数据表
1. 基本概念
在Doris中,数据都以关系表(Table)的形式进行逻辑上的描述。
1.1 ROW和COLUMN
一张表包括行(Row)和列(Column):Row,即用户的一行数据; Column,用于描述一行数据中不同的字段。
Column可以分为两大类:Key和Value。从业务角度看,Key和Value可以分别对应维度列和度量列。
1.2 Table和Partition
在Doris的存储引擎中,数据首先被划分成若干个分区(Partition),划分的规则通常是按照用户指定的分区列进行范围划分,比如按时间划分。而在每个分区内,数据被进一步的按照Hash的方式分桶,分桶的规则是要找用户指定的分桶列的值进行Hash后分桶。每个分桶就是一个数据分片(Tablet),也是数据划分的最小逻辑单元。
Tablet之间的数据是没有交集的,独立存储的。Tablet也是数据移动、复制等操作的最小物理存储单元。
Partition可以视为是逻辑上最小的管理单元。数据的导入与删除,都可以或仅能针对一个partition进行。
2. 字段类型
2.1 数值类型
| 类型名 | 存储空间(字节) | 描述 |
|---|---|---|
| BOOLEAN | 1 | 布尔值,0代表 false, 1代表 true。 |
| TINYINT | 1 | 有符号整数,范围 [-128, 127]。 |
| SMALLINT | 2 | 有符号整数,范围 [-32768, 32767]。 |
| INT | 4 | 有符号整数, 范围 [-2147483648, 2147483647] |
| BIGINT | 8 | 有符号整数, 范围 [-9223372036854775808, 9223372036854775807]。 |
| LARGEINT | 16 | 有符号整数,范围 [-2^127 + 1 ~ 2^127 - 1]。 |
| FLOAT | 4 | 浮点数,范围 [-3.410^38 ~ 3.410^38]。 |
| DOUBLE | 8 | 浮点数,范围 [-1.7910^308 ~ 1.7910^308]。 |
| DECIMAL | 4/8/16 | 高精度定点数,格式:DECIMAL(M[,D])。 其中M 代表一共有多少个有效数字(precision), D 代表小数位有多少数字(scale)。 有效数字 M 的范围是 [1, 38], 小数位数字数量 D 的范围是 [0, precision]。 0 < precision <= 9 的场合,占用 4 字节。 9 < precision <= 18 的场合,占用 8 字节。 16 < precision <= 38 的场合,占用 16 字节。 |
2.2 日期类型
| 类型名 | 存储空间(字节) | 描述 |
|---|---|---|
| DATE | 16 | 日期类型,目前的取值范围是 ['0000-01-01', '9999-12-31'], 默认的打印形式是 'yyyy-MM-dd'。 |
| DATETIME | 16 | 日期时间类型,格式:DATETIME([P])。 可选参数P表示时间精度,取值范围是[0, 6], 即最多支持 6 位小数(微秒)。不设置时为0。 取值范围是 ['0000-01-01 00:00:00[.000000]', '9999-12-31 23:59:59[.999999]']。 打印的形式是 'yyyy-MM-dd HH:mm:ss.SSSSSS'。 |
2.3 字符串类型
| 类型名 | 存储空间(字节) | 描述 |
|---|---|---|
| CHAR | M | 定长字符串,M代表的是定长字符串的字节长度。 M 的范围是1-255。 |
| VARCHAR | 不定长 | 变长字符串,M代表的是变长字符串的字节长度。 M 的范围是1-65533。变长字符串是以UTF-8 编码存储的, 因此通常英文字符占1个字节,中文字符占3个字节。 |
| STRING | 不定长 | 变长字符串,默认支持1048576 字节(1MB), 可调大到2147483643字节(2GB)。 可通过BE配置string_type_length_soft_limit_bytes调整。 String类型只能用在Value列,不能用在Key列和分区分桶列。 |
2.4 半结构类型
| 类型名 | 存储空间(字节) | 描述 |
|---|---|---|
| ARRAY | 不定长 | 由 T 类型元素组成的数组,不能作为 Key 列使用。 目前支持在 Duplicate 和 Unique 模型的表中使用。 |
| MAP | 不定长 | 由 K, V 类型元素组成的 map,不能作为 Key 列使用。 目前支持在 Duplicate 和 Unique 模型的表中使用。 |
| STRUCT | 不定长 | 由多个 Field 组成的结构体,也可被理解为多个列的集合。 不能作为 Key 使用,目前 STRUCT 仅支持在 Duplicate 模型的表中使用。 一个 Struct 中的 Field 的名字和数量固定,总是为 Nullable。 |
| JSON | 不定长 | 二进制 JSON 类型,采用二进制 JSON 格式存储, 通过 JSON 函数访问 JSON 内部字段。 长度限制和配置方式与 String 相同 |
| VARIANT | 不定长 | 动态可变数据类型,专为半结构化数据如 JSON 设计, 可以存入任意 JSON,自动将 JSON 中的字段拆分成子列存储, 提升存储效率和查询分析性能。长度限制和配置方式与 String 相同。 Variant 类型只能用在 Value 列,不能用在 Key 列和分区分桶列。 |
2.5 聚合类型
| 类型名 | 存储空间(字节) | 描述 |
|---|---|---|
| HLL | 不定长 | HLL 是模糊去重,在数据量大的情况性能优于 Count Distinct。 HLL 的误差通常在 1% 左右,有时会达到 2%。 HLL 不能作为 Key 列使用,建表时配合聚合类型为 HLL_UNION。 用户不需要指定长度和默认值。长度根据数据的聚合程度系统内控制。 HLL 列只能通过配套的 hll_union_agg、hll_raw_agg、 hll_cardinality、hll_hash 进行查询或使用。 |
| BITMAP | 不定长 | Bitmap 类型的列可以在Aggregate表、Unique表或Duplicate表中使用。 在Unique 表或Duplicate表中使用时, 其必须作为非Key列使用。 在Aggregate表中使用时, 其必须作为非Key列使用, 且建表时配合的聚合类型为BITMAP_UNION。 用户不需要指定长度和默认值。长度根据数据的聚合程度系统内控制。 BITMAP列只能通过配套的 bitmap_union_count、bitmap_union、 bitmap_hash、bitmap_hash64等函数进行查询或使用。 |
| QUANTILE_STATE | 不定长 | QUANTILE_STATE是一种计算分位数近似值的类型, 在导入时会对相同的Key,不同Value进行预聚合, 当 value 数量不超过2048时采用明细记录所有数据, 当 Value 数量大于2048时采用TDigest算法, 对数据进行聚合(聚类)保存聚类后的质心点。 QUANTILE_STATE不能作为Key列使用, 建表时配合聚合类型为QUANTILE_UNION。 用户不需要指定长度和默认值。 长度根据数据的聚合程度系统内控制。 QUANTILE_STATE列只能通过配套的 QUANTILE_PERCENT、QUANTILE_UNION、TO_QUANTILE_STATE 等函数进行查询或使用。 |
| AGG_STATE | 不定长 | 聚合函数,只能配合state/merge/union函数组合器使用。 AGG_STATE不能作为Key列使用, 建表时需要同时声明聚合函数的签名。 用户不需要指定长度和默认值。 实际存储的数据大小与函数实现有关。 |
2.6 IP类型
| 类型名 | 存储空间(字节) | 描述 |
|---|---|---|
| IPv4 | 4 字节 | 以4字节二进制存储IPv4地址, 配合ipv4_*系列函数使用。 |
| IPv6 | 16 字节 | 以16字节二进制存储IPv6地址, 配合ipv6_*系列函数使用。 |
3. 数据模型
Doris的数据模型分为3类:
- 明细模型(Duplicate Key Model):允许指定的Key列重复,Doirs存储层保留所有写入的数据,适用于必须保留所有原始数据记录的情况。
- 主键模型(Unique Key Model):每一行的Key值唯一,可确保给定的Key列不会存在重复行,Doris存储层对每个key只保留最新写入的数据,适用于数据更新的情况。
- 聚合模型(Aggregate Key Model):可根据Key列聚合数据,Doris存储层保留聚合后的数据,从而可以减少存储空间和提升查询性能;通常用于需要汇总或聚合信息(如总数或平均值)的情况。
3.1 Aggregate(聚合模型)
- 提前创建数据库test_db:
CREATE DATABASE test_db;
USE test_db;- 创建聚合表
CREATE TABLE IF NOT EXISTS example_tbl_agg1
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
-- 字段不是度量列,就是维度列,将所有维度列写入到AGGREGATE KEY中
AGGREGATE KEY(`user_id`, `date`, `city`, `age`, `sex`)
-- 没有分区使用默认分区,在默认分区上面创建10个桶
DISTRIBUTED BY HASH(`user_id`) BUCKETS 10
PROPERTIES (
"replication_num" = "1"
);这是一个典型的用户信息和访问行为的事实表。在一般星型模型中,用户信息和访问行为一般分别存放在维度表和事实表中。这里为了更加方便的解释Doris的数据模型,将两部分信息统一存放在一张表中。
表中的列按照是否设置了AggregationType,分为Key (维度列)和Value(指标列)。没有设置 AggregationType的user_id、date、age、sex称为Key,而设置了AggregationType的称为Value。
当导入数据时,对于Key列相同的行会聚合成一行,而Value列会按照设置的AggregationType进行聚合。AggregationType目前有以下几种聚合方式和agg_state:
- SUM:求和,多行的Value进行累加。
- REPLACE:替代,下一批数据中的Value会替换之前导入过的行中的Value。
- MAX:保留最大值。
- MIN:保留最小值。
- REPLACE_IF_NOT_NULL:非空值替换。和REPLACE的区别在于对于null值,不做替换。
- HLL_UNION:HLL类型的列的聚合方式,通过HyperLogLog算法聚合。
- BITMAP_UNION:BIMTAP类型的列的聚合方式,进行位图的并集聚合。
- 插入数据
insert into example_tbl_agg1 values
(10000,"2017-10-01","北京",20,0,"2017-10-01 06:00:00",20,10,10),
(10000,"2017-10-01","北京",20,0,"2017-10-01 07:00:00",15,2,2),
(10001,"2017-10-01","北京",30,1,"2017-10-01 17:05:45",2,22,22),
(10002,"2017-10-02","上海",20,1,"2017-10-02 12:59:12",200,5,5),
(10003,"2017-10-02","广州",32,0,"2017-10-02 11:20:00",30,11,11),
(10004,"2017-10-01","深圳",35,0,"2017-10-01 10:00:15",100,3,3),
(10004,"2017-10-03","深圳",35,0,"2017-10-03 10:20:22",11,6,6);- 查询数据
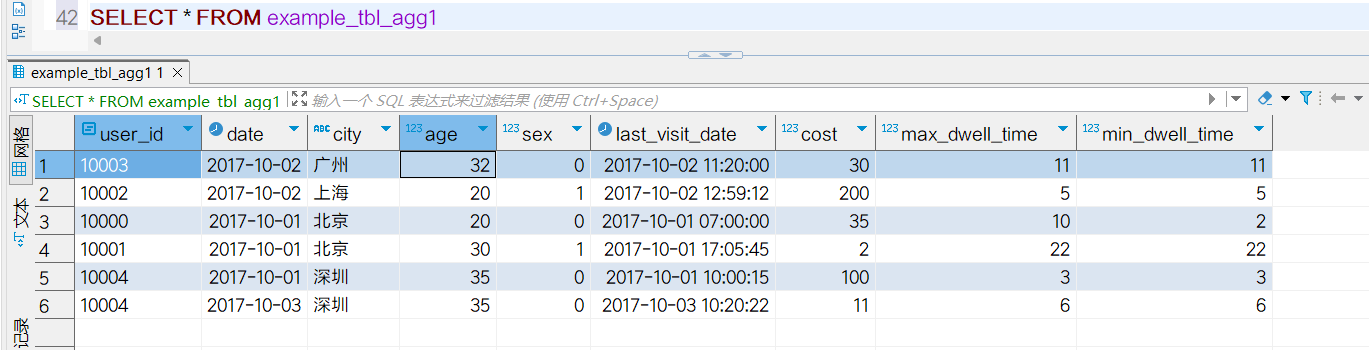 发现插入7条查询出来6条,少一条的原因是Doris中只会存储聚合后的数据。第1条和第二条的维度列也就是
发现插入7条查询出来6条,少一条的原因是Doris中只会存储聚合后的数据。第1条和第二条的维度列也就是AGGREGATE KEY相同,会预聚合在一起。存储明细数据的话会导致明细数据丢失,用户不能再查询到聚合前的数据了。
提示
- AGGREGATE KEY数据模型中,所有没有指定聚合方式(SUM、REPLACE、MAX、MIN)的列视为Key列。而其余则为Value列。
- 在同一个导入批次中的数据,对于REPLACE这种聚合方式,替换顺序不做保证,如在这个例子中,最终保存下来的,也有可能是2017-10-01 06:00:00;而对于不同导入批次中的数据,可以保证,后一批次的数据会替换前一批次。
- Key列必须在所有Value列之前。
- 尽量选择整型类型。因为整型类型的计算和查找效率远高于字符串。
- 对于不同长度的整型类型的选择原则,遵循够用即可。
- 对于VARCHAR和STRING类型的长度,遵循够用即可。
3.2 Unique(主键模型)
在某些多维分析场景下,用户更关注的是如何保证Key的唯一性,即如何获得Primary Key唯一性约束。因此,我们引入了Unique的数据模型。该模型本质上是聚合模型的一个特例,也是一种简化的表结构表示方式。 Unique模型默认的更新语义为整行UPSERT,即UPDATE OR INSERT,该行数据的key如果存在,则进行更新,如果不存在,则进行新数据插入。
CREATE TABLE IF NOT EXISTS example_tbl_unique
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`username` VARCHAR(50) NOT NULL COMMENT "用户昵称",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`phone` LARGEINT COMMENT "用户电话",
`address` VARCHAR(500) COMMENT "用户地址",
`register_time` DATETIME COMMENT "用户注册时间"
)
UNIQUE KEY(`user_id`, `username`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 10
PROPERTIES (
"replication_num" = "1"
);主键模型提供了两种实现方式:
- 写时合并(merge-on-write)。在1.2版本中,我们引入了写时合并实现,该实现会在数据写入阶段完成所有数据去重的工作,因此能够提供非常好的查询性能。自2.1版本起,已经非常成熟稳定,由于其优秀的查询性能,写时合并成为Unique模型的默认实现。
- 读时合并(merge-on-read)。在读时合并实现中,用户在进行数据写入时不会触发任何数据去重相关的操作,所有数据去重的操作都在查询或者compaction时进行。因此,读时合并的写入性能较好,查询性能较差,同时内存消耗也较高。
insert into example_tbl_unique VALUES
(10000,'wuyanzu','北京',18,0,12345678910,'北京朝阳区','2017-10-01 07:00:00'),
(10000,'wuyanzu','北京',19,0,12345678910,'北京朝阳区','2017-10-01 0:00:00'),
(10000,'zhangsan','北京',20,0,12345678910,'北京海淀区','2017-11-15 06:10:20');插入数据3条,查询数据会发现少了一条: 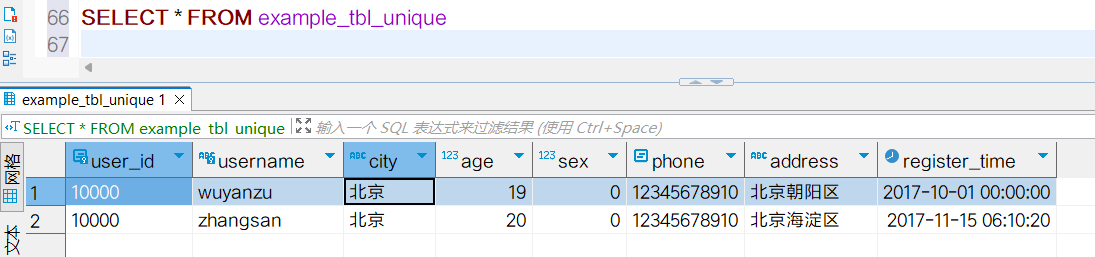 按照UNIQUE KEY指定的列会发现第一条和第二条数据前两列相同,Doris会认为这两条数据相同,做了去重保留第二条数据。example_tbl_unique表也可以通过前面的Aggregate模型实现:
按照UNIQUE KEY指定的列会发现第一条和第二条数据前两列相同,Doris会认为这两条数据相同,做了去重保留第二条数据。example_tbl_unique表也可以通过前面的Aggregate模型实现:
CREATE TABLE IF NOT EXISTS example_tbl_unique2
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`username` VARCHAR(50) NOT NULL COMMENT "用户昵称",
`city` VARCHAR(20) REPLACE COMMENT "用户所在城市",
`age` SMALLINT REPLACE COMMENT "用户年龄",
`sex` TINYINT REPLACE COMMENT "用户性别",
`phone` LARGEINT REPLACE COMMENT "用户电话",
`address` VARCHAR(500) REPLACE COMMENT "用户地址",
`register_time` DATETIME REPLACE COMMENT "用户注册时间"
)
AGGREGATE KEY(`user_id`, `username`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 10
PROPERTIES (
"replication_num" = "1"
);提示
- Unique表的实现方式只能在建表时确定,无法通过schema change进行修改。
- 旧的Merge-on-Read的实现无法无缝升级到Merge-on-Write的实现(数据组织方式完全不同),如果需要改为使用写时合并的实现版本,需要手动执行
insert into unique-mow-table select * from source table来重新导入。 - 整行更新:Unique模型默认的更新语义为整行UPSERT,即 UPDATE OR INSERT,该行数据的key如果存在,则进行更新,如果不存在,则进行新数据插入。在整行UPSERT语义下,即使用户使用insert into指定部分列进行写入,Doris也会在Planner中将未提供的列使用NULL值或者默认值进行填充。
- 部分列更新:如果用户希望更新部分字段,需要使用写时合并实现,并通过特定的参数来开启部分列更新的支持。
3.3 Duplicate(明细模型)
在某些多维分析场景下,数据既没有主键,也没有聚合需求或者必须保留所有原始数据记录,因此我们引入Duplicate模型。
CREATE TABLE IF NOT EXISTS example_tbl_duplicate
(
`timestamp` DATETIME NOT NULL COMMENT "日志时间",
`type` INT NOT NULL COMMENT "日志类型",
`error_code` INT COMMENT "错误码",
`error_msg` VARCHAR(1024) COMMENT "错误详细信息",
`op_id` BIGINT COMMENT "负责人id",
`op_time` DATETIME COMMENT "处理时间"
)
DUPLICATE KEY(`timestamp`, `type`, `error_code`)
DISTRIBUTED BY HASH(`type`) BUCKETS 10
PROPERTIES (
"replication_num" = "1"
);插入4条数据:
insert into example_tbl_duplicate values
('2017-10-01 08:00:05', 1,404,'not found page',101, '2017-10-01 08:00:05'),
('2017-10-01 08:00:05', 1,404,'not found page',101, '2017-10-01 08:00:05'),
('2017-10-01 08:00:05', 2,404,'not found page',101, '2017-10-01 08:00:06'),
('2017-10-01 08:00:06', 1,404,'not found page',101, '2017-10-01 08:00:07');查询数据,发现数据也是4条: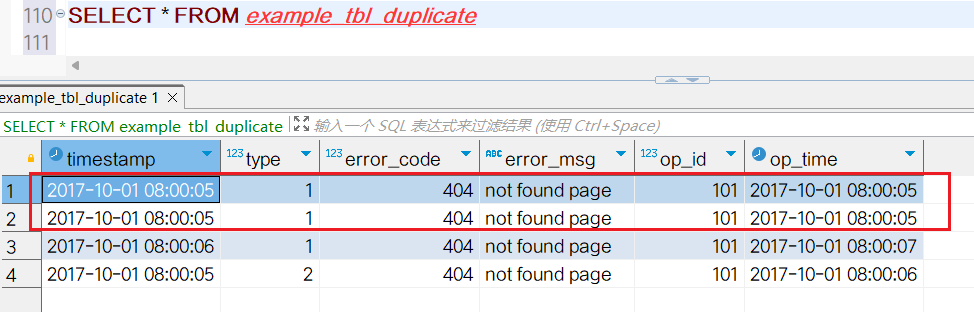 当创建表的时候没有指定Unique、Aggregate或Duplicate时,会默认创建一个Duplicate模型的表,并自动按照一定规则选定排序列。
当创建表的时候没有指定Unique、Aggregate或Duplicate时,会默认创建一个Duplicate模型的表,并自动按照一定规则选定排序列。
4. 模型选择建议
因为数据模型在建表时就已经确定,且无法修改。所以,选择一个合适的数据模型非常重要。
Aggregate 模型可以通过预聚合,极大地降低聚合查询时所需扫描的数据量和查询的计算量,非常适合有固定模式的报表类查询场景。但是该模型对count(*)查询很不友好。同时因为固定了Value列上的聚合方式,在进行其他类型的聚合查询时,需要考虑语意正确性。
Unique模型针对需要唯一主键约束的场景,可以保证主键唯一性约束。但是无法利用ROLLUP等预聚合带来的查询优势。对于聚合查询有较高性能需求的用户,推荐使用自1.2版本加入的写时合并实现。
Duplicate适合任意维度的Ad-hoc查询。虽然同样无法利用预聚合的特性,但是不受聚合模型的约束,可以发挥列存模型的优势(只读取相关列,而不需要读取所有 Key 列)。
5. 建表语法
CREATE TABLE [IF NOT EXISTS] [database.]table
(
column_definition_list
[, index_definition_list]
)
[engine=olap|mysql|broker|hive|es]
[keys_type]
[table_comment "table comment"]
[partition_info]
distribution_desc
[rollup_list]
[properties]
[extra_properties]