与FlinkSQL集成
Apache Iceberg同时支持Apache Flink的DataStream API和Table API。
1. 环境准备
1.1 下载iceberg包
访问https://repo1.maven.org/maven2/org/apache/iceberg/, 下载对应Flink版本的iceberg运行jar包: 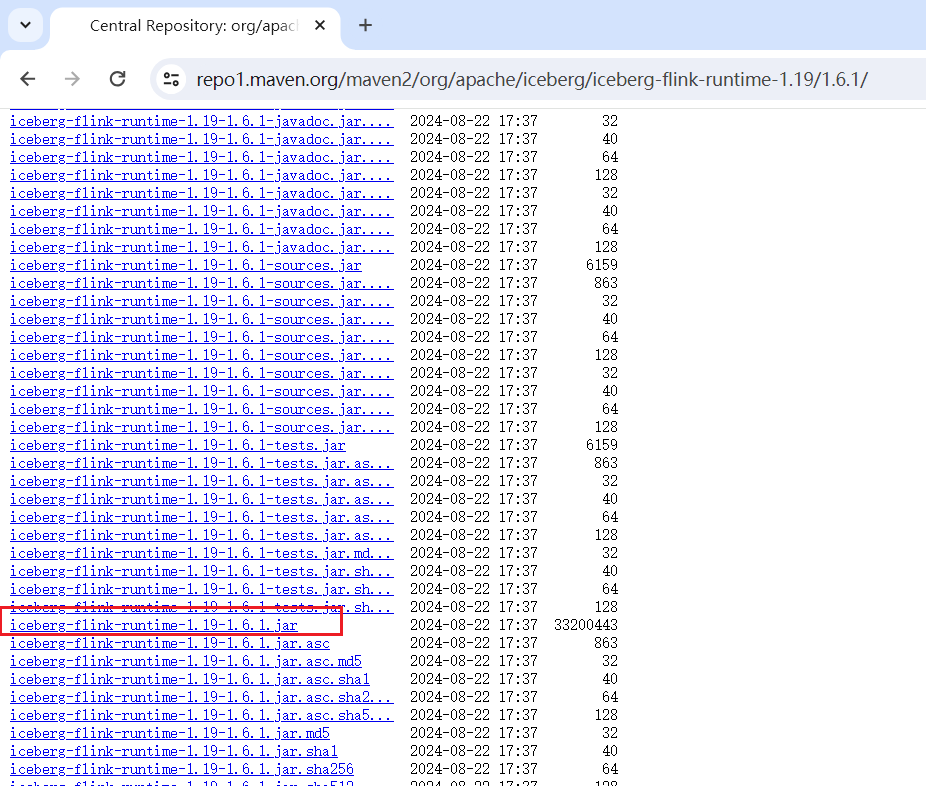
提示
目前最新版本为1.8.0,但是iceberg从1.7.0开始不再支持jdk1.8, iceberg1.6.1支持jdk1.8
1.2 拷贝iceberg的jar包到Flink
cp /opt/software/iceberg-flink-runtime-1.19-1.6.1.jar /opt/module/flink-1.17.2/lib/1.3 支持HiveCatalog
访问https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-hive-3.1.3_2.12/1.17.2/, 下载对应Hive版本的sql驱动jar包: 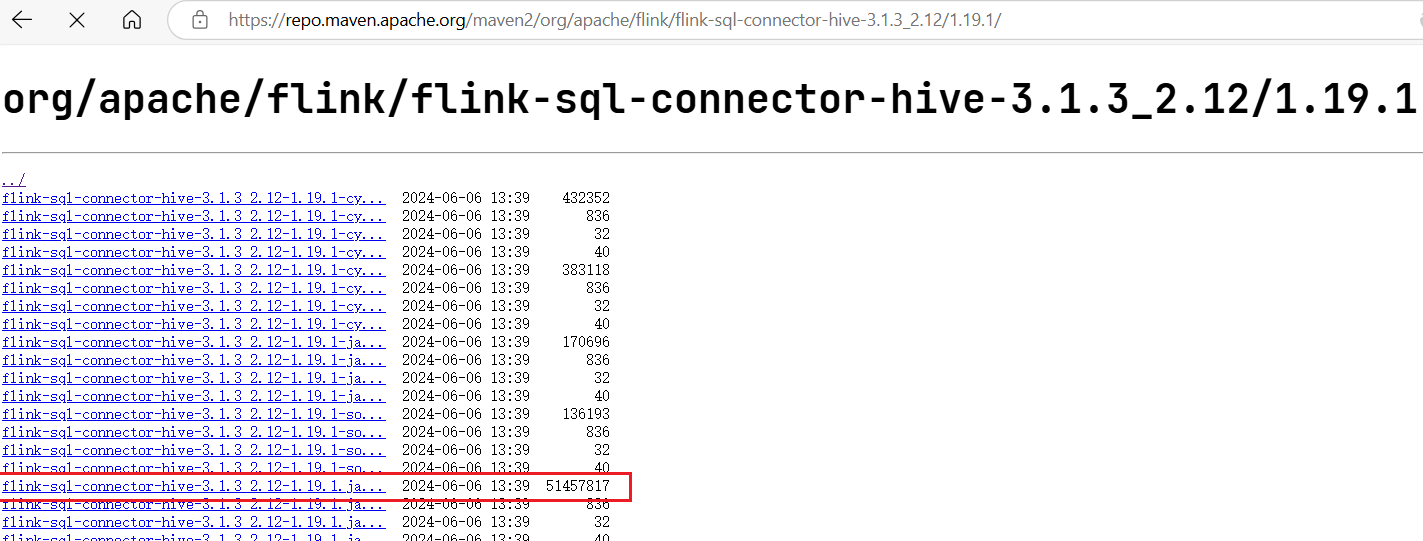 拷贝hive驱动jar包到Flink
拷贝hive驱动jar包到Flink
cp /opt/software/flink-sql-connector-hive-3.1.3_2.12-1.17.2.jar /opt/module/flink-1.17.2/lib/1.4 配置环境变量
- 修改my_env.sh配置
sudo vim /etc/profile.d/my_env.sh
## 添加如下内容
export HADOOP_CLASSPATH=`$HADOOP_HOME/bin/hadoop classpath`- 修改conf.yaml配置
## 关闭类加载警告
classloader:
check-leaked-classloader: false
taskmanager:
numberOfTaskSlots: 4
execution:
checkpointing:
interval: 30s
## 开启checkpoint特性
state:
backend:
type: rocksdb
incremental: true
checkpoints:
dir: hdfs://hadoop102:8020/flink/ckps提示
从Flink 1.19开始,默认配置文件已改为config.yaml, 并使用YAML 1.2语法
1.5 启动环境依赖
启动Hadoop集群和Hive的metastore服务
2. 启动sql-client
2.1 使用local模式
修改workers文件
vim /opt/module/flink-1.17.2/conf/workers
#表示:会在本地启动3个TaskManager的 local集群
localhost
localhost
localhost2.2 启动Flink
[jack@hadoop102 flink-1.17.2]$ ./bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host hadoop102.
Starting taskexecutor daemon on host hadoop102.
[INFO] 1 instance(s) of taskexecutor are already running on hadoop102.
Starting taskexecutor daemon on host hadoop102.
[INFO] 2 instance(s) of taskexecutor are already running on hadoop102.
Starting taskexecutor daemon on host hadoop102.查看webui:http://hadoop102:8081
2.3 启动sql-client
./bin/sql-client.sh embedded
3. 创建和使用Catalog
3.1 语法说明
iceberg使用flink的语法创建catalog:
CREATE CATALOG <catalog_name> WITH (
'type'='iceberg', -- 这是必须显示配置
`<config_key>`=`<config_value>`
);其中的config_key有以下这些属性可选配置:
- catalog-type: 内置了hive和hadoop两种catalog,也可以使用catalog-impl来自定义catalog。
- catalog-impl: 自定义catalog实现的全限定类名。如果未设置catalog-type,则必须设置。
- property-version: 描述属性版本的版本号。此属性可用于向后兼容,以防属性格式更改。当前属性版本为1。
- cache-enabled: 是否启用目录缓存,默认值为true。
- cache.expiration-interval-ms: 本地缓存catalog条目的时间(以毫秒为单位);负值,如-1表示没有时间限制,不允许设为0。默认值为-1。
- uri: Hive metastore的thrift uri。
- clients:Hive metastore客户端池大小,默认为2。
- warehouse: 数仓目录。
- hive-conf-dir:包含hive-site.xml配置文件的目录路径,hive-site.xml中hive.metastore.warehouse.dir的值会被warehouse覆盖。
- hadoop-conf-dir:包含core-site.xml和hdfs-site.xml配置文件的目录路径。
3.2 Hive Catalog
- 创建hive catalog
Flink SQL> CREATE CATALOG hive_catalog WITH (
> 'type'='iceberg',
> 'catalog-type'='hive',
> 'uri'='thrift://hadoop103:9083',
> 'clients'='3',
> 'property-version'='1',
> 'warehouse'='hdfs://hadoop102:8020/flink/warehouse/'
> );
[INFO] Execute statement succeed.
Flink SQL> use catalog hive_catalog;
[INFO] Execute statement succeed.3.3 Hadoop Catalog
Iceberg还支持HDFS中基于目录的catalog,可以使用'catalog-type'='hadoop'配置。
Flink SQL> CREATE CATALOG hadoop_catalog WITH (
> 'type'='iceberg',
> 'catalog-type'='hadoop',
> 'warehouse'='hdfs://hadoop102:8020/warehouse/flink-iceberg',
> 'property-version'='1'
> );
[INFO] Execute statement succeed.3.4 配置sql-client初始化文件
如果退出flink-sql客户端,之前创建的catalog都会被自动清空,可以添加初始化脚本:
vim /opt/module/flink-1.17.2/conf/sql-client-init.sql
## 添加初始化脚本内容
CREATE CATALOG hive_catalog WITH (
'type'='iceberg',
'catalog-type'='hive',
'uri'='thrift://hadoop103:9083',
'clients'='3',
'property-version'='1',
'warehouse'='hdfs://hadoop102:8020/flink/warehouse/'
);
CREATE CATALOG hadoop_catalog WITH (
'type'='iceberg',
'catalog-type'='hadoop',
'warehouse'='hdfs://hadoop102:8020/warehouse/flink-iceberg',
'property-version'='1'
);
USE CATALOG hive_catalog;
-- 结果显示模式设置为tableau
SET sql-client.execution.result-mode=tableau;后续启动sql-client时,加上-i sql文件路径 即可完成catalog的初始化。
./bin/sql-client.sh embedded -i conf/sql-client-init.sql
Flink SQL> show catalogs;
+-----------------+
| catalog name |
+-----------------+
| default_catalog |
| hadoop_catalog |
| hive_catalog |
+-----------------+
3 rows in set4. 创建数据库
Flink SQL> create database flink_db;
[INFO] Execute statement succeed.
Flink SQL> use flink_db;
[INFO] Execute statement succeed.5. 创建表
截至iceberg1.8,仍然不支持计算列、watermark(支持主键)。flink建表不区分内部外部表,也就是没有external关键字的使用,默认创建的就是外部表。
5.1 创建普通表
-- 默认使用hive_catalog
CREATE TABLE ice_flink_sample1 (
id BIGINT COMMENT 'unique id',
data STRING
);
-- 创建hadoop_catalog中的表
CREATE TABLE hadoop_catalog.default_database.ice_sample2 (
id INT,
name STRING
);
-- 如果没有在iceberg相关的catalog里, 需要使用connector关键字指明创建iceberg表
CREATE TABLE default_catalog.default_database.ice_sample3 (
id INT,
name STRING
)
WITH (
'connector' = 'iceberg',
'catalog-name' = 'default_catalog',
'catalog-type' = 'hadoop',
'warehouse' = 'hdfs://hadoop102:8020/warehouse/flink-iceberg/',
'format-version' = '2'
);5.2 创建分区表
CREATE TABLE ice_flink_sample2 (
id BIGINT COMMENT 'unique id',
category STRING
)
partitioned by (category);
-- 创建主键分区表
CREATE TABLE ice_flink_sample3 (
id BIGINT COMMENT 'unique id',
category STRING,
ts timestamp(3),
primary key (id) not enforced -- 支持设置主键
)
partitioned by (category);提示
Apache Iceberg支持隐藏分区特性,但目前Apache flink不支持在列上通过函数进行分区,因而Flink集成Iceberg不支持隐藏分区。
5.3 CTAL建表
LIKE语法用于创建一个与另一个表具有相同schema、分区和属性的表。
create table ice_flink_sample5 like ice_flink_sample3;5.4 CTAS建表
create table ice_flink_sample6 as select * from ice_flink_sample3;5.5 创建watermark表

5.6 创建含有计算列的表

6. 修改表
6.1 修改表名
Flink SQL> alter table ice_flink_sample6 rename to new_ice_flink_sample6;
[INFO] Execute statement succeed.6.2 修改表属性
Flink SQL> alter table new_ice_flink_sample6 set ('write.format.default'='avro');
[INFO] Execute statement succeed.6.3 添加表字段
Flink SQL> alter table ice_flink_sample1 add catagory string;
[INFO] Execute statement succeed.
Flink SQL> show create table ice_flink_sample1;
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| result |
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| CREATE TABLE `hive_catalog`.`flink_db`.`ice_flink_sample1` (
`id` BIGINT,
`data` VARCHAR(2147483647),
`catagory` VARCHAR(2147483647)
) WITH (
'write.parquet.compression-codec' = 'zstd',
'write.upsert.enabled' = 'true'
)
|
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set6.4 修改表字段
## 修改表字段名称
Flink SQL> alter table ice_flink_sample1 rename catagory to category;
[INFO] Execute statement succeed.
## 将id类型从int改为bigint
Flink SQL> alter table ice_flink_sample1 modify id bigint;
[INFO] Execute statement succeed.6.5 删除表字段
Flink SQL> alter table ice_flink_sample1 drop category;
[INFO] Execute statement succeed.7. 删除表
对new_ice_flink_sample6插入数据后,可见HDFS上data目录下有文件:
drop table new_ice_flink_sample6;查看HDFS上表目录还在,但是data目录下已经被清空 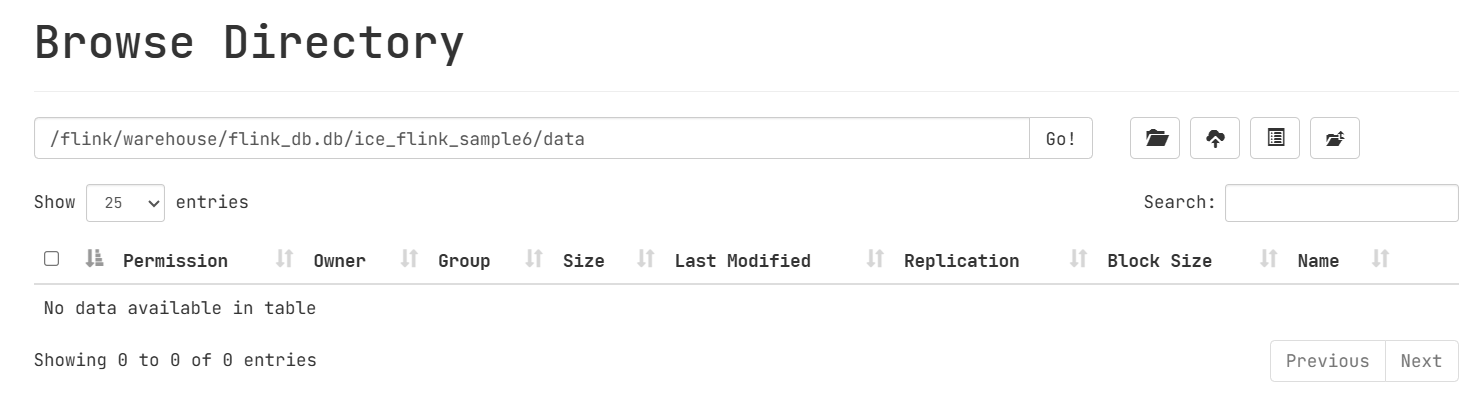
8. 插入数据
8.1 INSERT INTO
INSERT INTO sample1 VALUES (1, 'a');8.2 INSERT OVERWRITE
仅支持Flink的Batch模式, 默认是streaming
Flink SQL> insert overwrite sample1 values(3, 'china');
[ERROR] Could not execute SQL statement. Reason:
java.lang.IllegalStateException: Unbounded data stream doesn't support overwrite operation.
Flink SQL> SET execution.runtime-mode = batch;
[INFO] Execute statement succeed.
Flink SQL> insert overwrite sample1 values(3, 'china');
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: 77fdc0e6f11cafa42e9fb39e1745c0e4
Flink SQL> select * from sample1;
+----+-------+
| id | data |
+----+-------+
| 3 | china |
+----+-------+
1 row in set (2.51 seconds)8.3 UPSERT
当将数据写入v2表格式时,Iceberg支持基于主键的UPSERT(没有主键的表肯定不得行🤔)。有两种方法可以启用upsert。
- 建表时指定v2表
-- 建表不指定版本默认是v1表
CREATE TABLE ice_flink_sample6 (
`id` INT COMMENT 'unique id',
`data` STRING NOT NULL,
PRIMARY KEY(`id`) NOT ENFORCED
) with (
'format-version'='2',
'write.upsert.enabled'='true'
);插入数据发现数据条数只有2条:
Flink SQL> insert into ice_flink_sample6 values (1, 'china'),(2, 'russia'),(2, 'japan');
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: 210a266aa8fa1bfb93d5d075fe09afb9
Flink SQL> select * from ice_flink_sample6;
+----+-------+
| id | data |
+----+-------+
| 1 | china |
| 2 | japan |
+----+-------+
2 rows in set (2.06 seconds)- 插入时指定
-- 表要求仍然是v2表,只不过没配置属性write.upsert.enabled而已,想用upsert可以使用hint语法
INSERT INTO sample1 /*+ OPTIONS('upsert-enabled'='true') */
values (3, 'test');- 通过修改表属性
create table ice_flink_sample7(
id int,
category string,
primary key(id) not ENFORCED
) partitioned by (id);
alter table ice_flink_sample7 set ('format-version'='2');
alter table ice_flink_sample7 set ('write.upsert.enabled'='true');
insert into ice_flink_sample7 values (1, 'china'),(2, 'russia'),(2, 'japan');查询ice_flink_sample7表数据: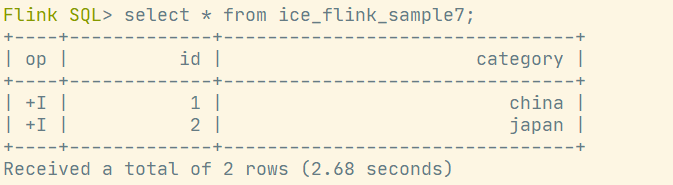
提示
OVERWRITE和UPSERT不能同时设置。在UPSERT模式下,如果对表进行分区,则分区字段必须也是主键。uperset在流式处理中iceberg中会出现大量的小文件,容易出现性能问题。
9. 查询数据
Iceberg支持Flink的流式和批量读取。 需要将flinksql集成kafka的jark包提前放到lib目录下:
cp /opt/software/flink-sql-connector-kafka-3.3.0-1.19.jar /opt/module/flink-1.17.2/lib/然后创建一张流式表在flink的数据库中(不用到iceberg特性的表都不建议建在iceberg的数据库中):
-- 默认的catalog是基于flink内部的,但是重启会丢失
create table default_catalog.default_database.kafka_data(
id int,
data string
) with (
'connector' = 'kafka'
,'topic' = 'test111'
,'properties.bootstrap.servers' = 'hadoop102:9092'
,'format' = 'json'
,'properties.group.id'='iceberg'
,'scan.startup.mode'='earliest-offset'
);
INSERT INTO hive_catalog.flink_db.sample1 SELECT * FROM default_catalog.default_database.kafka_data;9.1 Batch模式
-- 设置批量读取,flink查询数据后直接返回返回
SET execution.runtime-mode = batch;向主题test111添加数据: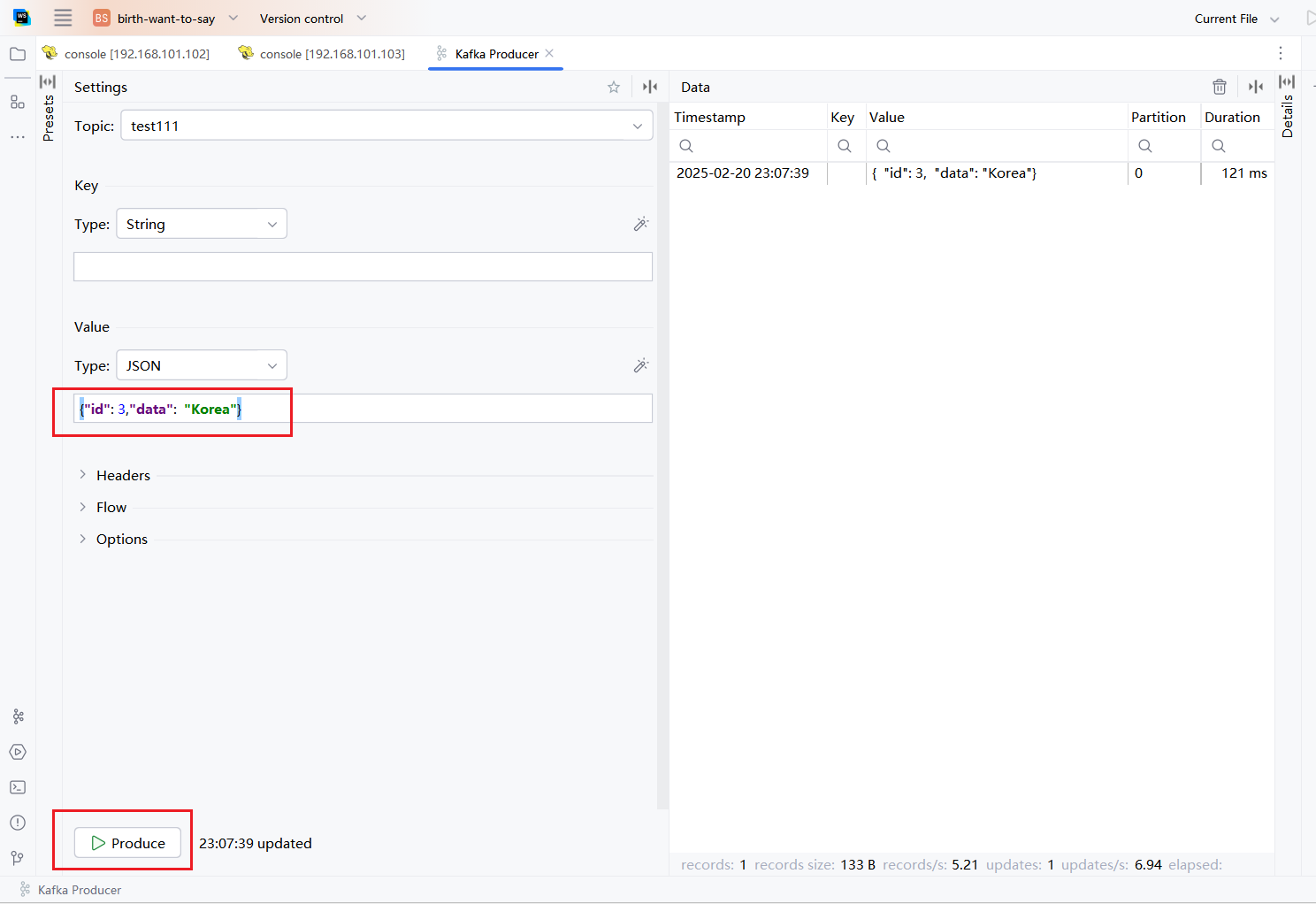
消费数据返回结果:
Flink SQL> select * from sample1;
+----+-------+
| id | data |
+----+-------+
| 3 | china |
| 3 | Korea |
+----+-------+
2 rows in set (2.77 seconds)9.2 Streaming模式
SET execution.runtime-mode = streaming;
-- 流式读取会使用sqlhint语法,需要开启sqlhint功能
SET table.dynamic-table-options.enabled=true;- 从当前快照读取所有记录,然后从该快照读取增量数据
 但是会发现查询并没有隔1s就读出结果,延迟比较大🐌
但是会发现查询并没有隔1s就读出结果,延迟比较大🐌 - 读取指定快照id(不包含)后的增量数据
SELECT * FROM sample1 /*+ OPTIONS('streaming'='true', 'monitor-interval'='1s', 'start-snapshot-id'='1480938328156972338')*/ ;执行结果:
monitor-interval: 连续监控新提交数据文件的时间间隔(默认为10s)。start-snapshot-id: 流作业开始的快照id。
9.3 读取元数据
- 查询表历史
Flink SQL> SELECT * FROM sample1$history;
+----+----------------------------+----------------------+----------------------+---------------------+
| op | made_current_at | snapshot_id | parent_id | is_current_ancestor |
+----+----------------------------+----------------------+----------------------+---------------------+
| +I | 2025-02-20 16:27:42.219000 | 7624841869579953721 | <NULL> | TRUE |
| +I | 2025-02-20 18:25:48.871000 | 7746000265018688527 | 7624841869579953721 | TRUE |
| +I | 2025-02-20 23:39:53.333000 | 331542884841832756 | 7746000265018688527 | TRUE |
| +I | 2025-02-20 23:44:52.346000 | 7842208569105275211 | 331542884841832756 | TRUE |
| +I | 2025-02-20 23:48:52.545000 | 4972667660659945835 | 7842208569105275211 | TRUE |
| +I | 2025-02-20 23:49:52.551000 | 8765394301691897863 | 4972667660659945835 | TRUE |
| +I | 2025-02-20 23:50:52.567000 | 888884632272991439 | 8765394301691897863 | TRUE |
| +I | 2025-02-20 23:51:52.518000 | 1480938328156972338 | 888884632272991439 | TRUE |
| +I | 2025-02-20 23:56:52.421000 | 8015754396930444358 | 1480938328156972338 | TRUE |
+----+----------------------------+----------------------+----------------------+---------------------+
Received a total of 9 rows (2.53 seconds)- 查询表快照
SELECT * FROM sample1$snapshots;执行结果: 3. 查询表分区
3. 查询表分区
SELECT * FROM sample1$partitions;10. 与Flink集成的不足
当前Flink-Iceberg集成工作中尚不支持以下功能:
- 不支持使用隐藏分区创建Iceberg表。
- 不支持使用计算列创建Iceberg表。
- 不支持使用watermark创建Iceberg表。