink_columns`, `sink_row_key`) VALUES ('user_info', 'dim_user_info', 'info','id,login_name,name,user_level,birthday,gender,create_time,operate_time', 'id');
INSERT INTO `table_process_dim`(`source_table`, `sink_table`, `sink_family`, `sink_columns`, `sink_row_key`) VALUES ('base_dic', 'dim_base_dic', 'info','dic_code,dic_name', 'dic_code');- MySQL配置文件中增加gmall2023_config开启Binlog
sudo vim /etc/my.cnf
## 增加对于gmall2023_config的监控
binlog-do-db=gmall2023_config- 重启MySQL服务
6. DIM层主要任务
6.1 接收Kafka数据,过滤空值数据
对Maxwell抓取的数据进行ETL,有用的部分保留,没用的过滤掉。
6.2 动态拆分维度表功能需求
实时数仓的维度表用于补充事实数据的维度信息(维度关联),事实数据是以流的形式存在的,如果维度信息也是这样,维度关联就要通过双流join来实现,而通常维度数据的生成时间可能远远早于事实数据,要保证二者可以正确关联,就要把维度流的数据缓存下来,设置一个极大的ttl,使其常驻内存。对于数据量比较小的维度而言,这样做没有什么问题,但如果是用户这样数据量在百G以上的维度,必然会带来极大的内存开销,不是一个很好的解决方案。
6.3 动态拆分维度表功能设计
通常,我们会将维度数据写入外部存储介质,通常是HBase,Redis或MySQL这样的K-V数据库,以便通过主键高效地获取维度信息。本项目选用Redis,主要是考虑到大数据场景下某些维度表数据量极大,MySQL可能扛不住这样的压力。HBase虽然支持海量数据的读写操作,可以托管数十亿行、数百万列的大表,并且支持随机查询,可以通过row_key快速定位目标数据,但是性能较慢。
所有维度都存在Kafka的topic_db主题,不同的维度表上下游、字段信息不同,可以把这些信息记录在配置文件中,在程序启动时加载,根据配置信息完成维度数据的处理。但需要解决一个非常严重的问题,程序启动后并不能动态感知配置变化,当业务端需求变化时必须重启计算程序读取更新后的配置文件,效率极低。此处需要一种动态配置方案,当配置变化时,流处理程序可以自动感知。此处提出三种动态配置方案:
- 用Zookeeper存储配置信息,通过Watch感知数据变化,结点数据变更,IDEA程序捕捉到了变更操作,将变更告知Flink应用。
- 用MySQL数据库存储,周期性同步:只需要在分流程序的指定位置写一个死循环,周期性拉取MySQL配置表的数据即可。
- 用MySQL数据库存储,通过FlinkCDC监控配置表数据变更。
第二种方案无法实时获知数据变更,配置信息的更新至多需要等待一个周期,为了提升时效性,周期应尽可能短,但周期越短,执行查询的频率越高,开销越大,并且周期再短都无法实现实时更新,必然存在延迟。
而第一种方案中Zookeeper是大数据生态中的协调者,一般不会用于存储数据,且Zookeeper的结点存储的是字符串,我们可以通过JSON数组存储配置信息,但是与第三种方案相比,对于用户而言,操作繁琐,且配置信息不够清晰。
第三种方案可以实现变更数据的实时监控,且配置信息存储在MySQL,符合开发习惯,易于维护,配置变更操作简便。
6.4 业务数据DIM层代码流程
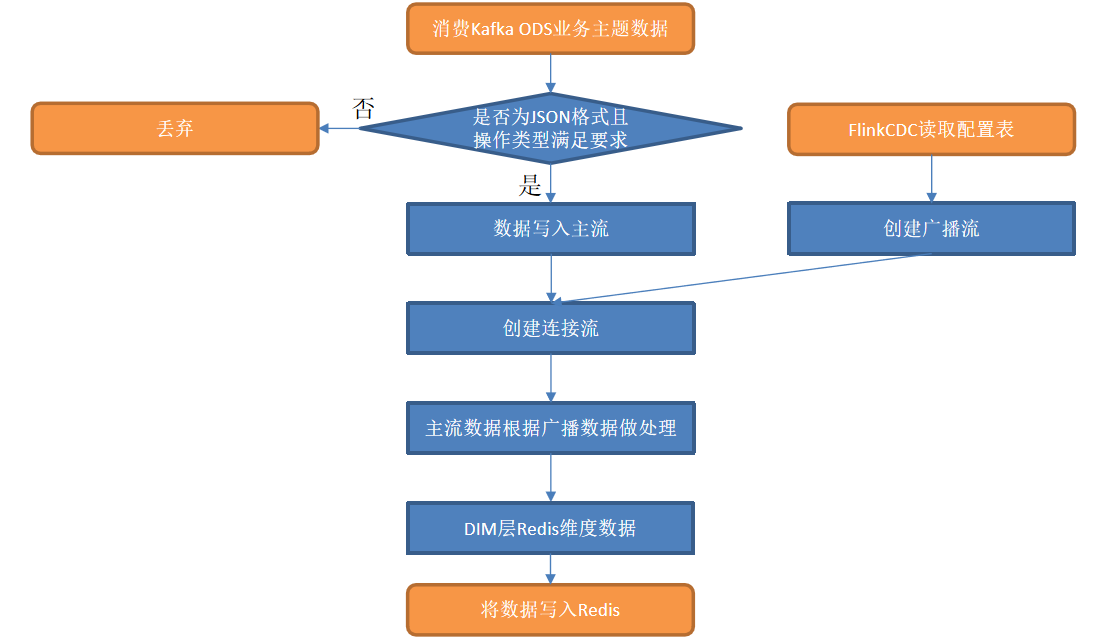 使用FLinkCDC进行捕获配置表信息,将配置流写入到数据同步的主流中,实现动态配置。
使用FLinkCDC进行捕获配置表信息,将配置流写入到数据同步的主流中,实现动态配置。
6.5 扩展FlinkSouceUtil
common模块引入依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
</dependency>添加cdc数据源:
// 获取cdc数据源
public static MySqlSource<String> getMysqlSource(String databaseName, String tableName) {
return MySqlSource.<String>builder()
.hostname(Constant.MYSQL_HOST)
.port(Constant.MYSQL_PORT)
.databaseList(databaseName)
// 需要读取的表
.tableList(databaseName+"."+tableName)
.username(Constant.MYSQL_USER_NAME)
.password(Constant.MYSQL_PASSWORD)
.deserializer(new JsonDebeziumDeserializationSchema())
// 从开始读取
.startupOptions(StartupOptions.initial())
.build();
}6.6 编写RedisUtil
- 添加依赖
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.45.1</version>
</dependency>- 编写RedisUtil
public class RedisUtil {
static RedissonClient client = null;
// 使用懒汉单例模式
public static void createConnection() {
synchronized (RedisUtil.class) {
if (client == null) {
Config config = new Config();
config.useSingleServer()
.setAddress(Constant.REDIS_LIST)
.setDatabase(0)
.setConnectionPoolSize(10)
.setConnectionMinimumIdleSize(5);
client = Redisson.create(config);
}
}
}
public static void dropTable(String namespace, String sinkTable) {
client.getMap(namespace).remove(sinkTable);
}
public static void createTable(String namespace, String sinkTable, String[] split) {
client.getMap(namespace).put(sinkTable, split);
}
}7. 代码实现
7.1 接收Kafka数据,过滤空值数据
common模块引入依赖:
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
</dependency>7.1 创建TableProcessDim类
在realtime-dim包下创建以下包结构: app包,function包, 在common模块的bean包下创建TableProcessDim实体类
public class TableProcessDim {
// 来源表名
String sourceTable;
// 目标表名
String sinkTable;
// 输出字段
String sinkColumns;
// 数据到 hbase 的列族
String sinkFamily;
// sink到 hbase 的时候的主键字段
String sinkRowKey;
// 配置表操作类型
String op;
......// getset方法省略7.2 编写DimApp类
public static void main(String[] args) throws Exception {
new DimApp().start(10001, "dim_app", Constant.TOPIC_DB);
}
@Override
public void handle(StreamExecutionEnvironment env, DataStreamSource<String> kafkaSource) {
// 核心业务逻辑,对数据进行处理
// 1.主流处理
SingleOutputStreamOperator<JSONObject> filterKafkaSource = etl(kafkaSource);
// 2. 使用flink cdc监控配置表信息
DataStreamSource<String> cdcStream = getConfigCDCStream(env);
// 3. 在Redis中同步维度表信息, 同时将cdc信息流 转换成 TableProcessDim流
SingleOutputStreamOperator<TableProcessDim> cdcTableStream = syncTableInfo(cdcStream).setParallelism(1);
// 4. 连接主流和广播流
SingleOutputStreamOperator<Tuple2<JSONObject, TableProcessDim>> dimStream =
processConnect(filterKafkaSource, cdcTableStream).setParallelism(1);
// 5. 筛选出需要写出的字段
// dimStream.print();
SingleOutputStreamOperator<Tuple2<JSONObject, TableProcessDim>> filterColumnStream = deleteNotNeedColumns(dimStream);
// 7. 写出到Redis
filterColumnStream.addSink(new RedisSinkFunction());
}
private SingleOutputStreamOperator<Tuple2<JSONObject, TableProcessDim>> deleteNotNeedColumns(SingleOutputStreamOperator<Tuple2<JSONObject, TableProcessDim>> dimStream) {
return dimStream.map(new MapFunction<Tuple2<JSONObject, TableProcessDim>, Tuple2<JSONObject, TableProcessDim>>() {
@Override
public Tuple2<JSONObject, TableProcessDim> map(Tuple2<JSONObject, TableProcessDim> dataWithConfig) throws Exception {
JSONObject jsonObj = dataWithConfig.f0;
TableProcessDim dim = dataWithConfig.f1;
List<String> columns = Arrays.asList(dim.getSinkColumns().split(","));
jsonObj.keySet().removeIf(key -> !columns.contains(key));
return dataWithConfig;
}
});
}
private SingleOutputStreamOperator<TableProcessDim> syncTableInfo(DataStreamSource<String> cdcSource) {
// 需要提前连接redis, 使用RichFlatMapFunction提供生命周期,也可以使用底层函数ProcessFunction
SingleOutputStreamOperator<TableProcessDim> tableStream = cdcSource.flatMap(new RichFlatMapFunction<String, TableProcessDim>() {
@Override
public void open(Configuration parameters) throws Exception {
// 创建redis连接
RedisUtil.createConnection();
}
@Override
public void flatMap(String value, Collector<TableProcessDim> out) throws Exception {
JSONObject jsonObject = JSON.parseObject(value);
String op = jsonObject.getString("op");
TableProcessDim tableProcessDim;
if ("d".equals(op)) { // 表示删除表
tableProcessDim = jsonObject.getObject("before", TableProcessDim.class, JSONReader.Feature.SupportSmartMatch);
RedisUtil.dropTable(Constant.REDIS_NAMESPACE, tableProcessDim.getSinkTable());
} else if ("c".equals(op) || "r".equals(op)) {
tableProcessDim = jsonObject.getObject("after", TableProcessDim.class, JSONReader.Feature.SupportSmartMatch);
String[] split = tableProcessDim.getSinkFamily().split(",");
RedisUtil.createTable(Constant.REDIS_NAMESPACE, tableProcessDim.getSinkTable(), split);
} else {
// 不是删除和创建,那就是更新表,需要先删除再创建
tableProcessDim = jsonObject.getObject("after", TableProcessDim.class, JSONReader.Feature.SupportSmartMatch);
RedisUtil.dropTable(Constant.REDIS_NAMESPACE, tableProcessDim.getSinkTable());
String[] split = tableProcessDim.getSinkFamily().split(",");
RedisUtil.createTable(Constant.REDIS_NAMESPACE, tableProcessDim.getSinkTable(), split);
}
tableProcessDim.setOp(op);
out.collect(tableProcessDim);
}
@Override
public void close() throws Exception {
// redis使用连接池,先不管
}
});
return tableStream;
}
private static SingleOutputStreamOperator<Tuple2<JSONObject, TableProcessDim>> processConnect(SingleOutputStreamOperator<JSONObject> filterKafkaSource, SingleOutputStreamOperator<TableProcessDim> cdcTableStream) {
// TableProcessDim流 转成 广播流
MapStateDescriptor<String, TableProcessDim> broadcastDimStateDescriptor = new MapStateDescriptor<>(
"broadcast_dim",
Types.STRING,
Types.POJO(TableProcessDim.class));
BroadcastStream<TableProcessDim> broadcastDimStream = cdcTableStream.broadcast(broadcastDimStateDescriptor);
SingleOutputStreamOperator<Tuple2<JSONObject, TableProcessDim>> dimTableSource = filterKafkaSource.connect(broadcastDimStream)
.process(new DimBroadcastFunction(broadcastDimStateDescriptor));
return dimTableSource;
}
private static DataStreamSource<String> getConfigCDCStream(StreamExecutionEnvironment env) {
// 获取mysqlSource
MySqlSource<String> mysqlSource = FlinkSourceUtil.getMysqlSource(Constant.MYSQL_PROCESS_DATABASE, Constant.MYSQL_PROCESS_TABLE);
// 设置并行度为1
DataStreamSource<String> cdcSource =
env.fromSource(mysqlSource, WatermarkStrategy.noWatermarks(), "cdc_source").setParallelism(1);
return cdcSource;
}
private static SingleOutputStreamOperator<JSONObject> etl(DataStreamSource<String> kafkaSource) {
// flatmap = filter(清洗)+map(转换)
return kafkaSource.flatMap(new FlatMapFunction<String, JSONObject>() {
@Override
public void flatMap(String value, Collector<JSONObject> out) {
try {
JSONObject jsonObject = JSON.parseObject(value);
String database = jsonObject.getString("database");
String type = jsonObject.getString("type");
JSONObject data = jsonObject.getJSONObject("data");
/**
* 处理数据, 只收集gmall_v4数据库的binlog信息
* 不关注bootstrap-start和bootstrap-complete
*/
if (Constant.MYSQL_BUSINESS_DATABASE.equals(database) && !StringUtils.equals("bootstrap-start", type)
&& !StringUtils.equals("bootstrap-complete", type)
&& data != null && data.size() != 0) {
out.collect(jsonObject);
}
} catch (Exception e) {
e.printStackTrace();
}
}
});
}7.3 编写相关函数类
public class DimBroadcastFunction extends BroadcastProcessFunction<JSONObject, TableProcessDim, Tuple2<JSONObject, TableProcessDim>> {
static Logger logger = LoggerFactory.getLogger("DimApp");
MapStateDescriptor<String, TableProcessDim> broadcastDimStateDescriptor;
public DimBroadcastFunction(MapStateDescriptor<String, TableProcessDim> broadcastDimStateDescriptor){
this.broadcastDimStateDescriptor = broadcastDimStateDescriptor;
}
// 为了避免map在多个flink中不一致,需要设置并行度为1
private Map<String, TableProcessDim> map;
// 用于完成配置信息的初始化操作
@Override
public void open(Configuration parameters) throws Exception {
// open 中没有办法访问状态!!!
// MapState<String, TableProcessDim> broadcastState = getRuntimeContext().getMapState(broadcastDimStateDescriptor);
Connection conn = JdbcUtil.getConnection(Constant.MYSQL_URL, Constant.MYSQL_USER_NAME, Constant.MYSQL_PASSWORD);
// 对配置表信息进行预加载
String sql = "SELECT source_table sourceTable, sink_table sinkTable, sink_family sinkFamily, " +
"sink_columns sinkColumns, sink_row_key sinkRowKey, 'r' op FROM gmall2023_config.table_process_dim;";
map = JdbcUtil.<String, TableProcessDim>queryBeanMap(conn, sql, TableProcessDim.class);
JdbcUtil.closeConnection(conn);
}
// 3. 处理数据流中的数据: 从广播状态中读取配置信息
@Override
public void processElement(JSONObject jsonObj, ReadOnlyContext ctx, Collector<Tuple2<JSONObject, TableProcessDim>> out) throws Exception {
// 读取广播状态
ReadOnlyBroadcastState<String, TableProcessDim> broadcastState = ctx.getBroadcastState(broadcastDimStateDescriptor);
// 查询广播状态
String key = jsonObj.getString("table");
TableProcessDim tableProcessDim = broadcastState.get(key);
if (tableProcessDim == null) { // 如果状态中没有查到, 则去 map 中查找
tableProcessDim = map.get(key);
if (tableProcessDim != null) {
logger.info("在 map 中查找到 " + key);
}
} else {
logger.info("在 状态 中查找到 " + key);
}
if (tableProcessDim != null) {
JSONObject data = jsonObj.getJSONObject("data");
data.put("op_type", jsonObj.getString("type"));
out.collect(Tuple2.of(jsonObj, tableProcessDim));
}
}
// 将配置表信息作为一个维度表标记, 写到广播状态
@Override
public void processBroadcastElement(TableProcessDim value, Context ctx, Collector<Tuple2<JSONObject, TableProcessDim>> out) throws Exception {
//保持最新广播状态
BroadcastState<String, TableProcessDim> broadcastState = ctx.getBroadcastState(broadcastDimStateDescriptor);
String key = value.getSourceTable();
if ("d".equals(value.getOp())) {
map.remove(key);
broadcastState.remove(key);
} else {
// 更新或者添加状态
broadcastState.put(key, value);
}
}
}public class RedisSinkFunction extends RichSinkFunction<Tuple2<JSONObject, TableProcessDim>> {
@Override
public void open(OpenContext openContext) throws Exception {
RedisUtil.createConnection();
}
@Override
public void invoke(Tuple2<JSONObject, TableProcessDim> value, Context context) throws Exception {
JSONObject jsonObj = value.f0;
TableProcessDim tableProcessDim = value.f1;
// insert update delete bootstrap-insert
String type = jsonObj.getString("type");
JSONObject data = jsonObj.getJSONObject("data");
String sinkRowKey = tableProcessDim.getSinkRowKey();
String sinkTable = tableProcessDim.getSinkTable();
if("delete".equals(type)){
RedisUtil.deleteTableData(sinkTable, sinkRowKey, data);
}else{
RedisUtil.saveTableData(sinkTable, sinkRowKey, data);
}
}
}