大数据架构之Kappa架构
1. Kappa架构图
Kappa架构是一种现代的大数据处理架构模式,由Linkedln的前首席工程师Jav Kreps在深入分析和反思Lambda架构的基础上提出。Kappa架构的设计目标是在保证实时性和准确性的同时简化系统的复杂性,尤其是减少在处理实时和历史数据时所需的重复代码。 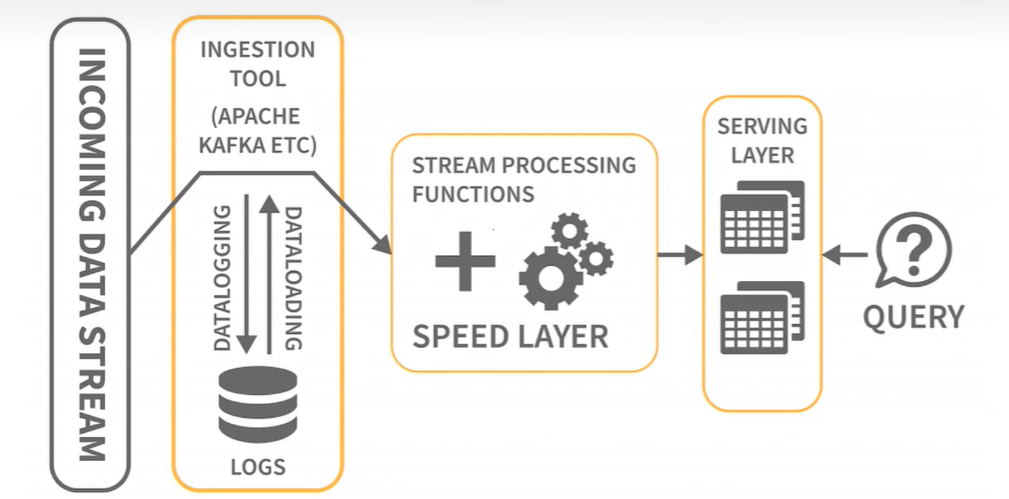 Kappa架构的数据处理流程相对简洁和集中,其核心思路是将所有数据作为事件流来处理。
Kappa架构的数据处理流程相对简洁和集中,其核心思路是将所有数据作为事件流来处理。
2. Kappa处理流程
2.1 事件产生与收集
- 应用系统在每次发生业务活动时,如用户行为、交易、传感器读数等,都会生成对应的事件数据。
- 这些事件被实时地发送至一个持久化、可重播的消息队列系统,最常见的是Apache Kafka。
2.2 事件日志存储
Kafka作为一个事件日志核心组件,负责接收并存储所有产生的事件。它可以设置数据保留期限,即历史事件可以在一定时间内被重新消费。
2.3 实时流处理
- 流处理系统订阅Kafka中的各个主题(topic),实时消费这些事件。
- 消费者应用(通常是流处理引擎,如Apache Flink、Spark Streaming或Samza等)会对事件进行处理,如清洗、转换、聚合以及触发业务逻辑。
- 处理后的结果可以直接输出到实时报表、监控系统,或者是更新到在线存储系统中供实时查询和决策。
2.4 事件重播和处理逻辑更新
- 当业务需求变更或处理逻辑需要更新时,不需要重新处理整个历史数据集。
- 相反,只需更新流处理逻辑,然后从Kafka中重新读取相应时间段的事件,按照新的逻辑重新处理这些事件。
- 通过这种方式,Kappa架构能够保证在不牺牲实时性的同时,也能轻松应对业务逻辑的演变。
2.5 数据持久化与离线分析
尽管Kappa架构以实时处理为主,但也可以将处理过的数据存储到数据湖或数据仓库中,用于后期的离线分析、机器学习训练或备份用途。
简而言之,Kappa架构的核心在于将所有数据处理转化为对事件流的处理,并通过事件日志的重播机制来实现数据的一致性和处理逻辑的灵活性。
3. Kappa架构缺点
Kappa架构的优点在于将实时和离线代码统一起来,方便维护而且统一了数据口径的问题。而Kappa的缺点也很明显:
3.1 流式处理对于历史数据的高吞吐量力不从心
所有的数据都通过流式计算,即便通过加大并发实例数亦很难适应I0T时代对数据查询响应的即时性要求。
3.2 开发周期长
此外Kappa架构下由于采集的数据格式的不统一,每次都需要开发不同的Streaming程序,导致开发周期长。
3.3 服务器成本浪费
Kappa架构的核心原理依赖于外部高性能存储redis、hbase服务。但是这2种系统组件,又并非设计来满足全量数据存储设计,对服务器成本严重浪费。
4. Lambda架构vsKappa架构
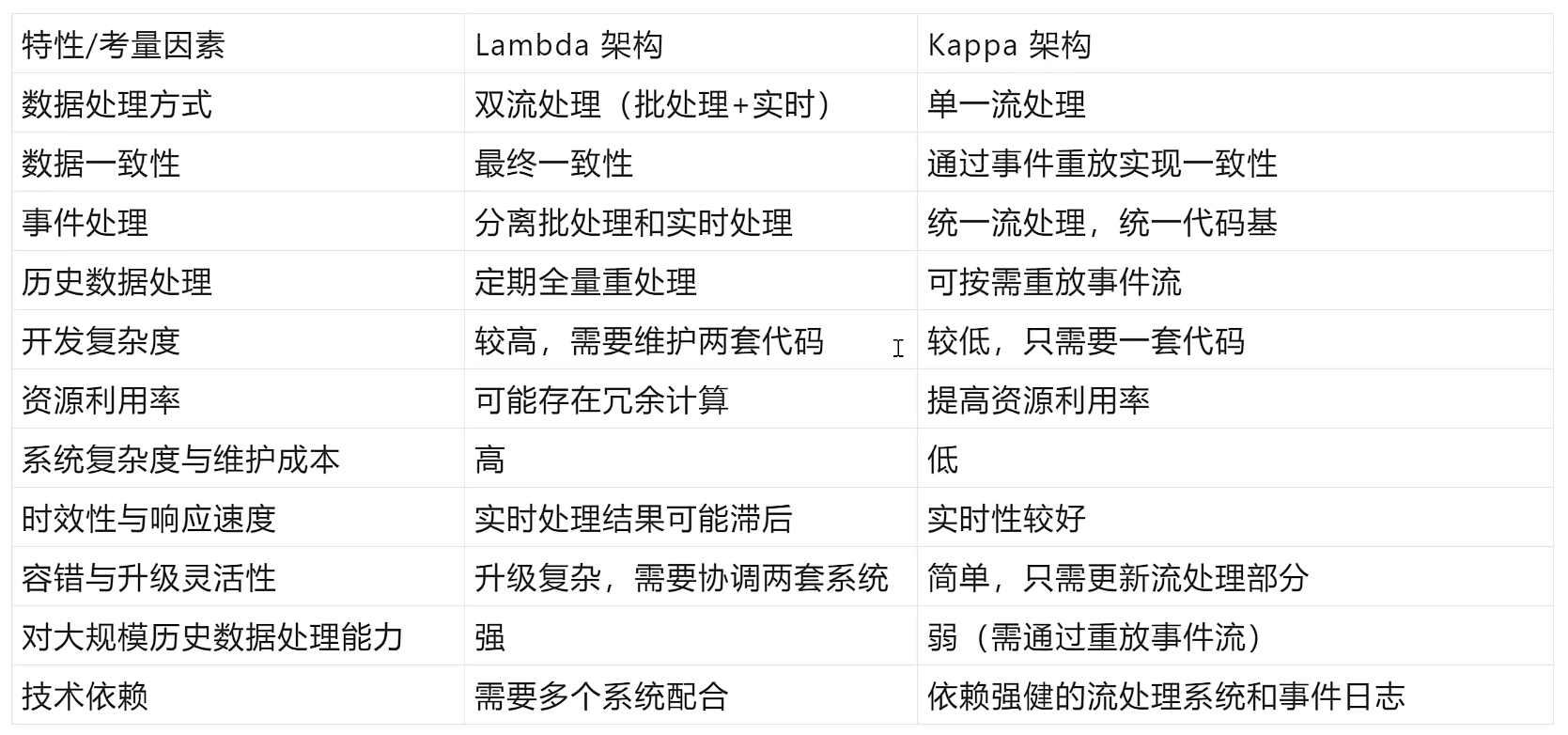 在实际应用中,选择哪种架构取决于具体业务场景和需求。如果业务需求主要是实时性较强并且对历史数据重处理的需求相对较少,Kappa架构可能会有更好的性能表现。相反如果业务中有大量复杂的批处理需求和频繁的历史数据重算,Lambda架构可能更为合适,
在实际应用中,选择哪种架构取决于具体业务场景和需求。如果业务需求主要是实时性较强并且对历史数据重处理的需求相对较少,Kappa架构可能会有更好的性能表现。相反如果业务中有大量复杂的批处理需求和频繁的历史数据重算,Lambda架构可能更为合适,