集合框架之双列集合
从下图可以看到Set集合底层大量用到了Map集合,了解Set集合就需要具体了解Map的底层原理。 
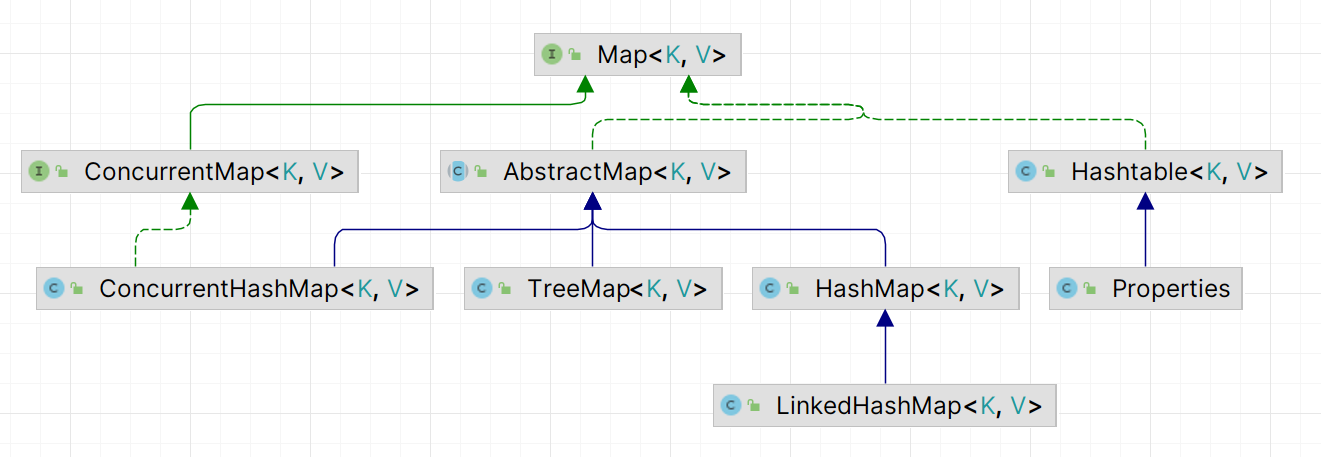
1. Map集合
1.1 Map集合特点
- 双列集合一次需要存一对数据,分别为键和值
- 键不能重复,值可以重复
- 键和值是一一对应的,每一个键只能找到自己对应的值
- 键+值这个整体-->我们称之为“键值对”或者“键值对对象”,在Java中叫做Entry对象
1.2 Map常用API
Map是双列集合的顶层接口,它的功能是全部双列集合都可以继承使用的:
| 方法名称 | 说明 |
|---|---|
| V put(K key,V value) | 添加元素 |
| V remove(Object key) | 根据键删除键值对元素 |
| void clear() | 移除所有的键值对元素 |
| boolean containsKey(Object key) | 判断集合是否包含指定的键 |
| boolean containsValue(Object value) | 判断集合是否包含指定的值 |
| boolean isEmpty() | 判断集合是否为空 |
| int size() | 集合的长度,也就是集合中键值对的个数 |
其中put()方法需要注意的是,在添加数据的时候,如果键是存在的,那么会把原有的键值对对象覆盖,会把被覆盖的值进行返回。
2. Map的遍历
2.1 键找值方式
Map<String, String> map = Map.of("韦小宝", "双儿", "郭靖", "黄蓉", "杨过", "小龙女", "张无忌", "赵敏");
Set<String> keySet = map.keySet();
for (String key : keySet) {
System.out.println("key: "+key+" , value: "+map.get(key));
}2.2 键值对方法
Map<String, String> map = Map.of("韦小宝", "双儿", "郭靖", "黄蓉", "杨过", "小龙女", "张无忌", "赵敏");
Set<Map.Entry<String, String>> entries = map.entrySet();
for (Map.Entry<String, String> entry : entries) {
System.out.println(entry.getKey() + " : " + entry.getValue());
}map.entrySet()得到一个Set集合,里面包含了键值对对象。
2.3 Lambda方式
Map<String, String> map = Map.of("韦小宝", "双儿", "郭靖", "黄蓉", "杨过", "小龙女", "张无忌", "赵敏");
map.forEach((k, v) -> System.out.println(k + " : " + v));3. HashMap集合
请参考hashmap笔记
4. LinkedHashMap集合
由键决定:有序、不重复、无索引。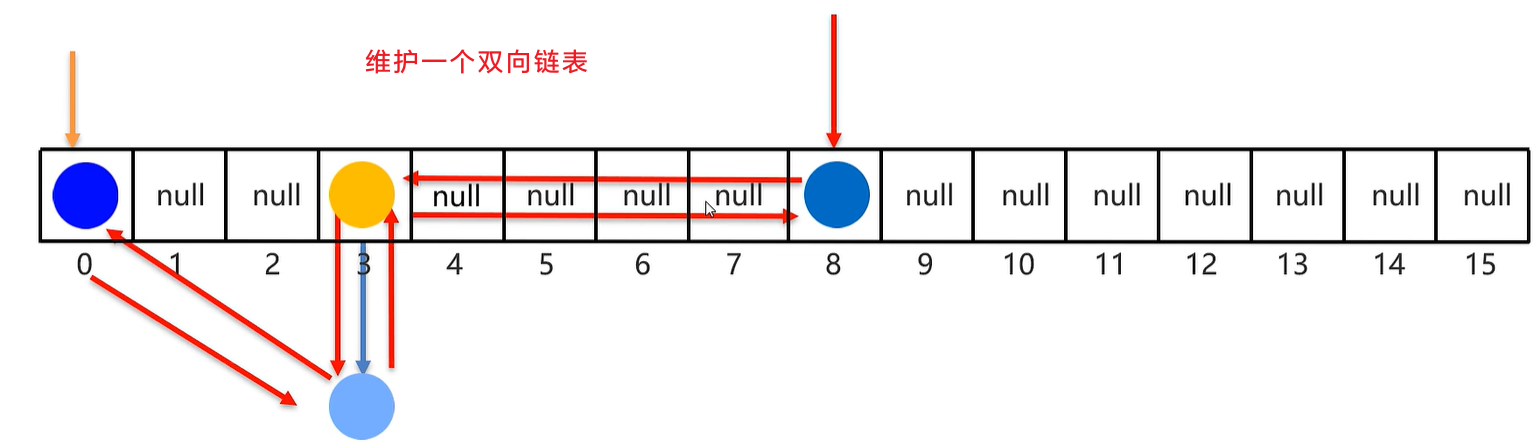
5. TreeMap集合
由键决定特性:不重复、无索引、可排序,其中可排序:对键进行排序。TreeMap跟Treeset底层原理一样,都是红黑树结构的。要求传入的键必须实现Comparable接口,否则报错!
5.1 自定义排序规则
默认按照键的从小到大进行排序,也可以自己规定键的排序规则。TreeMap支持自定义排序:
- 实现Comparable接口,指定比较规则。
- 创建集合时传递Comparator比较器对象,指定比较规则。
5.2 TreeMap底层原理
TreeMap底层使用的是Entry对象保存数据: 创建TreeMap时,什么也没有做:
创建TreeMap时,什么也没有做:
public TreeMap() {
comparator = null;
}TreeMap对象会维护两个属性:root和size:
5.3 put数据流程
执行put()方法,底层会调用另外一个重载的put()方法, 第一个参数为键,第二个参数为值,第三个参数为是否替换旧值,默认为true表示会替换覆盖, 如果不想覆盖则手动调用putIfAbsent()方法: 真正执行的
真正执行的put()方法如下: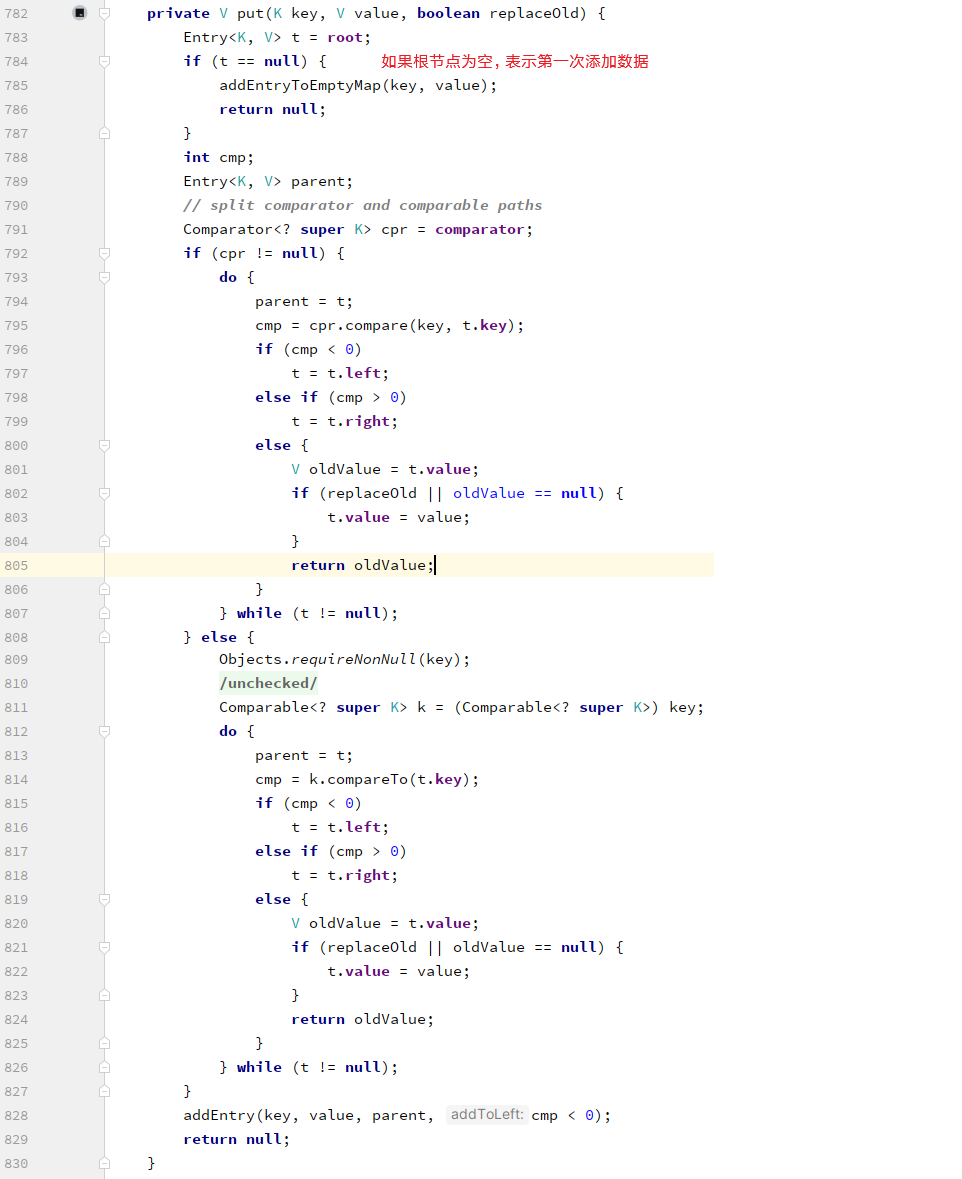 在
在addEntryToEmptyMap()方法中:
private void addEntryToEmptyMap(K key, V value) {
// 没啥意义
compare(key, key); // type (and possibly null) check
// 创建Entry对象,并赋值给root根节点
root = new Entry<>(key, value, null);
size = 1;
modCount++;
}如果不是第一次添加数据,root就不为null, 就开始判断是否有比较器对象,再进行遍历子树节点,在遍历过程中,如果cmp=0, 表示存在该节点,直接覆盖值即可,小需要注意的是整个比较过程并没有用到hashcode和equals方法,用到是键的compareTo()方法: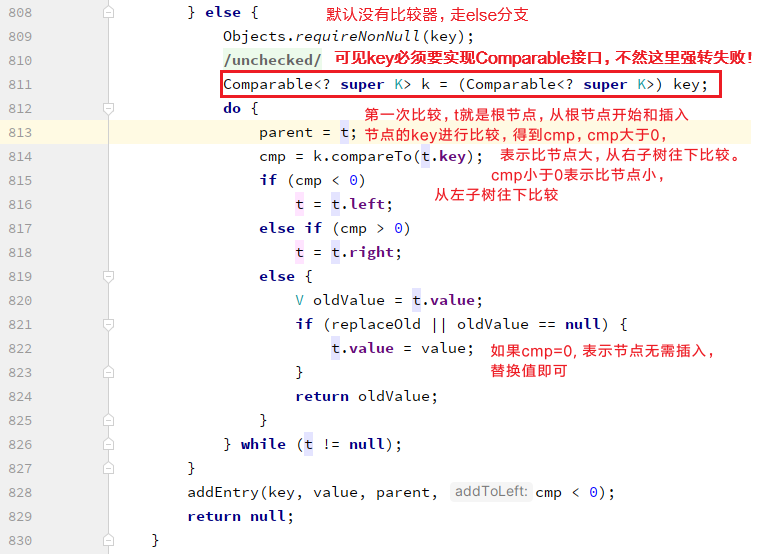 遍历直到到叶子节点为之,此时执行添加节点操作:
遍历直到到叶子节点为之,此时执行添加节点操作: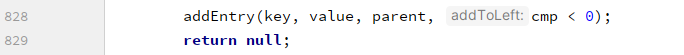 在添加节点操作中,添加完毕后需要按照红黑树规则进行调整:
在添加节点操作中,添加完毕后需要按照红黑树规则进行调整: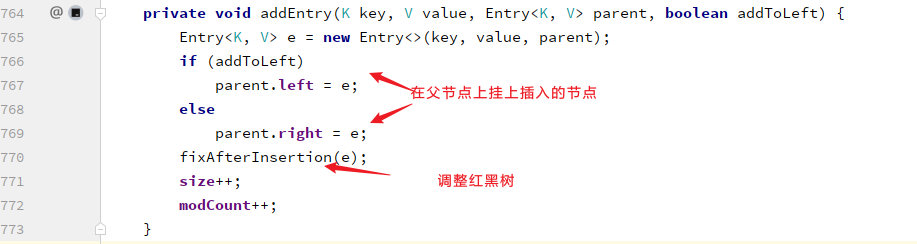 进入fixAfterInsertion()方法:
进入fixAfterInsertion()方法:
private void fixAfterInsertion(Entry<K,V> x) {
//首先将插入的节点颜色标识为红色,这也就解决默认Entry对象初始化都是黑色的问题。
x.color = RED;
// 按照红黑规则进行调整
// parentOf(parentOf(x)表示爷爷节点
// leftOf()表示左子节点
while (x != null && x != root && x.parent.color == RED) {
// 判断当前父节点是否是爷爷下的左子节点,这样方便获取叔叔节点
if (parentOf(x) == leftOf(parentOf(parentOf(x)))) {
// y表示叔叔节点
Entry<K,V> y = rightOf(parentOf(parentOf(x)));
// 叔叔节点为红色
if (colorOf(y) == RED) {
setColor(parentOf(x), BLACK);
setColor(y, BLACK);
setColor(parentOf(parentOf(x)), RED);
// 将x定义为红色节点,再次进行while中判断,直到x为根节点
x = parentOf(parentOf(x));
} else {
if (x == rightOf(parentOf(x))) {
x = parentOf(x);
// 左旋
rotateLeft(x);
}
setColor(parentOf(x), BLACK);
setColor(parentOf(parentOf(x)), RED);
rotateRight(parentOf(parentOf(x)));
}
} else {
// 判断当前父节点是否是爷爷下的左子节点,y表示叔叔节点
Entry<K,V> y = leftOf(parentOf(parentOf(x)));
// 叔叔节点为红色
if (colorOf(y) == RED) {
setColor(parentOf(x), BLACK);
setColor(y, BLACK);
setColor(parentOf(parentOf(x)), RED);
// 将x定义为红色节点,再次进行while中判断,直到x为根节点
x = parentOf(parentOf(x));
} else {
if (x == leftOf(parentOf(x))) {
x = parentOf(x);
rotateRight(x);
}
setColor(parentOf(x), BLACK);
setColor(parentOf(parentOf(x)), RED);
rotateLeft(parentOf(parentOf(x)));
}
}
}
// 根节点设置为黑色
root.color = BLACK;
}其中parentOf()方法用来获取父节点信息。
6. 常见问题
6.1 JDK8之后的HashMap中也有红黑树,为何不要求插入数据的键必须实现Comparable接口?
因为在Hashmap的底层,默认是利用哈希值的大小关系来创建红黑树的。查看HashMap源码: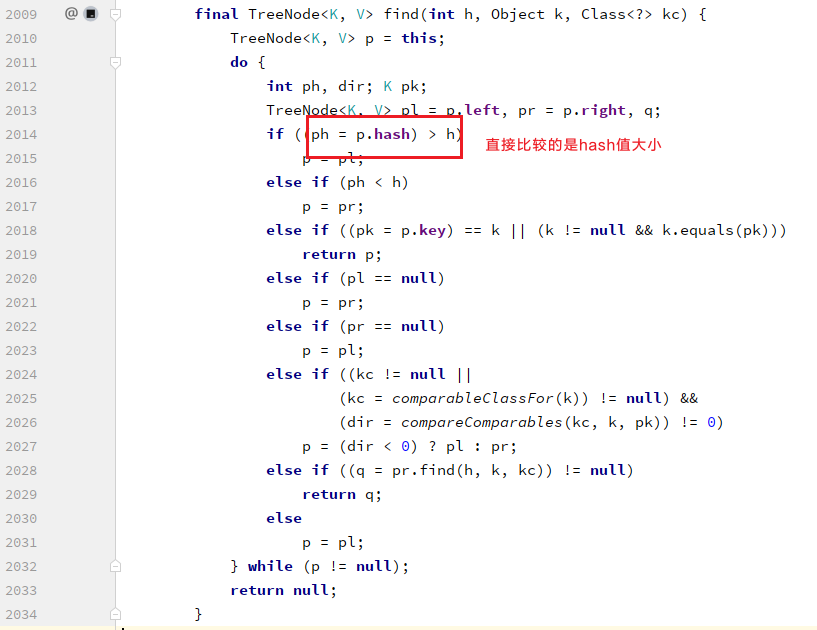
6.2 TreeMap和HashMap哪个效率更高?
如果是最坏情况,添加了8个元素,这8个元素形成了链表,此时reeMap的效率要更高但是这种情况出现的几率非常的少。一般而言,还是HashMap的效率要更高。
6.3 三种双列集合,如何选择?
要求数据有序使用LinkedHashMap, 自定义排序使用TreeMap, 一般情形直接使用HashMap(效率最高)。