集合常用函数
1. 基本属性和常用操作
def main(args: Array[String]): Unit = {
val list: List[Int] = List(1, 2, 3, 4)
// 获取集合长度
println(list.length)
// 获取集合大小,等同于length
println(list.size)
// 是否包含
println(list.contains(3))
println("==========================")
// 循环遍历
list.foreach(println)
println("==========================")
for (elem <- list.iterator) {
println(elem)
}
// 生成字符串
println(list.mkString(","))
}运行结果: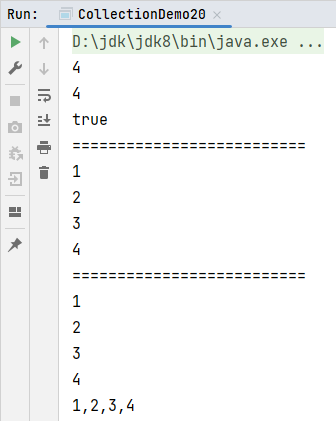
2. 衍生集合
所谓衍生集合就是从一个集合中获取部分集合元素
def main(args: Array[String]): Unit = {
val list1: List[Int] = List(1, 2, 3, 4, 4, 5, 6)
val list2: List[Int] = List(4, 5, 6, 4, 7, 8, 9)
val set1: Set[Int] = Set(1, 2, 3, 4, 4, 5, 6)
val set2: Set[Int] = Set(4, 5, 6, 4, 7, 8, 9)
// 获取集合的头
println(s"list的头元素: ${list1.head}")
println(s"set的头元素: ${set1.head}")
// 判断集合是否为空
println(s"集合判空:${list1.isEmpty}")
println(s"集合判空:${set1.isEmpty}")
// 集合去重, set没有去重方法
println(s"list去重:${list1.distinct}")
// 获取集合的尾(不是头的就是尾)
println(s"获取集合的尾:${list1.tail}")
println(s"获取集合的尾:${set1.tail}")
// 获取集合的所有尾的迭代
list1.tails.foreach(item => println(s"获取集合的所有尾: $item"))
set1.tails.foreach(item => println(s"获取集合的所有尾: $item"))
// 集合最后一个数据
println(s"获取最后一个: ${list1.last}")
println(s"获取最后一个: ${set1.last}")
// 集合初始数据(获取除了最后一个所有的)
println(s"获取除了最后一个所有的: ${list1.init}")
println(s"获取除了最后一个所有的: ${set1.init}")
// 获取集合的所有初始值迭代
list1.inits.foreach(item => println(s"获取集合的所有初始值: $item"))
set1.inits.foreach(item => println(s"获取集合的所有初始值: $item"))
// 反转, set集合不支持倒序
println(s"倒序:${list1.reverse}")
// 取前(后)n 个元素
println(list1.take(3))
println(set1.take(3))
// 从后取n个元素
println(s"从右边取多个元素:${list1.takeRight(3)}")
println(s"从右边取多个元素:${set1.takeRight(3)}")
// 去掉前(后)n 个元素
println(s"删除指定个数元素后: ${list1.drop(1)}")
println(s"删除指定个数元素后: ${set1.drop(1)}")
// 去掉前(后)n 个元素
println(s"删除末尾指定个数元素后: ${list1.dropRight(2)}")
println(s"删除末尾指定个数元素后: ${set1.dropRight(2)}")
// 分割集合
val tuple: (List[Int], List[Int]) = list2.splitAt(2)
println(s"分割集合的第一个部分: ${tuple._1}")
println(s"分割集合的第二个部分: ${tuple._2}")
// 滑窗, 就像推拉门窗一样效果,外面的人只能看到窗口滑动露出的事务
println(list1.sliding(2).mkString(","))
println(set1.sliding(2).mkString(","))
println("--------------------------------")
}运行结果:
3. 集合之间运算
def main(args: Array[String]): Unit = {
val list1: List[Int] = List(1, 2, 3, 4, 4, 5, 6)
val list2: List[Int] = List(4, 5, 6, 4, 7, 8, 9)
val set1: Set[Int] = Set(1, 2, 3, 4, 4, 5, 6)
val set2: Set[Int] = Set(4, 5, 6, 4, 7, 8, 9)
// 并集
println(s"并集: ${list1.union(list2)}")
println(s"并集: ${set1.union(set2)}")
// 交集
println(s"交集: ${list1.intersect(list2)}")
// 如果是set会自动将新集合去重
println(s"交集: ${set1.intersect(set2)}")
// 差集, 左边的集合为主,返回左边剩下的集合
println(s"差集: ${list1.diff(list2)}")
println(s"差集: ${set1.diff(set2)}")
// 拉链, 注:如果两个集合的元素个数不相等,那么会以长度少的那个集合为主进行拉链,
// 多余的数据省略不用
println(s"拉链: ${list1.zip(list2)}")
println(s"拉链: ${set1.zip(set2)}")
// 按照索引拉链
val list3 = List("a", "b", "c", "d")
println(list3.zipWithIndex)
}运行结果:
4. 集合计算简单函数
def main(args: Array[String]): Unit = {
val list1: List[Int] = List(1, 2, 3, 4, 4, 5, 6)
val list2: List[Int] = List(4, 5, 6, 4, 7, 8, 9)
val set1: Set[Int] = Set(1, 2, 3, 4, 4, 5, 6)
val set2: Set[Int] = Set(4, 5, 6, 4, 7, 8, 9)
// 求和
println(list1.sum)
// 求乘积
println(list1.product)
// 最大值
println(list1.max)
// 最小值
println(list1.min)
}运行结果: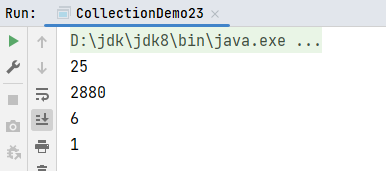
5. 集合计算高级函数
也称为功能函数,它们用来实现特定的功能,但是功能的逻辑不确定。Scala提供了可以进行自动转换的操作,具体的转换逻辑由开发人员提供。
5.1 转化/映射(map)
将集合中的每一条数据按照指定的逻辑进行转换,并放入新的集合
def main(args: Array[String]): Unit = {
val list1: List[Int] = List(1, 2, 3, 4, 4, 5, 6)
// 实现集合中的元素增长到原来的3倍
// 如果匿名函数只有一个参数并且只会被使用一次,可以使用下划线代替该参数
println(list1.map(_ * 3))
}运行结果: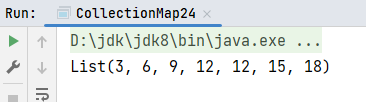
5.2 扁平化(flatMap)
将数据拆分成个体来使用,按照特定的逻辑处理。也就是将里面当个元素拆分为1=>N, 转换成的类型为GenTraversableOnce,GenTraversableOnce为集合类型的顶层通用类,也就是说集合类型都可以参与进来进行使用。
def main(args: Array[String]): Unit = {
val list1 = List(List(1, 2, 3), List(4, 4, 5, 6))
// 扁平化操作
val list2 = list1.flatten
println(list2)
val set1 = Set("Hello Scala", "Use BigData")
// flatten使用默认规则会将每个数据进行扁平化,字符串的扁平化是将字符串拆分成char数组
// val set2 = set1.flatten
// println(set2) 如果需要拆分成单词,就不能使用默认的拆分规则
// 自定义规则扁平化: flatMap, 传入一个功能函数
println(set1.flatMap(_.split(" ")))
}运行结果: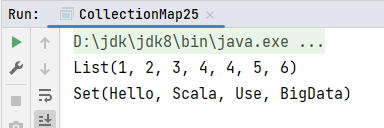
5.3 过滤(filter)
遍历一个集合并从中获取满足指定条件的元素组成一个新的集合, 其中传入的规则成立也就是true,数据被保留,否则false, 数据被筛选过滤掉。
def main(args: Array[String]): Unit = {
val list1 = List(1,2,3,4,5,6,7,8)
// 获取奇数集合
println(list1.filter(_ % 2 == 1))
}运行结果: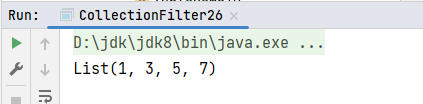
5.4 分组(groupBy)
按照指定的规则对集合的元素进行分组, 最终结果为一个Map,数据分组需要进行标记,执行分组会将相同标记的数据放置在一起,但是标记的类型不固定, 其中标记实际上就是Map的Key,Value就是相同标记的数据集合。
def main(args: Array[String]): Unit = {
val list1 = List(1,2,3,4,5,6,7,8)
// 按照奇偶分组
val map1 = list1.groupBy(item => {
if (item % 2 == 0) {
"偶数"
} else {
"奇数"
}
})
println(map1)
// 标记可以任意灵活,可以简化分组:
val map2 = list1.groupBy(item => {
item % 2 == 0
})
println(map2)
// 还可以再次简化
val map3 = list1.groupBy(_ % 2)
println(map3)
}运行结果: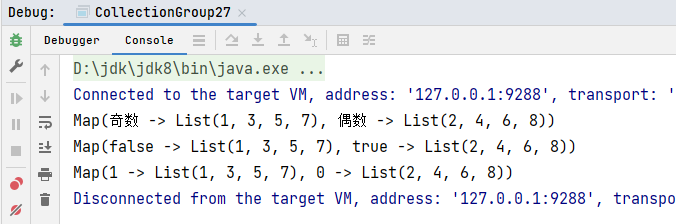
5.5 mapValues
当KV类型得数据在转换时,如果K不变,只是对V进行转换操作,可以采用新得功能函数:mapValues
def main(args: Array[String]): Unit = {
val map1 = Map("a" -> 1, "b" -> 2, "c" -> 3)
// 如果得到(a,2)(b,4)(c,6)
// 使用map方法繁琐一些
println(map1.map(item => (item._1, item._2 * 2)))
// 使用mapValues, 目的更加明确,只操作value
println(map1.mapValues(_ * 2))
}运行结果: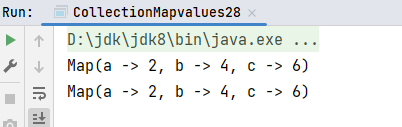
5.6 排序
对一个集合进行排序,Scala提供了sorted、sortBy、sortWith排序方法。
- sorted
对一个集合进行自然排序,通过传递隐式的Ordering
def main(args: Array[String]): Unit = {
val list1: List[Int] = List(3, 5, 2, 4, 9, 1)
val list2: List[String] = List("3", "5", "32", "4", "49", "1")
// 自然排序,默认升序
println(list1.sorted)
// 字符串类型和数字类型不同,数字类型按照大小排序,字符串按照字典排序
println(list2.sorted)
// sorted存在函数柯里化,可以传递多个参数列表
// 指定为倒序
println(list1.sorted(Ordering.Int.reverse))
}运行结果: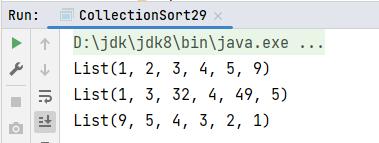 2. sortBy
2. sortBy
通过指定的类型进行排序,相比sorted更加灵活,可以支持元素的具体单个属性和多个属性挨个排序。
def main(args: Array[String]): Unit = {
val list1: List[Int] = List(3, 5, 2, 4, 9, 1)
val list2: List[String] = List("3", "5", "32", "4", "49", "1")
// 使用字典规则排序
println(s"按照字典排序:${list1.sortBy(it=>it.toString)}")
// 字符串集合,使用数字规则排序
println(s"按照数字排序:${list2.sortBy(it=>it.head.toLong)}")
// 指定为倒序
println(s"倒序:${list1.sorted(Ordering.Int.reverse)}")
val user1 = new User()
val user2 = new User()
val user3 = new User()
user1.age = 22
user1.name = "yuanyuan"
user2.age = 13
user2.name = "jack"
user3.age = 34
user3.name = "maomao"
val list3: List[User] = List(user1, user2, user3)
// 指定按照年龄属性排序
val sortedList1: List[User] = list3.sortBy(_.age)
println(s"按照年龄排序:${sortedList1}")
}
class User {
var name: String = _
var age: Int = _
var salary: Double = _
override def toString:String = {
s"User$age"
}
}运行结果: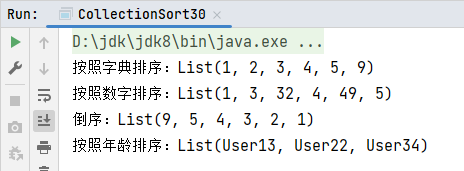 3. sortWith
3. sortWith
也是基于函数的排序,通过一个comparator函数,实现自定义排序的逻辑。用于比较复杂的排序,比如多个属性同时排序。内部排序结果通过布尔值进行判断,传入两个集合元素到自定义匿名函数中。
def main(args: Array[String]): Unit = {
val user1 = new User()
val user2 = new User()
val user3 = new User()
val user4 = new User()
user1.age = 22
user1.salary = 3000
user2.age = 23
user2.salary = 4900
user3.age = 34
user3.salary = 2300
user4.age = 23
user4.salary = 4300
val list3: List[User] = List(user1, user2, user3, user4)
// 和sortBy一样,也支持相同功能
val sortedList1: List[User] = list3.sortWith((u1, u2) => {
// 升序: 可以理解为从小到大就是用小于
u1.age < u2.age
})
println(sortedList1)
// 按照年龄升序排序,如果年龄相同按照薪水升序排序
// 你会发现sortBy不能实现这样的效果,因为两个排序各自执行
println(s"sortBy: ${list3.sortBy(_.age).sortBy(_.salary)}")
val sortedList2 = list3.sortWith((u1, u2) => {
if(u1.age == u2.age){
u1.salary < u2.salary
}else{
u1.age < u2.age
}
})
println(s"sortWith: ${sortedList2}")
// 如果有多个属性需要排序,比如按照第一个属性升序,如果相同按照第二个属性降序,如果第二个属性相同按照第三个属性排序。。。。
// 可以使用特殊的方式排序: tuple排序
val userList: List[User] = list3.sortBy(user => {
// 默认都是升序
(user.age, user.salary)
})(Ordering.Tuple2(Ordering.Int, Ordering.Double.reverse))
println(userList)
}
class User {
var name: String = _
var age: Int = _
var salary: Double = _
override def toString:String = {
s"User$age: $salary"
}
}运行结果: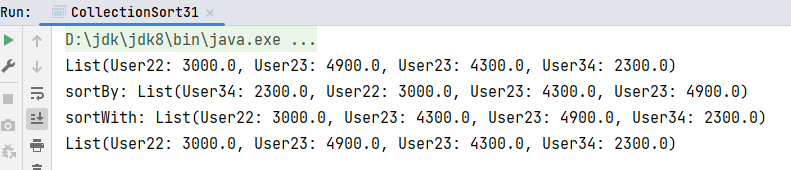
5.7 reduce
reduce可以实现自定义聚合计算,reduce里面需要传递一个参数,参数类型为函数类型:(A1, A1)=>A1, 这里的A1为两两计算时的数据类型,且和数据结果的类型保持一致,计算结果将作为下一次计算的第一个A1传入进来。
def main(args: Array[String]): Unit = {
val list1: List[Int] = List(1, 2, 3, 4)
// 集合的求和
val result1: Int = list1.reduce(
(x, y) => {
// 第一次计算时,x表示集合第一个数,y表示集合第二个数
// 第二次迭代计算时候,x表示上一次计算结果,y表示集合第三个数
println(s"x: $x + y: $y")
x + y
}
)
println(result1)
// 计算简化写法:
println(list1.reduce(_ + _))
}运行结果: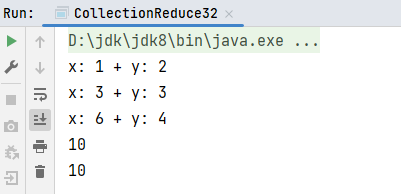
- reduceLeft
reduce底层就是reduceLeft, 从左边依次两两计算
def main(args: Array[String]): Unit = {
val list1: List[Int] = List(1, 2, 3, 4, 5)
// 集合的求差
// 计算集合所有元素从左到右的差
println(s"reduceLeft: ${list1.reduceLeft(_ - _)}")
}运行结果: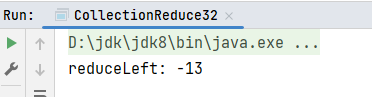 2. reduceRight
2. reduceRight
reduceRight表示从右边开始,但和reduceLeft的区别还在于传入计算规则的参数, 和实际运算的参数顺序是颠倒的,查看源码:
override /*IterableLike*/
def reduceRight[B >: A](op: (A, B) => B): B =
if (isEmpty) throw new UnsupportedOperationException("Nil.reduceRight")
else if (tail.isEmpty) head
else op(head, tail.reduceRight(op))计算集合的差:
def main(args: Array[String]): Unit = {
val list1: List[Int] = List(1, 2, 3, 4, 5)
// 集合的求差
// reduceRight表示从右边开始
val result: Int = list1.reduceRight(
(x, y) => {
// 从右边开始,第一个元素和第二个元素作计算,规则函数内部颠倒顺序,
// x为第二个元素,y为第一个元素
println(s"x: $x, y: $y")
x - y
}
)
// 计算逻辑为: 1 - (2 - (3 - (4 - 5)))
println(s"reduceRight: $result")
// 可以简化为
println(s"reduceRight: ${list1.reduceRight(_ - _)}")
}运行结果: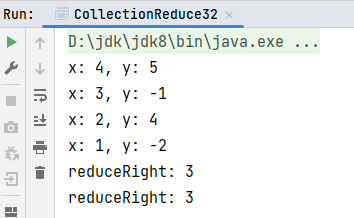
如何区分reduceLeft和reduceRight呢?
可以通过加括号的方式:
- reduceLeft: 从左边加括号,比如 (((1 - 2) - 3) - 4) - 5
- reduceRight: 从右边加括号,比如 1 - (2 - (3 - (4 - 5)))
5.8 折叠(fold)
在某些情况下,需要将外部数据和集合数据进行聚合,这时reduce无法使用,可以使用fold, fold的聚合原则还是两两聚合,它的参数列表支持柯里化,传入两个参数列表,第一个为函数初始值,第二个参数列表为集合两个元素,其中第一个参数列表的参数类型和最终计算结果类型保持一致。
def main(args: Array[String]): Unit = {
val list1: List[Int] = List(1, 2, 3, 4, 5, 6)
// 求和运算
val result1: Int = list1.fold(10)(_ + _)
println(result1)
}运行结果: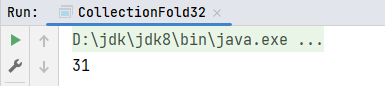
- foldLeft
def main(args: Array[String]): Unit = {
val list1: List[Int] = List(1, 2, 3, 4, 5, 6)
// 求和运算
// fold底层就是foldLeft
val result1: Int = list1.foldLeft(10)(_ + _)
println(result1)
// 计算过程: ((((((10 - 1) - 2) - 3) - 4) - 5) - 6)
val result2: Int = list1.foldLeft(10)(_ - _)
println(result2)
}运行结果: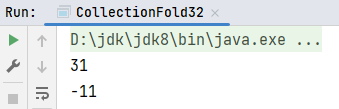 2. foldRight
2. foldRight
如图是foldRight的源码:
def main(args: Array[String]): Unit = {
val list1: List[Int] = List(1, 2, 3, 4, 5, 6)
// 求和运算
// foldRight计算: 将初始值放置在集合的右边,开始从右边加括号
// (1 - (2 - (3 - (4 - (5 - (6 - 10))))))
val result1: Int = list1.foldRight(10)(_ - _)
println(result1)
}运行结果: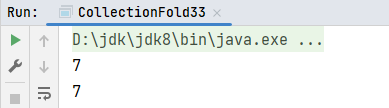
6. 代码实操
读取文件实现wordcount功能。
6.1 创建工程scala-demo
pom.xml配置如下:
详细信息
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>scala-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<name>scala-demo</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<java.version>1.8</java.version>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<maven.compiler.compilerVersion>1.8</maven.compiler.compilerVersion>
<scala.version>2.12.19</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.4.6</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>6.2 创建data.txt文件
如图所示,在resource目录下创建data.txt文件: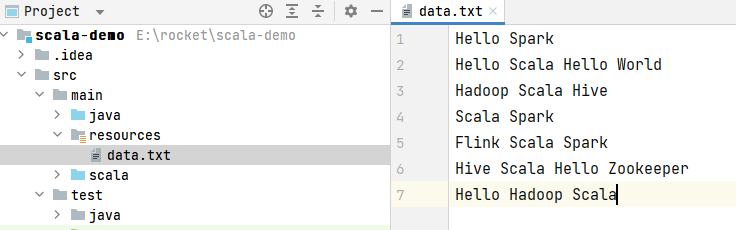
6.3 代码实现
def main(args: Array[String]): Unit = {
// 读取文件
val source: BufferedSource = Source.fromResource("data.txt")
val lineList: List[String] = source.getLines().toList
// 获取文件内容后可以提前关闭文件流
source.close()
// 扁平化,获取所有的单词集合
val wordList: List[String] = lineList.flatMap(_.split(" "))
// 按照元素分组
val functionToMap = wordList.groupBy(item=>item)
// 单独操作value, 将value进行map操作,变成集合大小
val stringToInt: Map[String, Int] = functionToMap.mapValues(item => item.size)
// 获取前三名
val tuples: List[(String, Int)] = stringToInt.toList.sortBy(item => item._2)(Ordering.Int.reverse).take(3)
// 输出结果
println(tuples)
}运行结果: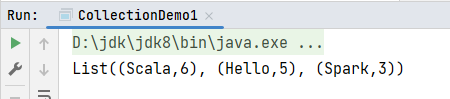 代码看起来有点乱,Scala函数主要用来迭代计算的,所谓迭代就是上一个计算的结果作为下一个计算的输入,所谓流式计算优化如下:
代码看起来有点乱,Scala函数主要用来迭代计算的,所谓迭代就是上一个计算的结果作为下一个计算的输入,所谓流式计算优化如下:
def main(args: Array[String]): Unit = {
// 读取文件
val source: BufferedSource = Source.fromResource("data.txt")
val lineList: List[String] = source.getLines().toList
source.close()
lineList
.flatMap(_.split(" "))
// 在Scala中,identity是一个函数,它表示接受一个参数并返回该参数本身。
.groupBy(identity)
.mapValues(_.size)
.toList.sortBy(_._2)(Ordering.Int.reverse).take(3)
.foreach(println)
}运行结果: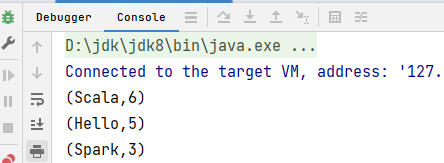
总结
集合不可能将所有的计算全部都封装,所以有些计算需要我们自己指定,然后由集合帮助我们执行。计算过程中,必须是两两计算,两两计算完毕后,继续执行两两计算,进行迭代操作。
迭代计算的过程就是将计算逻辑作为参数,传递给集合,由集合完成计算