# 函数式编程之高阶
1. 函数高级
所谓的高阶函数,其实就是将函数当成一个类型来使用,而不是当成特定的语法结构。
1.1 函数作为值
函数可以作为值进行传递。
def test(): Unit = {
println("test....")
}
def test1(age: Int): String = {
println("test1....")
"hehe"
}
// 如果不想执行函数,而是访问函数本身,在被调用函数后面加上 _,相当于把函数当成一个整体
test()
println(test _)
// 函数其实就是对象,对象应该有类型的, 函数对象的类型称为函数类型
// 类型中的0 表示函数参数列表中参数的个数
// 括号中的Unit表示函数没有返回值
val f1: Function0[Unit] = test _
// 括号中的Int表示函数参数的类型
val f2: Function1[Int, Unit] = test1 _
println(f1)
println(f2)
// 函数对象的参数最多有22个,需要区分函数参数是没有限制的
// 为了使用方便,函数类型可以使用另外一种声明方式
// 这里的f3类型为: Int => String
// 如果将一个函数赋值给变量,那么这个变量就是函数,是函数就可以调用
val f3 = test1 _
f3(123)下划线的作用
- import作用
import xxx.yyy._ - 可以声明变量
val _ = "张三" - 可以将函数作为对象作用
val obj = fun _ - 如果匿名函数的参数按照顺序只使用一次,那么采用下划线代替参数
1.2 函数作为参数
def fun(): Unit = {
println("fun...")
}
// 将函数作为参数使用
def test2(f: () => Unit): Unit = {
f()
}
test2(fun)
// 将函数作为参数,常用于提前将使用规则定义好,但是计算逻辑不确定的时候。
def test3(f: (Int, Int) => Int): Unit = {
var result = f(10, 20)
println(result)
}
// 函数作为参数将计算逻辑传递进去,也就可以不用将计算逻辑写死了
// 逻辑1 符合使用规则
def sum(a: Int, b: Int): Int = {
a + b
}
// 逻辑2 符合使用规则
def multiply(a: Int, b: Int): Int = {
a * b
}
// 使用逻辑1
test3(sum _) // 如果能够推断出来不是调用,函数对象作为参数可以省略 _
test3(sum)
// 使用逻辑2
test3(multiply)
// 可以传递匿名函数, 常用来作为参数使用
test3(
(x: Int, y: Int) => {
x + y
}
)1.3 函数作为返回值
def main(args: Array[String]): Unit = {
// Scala也可以将函数对象作为返回结果返回,函数的返回值一般不声明的,使用自动推断
def outer() = {
def inner(): Unit = {
println("inner....")
}
inner _
}
// 此时f就是一个函数对象,有函数类型()=>Unit
val f = outer()
// 执行函数对象
f()
def outer2(x: Int) = {
def mid(f: (Int, Int) => Int) = {
def inner2(y: Int) = {
f(x, y)
}
inner2 _
}
mid _
}
val result: Int = outer2(10)(_ + _)(20)
println(result)
}1.4 匿名函数
没有名字的函数就是匿名函数。
(x:Int)=>{函数体}x:表示输入参数类型;Int:表示输入参数类型;函数体:表示具体代码逻辑。
传递匿名函数至简原则:
- 参数的类型可以省略,会根据形参进行自动的推导
- 类型省略之后,发现只有一个参数,则圆括号可以省略;其他情况:没有参数和参数超过1的永远不能省略圆括号。
- 匿名函数如果只有一行,则大括号也可以省略。
- 如果参数只出现一次,则参数省略且后面参数可以用_代替。
// 匿名函数支持至简原则
// 1. 匿名函数如果只有一行,那么大括号可以省略
test3(
(x: Int, y: Int) => x + y
)
// 2. 匿名函数的参数类型如果可以推断出来, 那么参数类型可以省略
test3(
(x, y) => x + y
)
// 3. 匿名函数如果参数列表的个数只有一个,那么小括号可以省略
// 4. 匿名函数如果按照参数顺序只执行一次,那么可以使用下划线来代替参数,并省略参数列表和=>
test3(
_ + _
)
test3(
(x, y) => x + x // 这不符合只执行一次,不能使用_精简
)
def test4(f: (String) => Unit): Unit = {
f("jack")
}
// _下划线不能嵌套使用
test4(println(_)) // 正确
// test4(println(_ + "jack")) // println函数内部"_"参与了运算, 不算直接使用,报错2. 闭包&函数柯里化
2.1 闭包
闭包:如果一个函数,使用到了它的外部变量,那么这个函数和他所处的环境,称为闭包。
def main(args: Array[String]): Unit = {
def outer(x: Int) = {
def inner(y: Int): Int = {
x + y
}
inner _
}
println(outer(10)(20))
}inner函数的函数体中需要用到x值,但是outer已经出栈, x随之就会销毁,x在inner函数中就看不见了,这就产生问题,如图所示: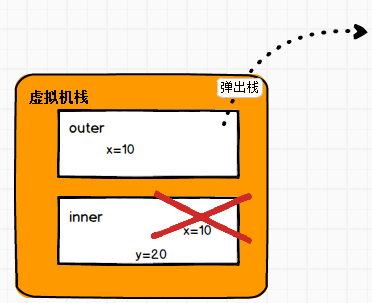 但是运行没有报错,结果为:
但是运行没有报错,结果为: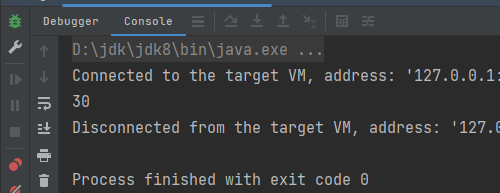
分析原因,查看反编译字节码文件,可以发现没有报错的原因: 其实变量x并没有释放,而是包含在了声明inner函数的内部,形成了闭合的效果。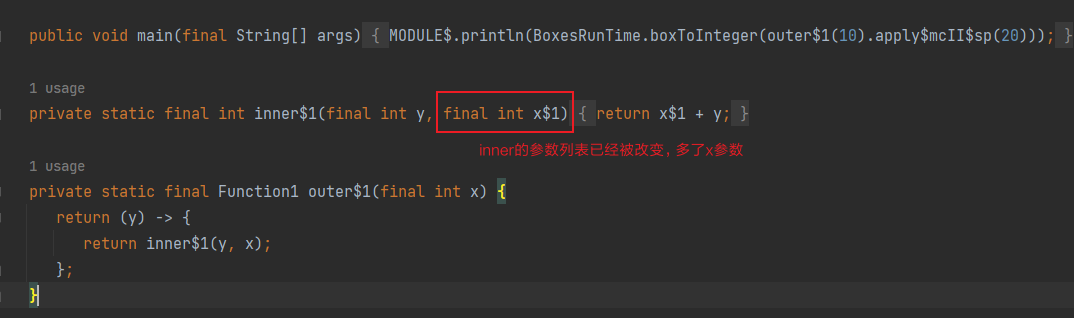
提示
Scala不同版本实现闭包的不一样:
在Scala2.12之前的版本,闭包使用的是匿名函数类实现。
在Scala2.12之后的版本,闭包使用的是改变函数的声明来实现。
闭包的场景:
- 内部函数使用了外部的数据,改变了数据的生命周期。
- 将函数作为对象使用,改变函数本身的生命周期。
- 所有匿名函数都有闭包。
- 内部函数返回到外部使用也会有闭包。
2.2 函数柯里化
函数柯里化:把一个参数列表的多个参数,变成多个参数列表。函数柯里化一定存在闭包。
def test(a: Int, b: Int): Unit = {
for (i <- 1 to a) {
println(s"${i}")
}
for (i <- 1 to b) {
println(s"${i}")
}
}
// test(3, 10)
// 如果函数的参数之间没有关系,那么如果在传值的时候,同时传递,其实就有耦合性,而且增加了调用难度:
// 比如a参数耗时10S, b参数耗时5分钟
// 因而有了函数柯里化, 就是为了将函数简单化,将无关的参数进行分离,可以设定多个参数列表
// 将test函数改造成柯里化
def test1(a: Int)(b: Int): Unit = {
for (i <- 1 to a) {
println(s"a: ${i}")
}
for (i <- 1 to b) {
println(s"b: ${i}")
}
}
// 只传递函数的一部分参数来调用它,让它返回一个函数去处理剩下的参数。
val f: Int => Unit = test1(5)
// 直到传递处理所有的参数为止。
test1(10)(30)3. 控制抽象
抽象意为不完整,比如抽象类:不完整的类;抽象方法:不完整的方法。函数的类型只有返回,没有输入的情况称之为抽象,因为不完整。
def test(f: () => Unit): Unit = {
f()
}
def test1(f: => Unit): Unit = {
// 需要注意的是,调用的时候不能加上小括号,f()
f
}
// 完整的参数传递,是将函数对象作为参数进行传递
test(
()=>{
println("hehe")
}
)
// 所谓控制抽象,就是将代码作为参数进行传递
test1(
println("hehe")
)
// 控制参数的应用场景: 自定义语法时,可以采用控制抽象,因为代码是可以传递的,也就意味着逻辑是变化的
// 比如循环的中断代码体现了控制抽象
breakable(
for (i <- 1 to 5) {
if (i == 3) {
break // 无参函数的调用可以去掉括号
}
println(s"打印${i}")
}
)查看breakable的源代码可以看出,它是控制抽象的代码: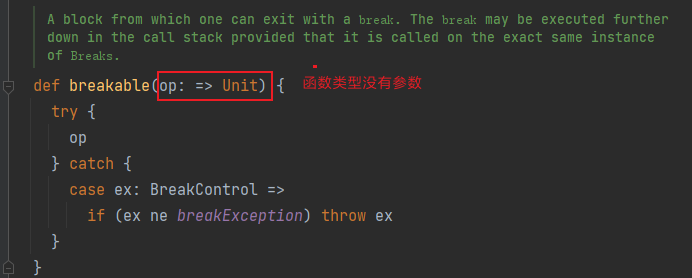
在breakable里面将逻辑代码作为参数传入到try-catch中,实现了自定义语法的效果。另外函数的参数如果跨域多行,那么可以将()换成{}, 如下:
breakable{
for (i <- 1 to 5) {
if (i == 3) {
break // 无参函数的调用可以去掉括号
}
println(s"打印${i}")
}
}4. 递归函数
一个函数/方法在函数/方法体内又调用了本身,我们称之为递归调用。
// 阶乘: 使用递归算法实现
// 1) 方法调用自身
// 2) 方法必须要有跳出的逻辑
// 3) 方法调用自身时,传递的参数应该有规律
// 4) scala 中的递归必须声明函数返回值类型,不能省略
def test(num:Int):Int={
if(num<=1){
1
}else{
num*test(num-1)
}
}
println(test(3)) Java的栈内存有大小限制,方法执行时,压栈的内存也是有大小的,那么栈内存不可能无限压栈, 如果压栈的次数超过阈值,就会出现错误,即使有跳出的逻辑也会出错,Scala采用了一种特殊的语法优化递归操作: 尾(伪)递归。比如下代码,并不会堆栈溢出:
Java的栈内存有大小限制,方法执行时,压栈的内存也是有大小的,那么栈内存不可能无限压栈, 如果压栈的次数超过阈值,就会出现错误,即使有跳出的逻辑也会出错,Scala采用了一种特殊的语法优化递归操作: 尾(伪)递归。比如下代码,并不会堆栈溢出:
// 原因是Scala使用while循环实现尾递归,但是Java中没有尾递归的优化。
def test1():Unit={
println("test1.....")
test1()
}
test1()区分堆栈溢出和堆内存溢出
栈内存可以有多个,每个线程就有一个独立栈内存,意味着线程越多,栈内存就越多,没有足够的内存分配栈空间就会发生栈内存溢出, 也就是OutOfMemoryError。而栈溢出指的是StackOverflowError, 一个虚拟机栈中堆栈数量是固定的,如果堆栈数量太多超过阈值,就会报错栈溢出。
5. 惰性函数
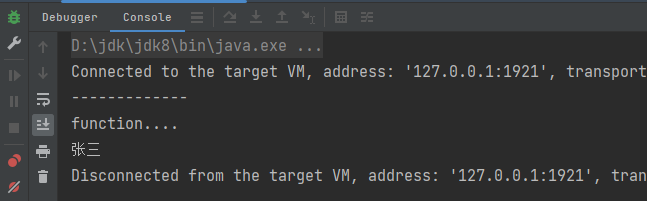
当函数返回值被声明为lazy时,函数的执行将被推迟,直到我们首次对此取值,该函数才会执行。这种函数我们称之为惰性函数。
def fun(): String = {
println("function....")
"张三"
}
lazy val a = fun()
println("-------------")
println(a)运行结果: