哈希表
哈希表(hash table),又称散列表,它通过建立键key与值value之间的映射,实现高效的元素查询。具体而言,我们向哈希表中输入一个键key,则可以在O(1)时间内获取对应的值value。
如图所示,给定n个学生,每个学生都有"姓名"和"学号"两项数据。假如我们希望实现"输入一个学号,返回对应的姓名"的查询功能,则可以采用图所示的哈希表来实现。  除哈希表外,数组和链表也可以实现查询功能,它们的效率对比如表所示:
除哈希表外,数组和链表也可以实现查询功能,它们的效率对比如表所示:
| 数组 | 链表 | 哈希表 | |
|---|---|---|---|
| 查找元素 | O(n) | O(n) | O(1) |
| 添加元素 | O(1) | O(1) | O(1) |
| 删除元素 | O(n) | O(n) | O(1) |
观察发现,在哈希表中进行增删查改的时间复杂度都是O(1) ,非常高效。
1. 哈希表常用操作
哈希表的常见操作包括:初始化、查询操作、添加键值对和删除键值对等。
/* 初始化哈希表 */
Map<Integer, String> map = new HashMap<>();
/* 添加操作 */
// 在哈希表中添加键值对 (key, value)
map.put(12836, "小哈");
map.put(15937, "小啰");
map.put(16750, "小算");
map.put(13276, "小法");
map.put(10583, "小鸭");
/* 查询操作 */
// 向哈希表中输入键 key ,得到值 value
String name = map.get(15937);
/* 删除操作 */
// 在哈希表中删除键值对 (key, value)
map.remove(10583);哈希表有三种常用的遍历方式:遍历键值对、遍历键和遍历值。示例代码如下:
/* 遍历哈希表 */
// 遍历键值对 key->value
for (Map.Entry <Integer, String> kv: map.entrySet()) {
System.out.println(kv.getKey() + " -> " + kv.getValue());
}
// 单独遍历键 key
for (int key: map.keySet()) {
System.out.println(key);
}
// 单独遍历值 value
for (String val: map.values()) {
System.out.println(val);
}2. 哈希冲突与扩容
从本质上看,哈希函数的作用是将所有key构成的输入空间映射到数组所有索引构成的输出空间,而输入空间往往远大于输出空间。因此,理论上一定存在"多个输入对应相同输出"的情况。
如图所示,两个学号指向了同一个姓名,这显然是不对的。我们将这种多个输入对应同一输出的情况称为哈希冲突(hash collision)。 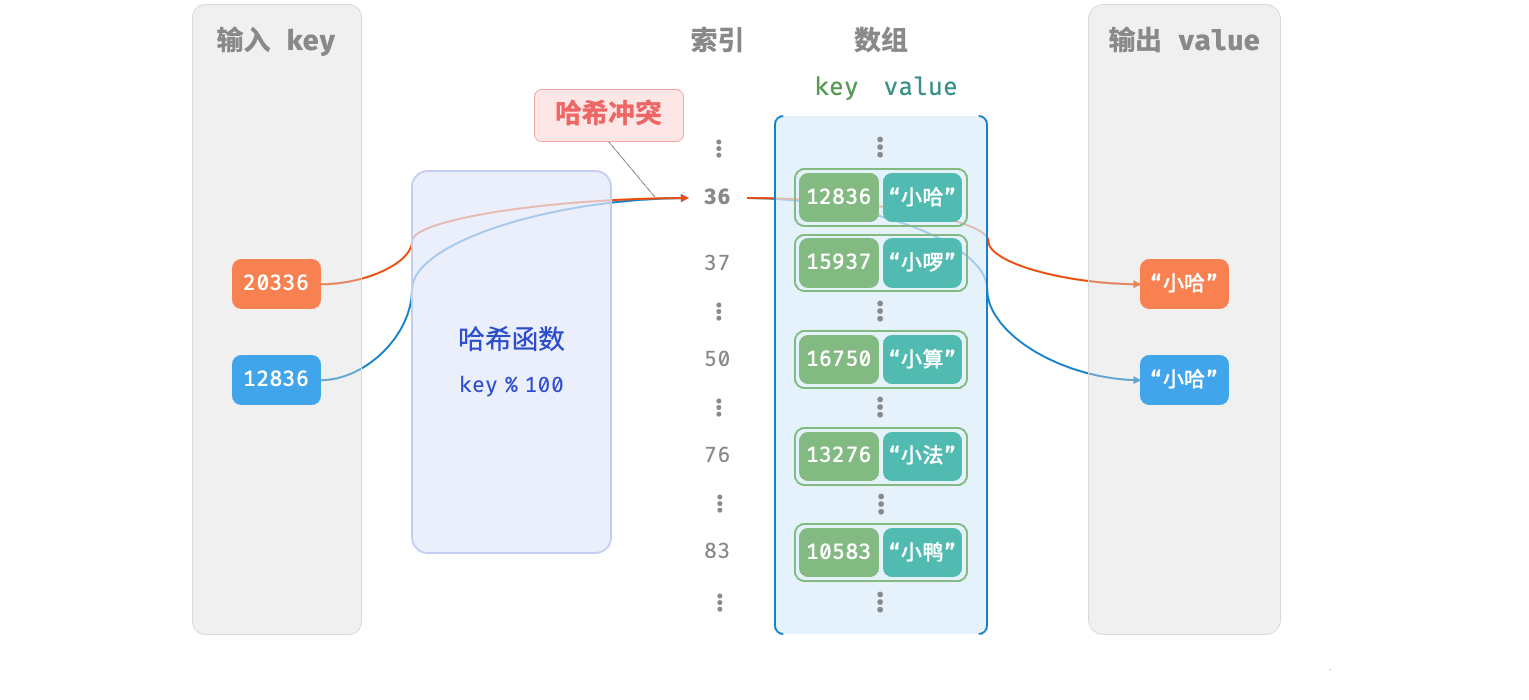 容易想到,哈希表容量n越大,多个key被分配到同一个桶中的概率就越低,冲突就越少。因此,我们可以通过扩容哈希表来减少哈希冲突。如图所示,扩容前键值对 (136, A)和(236, D)发生冲突,扩容后冲突消失。
容易想到,哈希表容量n越大,多个key被分配到同一个桶中的概率就越低,冲突就越少。因此,我们可以通过扩容哈希表来减少哈希冲突。如图所示,扩容前键值对 (136, A)和(236, D)发生冲突,扩容后冲突消失。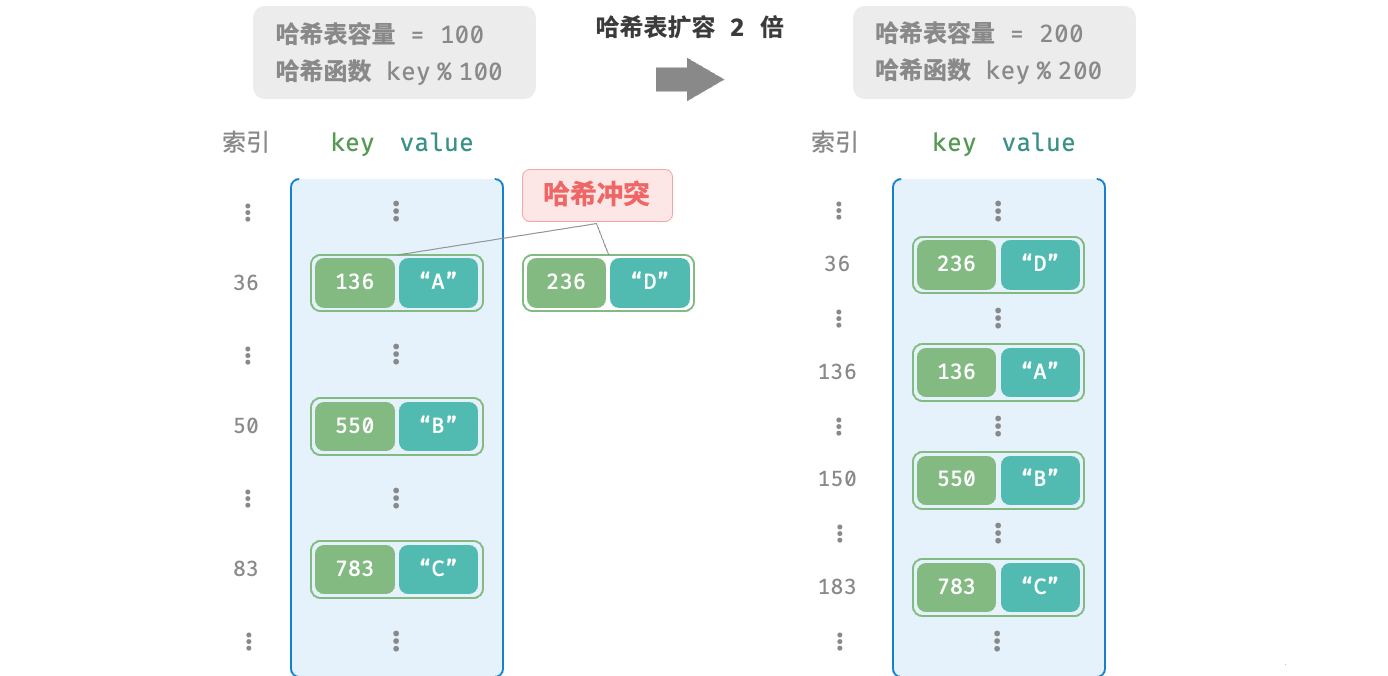 类似于数组扩容,哈希表扩容需将所有键值对从原哈希表迁移至新哈希表,非常耗时;并且由于哈希表容量capacity改变,我们需要通过哈希函数来重新计算所有键值对的存储位置,这进一步增加了扩容过程的计算开销。为此,编程语言通常会预留足够大的哈希表容量,防止频繁扩容。
类似于数组扩容,哈希表扩容需将所有键值对从原哈希表迁移至新哈希表,非常耗时;并且由于哈希表容量capacity改变,我们需要通过哈希函数来重新计算所有键值对的存储位置,这进一步增加了扩容过程的计算开销。为此,编程语言通常会预留足够大的哈希表容量,防止频繁扩容。
负载因子(load factor)是哈希表的一个重要概念,其定义为哈希表的元素数量除以桶数量,用于衡量哈希冲突的严重程度,也常作为哈希表扩容的触发条件。例如在 Java中,当负载因子超过0.75时,系统会将哈希表扩容至原先的2倍。
3. 哈希冲突
通常情况下哈希函数的输入空间远大于输出空间,因此理论上哈希冲突是不可避免的。比如,输入空间为全体整数,输出空间为数组容量大小,则必然有多个整数映射至同一桶索引。哈希冲突会导致查询结果错误,严重影响哈希表的可用性。为了解决该问题,每当遇到哈希冲突时,我们就进行哈希表扩容,直至冲突消失为止。此方法简单粗暴且有效,但效率太低,因为哈希表扩容需要进行大量的数据搬运与哈希值计算。为了提升效率,我们可以采用以下策略:
- 改良哈希表数据结构,使得哈希表可以在出现哈希冲突时正常工作。
- 仅在必要时,即当哈希冲突比较严重时,才执行扩容操作。
哈希表的结构改良方法主要包括"链式地址"和"开放寻址"。
3.1 链式地址
在原始哈希表中,每个桶仅能存储一个键值对。链式地址(separate chaining)将单个元素转换为链表,将键值对作为链表节点,将所有发生冲突的键值对都存储在同一链表中。  基于链式地址实现的哈希表的操作方法发生了以下变化:
基于链式地址实现的哈希表的操作方法发生了以下变化:
- 查询元素:输入 key ,经过哈希函数得到桶索引,即可访问链表头节点,然后遍历链表并对比 key 以查找目标键值对。
- 添加元素:首先通过哈希函数访问链表头节点,然后将节点(键值对)添加到链表中。
- 删除元素:根据哈希函数的结果访问链表头部,接着遍历链表以查找目标节点并将其删除。
链式地址存在以下局限性:
- 占用空间增大:链表包含节点指针,它相比数组更加耗费内存空间。
- 查询效率降低:因为需要线性遍历链表来查找对应元素。
值得注意的是,当链表很长时,查询效率O(n)很差。此时可以将链表转换为"AVL树(红黑树),从而将查询操作的时间复杂度优化至O(logn)。
3.2 开放寻址
开放寻址(open addressing)不引入额外的数据结构,而是通过"多次探测"来处理哈希冲突,探测方式主要包括线性探测、平方探测和多次哈希等。
- 线性探测 线性探测采用固定步长的线性搜索来进行探测,其操作方法与普通哈希表有所不同:
- 插入元素:通过哈希函数计算桶索引,若发现桶内已有元素,则从冲突位置向后线性遍历(步长通常为1),直至找到空桶,将元素插入其中。
- 查找元素:若发现哈希冲突,则使用相同步长向后进行线性遍历,直到找到对应元素,返回value即可;如果遇到空桶,说明目标元素不在哈希表中,返回
None。
如图展示了开放寻址(线性探测)哈希表的键值对分布。根据此哈希函数,最后两位相同的key都会被映射到相同的桶。而通过线性探测,它们被依次存储在该桶以及之下的桶中。 然而,线性探测容易产生"聚集现象"。具体来说,数组中连续被占用的位置越长,这些连续位置发生哈希冲突的可能性越大,从而进一步促使该位置的聚堆生长,形成恶性循环,最终导致增删查改操作效率劣化。
然而,线性探测容易产生"聚集现象"。具体来说,数组中连续被占用的位置越长,这些连续位置发生哈希冲突的可能性越大,从而进一步促使该位置的聚堆生长,形成恶性循环,最终导致增删查改操作效率劣化。
值得注意的是,我们不能在开放寻址哈希表中直接删除元素。这是因为删除元素会在数组内产生一个空桶None ,而当查询元素时,线性探测到该空桶就会返回,因此在该空桶之下的元素都无法再被访问到,程序可能误判这些元素不存在,如图所示: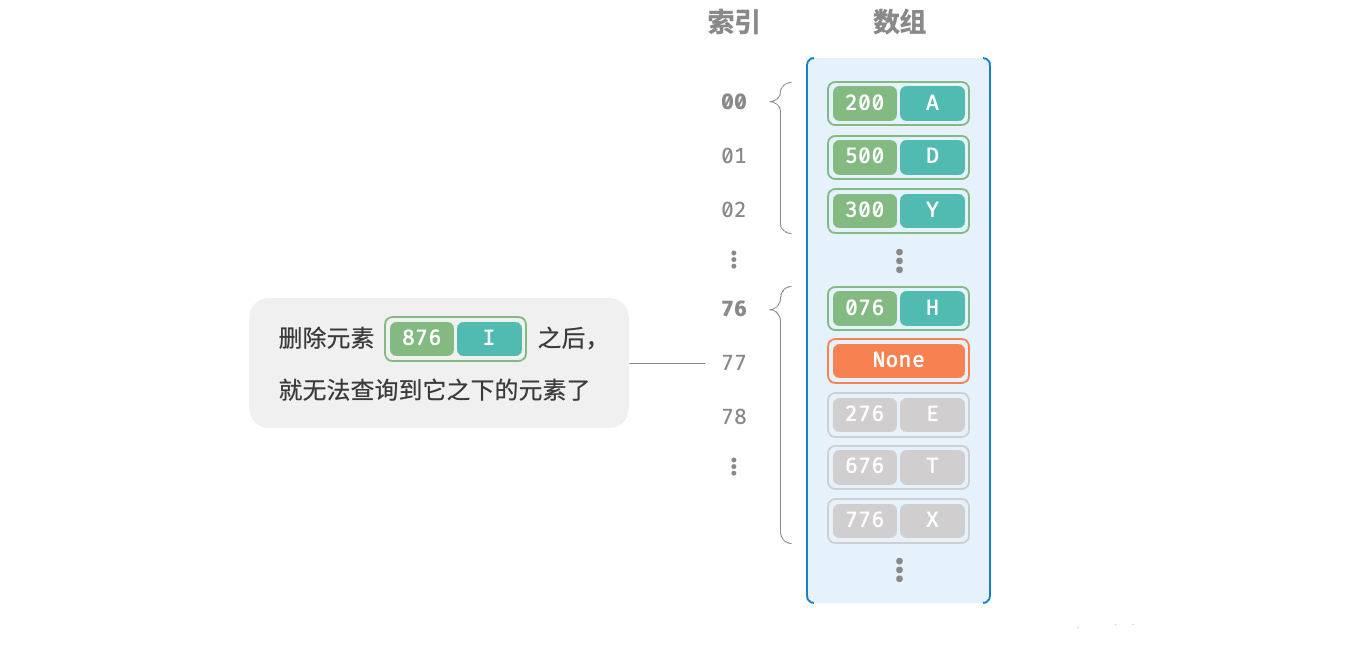 为了解决该问题,我们可以采用懒删除(lazy deletion)机制:它不直接从哈希表中移除元素,而是利用一个常量
为了解决该问题,我们可以采用懒删除(lazy deletion)机制:它不直接从哈希表中移除元素,而是利用一个常量TOMBSTONE来标记这个桶。在该机制下,None和TOMBSTONE都代表空桶,都可以放置键值对。但不同的是,线性探测到TOMBSTONE时应该继续遍历,因为其之下可能还存在键值对。
然而,懒删除可能会加速哈希表的性能退化。这是因为每次删除操作都会产生一个删除标记,随着TOMBSTONE的增加,搜索时间也会增加,因为线性探测可能需要跳过多个TOMBSTONE才能找到目标元素。
为此,考虑在线性探测中记录遇到的首个TOMBSTONE的索引,并将搜索到的目标元素与该TOMBSTONE交换位置。这样做的好处是当每次查询或添加元素时,元素会被移动至距离理想位置(探测起始点)更近的桶,从而优化查询效率。 2. 平方探测
平方探测与线性探测类似,都是开放寻址的常见策略之一。当发生冲突时,平方探测不是简单地跳过一个固定的步数,而是跳过"探测次数的平方"的步数,即1,4,9...步。平方探测主要具有以下优势:
- 平方探测通过跳过探测次数平方的距离,试图缓解线性探测的聚集效应。
- 平方探测会跳过更大的距离来寻找空位置,有助于数据分布得更加均匀。
然而,平方探测并不是完美的: - 仍然存在聚集现象,即某些位置比其他位置更容易被占用。
- 由于平方的增长,平方探测可能不会探测整个哈希表,这意味着即使哈希表中有空桶,平方探测也可能无法访问到它。
- 多次哈希
顾名思义,多次哈希方法使用多个哈希函数f₁(x),f₂(x),f₃(x)...进行探测。
插入元素:若哈希函数f₁(x)出现冲突,则尝试f₂(x),以此类推,直到找到空位后插入元素。
查找元素:在相同的哈希函数顺序下进行查找,直到找到目标元素时返回;若遇到空位或已尝试所有哈希函数,说明哈希表中不存在该元素,则返回None。
3.3 编程语言的选择
各种编程语言采取了不同的哈希表实现策略:
- Python采用开放寻址。字典dict使用伪随机数进行探测。
- Java采用链式地址。自JDK 1.8以来,当HashMap内数组长度达到64且链表长度达到8时,链表会转换为红黑树以提升查找性能。
- Go采用链式地址。Go规定每个桶最多存储8个键值对,超出容量则连接一个溢出桶;当溢出桶过多时,会执行一次特殊的等量扩容操作,以确保性能。
4. 哈希算法
无论是开放寻址还是链式地址,它们只能保证哈希表可以在发生冲突时正常工作,而无法减少哈希冲突的发生。如果哈希冲突过于频繁,哈希表的性能则会急剧劣化。键值对的分布情况由哈希函数决定。哈希函数的计算步骤,先计算哈希值,再对数组长度取模:
index = hash(key) % capacity观察以上公式,当哈希表容量capacity固定时,哈希算法hash()决定了输出值,进而决定了键值对在哈希表中的分布情况。这意味着,为了降低哈希冲突的发生概率,我们应当将注意力集中在哈希算法hash()的设计上。
4.1 哈希算法的设计
哈希算法的设计是一个需要考虑许多场景的复杂问题。比如:
- 加法哈希:对输入的每个字符的ASCII码进行相加,将得到的总和作为哈希值。
- 乘法哈希:利用乘法的不相关性,每轮乘以一个常数,将各个字符的ASCII码累积到哈希值中。
- 异或哈希:将输入数据的每个元素通过异或操作累积到一个哈希值中。
- 旋转哈希:将每个字符的ASCII码累积到一个哈希值中,每次累积之前都会对哈希值进行旋转操作。
/* 加法哈希 */
int addHash(String key) {
long hash = 0;
final int MODULUS = 1000000007;
for (char c : key.toCharArray()) {
hash = (hash + (int) c) % MODULUS;
}
return (int) hash;
}
/* 乘法哈希 */
int mulHash(String key) {
long hash = 0;
final int MODULUS = 1000000007;
for (char c : key.toCharArray()) {
hash = (31 * hash + (int) c) % MODULUS;
}
return (int) hash;
}
/* 异或哈希 */
int xorHash(String key) {
int hash = 0;
final int MODULUS = 1000000007;
for (char c : key.toCharArray()) {
hash ^= (int) c;
}
return hash & MODULUS;
}
/* 旋转哈希 */
int rotHash(String key) {
long hash = 0;
final int MODULUS = 1000000007;
for (char c : key.toCharArray()) {
hash = ((hash << 4) ^ (hash >> 28) ^ (int) c) % MODULUS;
}
return (int) hash;
}观察发现,每种哈希算法的最后一步都是对大质数1000000007取模,以确保哈希值在合适的范围内。值得思考的是,为什么要强调对质数取模,或者说对合数取模的弊端是什么?这是一个有趣的问题。
先抛出结论:使用大质数作为模数,可以最大化地保证哈希值的均匀分布。因为质数不与其他数字存在公约数,可以减少因取模操作而产生的周期性模式,从而避免哈希冲突。
4.2 常见哈希算法
不难发现,以上介绍的简单哈希算法都比较"脆弱",远远没有达到哈希算法的设计目标。在实际中,我们通常会用一些标准哈希算法,例如MD5、SHA-1、SHA-2和 SHA-3等。它们可以将任意长度的输入数据映射到恒定长度的哈希值。
| MD5 | SHA-1 | SHA-2 | SHA-3 | |
|---|---|---|---|---|
| 推出时间 | 1992 | 1995 | 2002 | 2008 |
| 输出长度 | 128 bit | 160 bit | 256/512 bit | 224/256/384/512 bit |
| 哈希冲突 | 较多 | 较多 | 很少 | 很少 |
| 安全等级 | 低,已被成功攻击 | 低,已被成功攻击 | 高 | 高 |
| 应用 | 已被弃用,仍用于数据完整性检查 | 已被弃用 | 加密货币交易验证、数字签名等 | 可用于替代 SHA-2 |
4.3 数据结构的哈希值
我们知道,哈希表的key可以是整数、小数或字符串等数据类型。编程语言通常会为这些数据类型提供内置的哈希算法,用于计算哈希表中的桶索引。以Java为例,我们可以调用hashcode()函数来计算各种数据类型的哈希值:
- 整数和布尔量的哈希值就是其本身。
- 浮点数和字符串的哈希值计算较为复杂,有兴趣的读者请自行学习。
- 元组的哈希值是对其中每一个元素进行哈希,然后将这些哈希值组合起来,得到单一的哈希值。
- 对象的哈希值基于其内存地址生成。通过重写对象的哈希方法,可实现基于内容生成哈希值。
int num = 3;
int hashNum = Integer.hashCode(num);
// 整数 3 的哈希值为 3
boolean bol = true;
int hashBol = Boolean.hashCode(bol);
// 布尔量 true 的哈希值为 1231
double dec = 3.14159;
int hashDec = Double.hashCode(dec);
// 小数 3.14159 的哈希值为 -1340954729
String str = "Hello 算法";
int hashStr = str.hashCode();
// 字符串"Hello 算法"的哈希值为 -727081396
Object[] arr = { 12836, "小哈" };
int hashTup = Arrays.hashCode(arr);
// 数组 [12836, 小哈] 的哈希值为 1151158
ListNode obj = new ListNode(0);
int hashObj = obj.hashCode();
// 节点对象 utils.ListNode@7dc5e7b4 的哈希值为 2110121908| 无序数组 | 二叉搜索树 | |
|---|---|---|
| 查找元素 | O(n) | O(logn) |
| 插入元素 | O(1) | O(logn) |
| 删除元素 | O(n) | O(logn) |