与SparkDataFrame集成
1. 环境准备
- 创建maven工程spark-iceberg-demo,配置pom文件
xml
<groupId>com.rocket.iceberg</groupId>
<artifactId>spark-iceberg-demo</artifactId>
<version>1.0</version>
<properties>
<scala.binary.version>2.12</scala.binary.version>
<spark.version>3.4.2</spark.version>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<!-- Spark的依赖引入 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<scope>provided</scope>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.binary.version}</artifactId>
<scope>provided</scope>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.binary.version}</artifactId>
<scope>provided</scope>
<version>${spark.version}</version>
</dependency>
<!--fastjson <= 1.2.80 存在安全漏洞,-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.83</version>
</dependency>
<dependency>
<groupId>org.apache.iceberg</groupId>
<artifactId>iceberg-spark-runtime-3.3_2.12</artifactId>
<version>1.1.0</version>
</dependency>
</dependencies>- 在reources目录下添加log4j2.properties
ini
log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy-MM-dd HH:mm:ss} %p %c{1}: %m%n
# Set the default spark-shell log level to ERROR. When running the spark-shell, the
# log level for this class is used to overwrite the root logger's log level, so that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=ERROR
# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=ERROR
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=ERROR
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=ERROR
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR2. 配置Catalog
scala
System.setProperty("HADOOP_USER_NAME", "jack")
val spark: SparkSession = SparkSession.builder().master("local").appName(this.getClass.getSimpleName)
.enableHiveSupport()
//指定hive catalog, catalog名称为iceberg_hive
.config("spark.sql.catalog.hive_prod", "org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.hive_prod.type", "hive")
.config("spark.sql.catalog.hive_prod.uri", "thrift://hadoop103:9083")
// .config("iceberg.engine.hive.enabled", "true")
.config("spark.sql.warehouse.dir", "hdfs://hadoop102:8020/spark/warehouse")
//指定hadoop catalog,catalog名称为iceberg_hadoop
.config("spark.sql.catalog.hadoop_prod", "org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.hadoop_prod.type", "hadoop")
.config("spark.sql.catalog.hadoop_prod.warehouse", "hdfs://hadoop102:8020/warehouse/spark-iceberg")
.getOrCreate()
spark.sql("use hive_prod.default;").show()3. 读取表
3.1 加载表
scala
spark.read
.format("iceberg")
.table("ice_spark_sample1")
.show()
2.2 指定时间查询
scala
// 查询2025-02-20之前的数据
spark.read
.option("as-of-timestamp", "1739980800000")
.format("iceberg")
.table("ice_spark_sample1")
.show()
2.3 指定快照id查询
scala
spark.read
.option("snapshot-id", 4012613232180724766L)
.format("iceberg")
.table("ice_spark_sample1")
.show()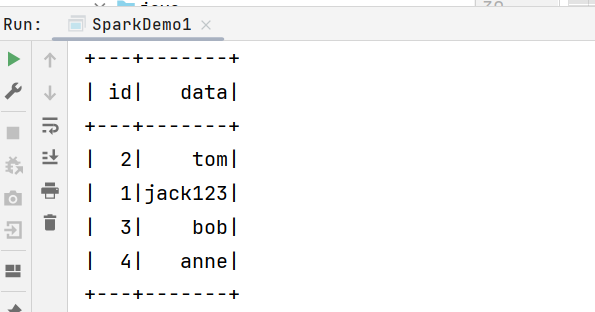
2.4 增量查询
scala
spark.read
.format("iceberg")
.option("start-snapshot-id", "5825989728064739405")
.option("end-snapshot-id", "7404723281141935099")
.table("ice_spark_sample1")
.show()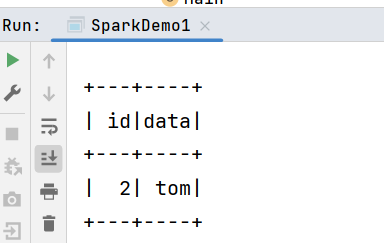 增量查询的表目前Iceberg只支持append的方式写数据,不支持replace, overwrite, delete操作。
增量查询的表目前Iceberg只支持append的方式写数据,不支持replace, overwrite, delete操作。
3. 检查表
3.1 查询元数据
scala
spark
.read
.format("iceberg")
.load("iceberg_hive.default.ice_spark_sample1.files")
.show()
3.2 元数据表时间旅行查询
scala
spark
.read
.format("iceberg")
.option("snapshot-id", 7601163594701794741L)
.load("iceberg_hive.default.ice_spark_sample1.files")
.show()4. 写入表
4.1 创建样例类,准备DF
scala
case class Sample(id:Int,data:String,category:String)
val df: DataFrame = spark.createDataFrame(Seq(Sample(1,'A', 'a'), Sample(2,'B', 'b'), Sample(3,'C', 'c')))4.2 插入数据并建表
scala
import spark.implicits._
df.writeTo("ice_spark_sample18")
.tableProperty("write.format.default", "orc")
.using("iceberg")
.tableProperty("format-version", "2")
// 指定表的存储位置
.tableProperty("location", "hdfs://hadoop102:8020/spark/warehouse/ice_spark_sample18")
.partitionedBy($"category")
.create()查询ice_spark_sample18表数据:
sh
0: jdbc:hive2://hadoop103:10000> select * from ice_spark_sample18;
+-----+-------+-----------+
| id | data | category |
+-----+-------+-----------+
| 1 | A | a |
| 2 | B | b |
| 3 | C | c |
+-----+-------+-----------+
3 rows selected (3.798 seconds)4.3 append追加
scala
df.writeTo("ice_spark_sample18").append()查询ice_spark_sample18表数据:
sh
0: jdbc:hive2://hadoop103:10000> select * from ice_spark_sample18;
+-----+-------+-----------+
| id | data | category |
+-----+-------+-----------+
| 1 | A | a |
| 2 | B | b |
| 3 | C | c |
| 1 | A | a |
| 2 | B | b |
| 3 | C | c |
+-----+-------+-----------+
6 rows selected (0.615 seconds)4.4 动态分区覆盖
scala
val df1: DataFrame = spark.createDataFrame(Seq(Sample(11,"A", "a"), Sample(22,"B", "b2"), Sample(33,"C", "c3")))
df1.writeTo("ice_spark_sample18").overwritePartitions()可以发现a分区的数据被覆盖了,其他数据作为追加方式写入: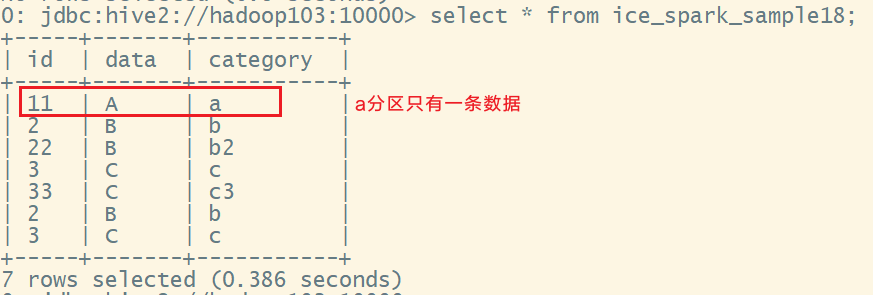
4.5 静态分区覆盖
只需要覆盖其中满足条件的数据:
scala
import spark.implicits._
df.writeTo("iceberg_hadoop.default.table1").overwrite($"category" === "c")执行后查看数据,发现b2值的数据不存在被覆盖了:
sh
0: jdbc:hive2://hadoop103:10000> select * from ice_spark_sample18;
+------+-------+-----------+
| id | data | category |
+------+-------+-----------+
| 111 | AAA | a3 |
| 222 | BBB | b22 |
| 333 | CCC | c3 |
| 2 | B | b |
| 3 | C | c |
| 11 | A | a |
| 33 | C | c3 |
| 2 | B | b |
| 3 | C | c |
+------+-------+-----------+
9 rows selected (0.511 seconds)4.6 插入分区表且分区内排序
scala
df.sortWithinPartitions("category")
.writeTo("iceberg_hadoop.default.table1")
.append()5. 维护表
5.1 获取Table对象
scala
System.setProperty("HADOOP_USER_NAME", "jack")
val spark: SparkSession = SparkSession.builder().master("local").appName(this.getClass.getSimpleName)
.enableHiveSupport()
.getOrCreate()
val hiveCatalog = new HiveCatalog()
hiveCatalog.setConf(spark.sparkContext.hadoopConfiguration)
val properties = new util.HashMap[String,String]()
properties.put("warehouse", "hdfs://hadoop102:8020/spark/warehouse")
properties.put("uri", "thrift://hadoop103:9083")
hiveCatalog.initialize("hiveCatalog", properties)
val ice_spark_sample1: Table = hiveCatalog.loadTable(TableIdentifier.of("default","ice_spark_sample1"))5.2 快照过期清理
每次写入Iceberg表都会创建一个表的新快照或版本。快照可以用于时间旅行查询,或者可以将表回滚到任何有效的快照。建议设置快照过期时间,过期的旧快照将从元数据中删除(不再可用于时间旅行查询)。
scala
// 10分钟天过期时间
val tsToExpire: Long = System.currentTimeMillis() - (1000 * 10 * 60)
ice_spark_sample1.expireSnapshots()
.expireOlderThan(tsToExpire)
.commit()
// 或使用SparkActions来设置过期, Spark3.x支持
SparkActions.get()
.expireSnapshots(ice_spark_sample1)
.expireOlderThan(tsToExpire)
.execute()查询数据库:
sh
0: jdbc:hive2://hadoop103:10000> select committed_at, snapshot_id, operation from hive_prod.default.ice_spark_sample1.snapshots;
+--------------------------+----------------------+------------+
| committed_at | snapshot_id | operation |
+--------------------------+----------------------+------------+
| 2025-02-19 15:08:29.046 | 7404723281141935099 | overwrite |
+--------------------------+----------------------+------------+
1 row selected (0.169 seconds)
0: jdbc:hive2://hadoop103:10000>可见只剩下一个快照,也就是保留了最新的数据状态。
5.3 删除无效文件
在Spark和其他分布式处理引擎中,任务或作业失败可能会留下未被表元数据引用的文件,在某些情况下,正常的快照过期可能无法确定不再需要并删除该文件。
scala
SparkActions
.get()
.deleteOrphanFiles(ice_spark_sample1)
.execute()警告
此操作可能需要较长时间才能完成,特别是当您在数据和元数据目录中有大量文件时。建议定期执行此操作,但您可能不需要频繁执行。
5.4 合并小文件
数据文件过多会导致更多的元数据存储在清单文件中,而较小的数据文件会导致不必要的元数据量和更低效率的文件打开成本。
scala
SparkActions
.get()
.rewriteDataFiles(table)
.filter(Expressions.equal("category", "a"))
.option("target-file-size-bytes", 1024L.toString) //1KB
.execute()