大数据架构之Lambda架构
1. Lambda架构图
Lambda架构是由Storm的作者Nathan Marz提出的一个近实时大数据处理架构。 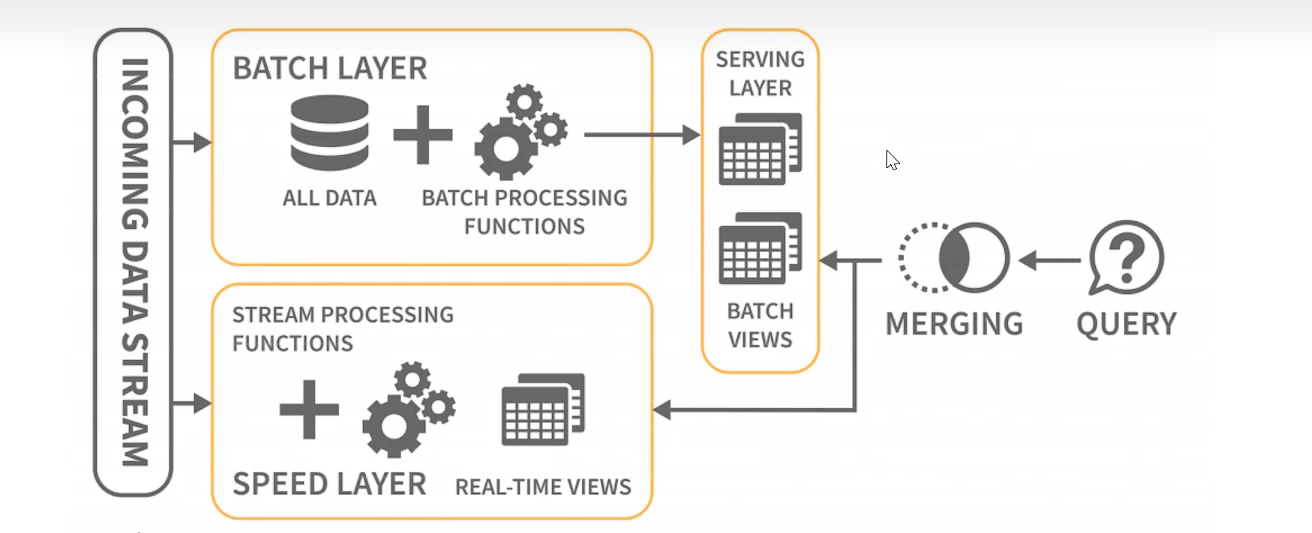 Lambda架构的分层如下;
Lambda架构的分层如下;
1.1 批量层(Batch Layer)
- 这一层主要用于处理完整的、历史的和更新的批量数据。例如,平台每天会收集前一天的所有用户行为记录(浏览、点击、购买等),并将这些数据导入到Hadoop HDFS或其他持久化存储中。
- 使用MapReduce、Spark或Hive等批处理工具对这些历史数据进行全量计算,生成各种汇总视图,如用户购买频率、商品热度排名等,并将这些视图存储在HBase或Cassandra这样的列式数据库中。
1.2 实时处理层(Speed Layer)
- 对于实时发生的用户行为事件,使用像Apache Storm、Flink或Spark Streaming这类实时流处理引擎进行处理。
- 当新的用户行为数据到达时(如用户刚刚完成一次购买),实时层立即对其进行计算,产生实时的更新视图,这些视图可能是近似的或临时的,但是能保证较低的延迟。实时层计算出的结果同样会被暂存,例如在Redis或Memcached中,以备快速查询, 如果数据过大可以考虑OLAP数据库。
1.3 服务层(Serving Layer)
- 服务层负责合并批处理层的准确视图和实时层的近似视图,并对外提供统一的数据服务接口。
- 当用户发起查询请求时(例如,请求查看某商品的实时销量),服务层会查询实时层的最新数据,并补充批处理层的历史精确数据,从而既保证了查询结果的实时性又不失准确性。
- 这个层可能使用Druid或Solr等搜索引擎技术,使查询性能达到亚秒级响应。
2. Lambda架构缺点
Lambda架构经过这么多年的发展,已经非常的成熟,其优点是稳定,对于实时计算部分的成本可控,而批处理部分可以利用晚上等空闲时间进行计算。这样把实时计算和离线处理的高峰错开来。
这种架构支撑了数据行业的早期发展,但也有一些缺点:
2.1 实时和批量结果不一致引起的冲突
由架构中可以得知,架构分实时和离线两部分,两边结果的计算要保持一致比较困难。理论上来说,对于一些需要全量数据才能计算出的结果,90%的数据计算已经由离线负责完成,剩下10%是当前实时的计算结果,对两个结果合并就能做到100%全量的处理,并且保证低延迟。但是,这仅仅是理论上以及我们所期望达到的,实际在应用的过程中因为各种原因导致这个时间没有对的上,导致衔接处出现了一些数据遗漏或者数据重复,就会让结果不准确。并且,当过了一段时间后,离线部分追了上来,对错误进行了修正,又会导致在前端页面导致结果被修改的问题。也就是说:理论是OK的,实施起来比较复杂,难免出现问题,对技术团队的能力有较高的要求。
2.2 批量计算无法在时限内计算完成
在IOT时代,数据量越来越多,很多时候的凌晨空闲期有的时候都不够用了,有的计算作业甚至会计算到中午才结束,这样的话离线部分就大大了落后进度了,这导致实时的压力越来越大,其不断递归选代的更新数据view越来越困难。
2.3 开发和维护的问题
由于要在两个不同的流程中对数据进行处理,那么针对一个业务就产生了两个代码库(一个离线计算、一个实时计算),那么这样的话会让系统的维护更加困难。
2.4 服务器存储开销大
由于View也就是中间数据的存在,会导致计算出许多的中间数据用来支撑业务,这样会加大存储的压力。