Kettle整合大数据
Kettle数据源支持连接到大数据集群进行数据处理,直接连接到Amazon Elastic MapReduce(EMR)、Azure HDInsight (HDI)、Cloudera Distribution for Hadoop(CDH)和Cloudera Data Platform(CDP)、Google Dataproc 和 Hortonworks Data Platform(HDP)。Kettle还支持HDFS、HBase、Hive、Oozie、Pig、Sqoop、Yarn/MapReduce、ZooKeeper和Spark等相关服务。
1. 准备工作
1.1 添加新驱动程序
Kettle使用驱动程序连接到Hadoop。这些连接作用的驱动程序是Apache Karaf存档文件(.kar格式)。从9.3开始官方并没在Kettle安装包中提供驱动包,需要到Kettle的官方maven中手动下载,本人已经整理好了,可以直接在百度云盘中获得, 链接地址:https://pan.baidu.com/s/1Uy9eApzPiYPplnyMXJssOw 提取码:6666
1.2 准备大数据配置文件
从hadoop集群上面下载集群配置文件hdfs.site.xml\core-site.xml\yarn-site.xml\mapred-site.xml, 在hive中下载选择驱动文件hive-site.xml,放到plugins\pentaho-big-data-plugin\hadoop-configurations\hdp30目录下: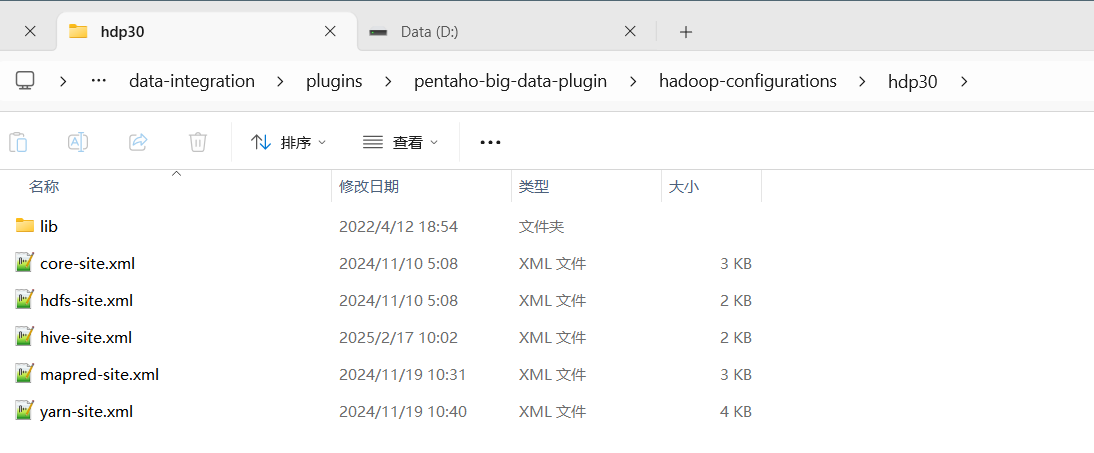
1.3 修改启动脚本
修改kettle启动文件Spoon.bat,在第139行,添加以下内容,指定编码为UTF-8和hive的连接用户名(用户名以实际为准):
"-DHADOOP_USER_NAME=jack" "-Dfile.encoding=UTF-8"2. 配置hadoop连接
2.1 添加连接驱动
右键点击Hadoop clusters,选择add driver: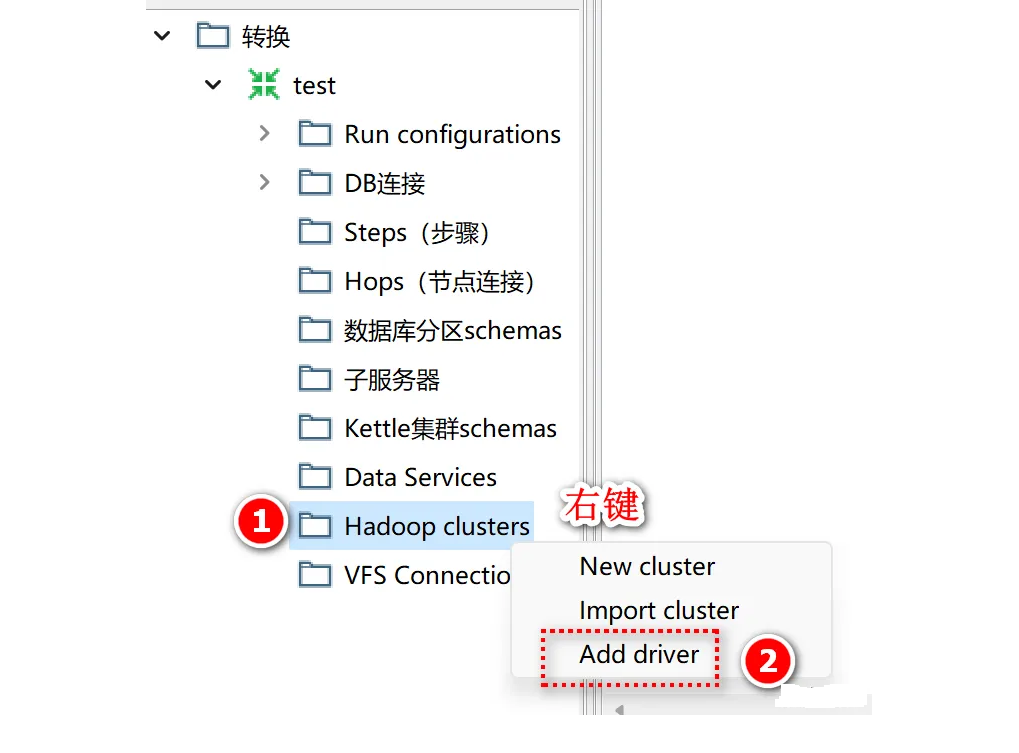 驱动位于"D:\pdi-ce-9.3.0.0-428\data-integration\addtional-shims"路径下:
驱动位于"D:\pdi-ce-9.3.0.0-428\data-integration\addtional-shims"路径下: 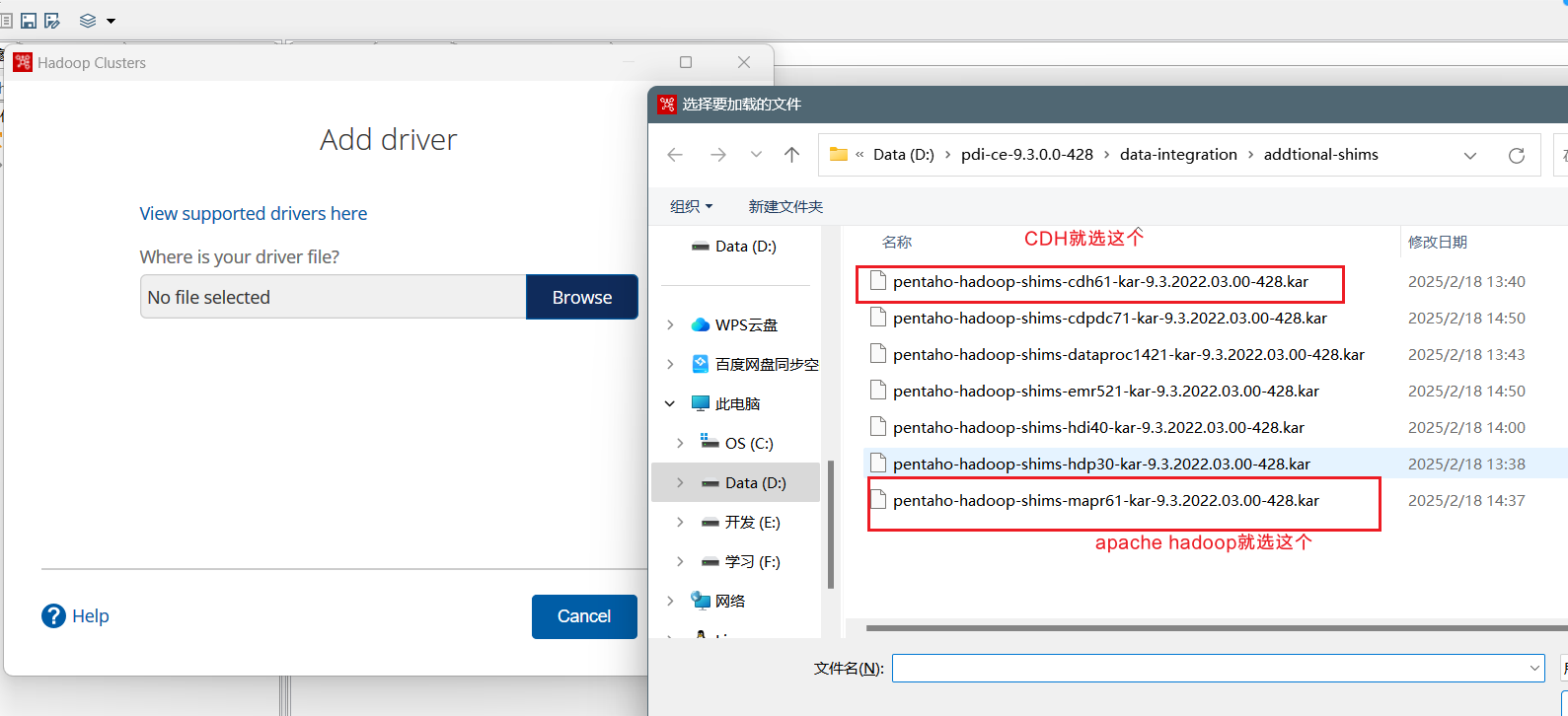 添加之后一定要重启Kettle
添加之后一定要重启Kettle 
2.2 新建集群
重启kettle后,右键点击Hadoop clusters,选择new cluster: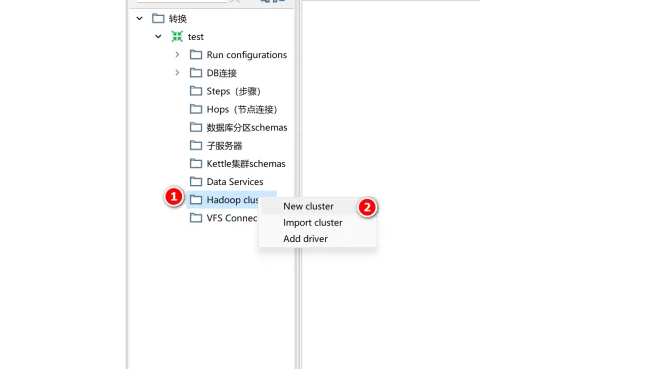 配置集群信息,可以不填ZooKeeper、Oozie、Kafka的连接信息
配置集群信息,可以不填ZooKeeper、Oozie、Kafka的连接信息 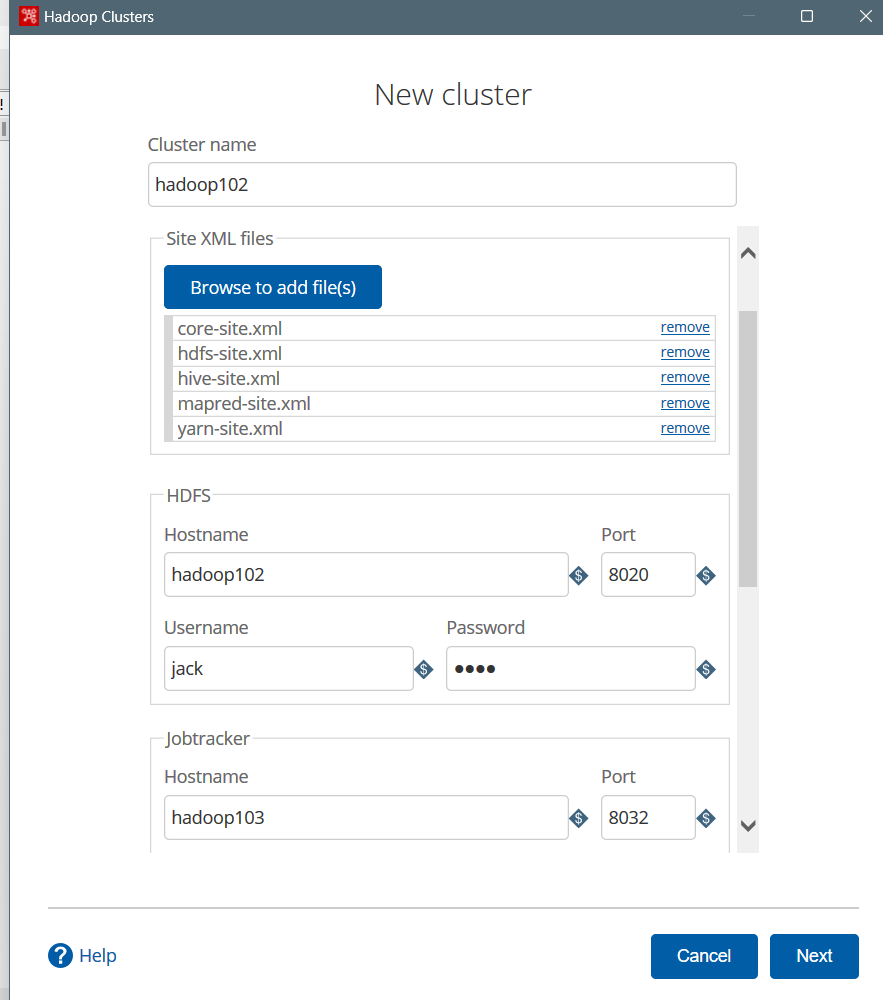 点击下一步,如果连接不成功,点击查询连接结果:
点击下一步,如果连接不成功,点击查询连接结果: 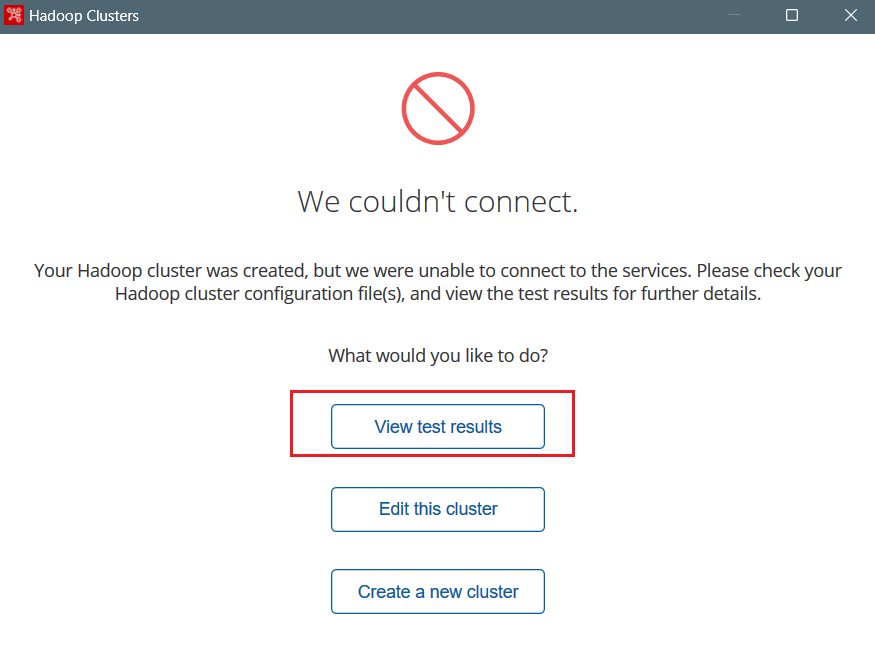 可以看到是验证本机用户和jack在hdfs的用户目录权限没通过:
可以看到是验证本机用户和jack在hdfs的用户目录权限没通过: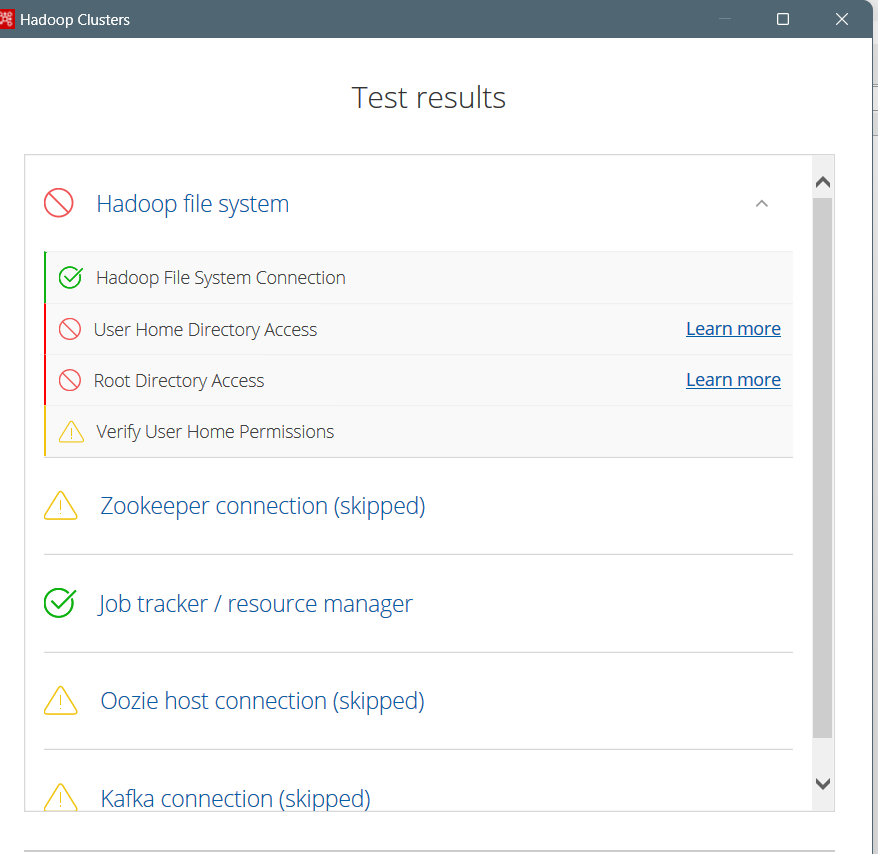 将两个地方的缓存文件夹删除即可:
将两个地方的缓存文件夹删除即可:
- C:\Users\mi(可替换为实际的文件目录).kettle
- D:\pdi-ce-9.3.0.0-428\data-integration\system\karaf\caches